一,前言
在本文中,我将使用python语言基于Jupyter notebook对这一份物流行业数据集进行多维度数据分析,文章内容参考自b站马士兵《数据分析五大经典实战项目》教学视频,并对其中一些操作做出优化。
数据集下载地址:物流行业数据分析 - Heywhale.com
数据集若涉及侵权,请联系删除,谢谢!
二,数据导入与数据梳理
<1> 第三方库与数据导入
# 1,导包
import pandas as pd
import numpy as np
# 2,数据导入
data = pd.read_csv("D:/DataSet/data_wuliu.csv", encoding="gbk")<2> 查看数据前十行可以发现三点:
- 数据中存在缺失值
- " 订单行" 这一列对于数据分析没有实质意义,可以考虑删除
- 销售金额单位不统一
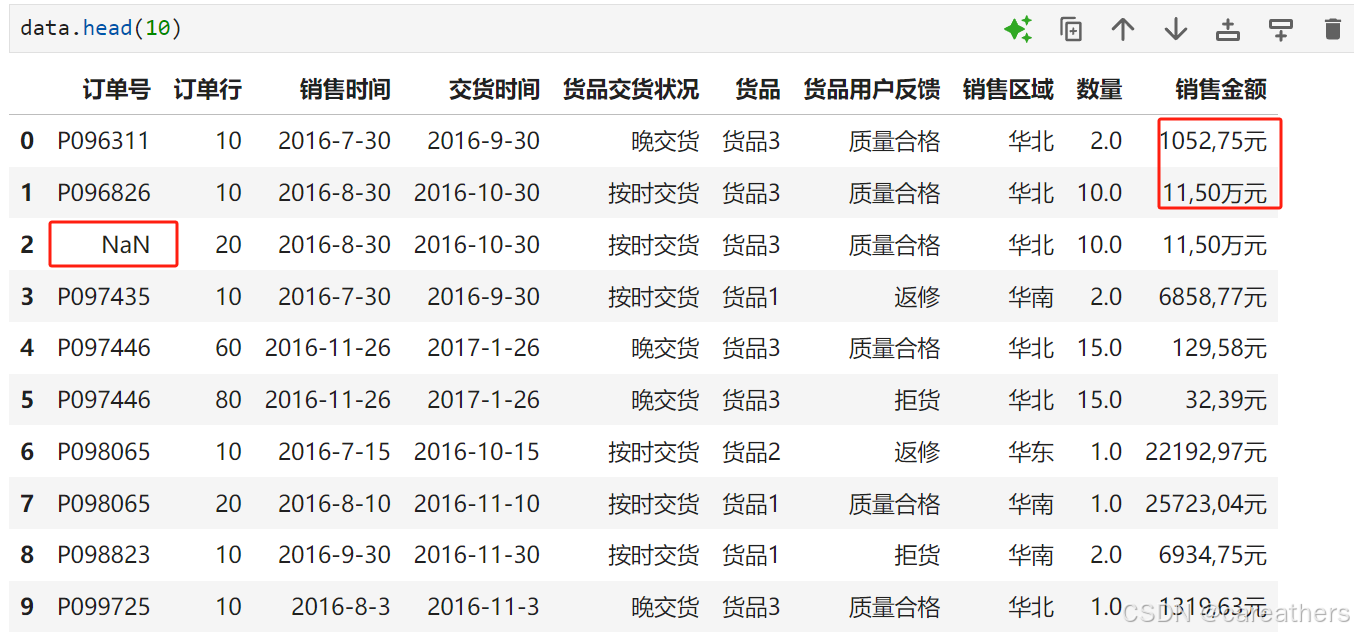
<3> 使用df.info()方法进一步查看数据的类型与缺失情况
通过输出信息我们能够发现:
1,数据中虽然存在缺失值,但是缺失值所占的比例非常少,因此我们可以将缺失值进行删除处理;
2,销售金额、销售时间、交货时间为字符串类型,后续我们需要将其进行类型转换
三,数据清洗
<1> 缺失值处理
由于在数据梳理的过程中发现缺失值较少,因此我们对缺失值直接采用删除的方式进行处理
# -- 缺失值处理 --
data.dropna(inplace=True)<2> 重复值处理
重复值对于我们数据分析是无用的,因此我们无需查看,直接将其删除即可
# -- 重复值处理 --
data.drop_duplicates(inplace=True)<3> 数据类型处理
在本案例中,我们发现销售时间、交货时间、销售金额等列均为字符串类型,这是不利于我们后续进行数据分析操作的,因此要对其进行数据类型处理。将销售时间、交货时间转换为时间类型数据,而销售金额则转换为整型数据
# -- 数据类型处理 --
data.销售时间 = pd.to_datetime(data.销售时间)
data.交货时间 = pd.to_datetime(data.交货时间)
# --对字符串进行处理(可以写成链式)
data.销售金额 = data.销售金额.map(lambda x: x.replace(",", ""))
data.销售金额 = data.销售金额.map(lambda x: x.replace("万元", "0000"))
data.销售金额 = data.销售金额.map(lambda x: x.replace("元", ""))
# -- 转换类型
data.销售金额 = data.销售金额.astype("int64")<4> 异常值处理
之所以现在才开始处理异常值,是因为在之前我们还未对销售金额类型进行处理,不利于我们查看异常值的情况
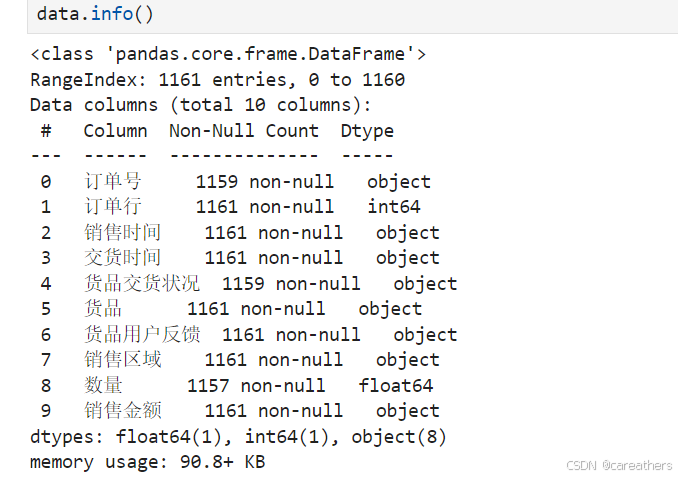
1,对数值类型数据进行分析
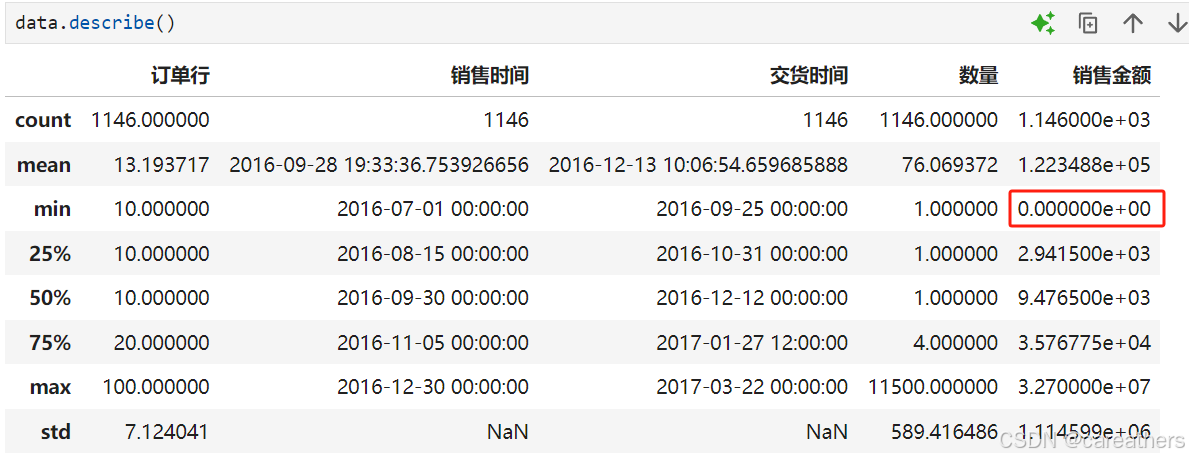
如下图所示,我们通过观察销售金额与数量这两列可以得出:
- 存在异常值,即销售金额为0
- 数据呈现很严重的右偏分布,从数量那一列中即可看出,第3/4位数为4,但是平均值却高达76。不过在电商领域中这属于正常现象,符合二八定律(即百分之二十的用户贡献了百分之八十的销售量),因此无需处理
2,对异常值进行处理
综上所述,我们仅需对销售金额为0的异常记录进行删除
# -- 异常值处理 --
data = data[data.销售金额 != 0]<5> 数据规整度处理
此处需要处理三个方面的内容:
1,在前文操作中,我们曾删除空缺行、重复行、异常行,此时数据的索引应当是杂乱无章的,为了保证行级索引的有序性,我们需要重置索引,操作如下:
# -- 重置行级索引 --
data.reset_index(drop=True, inplace=True)
2,对于类型为字符串的列,我们应当查看其是否存在空格,若是存在,则应当将空格去除
查看方式:

去除方式:
# -- 去除字符串前后空格 --
data.货品交货状况 = data.货品交货状况.str.strip()3,删除无用列(可选项)
为了保证数据的整洁与美观,对于不需要使用到的列,我们可以选择性将其删除
# -- 删除无用列 --
data.drop(columns=["订单行"], inplace=True)四,数据分析与可视化
为了降低数据分析的难度,我们可以将需要解决的问题先总结出来,后续带着问题去做数据分析就比较轻松。根据本数据集的特征,我们可以总结出以下问题:
- 配送服务是否存在问题?
- 是否存在尚有潜力的销售区域?
- 商品是否存在质量问题?
<1> 分析配送服务是否存在问题
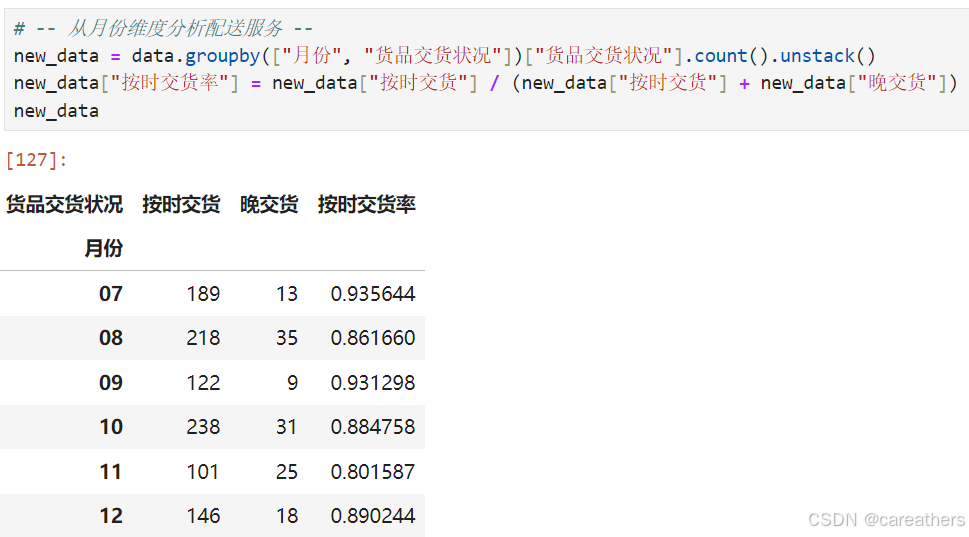
首先解决第一个问题,配送服务是否存在问题?观察到其货品交货存在两种情况,即 "晚交货" 与 "按时交货",因此我们可以计算其在不同维度下的按时交货率来进行分析
1,从月份维度进行分析
考虑到后续需要多次从月份维度进行分析,因此在数据中新增一列 "月份",表示销售时间所在月份,代码如下:
# -- 新增月份列 --
data["月份"] = data.销售时间.map(lambda x: x.strftime("%m")) 以月份为基准,按时交货率:
数据可视化:
# -- 数据可视化 --
from pyecharts.charts import Line
from pyecharts import options as opts
line = (
Line()
.add_xaxis(list(new_data.index))
.add_yaxis("按时交货率", [round(float(x), 2) for x in list(new_data.按时交货率)])
.set_global_opts(
title_opts=opts.TitleOpts(
title="从月份维度分析配送服务",
pos_left="center",
pos_bottom="1px"
)
)
)
line.render_notebook()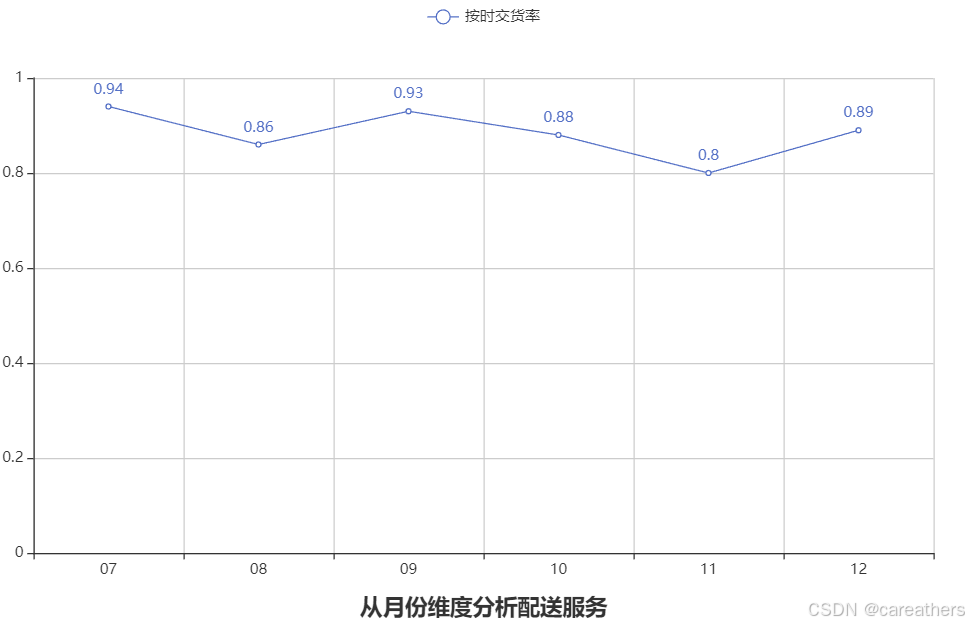
结合上图与对应的数据,我们似乎并不能从中得出什么很有用的结论,因此先将其搁置,若是后续在分析的过程中能出现与其规律相呼应的数据,再行讨论
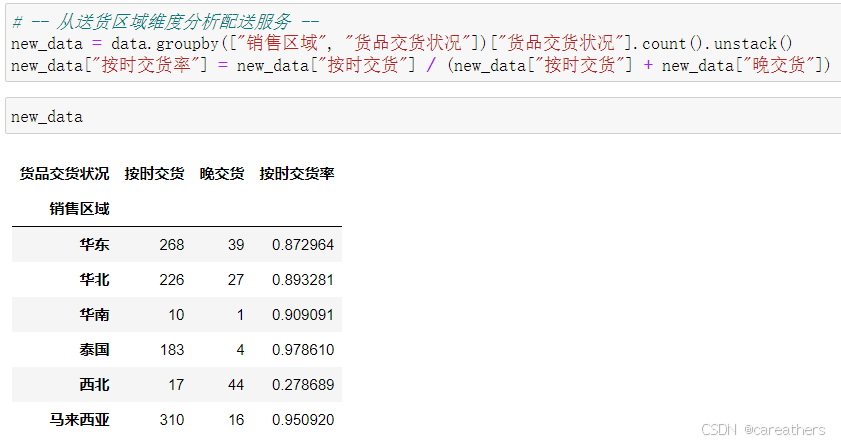
2,从销售区域维度进行分析
以销售地区为基准,按时交货率:
数据可视化:
# -- 数据可视化 --
from pyecharts.charts import Line
from pyecharts import options as opts
line = (
Line()
.add_xaxis(list(new_data.index))
.add_yaxis("按时交货率", [round(float(x), 2) for x in list(new_data.按时交货率)], is_smooth=True)
.set_global_opts(
title_opts=opts.TitleOpts(
title="从送货区域维度分析配送服务",
pos_left="center",
pos_bottom="1px"
)
)
)
line.render_notebook()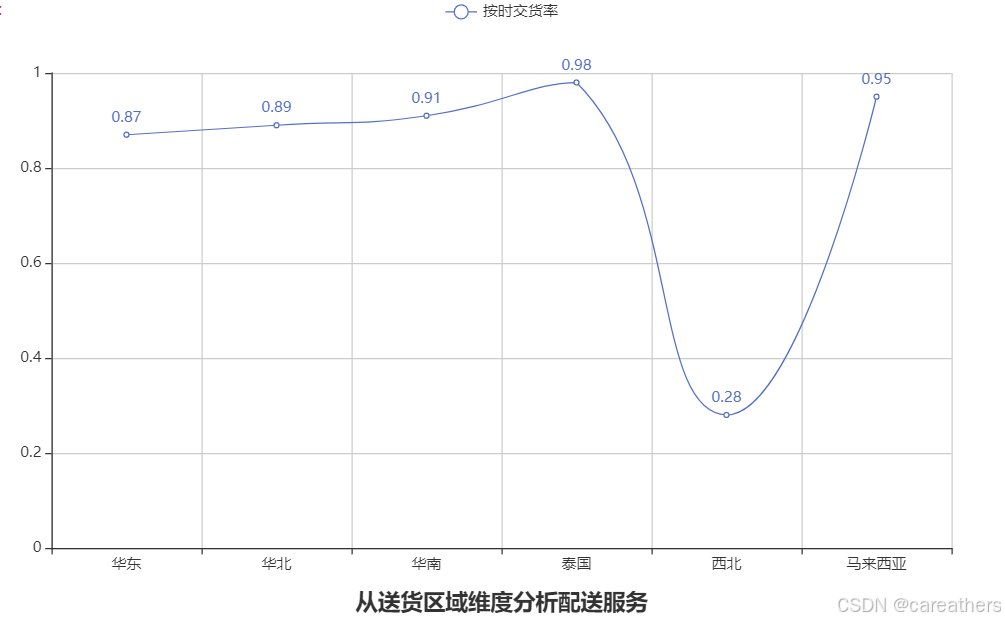
结合上图可以看到,西北地区的按时交货率低至28%,远远低于其它地区,这是我们发现的第一个问题。不过目前我们尚且不能得知其原因,或许需要在后续的分析中才能进一步了解。
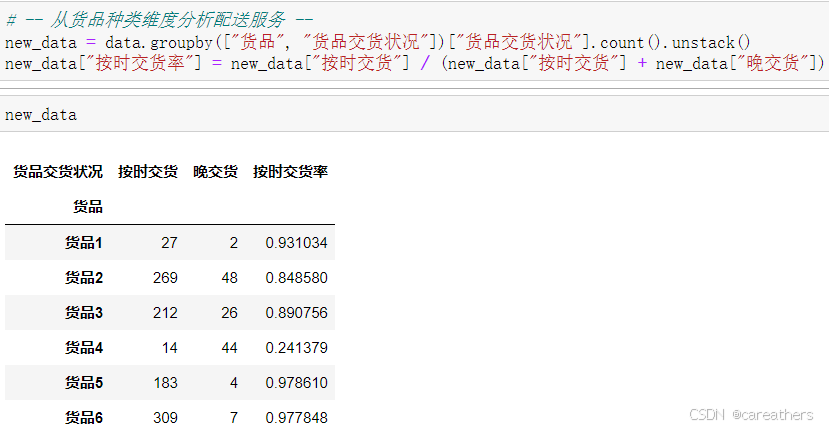
3,从货品维度进行分析
以货品种类为基准,按时交货率:
数据可视化:
# -- 数据可视化 --
from pyecharts.charts import Line
from pyecharts import options as opts
line = (
Line()
.add_xaxis(list(new_data.index))
.add_yaxis("按时交货率", [round(x, 2)for x in list(new_data.按时交货率)], is_smooth=True)
.set_global_opts(
title_opts=opts.TitleOpts(
title="从货品维度分析配送服务",
pos_left="center",
pos_bottom="1px"
)
)
)
line.render_notebook()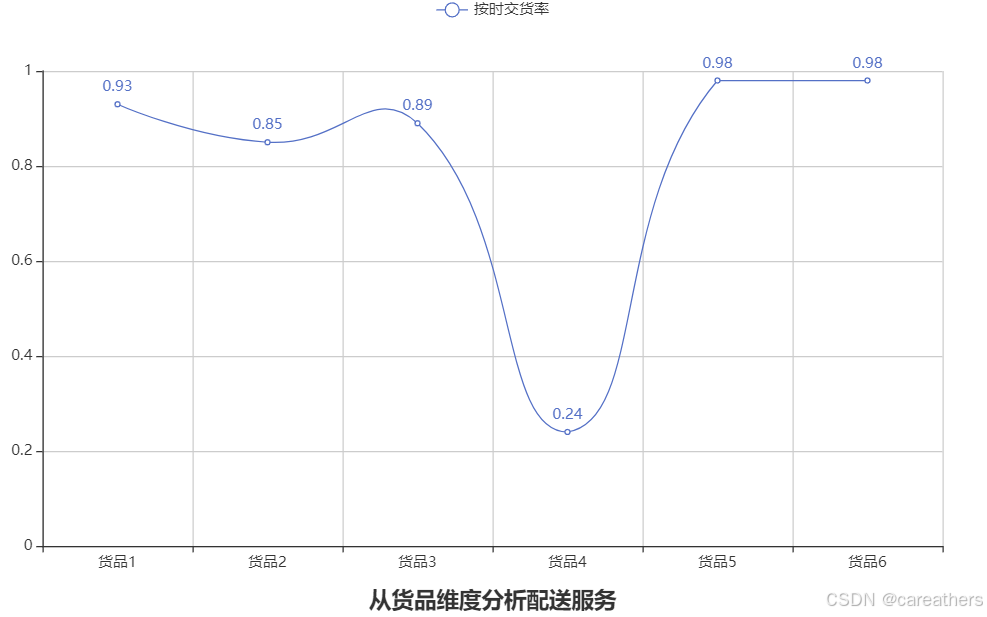
结合上图我们发现,货品4的按时交货率低至24%,这个数值与上文中西北地区按时交货率很接近,因此我们需要结合这两个维度一起查看才能得出准确的结论。
4,结合销售地区与货品这两个维度进行分析
基于销售地区与货品种类所得按时交货率:
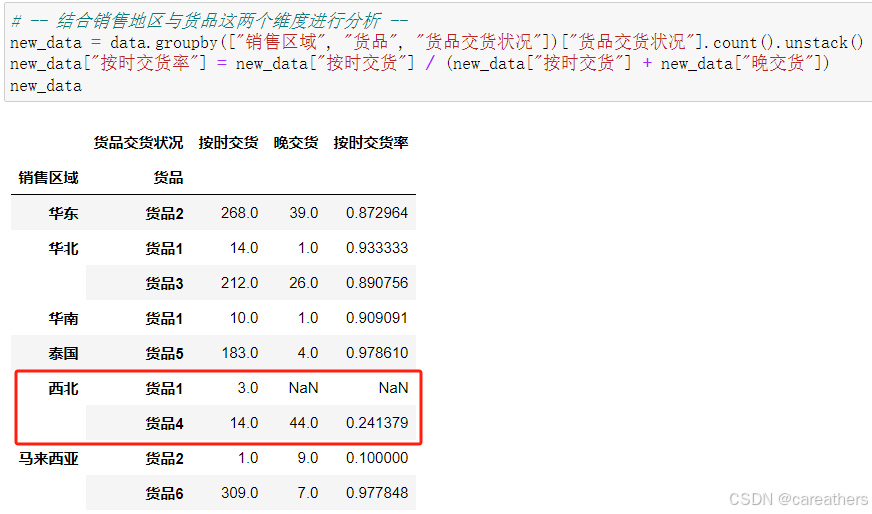
结合上述数据我们可以看到,西北地区存在两种货品,分别是货品1和货品4。其中,货品1的按时交货率高达100%,而货品4的按时交货率仅为24%。这一显著差异直接导致我们在以销售地区为维度进行分析时,发现西北地区的整体按时交货率仅有28%。
通过上述数据我们还发现,马来西亚地区货品2的按时交货率仅为10%,这说明该线路的配送时效存在着很大的问题
综上所述,我们即可对第一个问题进行解答:货品4运往西北地区 与 货品2运往马来西亚地区 这两条配送线路存在较大问题,急需提升时效!
<2> 是否存在尚有潜力的销售区域?
在本案例中若想分析一个区域是否具有潜力,最重要的就是根据货品的销售情况进行分析。因此处理方式与上文一致,先确定核心指标,后续通过不同维度进行数据分析,最终整合已知情况得出结论。
1,从月份与货品维度进行分析
以月份和货品为基准进行分析,观察各产品的销量是否随时间而波动
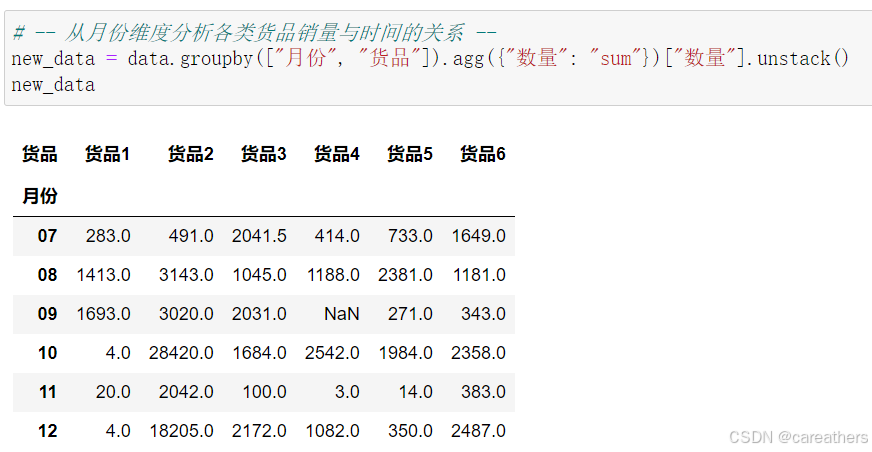
数据可视化:
# -- 数据可视化 --
from pyecharts.charts import Line
from pyecharts import options as opts
line = (
Line()
.add_xaxis(list(new_data.index))
.add_yaxis("货品1销量", list(new_data.货品1), label_opts=opts.LabelOpts(is_show=False), is_smooth=True)
.add_yaxis("货品2销量", list(new_data.货品2), label_opts=opts.LabelOpts(is_show=False), is_smooth=True)
.add_yaxis("货品3销量", list(new_data.货品3), label_opts=opts.LabelOpts(is_show=False), is_smooth=True)
.add_yaxis("货品4销量", list(new_data.货品4), label_opts=opts.LabelOpts(is_show=False), is_smooth=True)
.add_yaxis("货品5销量", list(new_data.货品5), label_opts=opts.LabelOpts(is_show=False), is_smooth=True)
.set_global_opts(
title_opts=opts.TitleOpts(
title="以月份为基准各货品销量统计图",
pos_bottom="1px",
pos_left="center"
)
)
)
line.render_notebook()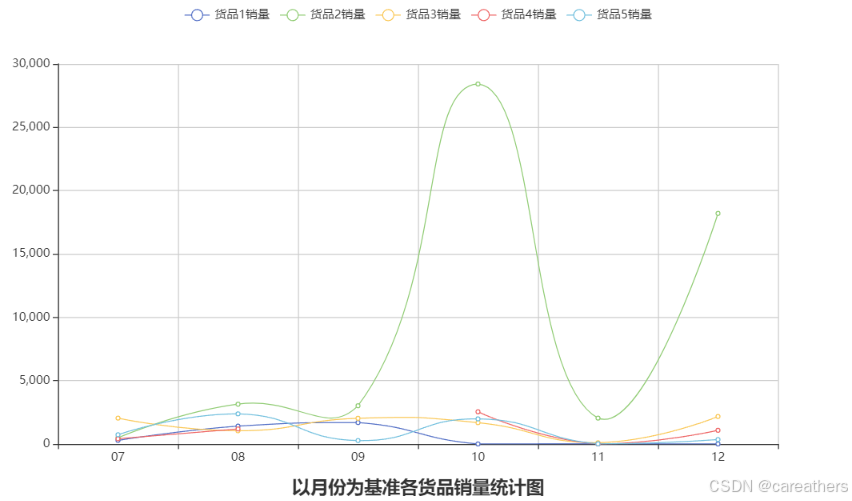
从上图中我们可以很明显地看到,货品1、3、4、5每月的总销量都稳定在3000以内,而货品2在十月份与十二月份销量突然暴涨三四倍,由此我们可以对其销量暴涨的原因做出合理的预测,可能是公司在十月份与十二月份对产品2加大了营销力度,也有可能是公司为产品2开辟了新的市场,从而导致其销量提升。就目前的已知信息而言,我们暂不能得知其具体原因,因此需要结合后续结论一起分析。
不过,既然已经有了两个推断,我们就可以从这方面着手区进行分析。接下来我们将结合货品种类、月份与销售区域维度进行分析,判断公司对于货品2是否有开辟新的市场。
2,结合货品种类、月份与销售区域维度对货品2进行分析
以月份为基准,分析货品2在各个月份销售区域分布情况,从而判断其是否有新开辟市场,如下:
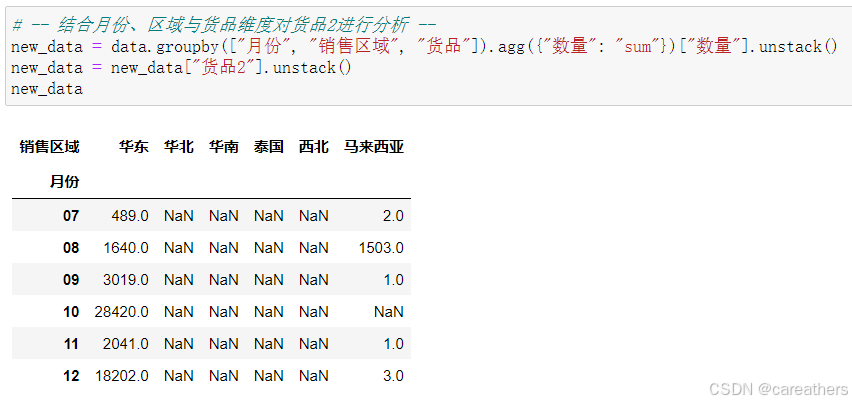
数据可视化:
# -- 数据可视化 --
from pyecharts.charts import Line
from pyecharts import options as opts
line = (
Line()
.add_xaxis(list(new_data.index))
.add_yaxis("货品2华东区域销量", list(new_data.华东), label_opts=opts.LabelOpts(is_show=False), is_smooth=True)
.add_yaxis("货品2华北区域销量", list(new_data.华北), label_opts=opts.LabelOpts(is_show=False), is_smooth=True)
.add_yaxis("货品2华南区域销量", list(new_data.华南), label_opts=opts.LabelOpts(is_show=False), is_smooth=True)
.add_yaxis("货品2泰国区域销量", list(new_data.泰国), label_opts=opts.LabelOpts(is_show=False), is_smooth=True)
.add_yaxis("货品2西北区域销量", list(new_data.西北), label_opts=opts.LabelOpts(is_show=False), is_smooth=True)
.add_yaxis("货品2马来西亚区域销量", list(new_data.马来西亚), label_opts=opts.LabelOpts(is_show=False), is_smooth=True)
.set_global_opts(
title_opts=opts.TitleOpts(
title="货品2以月份为基准各区域销量汇总图",
pos_bottom="1px",
pos_left="center"
)
)
)
line.render_notebook()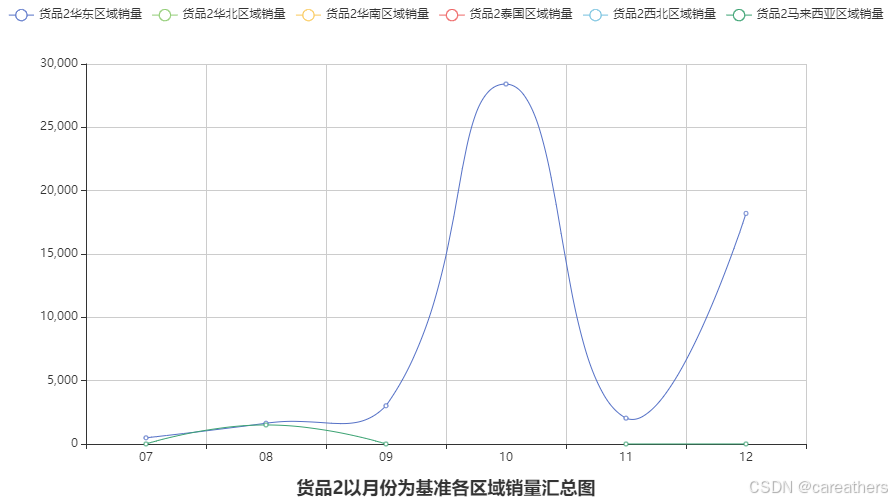
至此我们可以得出结论,货品2销售量大幅增长的来源主要来自于华东地区,说明其增长并非是开辟了新的销售市场,而是公司在十月份 与 十二月份加大了营销力度所导致的。再者,根据其销售反响我们也可以得出,货品2在华东地区的销售潜力巨大,公司可以考虑加大对其资源投入。
综上所述,我们即得出第二问的结论:货品2在华东地区具有较大的市场潜力,可以加大资源投入。
<3> 商品是否存在质量问题
在本数据集中若想判断商品是否存在质量问题,其主要依据就 "货品用户反馈",而用户反馈一共存在三种类别,分别是 "质量合格", "返修" 与 "拒货",我们可以由此计算货品合格率,再结合其他维度进行分析。
1,通过货品维度进行分析
以货品为基准,分析出每一种货品的产品合格率、返修率和拒收率:
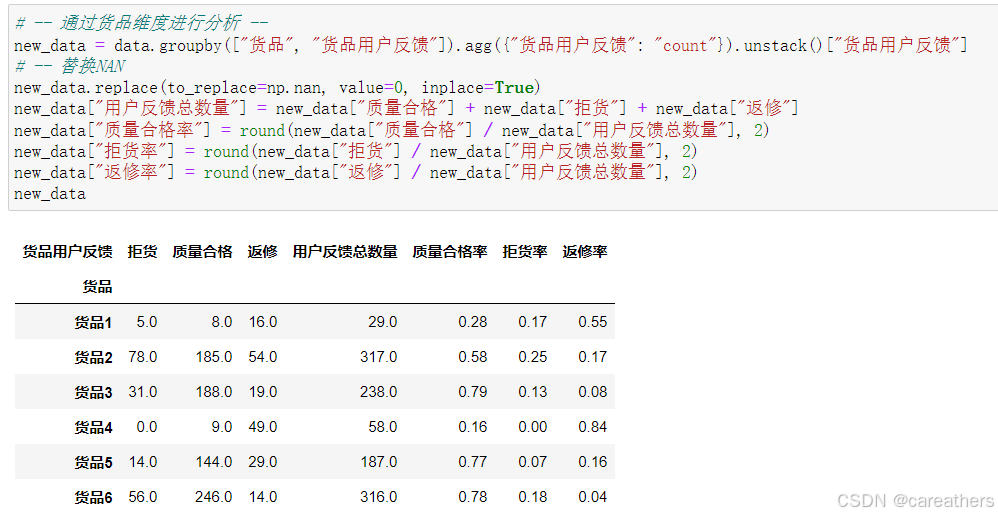
数据可视化:
# -- 数据可视化 --
from pyecharts.charts import Bar
from pyecharts import options as opts
bar = (
Bar()
.add_xaxis(list(new_data.index))
.add_yaxis("质量合格率", list(new_data.质量合格率), label_opts=opts.LabelOpts(is_show=False))
.add_yaxis("返修率", list(new_data.返修率), label_opts=opts.LabelOpts(is_show=False))
.add_yaxis("拒货率", list(new_data.拒货率), label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
title_opts=opts.TitleOpts(
title="各货品质量合格率、返修率、拒货率统计图",
pos_left="center",
pos_bottom="1px"
)
)
)
bar.render_notebook()
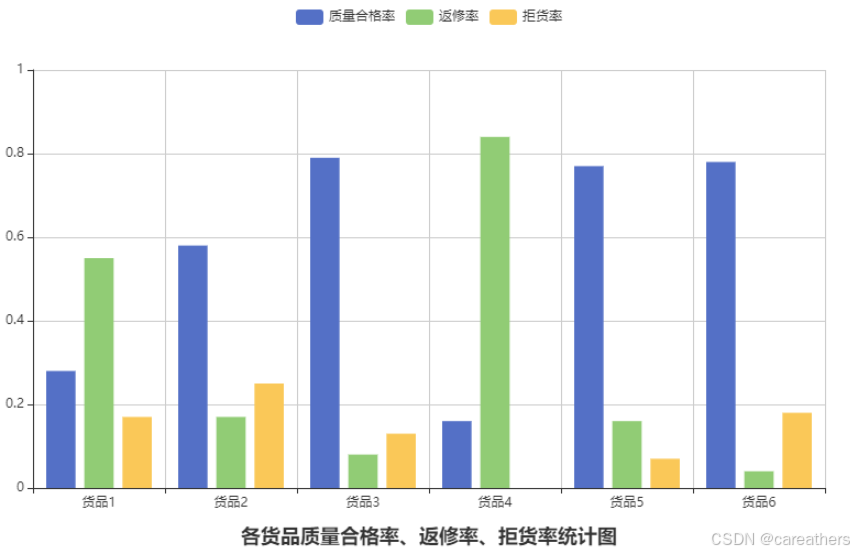
通过上图我们可以看到,货品1与货品4的质量合格率低于30%,并且其返修率均超过了50%,说明其存在较大的质量问题,后续我将结合货品的销售区域,对其进行进一步分析
2,结合货品与区域维度进行分析
以货品和销售区域为基准计算各项指标,能够更精确地定位到发生问题的货品及其销售区域,能够使我们做出更加准确的决策。
# -- 结合货品与区域维度进行分析 --
new_data = data.groupby(["货品", "销售区域", "货品用户反馈"]).agg({"货品用户反馈": "count"}).unstack()["货品用户反馈"]
# -- 替换NAN
new_data.replace(to_replace=np.nan, value=0, inplace=True)
new_data["用户反馈总数量"] = new_data["质量合格"] + new_data["拒货"] + new_data["返修"]
new_data["质量合格率"] = round(new_data["质量合格"] / new_data["用户反馈总数量"], 2)
new_data["拒货率"] = round(new_data["拒货"] / new_data["用户反馈总数量"], 2)
new_data["返修率"] = round(new_data["返修"] / new_data["用户反馈总数量"], 2)
new_data
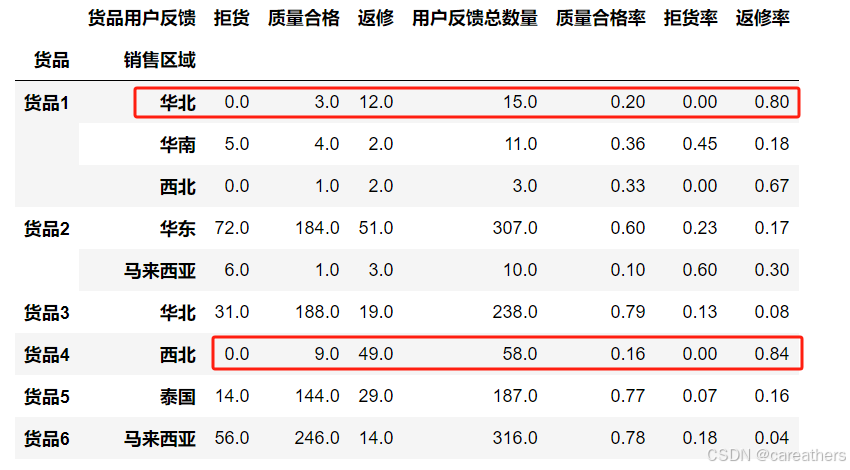
观察上述标红的两条数据我们不难看出,货品1销往华北地区的货品 和 货品4销往西北地区的货品,其返修率均高达80%,说明其货品存在严重的质量不合格现象。
除此之外我们还注意到,货品2销往马来西亚的货品,其拒货率高达60%,结合我们之前的分析结论:"货品2运往马来西亚的按时交货率仅为10%" 可以得出,马来西亚地区对于货品的配送时效有着较高的要求。
综上所述,我们可以得出第三问的答案:货品1销往华北地区的货品 与 货品4销往西北地区的货品均存在严重的质量问题,需要进行整改!
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【Python】物流行业数据分析与可视化案例

发表评论 取消回复