文章基本信息
作者:
- 王鹏飞
- 魏宗正
- 周东生
- 宋威
- 肖蕴明
- 孙庚
- 于硕
- 张强
机构:
- 大连理工大学计算机科学与技术学院
- 大连理工大学社会计算与认知智能教育部重点实验室
- 大连大学先进设计与智能计算教育部重点实验室
- 美国西北大学计算机科学系
- 吉林大学计算机科学与技术学院
- 吉林大学符号计算与知识工程教育部重点实验室
期刊:计算机学报
发表时间:2023 年 11 月 28 日
解决问题:对目前现有的联邦忘却学习工作进行了综述。
代码:综述无代码
文章:http://cjc.ict.ac.cn/online/onlinepaper/wpf-202431151459.pdf
摘要
数据已经成为与土地、劳动力、资本、技术等并列的重要生产要素之一. 利用数据分析挖掘数据的潜在 价值,有助于推动产业创新、技术升级和区域经济发展. 然而,在数据使用过程中,隐私泄露等风险限制了数据的 流通和共享. 因此,如何在数据流通和共享过程中保护数据隐私已成为研究热点. 联邦忘却学习(Federated Un⁃ learning)撤销用户数据对联邦学习模型的训练更新,可以进一步保护联邦学习用户的数据安全. 本文综述了联 邦忘却学习的研究工作,首先简要阐述了联邦学习架构,并引出忘却学习和联邦忘却学习的概念和定义;其次, 根据修正对象的不同将联邦忘却学习算法分为面向全局模型和面向局部模型两类,并详细分析各类算法的实现 细节以及优缺点;然后,本文还详述联邦忘却学习中常用评价指标,将评价指标划分为模型表现指标、遗忘效果 指标和隐私保护指标三类,并分析不同类型评价指标的优缺点;最后,本文对联邦忘却学习未来的研究方向进行 展望.
文章结构
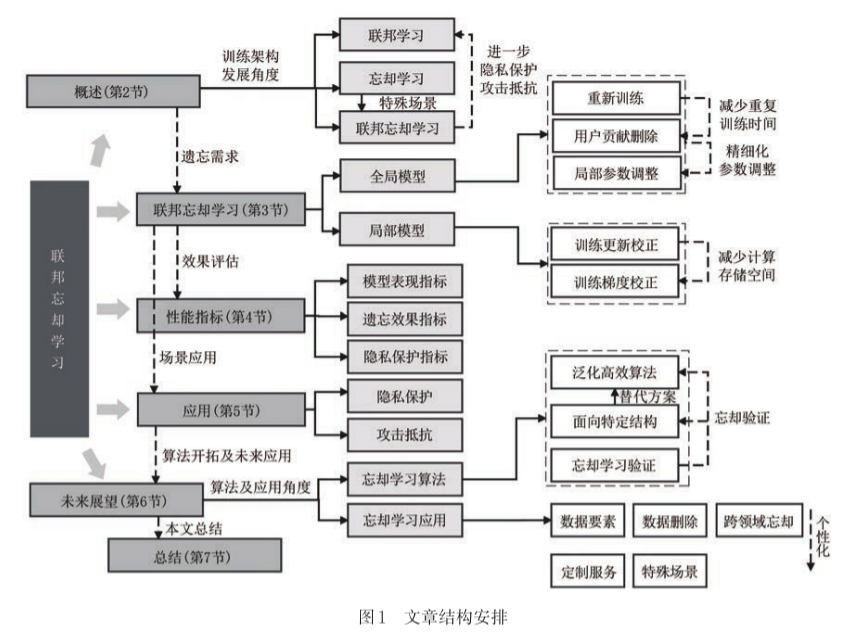
引言
引言部分介绍了目前数据的流通共享存在隐私泄露的问题,并且指出了目前的一些解决方案如同态加密、多方安全计算等技术的复杂性。引出了联邦学习,而联邦学习存在模型推断攻击的问题,再引出联邦忘却学习。
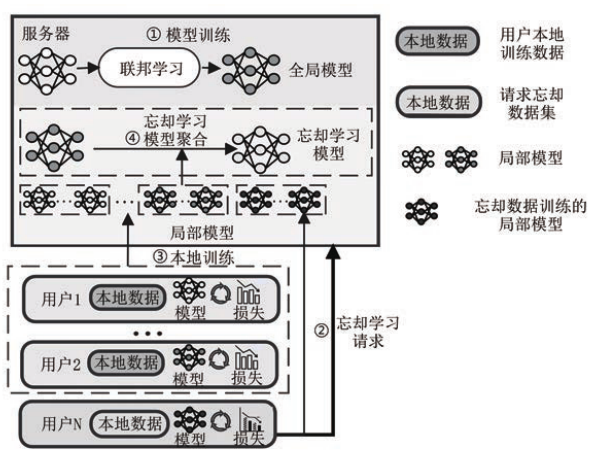
联邦忘却学习概述
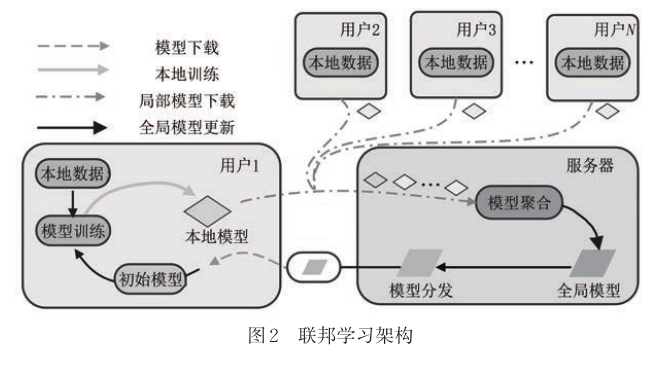
联邦学习
这一部分介绍了联邦学习的流程,以及联邦学习的形式化描述,具体可以看原文。
忘却学习
忘却学习的核心在于通过调整模型参数,实现与特定数据未参与训练相同的效果,同时避免完全的重复性训练。忘却学习的难度取决于不同的机器学习场景,即不同的数据访问权限。
机器忘却学习(Machine Unlearning)不受隐私保护或数据加密的限制,将所有训练数据集中处理,对特定数据进行忘却学习。机器忘却学习方向:
- 根据数量:
- 小样本忘却学习:指被遗忘数据样本量极小,如 3-5 张图片。
- 根据模型:
- 回归模型忘却
- 推荐模型忘却
- 根据需求:
- 快速忘却学习
- 根据隐私需求:
- 零次观察忘却:不允许使用请求遗忘的数据,只能利用剩余训练数据。
- 零样本忘却:所有参与训练的数据都无法访问,只能在数据不可见的情况下进行忘却学习。
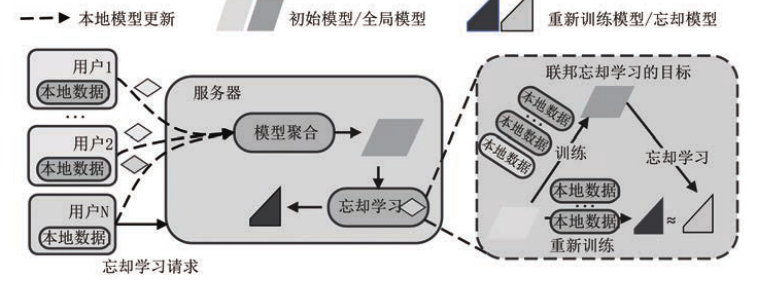
联邦忘却学习
**联邦忘却学习是零样本忘却学习的一个特例,**联邦学习场景不仅无法直接获取数据信息,而且数据还分布在不同用户的手中。然而联邦忘却学习符合现实世界的数据管理模式,所以很有研究价值。
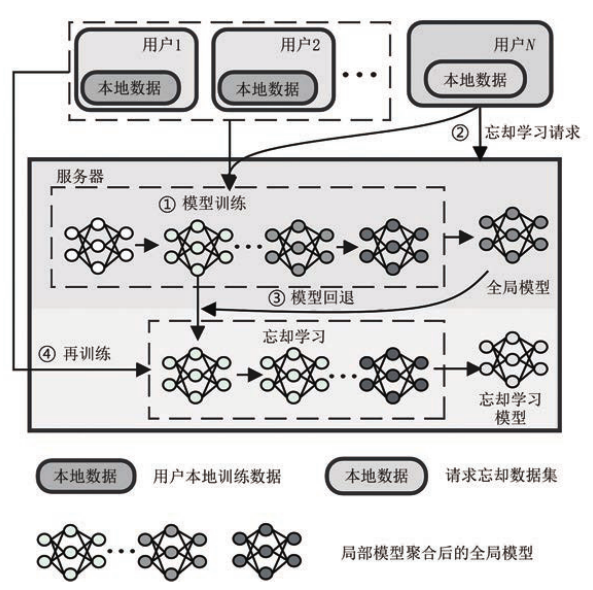
联邦忘却学习流程
联邦忘却学习流程:
- 正常进行联邦学习
- 在任意时刻,某一个用户提交撤销数据请求
- 中心服务器需要完成任务:使用忘却算法得到的全局模型分布和使用除去这个用户的数据以外数据集训练得到的全局模型分布一致。
- 完成数据撤销请求
- 服务器继续进行联邦学习
联邦忘却学习粒度
- 样本忘却:从联邦学习模型中撤销特定数据样本对模型的训练更新。
- 类别忘却:用于分类任务,撤销单个或多个类别的数据对全局模型的训练更新。
- 任务忘却:在进行多任务训练时,可以撤销某个任务所有的数据对模型的训练更新,但可能产生灾难性忘却。
联邦忘却学习挑战
- 分布式的训练方式导致联邦忘却学习难以完全撤销目标用户对模型的数据贡献。因为每个用户都会保留全局模型到本地。
- 模型训练的增长过程使联邦忘却学习难以利用已训练的信息,先前所有用户的训练更新都决定了当前用户在本地的模型参数更新,并且其他用户对模型的训练也会因增长的训练过程包含目标用户数据的痕迹。
- 大量的数据撤销导致灾难性的忘却,全局模型准确率急剧下降。
联邦忘却学习算法
首先根据修正对象(在忘却过程中被直接修改的特定元素)将各类联邦忘却学习算法划分为面向全局模型和面向局部模型两种。
面向全局模型的联邦忘却学习算法
面向全局模型的联邦忘却学习算法是直接对全局模型参数进行修改并利用用户数据调整全局模型。
重新训练
通过模型回退和再训练方法能够完全撤销特定用户数据对模型的训练更新。当某个用户发出忘却请求后,服务器将全局模型回退到某一个训练时刻。为了防止回退产生的灾难性遗忘,服务器依赖回退后的模型参数在其他用户数据上再进行训练,从而实现联邦忘却学习。但是这种方法的再训练过程中传输大规模模型参数时会产生巨大的通信压力,并且增加训练的时间成本,所以有一些工作来解决这些问题:
- 采用近似估计 Hessian 矩阵的方法来快速构建联邦学习模型。
- 利用有限记忆 BFGS 算法的思想估计 Hessian 矩阵。
- 采用异步联邦的聚合机制 KNOT,将用户划分为集群,采用多层的思想来限制每个集群内的用户删除请求,减少重复训练次数和通信成本。
- 提出 IFU(Informed Federated Unlearning) 算法。
用户贡献删除
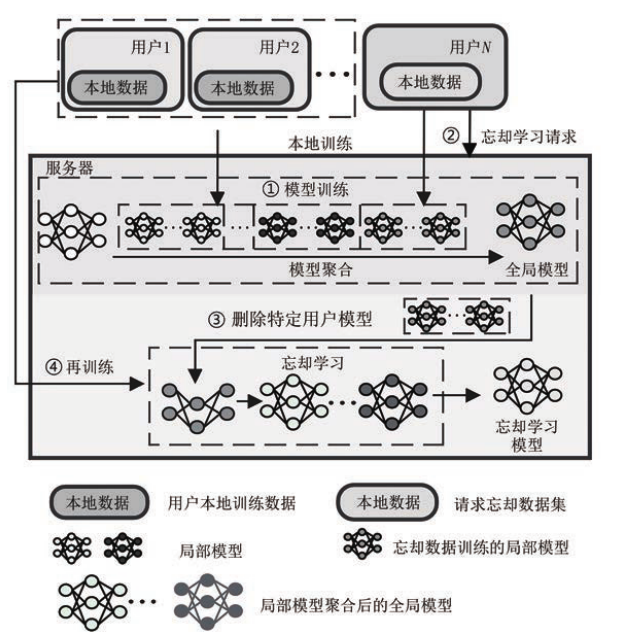
不同于重新训练方法,用户贡献删除算法可以减少用户重复训练的时间和通信开销,当特定用户发起忘却请求时,服务器从全局模型中直接删除用户产生的局部模型参数,实现对用户数据的忘却。最后,服务器利用再训练提升模型准确率,不再进行模型参数的回退。这个方向的一些工作:
- FUKD(Federated Unlearning with Knowledge Distillation),利用知识蒸馏技术实现联邦忘却学习。需要在中心服务器内存储所有用户模型参数,通过直接删除的方式实现忘却。它完全在服务器上进行,所以通信开销小。删除后,再通过知识蒸馏的方法回复产生的修正。
- FedLU,基于认知神经科学理论通过回溯干扰和被动衰减删除特定的知识。
局部参数调整
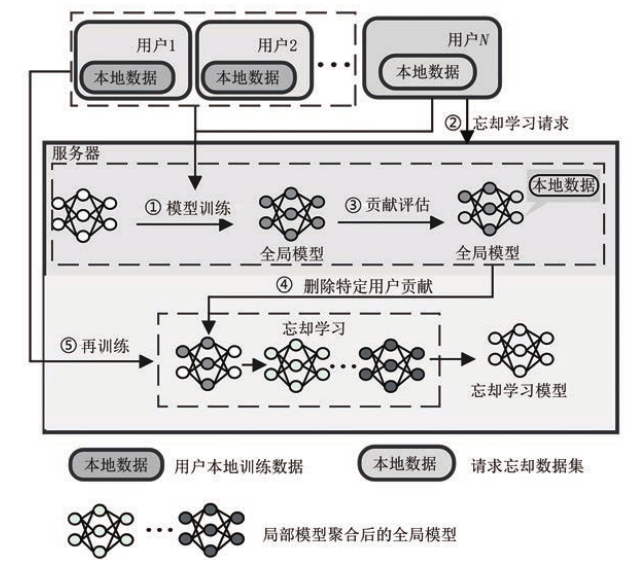
参数局部调整方法通过局部性地修改全局模型参数,解决特定模型结构的忘却学习问题。通过结构信息计算用户数据贡献的参数位置,准确删除用户数据对全局模型的贡献,从而实现数据的有效遗忘。当服务器接受某个用户的忘却请求后,根据模型结构对模型参数进行评估,识别出包含用户参数贡献的部分,然后将这部分贡献消除,形成新的模型参数。这个方向的一些工作:
- RevFRF:利用决策树的结构通过递归遍历的方式将目标用户提供的所有节点销毁,然后在剩余的用户中重新构建决策树,以恢复删除后的模型准确率损失。
- FUCP(Federated Unlearning via Class-discriminative Pruning):依据卷积神经网络结构中通道对类别的评分剪枝通道参数,有选择地遗忘特定类别的贡献。
面向全局模型方法对比

面向局部模型的联邦忘却学习算法
面向局部模型的联邦忘却学习算法是**利用用户训练的局部模型参数对全局模型参数进行间接修改。**通过增加联邦学习训练,在局部模型中获取新知识,根据新知识整体性地修改全局模型,不需要进行再训练。
训练更新校正
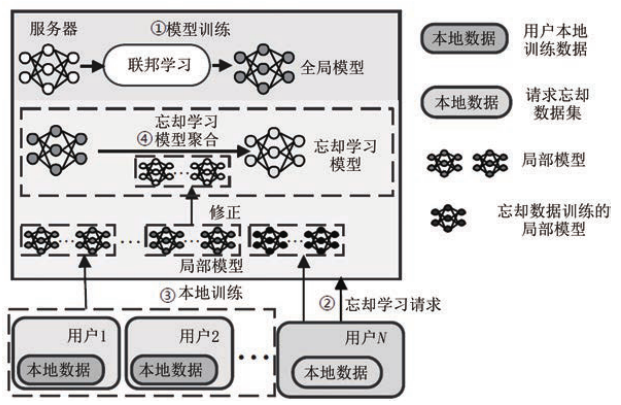
训练更新校正算法在现有模型的基础上增加额外的联邦学习训练,对训练过程中产生的模型参数进行修正,并通过聚合修正后的模型修改全局模型参数。当某个用户向服务器发起忘却请求时,服务器协同用户继续进行一定轮次的联邦学习训练,接受用户上传的模型参数,最后服务器对训练的局部模型参数进行修正,通过聚合修正后的模型参数更新全局模型,实现联邦忘却学习。这个方向的一些工作:
- FedEraser:基本思想是对用户模型参数更新进行校准。在服务器接受某个用户的忘却请求后,协同其余用户使用初始的全局模型参数继续本地训练,然后所有其余用户将本地模型更新发送给服务器,服务器利用已训练的更新对其余用户的训练参数进行校正。
- VERIFI:联邦忘却学习与验证的统一框架,提供 S2U(Scale-to-Unlearn) 算法,在模型聚合时,缩小目标用户的贡献比例,放大其余用户模型的贡献比例。
- 子空间梯度上升:服务器收集目标用户在执行梯度上升之后生成的梯度,以及其他用户的表示矩阵,服务器通过奇异值分解获取矩阵的梯度子空间,并修改全局模型参数。
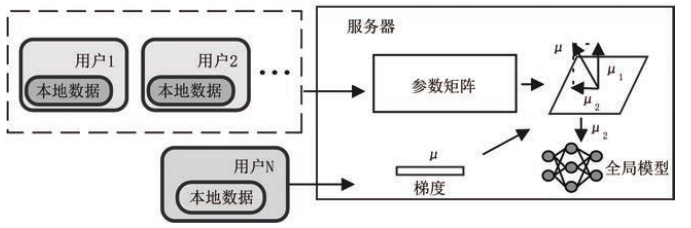
训练梯度校正
训练梯度校正的思想是在现有模型的基础上增加联邦学习训练,通过调整部分用户的训练方法,以直接聚合的方式来更新全局模型参数。当某个用户请求忘却时,服务器要求所有用户继续进行联邦训练,在此过程中调整用户的训练策略。最后,服务器接受并聚合用户的局部模型参数,利用聚合后的模型参数更新全局模型。主要通过修改梯度信息来达到忘却的目的。一些相关的工作:
- Forsaken:在参与训练的用户中配置可训练的虚拟梯度产生器,以根据目标函数的改变产生对应的虚拟梯度。目标用户发起忘却请求时,用户首先下载服务器的全局模型参数,初始化虚拟梯度,然后使用本地数据对模型进行训练,产生虚拟梯度,上传给服务器。服务器利用虚拟梯度信息修改全局模型参数。
- UPGA(Unlearning with Projected Gradient Ascent):利用梯度上升方法实现联邦忘却学习。
- EWC-SGA 框架:同样使用梯度上升的方法实现联邦忘却学习,但是加入了 Fisher 信息矩阵计算模型中每个参数的重要性因子之和,用于限制参数改变的幅度。
面向局部模型方法对比

不同联邦忘却学习算法对比
作者复现了一些方法进行了对比,选择Rapid Retraining和UPGA作为面向全局模型和面向局部模型联邦忘却学习算法代表去删除某一类数据对模型的影响,在剩余类别上进行准确率评估。增加FUCP作为局部参数调整算法的代表进行对比。在Epoch为30时开始联邦忘却学习进而删除某一类数据对模型的参数更新。
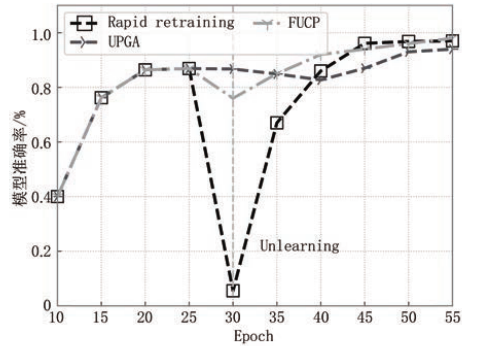
- 面向全局模型的算法会存在模型准确率急剧下降的问题,而面向局部模型避免了这一问题。此外,局部参数调整方法能够精确地删除目标数据对模型的贡献,在此基础上进行再训练。该方法借助模型结构和训练的数据信息,能够取得最佳的效果。
- 面向全局模型的算法大部分时间用于机器学习模型的准确率恢复,而面向局部模型大部分时间用于撤销目标用户对模型的训练更新。

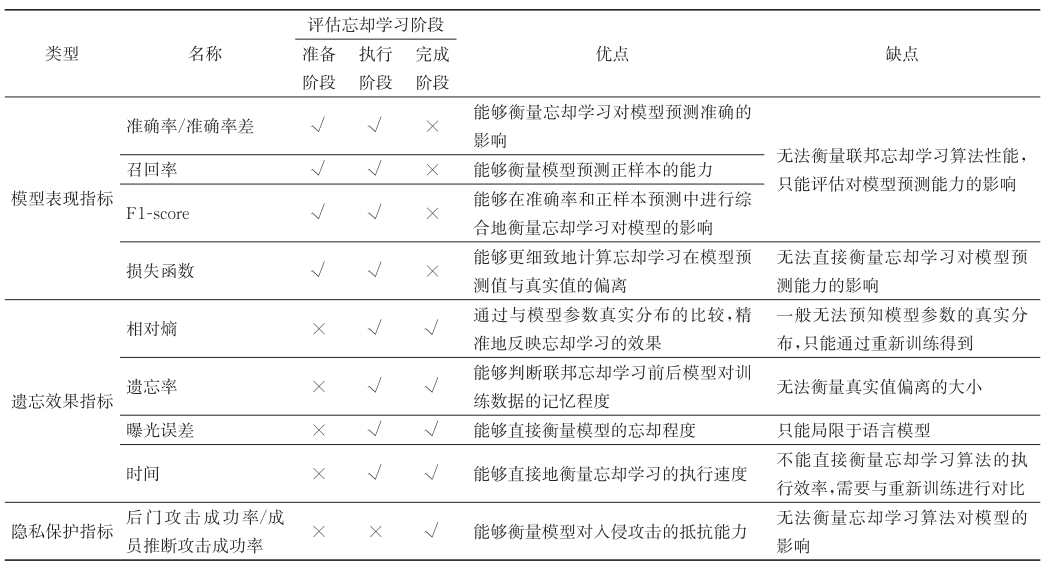
性能指标
- 模型表现指标
- 准确率、准确率差、召回率和 F1 分数
- 均方损失、L1 损失和交叉熵损失等
- 遗忘效果指标
- 相对熵
- 遗忘率
- 曝光误差
- 时间
- 隐私保护指标
- 信息损失
- 攻击抵抗
性能指标对比总结
联邦忘却学习应用
本节分别从用户和服务器的角度来介绍联邦忘却学习的应用。从用户角度来看,移除用户数据在模型中的影响可以减弱模型对该数据的记忆,从而有助于保护用户隐私;从服务器的角度看,消除劣质数据对全局模型的影响,可以显著提升模型的泛化能力。
隐私保护
联邦学习模型通过训练更新产生对用户数据的记忆,即使用户退出联邦学习系统,机器学习模型仍然保留因数据训练模型而产生的用户数据记忆,进而存在用户数据隐私泄露的风险。针对这一问题,联邦忘却学习可以为退出联邦学习系统的用户撤销 其数据对模型的训练更新,因此用户可以放心地进行数据流通,不必担心自身退出系统后的隐私泄露问题。
攻击抵抗
数据中毒会引起联邦学习模型准确率下降。在联邦学习的迭代训练过程中,所涉及的数据可能会失效、被污染、过时或被数据中毒攻击操控。联邦学习的全局模型将会因学习错误数据的贡献而造成准确率下降。因此,采用联邦忘却学习撤销这些错误数据所产生的模型更新,可以提高模型的泛化性能。
未来展望
- 泛化性更强的联邦忘却学习:不同机器学习方法以及联邦的模型结构存在差异,需要设计一个更加泛化高效的联邦忘却学习方法。
- 局部参数调整忘却学习算法:鉴于泛化的算法设计困难性,局部参数调整方法可以利用模型结构,寻找与特定用户数据高度相关的模型参数位置再删除或剪枝。可以考虑与高可解释性的数学方法相结合,例如奇异值分解、主成分分析等,捕获模型参数信息与数据之间的关联。
- 联邦忘却学习验证:忘却学习验证旨在确认特定数据的训练更新是否已成功地从模型中移除,这有助于确保数据安全和用户隐私得到充分保护。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 论文阅读——联邦忘却学习研究综述

发表评论 取消回复