使用B+树作为索引结构的原因:
一种自平衡树:
B+树在插入和删除的时候节点会进行分裂和合并操作,以保持树的平衡,存在冗余节点,使得删除的时候树结构变化小,更高效。
高度不会增长过快,查询磁盘I/O次数减少:
B+树是一种多叉树,非叶子节点只保存主键或索引值和页面指针,使得每一页能够容纳更多记录,内存中存放更多索引,容易命中缓存,查询I/O次数减少。
范围查询能力强:
叶子节点通过链表连接定位到叶子节点的起点后,只需要顺序扫描链表后续的数据,非常高效。
根节点开始,根据键值大小确定位置于左/右子树
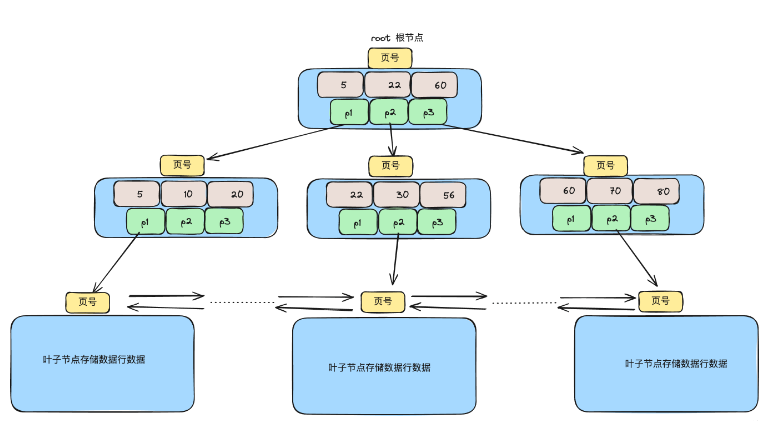
非叶子节存储主键和页号,通过页号定位到叶子节点(默认16k大小),可存储多条数据。
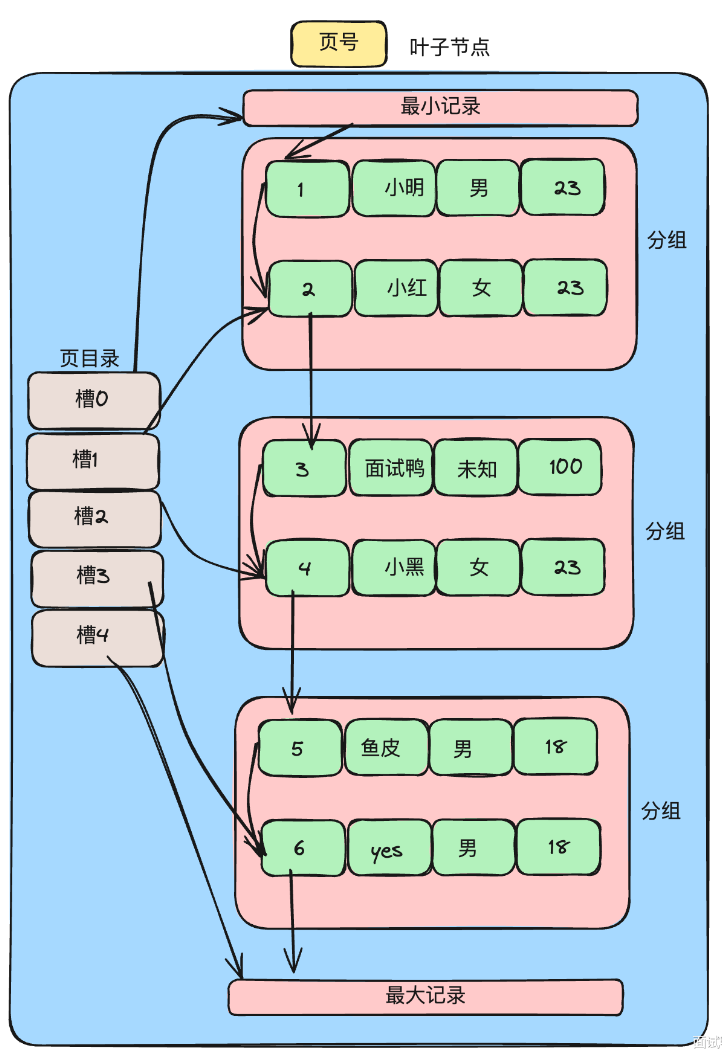
通过页目录索引快速找到记录,页目录每个槽指向对应分组的最大记录。
通过二分查询,利用槽定位数据所在组。
InnoDB规定:
第一个分组只有一条记录
中间的分组4-8条记录
最后一个分组1-8条记录
B+树和B树的区别:
B+树更加稳定,平均,都要从根结点查询到叶子节点。
B+树便于区间查找,B树只能每一层遍历查找。
B树每个节点都存储数据,B+树存储key和指针,内存中可存放更多索引页,减少磁盘查询次数。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【MySQL】查询原理 —— B+树查询数据全过程

发表评论 取消回复