集群搭建
参考:
使用 Docker-Compose
这里提供一个脚本来使用 docker-compose 完成RabbitMQ集群的配置及启动
docker-compose.yml 文件如下
#!/bin/bash
# 定义 RabbitMQ 用户名、密码和 Erlang Cookie
RABBITMQ_USER="guest"
RABBITMQ_PASS="guest"
ERLANG_COOKIE="secret_cookie"
# 创建 docker-compose.yml 文件
cat << EOF > docker-compose.yml
version: '3.8'
services:
rabbitmq1:
image: rabbitmq:3-management
hostname: rabbitmq1
environment:
RABBITMQ_DEFAULT_USER: $RABBITMQ_USER
RABBITMQ_DEFAULT_PASS: $RABBITMQ_PASS
ports:
- "15671:15672" # Management UI
- "5671:5672" # RabbitMQ
volumes:
- ./rabbitmq1/data:/var/lib/rabbitmq
- ./rabbitmq1/etc/rabbitmq:/etc/rabbitmq
networks:
- rabbitmq-net
rabbitmq2:
image: rabbitmq:3-management
hostname: rabbitmq2
environment:
RABBITMQ_DEFAULT_USER: $RABBITMQ_USER
RABBITMQ_DEFAULT_PASS: $RABBITMQ_PASS
ports:
- "15672:15672" # Management UI
- "5672:5672" # RabbitMQ
volumes:
- ./rabbitmq2/data:/var/lib/rabbitmq
- ./rabbitmq2/etc/rabbitmq:/etc/rabbitmq
networks:
- rabbitmq-net
rabbitmq3:
image: rabbitmq:3-management
hostname: rabbitmq3
environment:
RABBITMQ_DEFAULT_USER: $RABBITMQ_USER
RABBITMQ_DEFAULT_PASS: $RABBITMQ_PASS
ports:
- "15673:15672" # Management UI
- "5673:5672" # RabbitMQ
volumes:
- ./rabbitmq3/data:/var/lib/rabbitmq
- ./rabbitmq3/etc/rabbitmq:/etc/rabbitmq
networks:
- rabbitmq-net
networks:
rabbitmq-net:
EOF
echo "docker-compose.yml 文件已创建。"
# 创建节点目录结构
for i in {1..3}; do
mkdir -p rabbitmq$i/data rabbitmq$i/etc/rabbitmq
echo "NODENAME=rabbit@rabbitmq$i" > ./rabbitmq$i/etc/rabbitmq/rabbitmq-env.conf
echo "$ERLANG_COOKIE" > ./rabbitmq$i/etc/rabbitmq/.erlang.cookie
chmod 400 ./rabbitmq$i/etc/rabbitmq/.erlang.cookie # 设置权限为 400
done
echo "各节点的配置文件已创建。"
# 启动 Docker Compose
docker-compose up -d
# 等待 RabbitMQ 启动
sleep 10
# 将节点加入集群
docker exec -it rabbitmq2 rabbitmqctl stop_app
docker exec -it rabbitmq2 rabbitmqctl join_cluster rabbit@rabbitmq1
docker exec -it rabbitmq2 rabbitmqctl start_app
docker exec -it rabbitmq3 rabbitmqctl stop_app
docker exec -it rabbitmq3 rabbitmqctl join_cluster rabbit@rabbitmq1
docker exec -it rabbitmq3 rabbitmqctl start_app
# 显示集群状态
docker exec -it rabbitmq1 rabbitmqctl cluster_status
echo "RabbitMQ 集群已成功启动。"
使用方式:
复制脚本内容到指定脚本文件,例如rabbitmq_cluster.sh,添加执行权限并执行
脚本解释
Erlang节点之间通过认证Erlang Cookie的方式来允许互相通信,所以要确保在每个节点中使用相同的 RABBITMQ_ERLANG_COOKIE 值,以便它们能够相互通信。新版本已经不建议通过环境变量设置 Erlang Cookie 了,会有警告信息
RABBITMQ_ERLANG_COOKIE env variable support is deprecated and will be REMOVED in a future version. Use the $HOME/.erlang.cookie file or the --erlang-cookie switch instead.
,建议在 home 目录下新建 .erlang.cookie 文件,在 每个节点的 .erlang.cookie 写入一致的字符串,注意 .erlang.cookie 文件的权限应该为 400。所以为了便于修改ErlangCookie,启动容器时要做好容器数据卷的映射。因为 /var/lib/rabbitmq 是 RabbitMQ home 目录和 data 目录,所以需要映射到宿主机
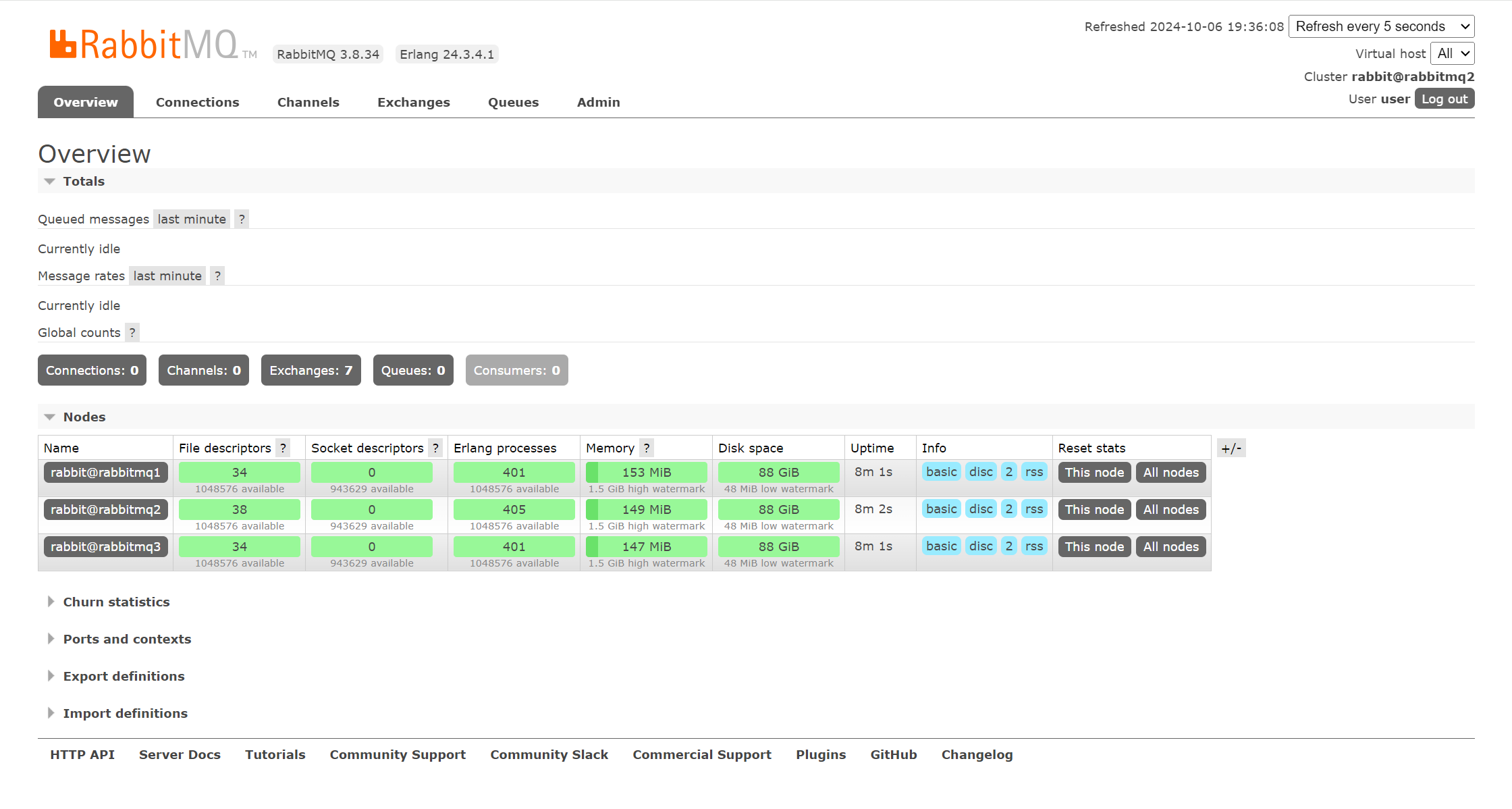
启动成功后:访问WEB控制台界面
镜像队列
如果 RabbitMQ 集群中只有一个 Broker 节点,那么该节点的失效将导致整体服务的临时性不可用,并且也可能会导致消息的丢失。可以将所有消息都设置为持久化,并且对应队列的durable属性也设置为true,但 是这样仍然无法避免由于缓存导致的问题:因为消息在发送之后和被写入磁盘井执行刷盘动作之间存在一 个短暂却会产生问题的时间窗。通过 publisherconfirm(发布确认) 机制能够确保客户端知道哪些消息己经存入磁盘,尽 管如此,一般不希望遇到因单点故障导致的服务不可用。
引入镜像队列(Mirror Queue)的机制,可以将队列镜像到集群中的其他 Broker 节点之上,如果集群中 的一个节点失效了,队列能自动地切换到镜像中的另一个节点上以保证服务的可用性。
搭建步骤
- 启动三台集群节点
- 随便找一个节点添加 policy(策略)
找到 Policies 部分。
点击 Add / update a policy 按钮。
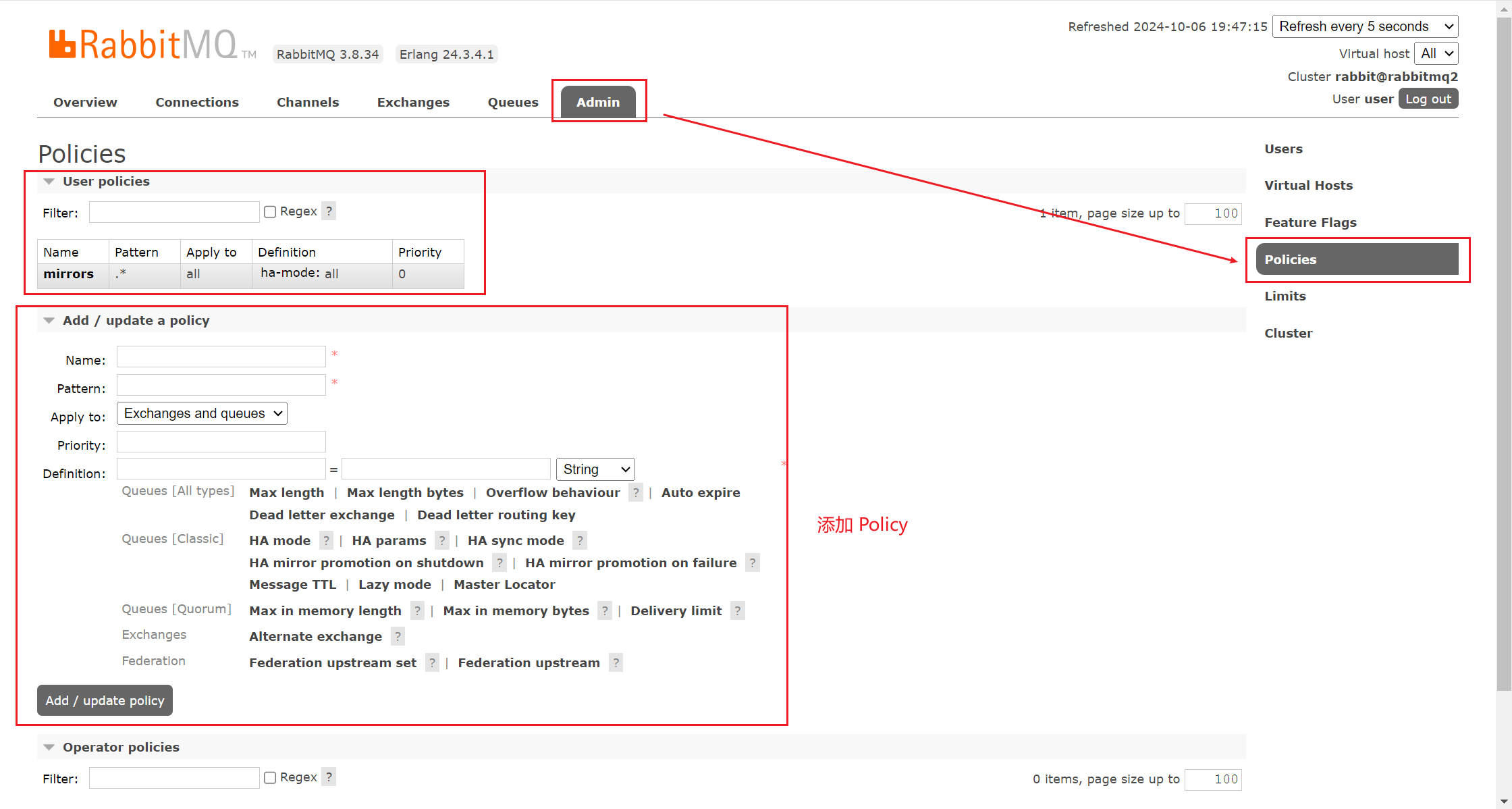
参数解释:
- Name: policy的名称,用户自定义。
- Pattern: queue的匹配模式(正则表达式)。^表示所有队列都是镜像队列。
- Definition: 镜像定义,包括三个部分ha-sync-mode、ha-mode、ha-params。
ha-mode: 指明镜像队列的模式,有效取值范围为all/exactly/nodes。
- all:表示在集群所有的代理上进行镜像。
- exactly:表示在指定个数的代理上进行镜像,代理的个数由ha-params指定。
- nodes:表示在指定的代理上进行镜像,代理名称通过ha-params指定。
ha-params: ha-mode模式需要用到的参数。
ha-sync-mode: 表示镜像队列中消息的同步方式,有效取值范围为:automatic,manually。
- automatic:表示自动向master同步数据。
- manually:表示手动向master同步数据。
Priority: 可选参数, policy的优先级。
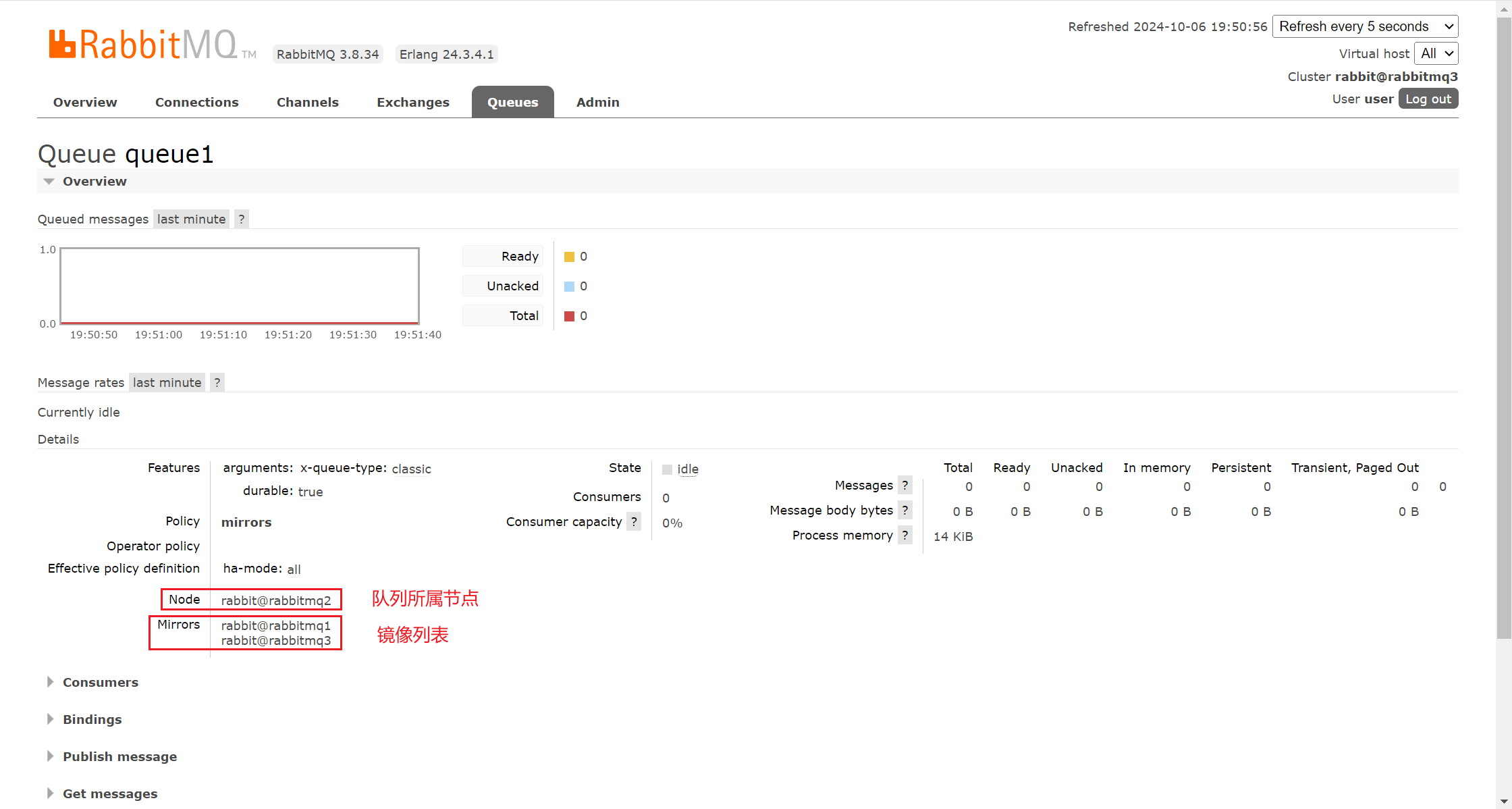
在 rabbitmq2 上创建一个队列发送一条消息,队列存在镜像队列,如下图所示:
工作原理
https://www.rabbitmq.com/docs/3.13/ha#what-is-mirroring
多个RabbitMQ节点组成镜像队列的情况下,有一个节点会作为主节点,其他的节点就是从节点,也就是其镜像队列。镜像队列其是就是从节点的概念。
对主节点的写操作会被复制到其他镜像队列上,slave会准确地按照master执行命令的顺序进行命令执行,故slave与master上维护的状态应该是相同的。
故障转移:如果持有队列主副本的节点发生故障,RabbitMQ 会自动将一个镜像副本提升为新的主副本,从而确保消息的可用性。
优缺点
优点:
- 高可用性:通过在多个节点上维护队列副本,确保即使某个节点故障,消息仍然可用。
- 故障转移:故障发生时可以快速切换到其他节点,减少服务中断。
缺点: - 资源消耗:镜像队列会消耗更多的内存和存储资源,因为每个消息都需要在多个节点上存储副本。
- 性能开销:在高负载情况下,消息复制可能导致性能下降,增加网络流量和延迟。
使用镜像策略的注意事项
在设计系统时,必须权衡高可用性和资源消耗之间的平衡。
定期监控队列和节点的状态,以确保镜像队列正常运行。
根据业务需求灵活设置镜像策略,确保系统在不同场景下的可靠性和性能。
通过合理配置镜像策略,您可以在 RabbitMQ 集群中实现高可用性和容错能力,确保消息在故障情况下的可用性。
镜像策略
RabbitMQ 的镜像策略(也称为高可用性策略)用于确保队列在集群中的高可用性和容错性。镜像队列会在多个节点上维护相同的队列副本,这样即使某个节点发生故障,其他节点仍然可以提供服务。以下是关于镜像策略的详细解释:
- 通过管理控制台设置
- 通过 rabbitmqctl 命令行工具设置
rabbitmqctl set_policy ha-all "^.*" '{"ha-mode":"all"}'
镜像策略的类型
ha-mode:
- all: 所有队列副本都在集群中的所有节点上。
- exactly: 指定每个队列应该有的副本数量。
- nodes: 指定特定的节点列表作为镜像副本。
ha-params:与 ha-mode 配合使用的参数,具体含义取决于 ha-mode 的选择。
主从同步
rabbitmq的主从复制是异步的,但是rabbitmq并不存在mysql这种场景的丢数据(这句话不是说rabbitmq保证不丢数据)。在这里,我们来分析一下RabbitMQ的副本复制的过程。
首先,我们来说一下mysql和rabbitmq的使用接口是不同的,这时很关键的一点。mysql是同步的接口,也就是说client将sql发给server,server处理sql后将结果返回给client,在server返回client结果前,client不能发起下一个sql的请求。对于rabbitmq来说,访问接口是异步的。client(我们这里说的是publisher)向rabbitmq server publish一条消息,在默认的情况下server是不返回成功还是失败的,也就是说client在不到成功还是失败的情况下就可以发起下一个请求。如果client关心server是否成功处理完这条消息,可以开启confirm模式,server会异步的返回ack通知client消息投递成功还是失败。但是client仍然不必等待收到当前消息的ack就可以继续发下一条。
接下来,我们来说rabbitmq的主从复制过程。实际上,RabbitMQ主从之间的数据复制是异步的,但是在rabbitmq中不会出现mysql那种丢数据的情况,这是因为rabbitmq的接口也是异步的,主收到一条消息写入本地存储,然后在发起写入从的请求。当所有从写入成功后,主才会给client返回ack说这次写入成功了。所以可以看出,虽然rabbitmq的主从复制是异步的,但是并且不会出现mysql丢数据的场景。只要客户端收到ack,就说明这条消息已经写入主和从了。
所以需要强调的一点是,同步和异步并非是决定数据可靠性的关键点。客户端收到成功通知时,所有副本是否写入成功才是判断数据可靠的关键点。因为mysql的接口是同步,所以才需要在主从复制同步还是异步上做出选择。rabbitmq的接口本身就是异步的接口,所以rabbitmq的主从复制就自然而然的是异步的方式。
同步延迟
在 RabbitMQ 中,同步延迟可能会影响消息的处理速度和系统的整体性能。以下是一些常见的解决方案和优化策略,可以帮助减少 RabbitMQ 的同步延迟:
- 优化网络配置
网络带宽:确保 RabbitMQ 节点之间有足够的带宽,特别是在高负载情况下。考虑使用更快的网络连接。
网络延迟:尽量将 RabbitMQ 节点部署在同一数据中心内,以减少网络延迟。 - 调整队列和镜像策略
使用适当的镜像策略:
如果不需要所有节点都有队列的镜像,可以选择 ha-mode 设置为 exactly 或 nodes,以减少复制的数量。
如果只需要部分节点有镜像,可以指定特定的节点。
减少镜像数量:尽量减少每个队列的镜像副本数量,权衡高可用性和性能之间的关系。 - 使用流控
设置队列流控:可以通过设置 x-max-length 或 x-max-length-bytes 限制队列的最大长度或大小,从而防止队列过长导致的延迟。 - 增加消费者数量
水平扩展消费者:增加消费者实例的数量,确保消息能够更快地被处理和确认。确保消费者能够在多个节点上并行运行。 - 优化消息处理
提高消息处理效率:检查消费者的处理逻辑,确保消息处理尽可能高效,避免在处理过程中出现瓶颈。
批量处理消息:考虑使用批量确认(basic.ack)而不是单个确认,以减少确认的开销。 - 监控和调试
使用监控工具:利用 RabbitMQ 的监控插件或其他监控工具(如 Prometheus、Grafana)监控系统性能,识别瓶颈。
分析日志:查看 RabbitMQ 日志,识别可能导致延迟的错误或警告。 - 资源和配置优化
调整 RabbitMQ 配置:根据系统需求调整 RabbitMQ 的配置参数,如内存、磁盘和 CPU 使用情况。
增加节点资源:确保 RabbitMQ 节点有足够的 CPU 和内存资源,避免因资源不足导致的性能下降。 - 使用持久化
选择适当的持久化策略:在消息持久化与性能之间进行权衡,确保消息持久化不会对性能产生负面影响。 - 负载均衡
使用负载均衡策略:在多个消费者之间分配负载,确保没有单个消费者过载,从而提高处理能力。
通过上述方法,您可以有效减少 RabbitMQ 的同步延迟,并提高系统的整体性能和可靠性。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » RabbitMQ 集群

发表评论 取消回复