机器学习中的聚类
摘要
聚类是无监督学习中的重要任务,旨在将数据集划分为若干个子集(簇),使得同一簇内的样本相似度高而不同簇间的样本相似度低。本周学习了聚类的性能度量指标,包括内部和外部指标,如Jaccard系数、Rand指数、DB指数等,并介绍了几种常见的距离计算方法。此外,深入学习了几种原型聚类算法:k均值、学习向量量化(LVQ)以及高斯混合模型(GMM),并以K-means算法为例,通过鸢尾花数据集进行了实战演示。
abstract
Clustering is an important task in unsupervised learning, which aims to divide a data set into several subsets (clusters) so that samples within the same cluster have high similarity while samples between different clusters have low similarity. This week you studied the performance metrics of clustering, including internal and external metrics such as Jaccard coefficient, Rand index, DB index, etc., and introduced several common distance calculation methods. In addition, several prototype clustering algorithms, including K-means, learning vector Quantization (LVQ) and Gaussian mixture model (GMM), are deeply learned, and K-Means algorithm is taken as an example to demonstrate through iris data set.
1.聚类任务
- 在无监督学习任务中研究最多、应用最广。
- 聚类目标:将数据集中的样本划分为若干个通常不相交的子集(cluster)
- 聚类既可以作为一个单独的过程(用于寻找数据内在的分布结构),也可以作为分类等其他学习任务的前驱过程。
2.性能度量
直观来说:聚类结果的”簇内相似度“高,且簇间相似度低,这样的聚类结果效果较好。
2.1聚类性能度量指标
对于数据集
D
=
{
x
1
,
x
2
,
…
,
x
m
}
D=\{x_{1},x_{2},\ldots,x_{m}\}
D={x1,x2,…,xm},假定通过聚类得到的簇划分为
C
=
{
C
1
,
C
2
,
…
,
C
k
}
C=\{C_{1},C_{2},\ldots,C_{k}\}
C={C1,C2,…,Ck},参考模型给出的簇划分为
C
∗
=
{
C
1
∗
,
C
2
∗
,
…
,
C
s
∗
}
{C^{*}}=\{C_{1}^{*},C_{2}^{*},\ldots,C_{s}^{*}\}
C∗={C1∗,C2∗,…,Cs∗}.同时
λ
\lambda
λ和
λ
∗
\lambda^{*}
λ∗分别表示
C
C
C和
C
∗
C^{*}
C∗对应的簇标记向量.
将样本两两配对考虑,定义为:
a
=
∣
S
S
∣
,
S
S
=
{
(
x
i
,
x
j
)
∣
λ
i
=
λ
j
,
λ
i
∗
=
λ
j
∗
,
i
<
j
}
b
=
∣
S
D
∣
,
S
D
=
{
(
x
i
,
x
j
)
∣
λ
i
=
λ
j
,
λ
i
∗
≠
λ
j
∗
,
i
<
j
}
c
=
∣
D
S
∣
,
D
S
=
{
(
x
i
,
x
j
)
∣
λ
i
≠
λ
j
,
λ
i
∗
=
λ
j
∗
,
i
<
j
}
d
=
∣
D
D
∣
,
D
D
=
{
(
x
i
,
x
j
)
∣
λ
i
≠
λ
j
,
λ
i
∗
≠
λ
j
∗
,
i
<
j
}
\begin{gathered} a=|SS|,SS=\{(x_{i},x_{j})|\lambda_{i}=\lambda_{j},\lambda_{i}^{*}=\lambda_{j}^{*},i<j\} \\ b=|SD|,SD=\{(x_{i},x_{j})|\lambda_{i}=\lambda_{j},\lambda_{i}^{*}\neq\lambda_{j}^{*},i<j\} \\ c=|DS|,DS=\{(x_{i},x_{j})|\lambda_{i}\neq\lambda_{j},\lambda_{i}^{*}=\lambda_{j}^{*},i<j\} \\ d=|DD|,DD=\{(x_{i},x_{j})|\lambda_{i}\neq\lambda_{j},\lambda_{i}^{*}\neq\lambda_{j}^{*},i<j\} \end{gathered}
a=∣SS∣,SS={(xi,xj)∣λi=λj,λi∗=λj∗,i<j}b=∣SD∣,SD={(xi,xj)∣λi=λj,λi∗=λj∗,i<j}c=∣DS∣,DS={(xi,xj)∣λi=λj,λi∗=λj∗,i<j}d=∣DD∣,DD={(xi,xj)∣λi=λj,λi∗=λj∗,i<j}
a+b+c+d = m*(m-1)/2;
2.1.1外部指标
将聚类结果与某个”参考模型“进行比较。
- Jaccard系数: J C = a a + b + c JC=\frac a{a+b+c} JC=a+b+ca
- FM指数: F M I = a a + b ⋅ a a + c FMI=\sqrt{\frac a{a+b}\cdot\frac a{a+c}} FMI=a+ba⋅a+ca
- Rand指数:
R
I
=
2
(
a
+
b
)
m
(
m
−
1
)
RI=\frac{2(a+b)}{m(m-1)}
RI=m(m−1)2(a+b)
系数和指数越大其聚类结果效果越好,公式中对于d而言没有太大意义
2.1.2内部指标:直接考察聚类结果而不用任何参考模型。
考虑聚类结果的簇划分
C
=
{
C
1
,
C
2
,
…
,
C
k
}
C=\{C_{1},C_{2},\ldots,C_{k}\}
C={C1,C2,…,Ck},定义簇C内样本间的平均距离:
a
v
g
(
C
)
=
2
∣
C
∣
(
∣
C
∣
−
1
)
∑
1
≤
i
≤
j
≤
∣
C
∣
d
i
s
t
(
x
i
,
x
j
)
avg(C)=\frac{2}{|C|(|C|-1)}\sum_{1\leq i\leq j\leq|C|}dist(x_i,x_j)
avg(C)=∣C∣(∣C∣−1)21≤i≤j≤∣C∣∑dist(xi,xj)
- DB指数:
D B I = 1 k ∑ i = 1 k max j ≠ i ( a v g ( C i ) + a v g ( C j ) d c e n ( μ i , μ j ) ) DBI=\frac{1}{k}\sum_{i=1}^{k}\max_{j\neq i}\left(\frac{avg(C_{i})+avg(C_{j})}{d_{cen}(\mu_{i},\mu_{j})}\right) DBI=k1i=1∑kj=imax(dcen(μi,μj)avg(Ci)+avg(Cj))
越小越好 (也就是簇与簇之间的距离也大同时每个簇的平均距离越小使得聚类结果更好) - Dunn指数
D I = min 1 ≤ i ≤ k { min j ≠ i ( d m i n ( C i , C j ) max 1 ≤ l ≤ k d i a m ( C l ) ) } DI=\min_{1\leq i\leq k}\left\{\min_{j\neq i}\left(\frac{d_{min}(C_i,C_j)}{\max_{1\leq l\leq k}diam(C_l)}\right)\right\} DI=1≤i≤kmin{j=imin(max1≤l≤kdiam(Cl)dmin(Ci,Cj))}
越大越好 (两个簇的最小距离越大越好同时簇之间的距离越小越好,整体越大越好)
3.距离计算
常用距离:
- Minkowski distance:
d i s t ( x i , x j ) = ( ∑ u = 1 n ∣ x i u − x j u ∣ p ) 1 p dist(x_i,x_j)=\left(\sum_{u=1}^n|x_{iu}-x_{ju}|^p\right)^{\frac1p} dist(xi,xj)=(u=1∑n∣xiu−xju∣p)p1
p=1:曼哈顿距离;p=2为欧式距离 - Value Difference Metric (处理无序属性)
若mu,a表示属性a上取值为u的样本数,mu,a,i表示在第i个样本簇中在属性a上取值为u的样本数,k为样本簇数,则属性u上两个离散值a和b之间的VDM距离为:
V D M p ( a , b ) = ∑ i = 1 k ∣ m u , a , i m u , a − m u , b , i m u , b ∣ p VDM_p(a,b)=\sum_{i=1}^k\left|\frac{m_{u,a,i}}{m_{u,a}}-\frac{m_{u,b,i}}{m_{u,b}}\right|^p VDMp(a,b)=i=1∑k mu,amu,a,i−mu,bmu,b,i p - 处理混合属性
M i n k o v D M p ( x i , x j ) = ( ∑ u = 1 n c ∣ x i u − x j u ∣ p + ∑ u = n c + 1 n V D M p ( x i u , x j u ) ) 1 p MinkovDM_p(x_i,x_j)=\left(\sum_{u=1}^{n_c}|x_{iu}-x_{ju}|^p+\sum_{u=n_c+1}^nVDM_p(x_{iu},x_{ju})\right)^{\frac{1}{p}} MinkovDMp(xi,xj)=(u=1∑nc∣xiu−xju∣p+u=nc+1∑nVDMp(xiu,xju))p1 - 加权距离(样本中不同属性的重要性不同时)
d i s t ( x i , x j ) = ( ω 1 ⋅ ∣ x i 1 − x j 1 ∣ p + ⋯ + ω n ⋅ ∣ x i n − x j n ∣ p ) 1 p ω i ≥ 0 , ∑ i = 1 n ω i = 1 dist(x_{i},x_{j})=(\omega_{1}\cdot|x_{i1}-x_{j1}|^{p}+\cdots+\omega_{n}\cdot|x_{in}-x_{jn}|^{p})^{\frac{1}{p}}\\\omega_{i}\geq0,\sum_{i=1}^{n}\omega_{i}=1 dist(xi,xj)=(ω1⋅∣xi1−xj1∣p+⋯+ωn⋅∣xin−xjn∣p)p1ωi≥0,i=1∑nωi=1
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
plt.figure(figsize=(12, 12))
n_samples = 1500
random_state = 170
X, y = make_blobs(n_samples=n_samples, random_state=random_state)
# Incorrect number of clusters
y_pred = KMeans(n_clusters=2, random_state=random_state).fit_predict(X)
plt.subplot(221)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.title("Incorrect Number of Blobs")
# 各向异性分布的斑点
# X坐标变换
transformation = [[0.60834549, -0.63667341], [-0.40887718, 0.85253229]]
X_aniso = np.dot(X, transformation) #矩阵相乘
y_pred = KMeans(n_clusters=3, random_state=random_state).fit_predict(X_aniso)
plt.subplot(222)
plt.scatter(X_aniso[:, 0], X_aniso[:, 1], c=y_pred)
plt.title("Anisotropically Distributed Blobs")
#Unequal Variance 不均衡方差导致的问题
X_varied, y_varied = make_blobs(n_samples=n_samples,
cluster_std=[1.0, 2.5, 0.5],
random_state=random_state)
y_pred = KMeans(n_clusters=3, random_state=random_state).fit_predict(X_varied)
plt.subplot(223)
plt.scatter(X_varied[:, 0], X_varied[:, 1], c=y_pred)
plt.title("Unequal Variance")
#Unevenly Sized 数据分布不均匀问题
X_filtered = np.vstack((X[y == 0][:500], X[y == 1][:100], X[y == 2][:10]))
y_pred = KMeans(n_clusters=3, random_state=random_state).fit_predict(X_filtered)
plt.subplot(224)
plt.scatter(X_filtered[:, 0], X_filtered[:, 1], c=y_pred)
plt.title("Unevenly Sized Blobs")
plt.show()
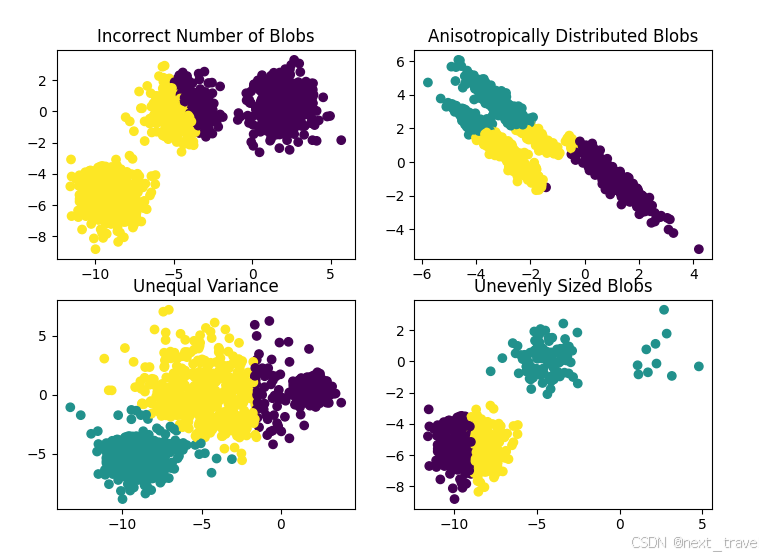
左上角图中,Blobs数据集一共有三个簇,但是k-means中规定为两个簇大小,导致错误的簇划分;右上角图中,由于k-means的特点,按照距离来判断是否属于同一类别,经过坐标变换后的簇分类出错;左下角图中,由于不均衡方差导致的簇划分出现问题;右下图中,数据过于分散,对于整体的分类影响不大。
4.原型聚类
- 原型聚类“基于原型的聚类”,此类算法假设聚类结构能通过一组原型刻画。
- 算法过程:算法先对原型进行初始化,再对原型进行迭代更新求解。
著名的原型聚类算法:k均值算法、学习向量量化算法、高斯混合聚类算法。
4.1k均值算法
对于数据集
D
=
{
x
1
,
x
2
,
…
,
x
m
}
D=\{x_{1},x_{2},\ldots,x_{m}\}
D={x1,x2,…,xm},k均值算法针对聚类的簇划分为
C
=
{
C
1
,
C
2
,
…
,
C
k
}
C=\{C_{1},C_{2},\ldots,C_{k}\}
C={C1,C2,…,Ck},最小化平方误差为:
E
=
∑
i
=
1
k
∑
x
∈
C
i
∥
x
−
μ
i
∥
2
2
E=\sum_{i=1}^k\sum_{x\in C_i}\|x-\mu_i\|_2^2
E=i=1∑kx∈Ci∑∥x−μi∥22,
μ
i
\mu_i
μi是簇Ci的均值向量。
E一定程度上反应了簇内样本围绕簇均值向量的紧密程度。
伪代码

4.2学习向量量化
学习向量量化(Learning Vector Quantization,LVQ)与一般聚类算法不同是LVQ假设样本中带有类别标记,学习过程中利用样本的这些监督信息来辅助聚类。
给定样本集
D
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
⋯
,
(
x
m
,
y
m
)
}
D=\{(x_1,y_1) ,(x_2,y_2) ,\cdots,(x_m,y_m)\}
D={(x1,y1),(x2,y2),⋯,(xm,ym)},LVQ的目的是学得一组n维原型向量{p1,p2,…,pn},每个原型向量代表一个聚类簇。常用于发现类别的“子类”结构。
量化过程

4.3高斯混合聚类
与k均值、LVQ用原型向量来刻画聚类结构不同,高斯混合聚类采用概率模型来表达聚类原型:
p
(
x
)
=
1
(
2
π
)
n
2
∣
Σ
∣
1
2
e
−
1
2
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
p(x)=\frac{1}{(2\pi)^{\frac{n}{2}}|\Sigma|^{\frac{1}{2}}}e^{-\frac{1}{2}(x-\mu)^{T}\Sigma^{-1}(x-\mu)}
p(x)=(2π)2n∣Σ∣211e−21(x−μ)TΣ−1(x−μ)
其中
μ
\mu
μ是n维均值向量,
Σ
\Sigma
Σ是n*n的协方差矩阵。
高斯混合分布的定义:
p
M
(
x
)
=
∑
i
=
1
k
α
i
p
(
x
∣
μ
i
,
Σ
i
)
p_M(x)=\sum_{i=1}^k\alpha_ip(x|\mu_i,\Sigma_i)
pM(x)=i=1∑kαip(x∣μi,Σi)
该分布由k个混合分布组成,每个分布对应一个高斯分布。而
α
i
\alpha_i
αi为相应的“混合系数”,且
∑
i
=
1
k
α
i
=
1
\sum_{i=1}^k\alpha_i=1
i=1∑kαi=1
模型求解:最大化(对数)似然作用-----找到一组参数θ,使得整个数据集
D
=
{
x
1
,
x
2
,
…
,
x
m
}
D=\{x_{1},x_{2},\ldots,x_{m}\}
D={x1,x2,…,xm}出现的概率最大。
L
L
(
D
)
=
ln
(
∏
j
=
1
m
p
M
(
x
j
)
)
=
∑
j
=
1
m
ln
(
∑
i
=
1
k
α
i
⋅
p
(
x
j
∣
μ
i
,
Σ
i
)
)
\begin{aligned} LL(D)& =\ln\left(\prod_{j=1}^mp_M(x_j)\right) \\ &=\sum_{j=1}^{m}\ln\left(\sum_{i=1}^{k}\alpha_{i}\cdot p\left(x_{j}|\mu_{i},\Sigma_{i}\right)\right) \end{aligned}
LL(D)=ln(j=1∏mpM(xj))=j=1∑mln(i=1∑kαi⋅p(xj∣μi,Σi))
令
∂
L
L
(
D
)
∂
μ
i
=
0
⟶
μ
i
=
∑
j
=
1
m
γ
j
i
x
j
∑
j
=
1
m
γ
j
i
∂
L
L
(
D
)
∂
Σ
i
=
0
⟶
Σ
i
=
∑
j
=
1
m
γ
j
i
(
x
j
−
μ
i
)
(
x
j
−
μ
i
)
T
∑
j
=
1
m
γ
j
i
\begin{aligned}&\frac{\partial LL(D)}{\partial\mu_{i}}=0\longrightarrow\quad\mu_{i}=\frac{\sum_{j=1}^{m}\gamma_{ji}x_{j}}{\sum_{j=1}^{m}\gamma_{ji}}\\&\frac{\partial LL(D)}{\partial\Sigma_{i}}=0\quad\longrightarrow\quad\Sigma_{i}=\frac{\sum_{j=1}^{m}\gamma_{ji}(x_{j}-\mu_{i})(x_{j}-\mu_{i})^{T}}{\sum_{j=1}^{m}\gamma_{ji}}\end{aligned}
∂μi∂LL(D)=0⟶μi=∑j=1mγji∑j=1mγjixj∂Σi∂LL(D)=0⟶Σi=∑j=1mγji∑j=1mγji(xj−μi)(xj−μi)T
高斯混合聚类过程
对于
α
i
\alpha_i
αi 可通过拉普拉斯和拉格朗日求得 有
∑
i
=
1
k
α
i
=
1
\sum_{i=1}^k\alpha_i=1
∑i=1kαi=1进一步算出每个
α
i
\alpha_i
αi。

5.实战
实现一个简单的K-means聚类算法来处理鸢尾花(Iris)数据集,并可视化聚类中心和原始数据分布在sklearn聚类结果的对比:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.cluster import KMeans
from sklearn.metrics import pairwise_distances_argmin_min
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data[:, :2] # 只取前两个特征以便于可视化
y = iris.target
# 定义K-means参数
n_clusters = 3
max_iter = 100
tol = 1e-4
# 随机初始化聚类中心
np.random.seed(0)
centers = X[np.random.choice(X.shape[0], n_clusters, replace=False)]
# K-means迭代更新
for i in range(max_iter):
# 分配最近的聚类中心
closest, _ = pairwise_distances_argmin_min(X, centers)
# 更新聚类中心
new_centers = np.array([X[closest == k].mean(axis=0) for k in range(n_clusters)])
# 检查收敛性
if np.sum(np.abs(new_centers - centers)) < tol:
break
centers = new_centers
# 使用sklearn KMeans进行对比
kmeans = KMeans(n_clusters=n_clusters, random_state=0).fit(X)
# 绘制结果
plt.figure(figsize=(12, 6))
# 左边是自定义K-means的结果
plt.subplot(1, 2, 1)
plt.scatter(X[:, 0], X[:, 1], c=closest, s=50, cmap='viridis')
plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, alpha=0.75, marker='x')
plt.title('Custom K-Means Clustering')
# 右边是sklearn KMeans的结果
plt.subplot(1, 2, 2)
plt.scatter(X[:, 0], X[:, 1], c=kmeans.labels_, s=50, cmap='viridis')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], c='red', s=200, alpha=0.75, marker='x')
plt.title('Sklearn K-Means Clustering')
plt.show()
6.总结
本周学习了机器学习中聚类任务的基础概念与主要方法,强调了在无监督场景下发现数据内在结构的重要性。不仅覆盖了聚类结果的质量评估手段,还详述了多种聚类算法,特别是基于原型的k均值、LVQ及GMM算法。最后,通过实际编码示例展示了如何使用K-means对鸢尾花数据进行聚类分析,并与标准库实现进行了对比。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 机器学习中的聚类

发表评论 取消回复