| 原文 | What Goes Around Comes Around |
| 作者 | Michael Stonebraker & Joseph M. Hellerstein |
| 其他译文 | https://zhuanlan.zhihu.com/p/111322429 |
1. 摘要
本文总结了近35年来的数据模型方案,分成9个不同的时代,讨论了每个时代的方案。我们指出,基础的数据模型思想只有少数的几个,大多已经出现很长时间了。新方案难免相似于旧模型。研究以前的方案,是很有价值的练习。
此外,我们介绍了在分析每个时代数据模型时获得的经验。当代研究人员往往没有经历过以前的年代,缺乏(如果有)对前人经验的理解。古话说:不知史,蹈覆辙。通过介绍历史经验,我们希望将来的研究人员可以避免重复历史。
很不幸,当前XML时代的方案和1970年代的CODASYL模型相似,后者因为过度复杂遭受失败。显然我们正在重复历史,又回到原点。希望下次我们能更聪明些。
2. 简介
关于数据模型的论文从1960年代就出现了。自从首位作者登上舞台,35年间,论文以惊人的规律性重复出现。然而今天很多论文的作者过于年轻,没能从前人讨论中学习经验。本文的目的就是总结35年来取的进步,指出在长期实践中我们应当吸取的经验。
我们展示了9个不同历史时期的数据模型:
- 层级型(IMS):1960年代到1970年代
- 网络(CODASYL):1970年代
- 关系型:1970年代到1980年代早期
- 实体-关系:1970年代
- 扩展关系型:1980年代
- 语义型:1970年代到1980年代
- 面向对象型:1980年代到1990年代
- 对象-关系型:1980年代到1990年代
- 半结构型(XML):1990年代至今
我们用统一的概念来描述不同时代的数据模型和查询语言,让读者可以忽略各模型在表述细节上的差异。我们也会使用统一的术语,尽量避免混淆。
在本文中,我们主要使用[CODD70]中的供应商和零件示例。我们在下面以关系型格式展示了这个示例。

图1 关系模式
这里展示了供应商信息、零件信息和记录了供应商出售零件条款的供应关系。
3. IMS时代
IMS(Information Management System)大约在1968年发布,最初使用层级型数据模型。它使用一个叫做 记录类型 的概念,这是一组带有名字和数据类型的域。记录类型的每个 实例 必须遵守记录类型定义所设定的数据描述。此外,一些具名域的子集必须唯一指定一个记录实例,即必须构成 键 。最后,记录类型组织成 树 ,每个记录类型(除了根)拥有唯一的 父 记录类型。IMS数据库是记录类型实例集合。除了根记录类型实例外,每个实例拥有唯一的父节点,是它们的记录类型。
树型结构为我们的示例数据提出了难题,我们不得不采用图2中的两种结构之一。它们有两个常见的不良性质:
- 重复信息。 在第一个模式中,销售同一种零件的供应商包含重复的零件信息。在第二个模式里,供应商信息在其出售的零件中重复出现。重复信息是不好的,如果修改了重复元素中的一部分而非全部,将产生状态不完整的数据库。
- 依赖父节点。 在第一个模式中,不允许存在暂时没有供应商销售的零件。在第二个模式中,不允许存在暂时不销售零件的供应商。在严格层级结构中不允许存在这样的“特殊情况”。
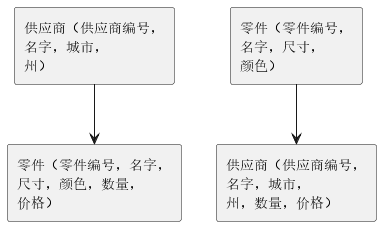
图2 两种层级结构
IMS选择使用层级数据库的原因在于,它可以使用一种简单的数据操作语言DL/1。IMS数据库的每个记录拥有一个 层级顺序键 (HSK)。HSK通过将祖先记录键拼接起来,再加上当前记录键构成。HSK以深度优先、从左到右的方式,定义了IMS数据库中记录的自然顺序。DL/1隐含使用HSK顺序作为命令的语义。例如“取下一个”命令返回HSK顺序的下一条记录。而“从子树中取下一个”命令从以特定记录为根的子树中按照HSK顺序查找。
使用第一个模式,我们可以用下面的方法查找供应商16销售的全部红色零件:
Get unique 供应商 (供应商编号 = 16) Until failure do Get next with parent (颜色 = 红色) Enddo
第一个命令查找供应商16,接着按HSK顺序遍历子树节点,查找红色零件。子树查找完成后,返回一个错误对象。
DL/1是一种“逐记录”语言。程序员构造一个算法解决查询问题,IMS负责执行算法。通常一个查询可以有多种解决方法。下面用一种新方法解决前面的查询问题:
Until failure do Get next 零件 (颜色 = 红色) Enddo
有人也许会觉得第二段代码明显不如第一段代码。实际上,如果数据库里只有一个供应商(编号16),第二段代码性能更好。DL/1程序员必须做出这样的性能权衡。
IMS支持用4种不同的存储格式记录层级数据。通常根记录可以:
- 顺序存储
- 通过记录键使用B-树索引
- 通过记录键使用散列表索引
非根记录需要从根记录开始查找,方法有:
- 物理顺序
- 各种形式的指针
一些存储结构限制了DL/1命令。例如顺序存储结构不支持插入记录,只适用于批处理环境。将变更列表按HSK顺序排列,遍历数据库,将变更插入适当位置,写入一个新的数据库。这种方式叫做“旧数据-新数据”处理。此外,通过键使用散列表索引根记录的存储结构不支持“取下一个”命令,无法按HSK顺序返回散列记录。
IMS有很多奇怪的特性,是为了避免低效率的操作。这样的设计决策也是有代价的:用户无法灵活调整存储结构来优化应用性能,因为DL/1程序无法兼容。
无论在存储的物理层作出何种调整,应用都可以正常运行的能力叫做 物理数据独立性 。这种性质很重要,数据库管理系统通常不是一次性开发完成的。当新的程序添加到应用中,调优需求可能发生改变,数据库管理系统可以通过调整存储结构获得更好的性能。IMS的设计限制了物理数据独立性。
应用的逻辑需求可能随着时间改变,对于新的业务需求或监管需求,系统需要新增记录类型。有时也需要将一些数据元素从一种记录类型迁移到另一种。IMS支持一定程度的 逻辑数据独立性 ,因为DL/1实际是定义在逻辑数据库上,而非底层物理数据库上。开发DL/1程序时,可以假定逻辑数据库和物理数据库结构相同。在向物理数据库添加新的记录类型时,可以重新设置逻辑数据库,排除新类型。IMS数据库可以添加新类型进行扩展,原始的DL/1程序可以正常运行。通常IMS逻辑数据库是物理数据库的子树。
让程序员处理数据的逻辑抽象模型是一个绝妙的想法,这让物理组织结构的变化不会影响DL/1程序的正常运行。逻辑和物理数据独立性是重要的,因为数据库管理系统拥有比数据更长的生命周期(往往长达四分之一世纪)。数据独立性让数据的变更不会产生高昂的程序修改成本。
关于IMS还有最后一点。显然示例数据难以适配前面提到的树结构表示,IMS难以在没有冗余或数据独立性问题的情况下表示示例数据。IMS的方法是扩展逻辑数据库概念。
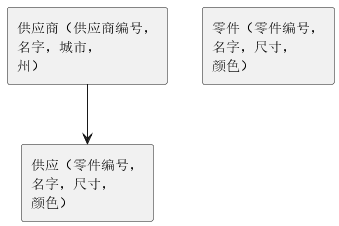
图3 两个IMS物理数据库
假设有两个物理数据库,一个包含零件信息,第二个包含图3中的供应商和供给信息。由于DL/1程序定义在树状结构上,不能直接处理图3中的结构。然而IMS可以定义图4中的逻辑数据库,将供给记录和零件记录按照共同的零件编号拼凑(连接),构成图中的层级结构。
通常图3是实际的存储结构,可以看到结构里没有冗余和不好的存在性依赖。程序员可以使用图4中的层级结构视图,它支持标准的DL/1程序。
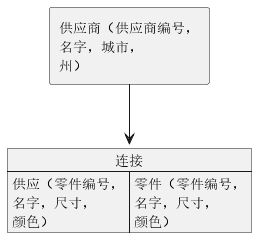
图4 一个IMS逻辑数据库
通常IMS允许使用两种不同的树状物理数据库连接起来构成一个逻辑数据库。以这种方式使用逻辑视图存在一些限制(比如不能使用删除命令),并且很复杂。但这提供了在IMS中表示非树状结构的方法。
很快可以看到,逻辑数据库复杂度是IBM在十年后决定支持关系型数据库的关键。
我们总结了迄今所学的经验,然后转向CODASYL模型。
经验1
物理和逻辑数据独立性非常重要。
经验2
树状模型存在很多限制。
经验3
为树状模型提供复杂的逻辑重组非常困难。
经验4
“逐记录”接口需要程序员执行手动查询优化,这很困难。
4. CODASYL时代
1969年,数据系统语言委员会(CODASYL)发布了首份报告,并在1971年和1973年发布了语言规范。CODASYL委员会专门致力将“逐记录”数据操作语言应用到网络数据模型。
这个模型将一组带有键的记录类型组织成网络,而非一颗树。因此一个记录实例可以有多个父节点,而非IMS中的单父节点。我们的供应商-零件-供应例子可以表示为图5中的CODASYL网络。
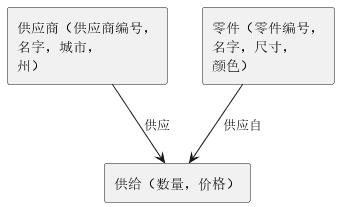
图5 CODASYL网络
注意网络里有三种记录类型,通过两个具名弧线:“供应”和“供应自”相连。在CODASYL中,具名弧线叫做 集合 ,虽然在技术上它并不是集合。弧线表明每个父记录类型(箭头尾)实例可以与若干个子记录类型实例(箭头首)关联。这是父记录类型实例和子记录类型实例间的一种“一对多”关系。
CODASYL网络是一组具名记录类型和具名集合类型构成的连通图。拥有至少一个入口点(记录类型不是任何集合的子节点)。CODASYL数据库是符合网络规则的一组记录实例和集合实例。
注意图5并没有层级数据模型中的存在性依赖。例如允许没有供应商销售的零件,只需要一个空的“供应自”集合实例。网络数据模型解决了层级模型的很多局限。但也有CODASYL难以建模的情况。例如关于婚礼庆典的数据,新娘、新郎和牧师之间存在一种三元关系。CODASYL集合只支持二元关系,因此产生了图6中的数据模型。
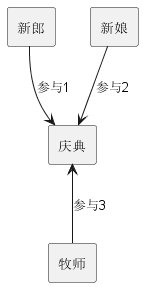
图6 CODASYL解决方案
这个方案需要使用3个二元集合表达一个三元关系,很不自然。虽然比IMS更灵活,CODASYL数据模型也存在很多局限:
CODASYL数据操作语言是“逐记录”语言。程序从入口节点进入数据库,沿着集合导航到目标数据。要在CODASYL中找出供应商16销售的红色零件,可以使用下面的代码:
Find 供应商 (供应商编号 = 16)
Until no-more {
Find next 供应商记录 in 供应
Find owner 零件记录 in 供应自集合
Get current record
-检查零件颜色-
}
程序从供应商16开始访问数据,对“供应”集合进行迭代,产生一组“供应”记录。对每个供应记录,程序访问“供应自”集合的父节点,检查零件颜色。
CODASYL数据模型建议将入口节点的记录按照键散列分布。有几种实现集合的方法,它们都使用了父记录和子记录间各种指针的组合。
CODASYL模型没有提供物理数据独立性。如果供应商记录的键从供应商编号变更为其他域,前面的程序将失效。CODASYL同样没有提供逻辑数据独立性,数据模式无法在不影响应用程序的情况下变更。
迁移到网络模型的优点在于,不用拼凑就能实现图结构数据,比如前面的例子。然而CODASYL模型比IMS模型更加复杂。IMS程序员在层级空间中移动,而CODASYL程序员则在多维超空间中穿梭。IMS程序员只需要考虑当前记录和单一父记录(如果需要执行“从子树中取下一个”)在数据库中的位置。
相比之下,CODASYL程序员需要记录:
- 最后访问的记录
- 每种记录类型中最后访问的记录
- 每个集合中最后访问的记录
CODASYL有多个数据操作命令更新当前位置信息。你可以把CODASYL编程理解为在数据库中移动一组位置指示器,直到发现一条目标记录,获取这条记录。CODASYL程序员可以根据需要禁止指示器移动。
可以这样想象CODASYL程序员:他在编程时盯着墙上使用不同颜色图钉标注出当前位置的CODASYL网络地图。在1973年图灵奖讲座中,查理·巴克曼称之为“穿梭在多维超空间”。
CODASYL模型增加了复杂度,来换取对非层级结构数据简单表示。CODASYL提供的逻辑和物理数据独立性不如IMS。
CODASYL还有一些小问题。例如在IMS中,每个数据库可以独立的从外部数据源批量加载。而CODASYL的全部数据在同一个大型网络中。整个网络必须一次性加载,需要很长时间。同样的,如果CODASYL数据库损坏了,必须从转储中全量加载。与分拆成独立的数据库相比,崩溃恢复更加复杂。
CODASYL加载程序也非常复杂,大量记录需要组装到集合中,往往需要多次磁盘寻址。仔细设计加载算法以提升性能成为一项重要的工作。所以CODASYL没有通用的加载工具,每次部署都需要编写独立的加载程序。这项复杂的工在IMS中则没那么重要。
至此,从CODASYL可以学到:
经验5
网络结构比层级结构更灵活,但也更复杂。
经验6
网络结构的加载和恢复工作远比层级结构复杂。
5. 关系时代
在前文所述背景下,泰德·科德在1970年提出了他的关系模型。几年后他在一次谈话中提到,每次逻辑或物理数据发生变化,IMS程序员需要花费大量时间来维护应用程序。这一发现成为他研究的驱动力,开始关心如何提供更好的数据独立性。
他的方案有三点:
- 将数据保存在简单结构(表)中
- 使用高级的“逐集合”数据操作语言访问数据库
- 不限制物理存储方案
简单结构可以更好的提供逻辑数据独立性。高级语言可以提供更高程度的物理数据独立性。不再需要像IMS和CODASYL那样限制物理存储方案。
关系模型额外的优势在于非常灵活,几乎可以表示任何对象。图1中困扰IMS的存在性依赖可以轻易的用关系模式处理。在CODASYL中难以表示的三元结婚庆典数据可以用关系模型表示为
庆典(新娘编号,新郎编号,牧师编号,其他数据)
科德在几年内又提出了多种关系模型(越来越复杂)。他早期提出的数据操作语言是关系演算和关系代数。科德最初是一名数学家(之前进行过元胞自动机方面的工作),他的数据操作语言方案是严谨的、形式化的,但让普通人难以理解。
科德方案立即引发了“大辩论”,在1970年代持续了很长时间。辩论席卷SIGMOD会议(及其前身SIGFIDET)。泰德·科德和支持者(多为研究员和学者)提出下列观点:
- 像CODASYL这样复杂的模型不可能是好方案
- CODASYL没有提供合理的数据独立性
- “逐记录”编程难以优化
- CODASYL和IMS不够灵活,无法简单的表示常见数据(例如结婚庆典)
另一方面查理·巴克曼和支持者(多为数据库管理系统从业人员)则认为:
- COBOL程序员无法理解新出现的关系语言
- 无法实现高性能关系模型
- CODASYL也能支持表,关系模型没有提出重要东西
争论的高光(或低光)时刻是74年的SIGMOD大会上科德和巴克曼以及双方助手间的辩论。作者之一也在现场,显然双方都没能清楚地表达立场,结果是谁也听不懂对方在讲什么。
接下来的几年,两个阵营(或多或少)调整了立场:
关系阵营认为:
- 科德是数学家,他提出的数据操作语言不好用。SQL和QUEL更好用。
- 系统R和INGRES证明科德的想法存在高性能实现。查询优化器在构造查询计划方面可以媲美(除了最顶级的)程序员。
- 上述系统证明物理数据独立性是可行的。与CODASYL相比,关系视图为逻辑数据独立性提供了大幅增强。
- 与“逐记录”语言相比,“逐集合”语言为程序员生产力带来了实质提升。
CODASYL阵营认为:
- 可以实现“逐集合”网络查询语言,例如LSL,提供完整的物理数据独立性和更好的逻辑数据独立性。
- 可以简化网络模型,变得不那么复杂。
双方都回应了对方的批评。争论随后平息下来,焦点转移到了商业市场,看看发生了什么。
关系阵营很幸运,微型计算机革命发生了,VAX销量猛增。它们是早期商业关系型系统(如甲骨文和INGRES)的目标平台。主流的CODASYL系统,例如Culinaine公司的IDMS,使用IBM汇编开发,不能移植。这让关系阵营感到高兴,也让早期的关系型系统独占VAX市场。这给了他们改进产品性能的时间,VAX也同关系型系统携手走向成功。
在大型机上,另一个完全不同的故事正在展开。IBM在VM/370平台上销售系统R的后续版本,在VSE平台(IBM的低端操作系统)上销售系统R的一个衍生版本。但这两个平台都没有被真正的商业数据处理用户接受。用户全部的操作都在高端操作系统MVS上执行。所以IBM继续销售IMS, Cullinaine也大量销售IDMS,而关系型系统不见踪影。
此时,VAX是关系型市场,大型机是非关系型市场。当时所有重要的数据管理都是在大型机上完成。
这种情况在1984年突然发生改变,IBM宣布即将发布基于MVS的DB/2。IBM从宣称IMS是核心数据库管理系统转变为双数据库策略:IMS和DB/2都是战略性的。因为DB/2是新技术,有更容易使用,每个人都很清楚谁将是最终赢家。
IBM发出的关于关系型系统的重要信号是一个重大转折事件。首先立即并完全结束了“大辩论”。当时IBM占有大量市场份额,它在实质上宣布了关系型系统的胜利,以及CODASYL系统和层级型系统的失败。不久之后,Cullinaine和IDMS市场份额迅速下降。其次,IBM成功的让SQL成为关系型语言的事实标准。其他(更好的)查询语言,比如QUEL,立刻消亡。要了解对SQL语义的重要批评,可以参考[DATE84]。
这里有必要介绍一个冷知识。对IBM来说,为IMS提供一个关系型前端是很自然的,如图7所示。这个架构允许IMS用户继续运行IMS,新应用可以使用关系型接口,提供了一个迁移到新技术的优雅方案。不断将DL/1迁移到SQL,同时可以保留IMS的高性能基础。
实际上IBM尝试过执行这个策略,建立了名为“鹰”的项目。很不幸事实证明在IMS的逻辑数据库概念上实现SQL非常困难,存在一些语义障碍。IMS逻辑数据库的复杂度困扰了IBM好几年。最终IBM不得不转向双数据库战略,在实际上宣布了“大辩论”的赢家。
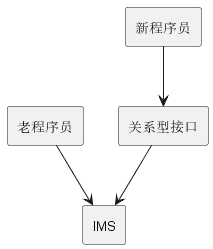
图7 鹰项目架构
总之,CODASYL和关系型系统的争论最终由3个事件决定: a) VAX系统的成功 b) CODASYL引擎无法移植 c) IMS逻辑数据库过于复杂
我们从这个时代得到的经验有:
经验7
无论使用何种数据模型,“逐集合”语言都很好,它改进了物理数据独立性。
经验8
简单数据模型比复杂模型更容易实现逻辑数据独立性。
经验9
技术争论的结果往往由市场巨头决定,和技术本身关系不大。
经验10
查询优化器可以战胜大部分程序员,除了顶级的“逐记录”数据库管理系统程序员。
6. 实体-关系时代
在1970年代中期,陈品山(Peter Chen)提出了关系-实体(E-R)数据模型,作为关系型模型、CODASYL和层级模型之外的方案。他的方案将数据库看作 实体 实例的集合。粗略地讲,实体是存在于数据库中,独立于其他实体的对象。在我们的示例中,供应商和零件就是实体。
此外实体拥有 属性 ,属性是描述实体性质的数据元素。例子中零件的属性是零件编号、零件名字、零件尺寸和零件颜色。属性中的一部分可以设定成是独有的,例如构成一个键。最后,不同实体之间可以存在关系。例子中供应是零件和供应商之间的关系,关系可以是“一对一”、“一对多”、“多对一”或“多对多”的,具体取决于各实体构成关系的方式。例子中供应商可能出售多种零件,零件也可以从不同的供应商采购。因此供给关系是“多对多”的。关系可以拥有描述自身性质的属性。例子中数量和价格是供应关系的属性。
实体-关系模型的常见表示法是图8中的“方框和箭头”符号。实体-关系模型从未成为数据库管理系统的底层数据模型。也许是因为没有配套的查询语言,也许是因为被1970年代关系型模型热潮所掩盖,也许是因为看起来像是CODASYL的简洁版本。无论出于何种原因,实体-关系模型在1970年代没有得到充分发展。

图8 实体-关系图
实体-关系模型在数据范式设计领域非常成功。设计关系型模型的最佳实践是一开始构造一组表,然后在初始设计上使用规范化理论。1970年代,人们提出了多个范式,包括第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和投影-连接范式。
在现实世界的数据库中使用范式理论存在两个难题。首先,数据库管理员会问:“我要从哪里获得一组初始表呢?”第二点也许更严重,范式理论基于函数依赖性概念,而数据库管理员可能不理解这种结构。因此使用范式理论设计数据库的工作停滞不前。
实体-关系模型反而成为非常流行的数据库设计工具。陈品山的文章提供了构造初始实体-关系图的方法。而把实体-关系图转换为符合第三范式的表非常容易,一些数据库管理工具就可以执行这样的转换。因此数据库管理员可以用矩形和箭头画出数据的实体-关系模型,然后自动转换成一个良好的关系模型。几乎所有的数据库设计工具,比如Magna Solutions的Silverrun、Computer Associates的ERwin和Embarcadero的ER/Studio都支持这个功能。
经验11
功能依赖性理论对普通人来说难以理解。“易于理解”是“保持简易”原则的原因之一。
7. R++时代
在1980年代早期,下列模式的论文大量出现:
- 考虑一个X应用
- 用关系型数据库管理系统实现X应用
- 指出查询困难或性能糟糕的原因
- 向关系型模型添加新“特性”解决问题
人们对很多这样的X应用进行了分析,包括机械CAD、VLSI CAD、文本管理、时间和计算机图形应用。这些论文构成了R++时代,它们都为关系模型提出了扩展。我们觉得其中最好的是Gem[ZANI83]。扎尼奥洛提出在关系型模型上增加下面的构造,并对应的扩展了查询语言:
1) 枚举属性。 例如在零件表中,通常有一个属性叫做“可选颜色”,包含一个值集合。在关系模型中添加处理值集合的数据类型很好。 2) 聚合(将元组引用作为数据类型)。 前面的供应关系有两个 外键 :供应商编号和零件编号。它们高效的指向其他表中的元组。让供应表具有如下结构会更简洁:
供应(PT,SR,数量,价格)
其中数据类型PT是“零件表元组”,SR是“供应商表元组”。当然,这些数据类型可能通过某些指针实现。有了这样的结构,我们可以用下面的方法查询销售红色零件的供应商:
SELECT 供应.SR.供应商编号 FROM 供应 WHERE 供应.PT.零件颜色 = "红色"
“级联点”符号允许程序员在查询供应表时高效的引用其他表中的元组。级联点符号和LSL等高阶网络语言中的路径表达式相似,允许程序员遍历多个表,无需使用显式连接。
3) 归纳。 假设在示例中有两种零件:电子零件和管道零件。对于电子零件,我们记录下能耗和电压,对管道零件,记录直径和管道材料。如图9中所示,根零件有两个特例,每个特例继承了祖先节点的全部数据属性。
Planner和Conniver等早期程序设计语言已经支持继承层级,近期的C++等语言也包含类似的概念。Gem只是将这个广为人知的概念引入数据库。
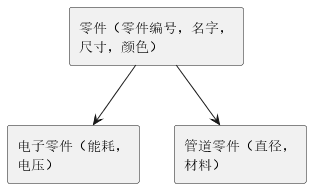
图9 继承层级
在Gem中,程序员可以在查询语言中引用继承层级。例如要查找红色电子元件,我们可以:
SELECT E.零件名字 FROM 电子元件 E WHERE E.颜色 = "红色"
此外,Gem支持优雅的空值处理方案。
这类扩展的问题在于,虽然可以提供比传统关系模型更简单的查询方法,但是只给出了很有限的性能改进。例如关系模型中的“主键-外键”关系可以轻易的模拟“元组作为数据类型”概念。既然外键实质上是逻辑指针,这种结构的性能表现与使用其他指针方案的系统接近。因此Gem实现不可能比关系模型实现快得多。
在1980年代早期,关系型系统供应商专注于改进事务性能和系统扩展性,让系统支持大规模商业数据处理应用。这是个大市场,有着巨大的利润空间。相对而言,R++思想影响有限,没有多少技术将R++思想带进商业领域,这些研究的长期影响很小。
经验12
除非提供了巨大的性能或功能改进,否则新构造将无立足之地。
8. 语义数据模型时代
与此同时,另一个学派有着类似的思想和不同的营销策略。他们认为关系数据模型“缺乏语义”,不能轻松表达某一类数据的关注点,因此需要一种“超越关系”数据模型。
超越关系数据模型通常称为语义数据模型,包括Smith和Smith[SMIT77]、Hammer和McLeod [ham81]等人的工作。Hammer和McLeod提出的SDM显然是更精巧的语义数据模型。本节我们将重点讨论它的概念。
SDM关注于 类 概念。类是一组具有相同模式的记录。与Gem相似,SDM使用“聚合”与“通用”概念,并引入了集合概念。SDM允许一个类包含其他类的记录作为属性,以此支持聚合概念。同时SDM扩展了Gem中的聚合构造,允许类的属性是其他类实例的集合。例如两个类“船只”和“国家”。“国家”类可以具有属性“本地注册船只”,值是一个“船只”集合。相反的,SDM也可以定义“船只注册地国家”属性。
此外,一个类可以归纳其他类。与Gem不同,归纳结构可以是图,而不仅仅是树。例如图10显示了一个归纳图,其中“美国油轮”同时从“油轮”和“美国船只”继承属性。这种结构叫做多重继承。一个类可以是其他多个类的并集、交集或差集,也可以是某个类的子类,由谓词确定其成员。例如, “重船”可以是“船只”中重量大于500吨的子类。最后,一个类也可以是由其他原因组合在一起的记录集合。例如“大西洋舰队”是一同跨越大西洋的船只集合。
最后,类可以拥有类变量,例如“船只”类可以有一个类变量,记录类成员的数量。
大部分语义数据模型非常复杂,通常都是理论方案。在SDM出现的几年之后,Univac尝试实现Hammer和McLeod的想法。然而他们很快发现SQL是通行标准,不兼容的系统在市场上并不成功。
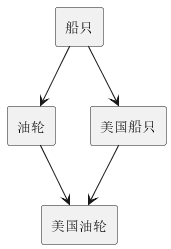
图10 多重继承示例
我们认为SDM存在和R++方案相同的两个问题。和R++一样,很多机制可以轻易在关系系统中模拟。方案提出的结构几乎没有实际作用。SDM阵营还面临着R++的第二个问题:供应商为事务处理性能分心。语义数据模型没什么长远影响。
9. 面向对象时代
从1980年代中期开始,出现了关注面向对象数据库管理系统的浪潮。社区发现关系型数据库和C++等编程语言之间存在对象失配问题(译注:impedance mismatch在物理学中翻译为“阻抗失配”。考虑到计算机领域内没有“阻抗”概念,此处译为“对象失配”)。
现实中关系型数据库拥有自己的命名体系、数据类型体系,以及返回查询结果数据的规范。配合关系型数据库使用的编程语言,无论是哪一种,也都有着自己独立的体系。因此集成应用和数据库需要对编程语言和数据库语言进行转换。就像把“苹果粘到煎饼上”(译注:苹果是立体的,煎饼是扁平的,比喻两个对象不匹配),因此叫做对象失配。
例如考虑下面的C++代码片段。它定义了零件结构体,分配了一个Example_part对象。
struct Part {
int number;
char* name;
char* bitness;
char* color;
} Example_part;
所有SQL运行时都支持利用数据装配结构体的方法。例如要获取零件16,装配成上面的结构体,可以使用下面的程序:
Define cursor P as
SELECT *
FROM 零件
WHERE 零件标识=16;
Open P into Example_part
Until no-more {
Fetch P(Example_part.number = pno,
Example_part.name = pname,
Example_part.bigness = psize,
Example_part.color = pcoor)
}
首先定义一个游标包含SQL查询结果。然后打开游标,取出一条记录,绑定到编程语言变量。变量的名字可以和数据库列名不同。运行时执行所需的数据类型转换。
现在程序员可以在编程语言中使用结构体。如果查询结果包含多条记录时,需要像例子那样遍历游标。
把数据库管理系统功能更紧密的集成到编程语言中是更简洁的方案。一些程序员可能喜欢持久编程语言,例如变量可以同时表示磁盘数据和内存数据,并且数据库检索方法同时也是编程语言构造。1970年代晚期发展出一些持久编程语言原型,包括Pascal-R、Rigel和一种PL/1内嵌语言。例如Rigel允许将上述查询表达为:
For P in 零件 where P.零件标识 = 16 {
操作零件的代码
}
在Rigel这类持久编程语言中,变量(例子中的pno)可以是声明式的。在Rigel里变量只需要声明一次,不需要在编程语言和数据库管理系统中分别声明。此外谓词“p.零件标识=16”是Rigel语言的一部分。最后,程序员使用编程语言内置的迭代方法(例子中的for循环)遍历查询记录。
持久编程语言显然比嵌入SQL更简洁。但这需要程序语言编译器支持数据库管理系统功能扩展。因为程序设计语言没有统一规范,这种扩展必须由每一个编译器单独完成。每个扩展都是独立的,例如C++就和APL非常不同。
很不幸,编程语言专家拒绝关注通用的I/O功能或特定的数据库管理系统功能。因此我们常用的编程语言都没有这方面的内置特性。这不仅让嵌入的数据子语言变得繁琐,也让编码和错误处理更加困难。最后,语言专家没有向报告撰写人那样,投入到重要的特定目标面向数据语言,即第四代语言中。
因此1970年代关于持久编程语言的研究没有为商业市场贡献任何技术,丑陋的内嵌数据子语言开始流行。
在1980年代中期对持久编程语言的兴趣得到复苏,动力来自于C++的流行。这次研究的潮流叫做面向对象数据库,主要关心C++对象持久化。虽然早期的工作来自于Garden、Exodus等系统的研究社区,主要推动力则来自于一些初创企业,包括Ontologic、Object Design和Versant。所有发布的商业系统都支持持久化C++。
这些系统通常将C++作为数据模型,每个C++结构体都可以持久化。出于某些原因,从10年前的实体-关系模型里直接借用“关系”概念,对C++进行扩展的方法非常流行。许多系统对C++运行时进行扩展,支持这个概念。
大部分面向对象数据库社区决定将工程数据库作为目标市场。这个领域的典型例子是CAD。在CAD程序中,工程师打开一个工程图,例如一个电路,接着修改工程对象,测试或在电路上运行模拟器。结束后关闭对象。这类程序的常见模式是打开一个大型工程对象,执行大量处理,然后关闭对象。
传统上这些对象通过一个装配程序读取到虚拟内存中。装配程序“重组”磁盘上的对象,组成虚拟内存中的C++对象。“重组”一词表示在装配过程中需要修改对象指针。在磁盘上,指针通常是类似外键的某种逻辑指针,也可以是磁盘指针(如块号、偏移量等)。在虚拟内存中,指针是虚拟内存地址。装配程序需要重组磁盘对象,产生虚拟内存对象。接着代码操作对象,通常会执行很长一段时间。处理完毕后,拆解程序将C++对象顺序排列,持久化到磁盘。
要占领工程市场,持久化C++实现需要满足下列需求:
- 不需要声明式查询语言。只要提供在C++中引用磁盘上的大型工程对象的方法。
- 不需要花哨的事务管理。这个市场几乎都是单个用户在处理大型工程对象。当然,提供某种版本管理系统会很好。
- 运行时系统在操作对象时,可以与传统的C++媲美。在这个市场中,持久化C++的算法性能需要能媲美传统C++和手动编写的装配程序。
显然面向对象数据库厂商专注于迎合这些需求。因此对事务和查询的支持薄弱。相反厂商关注于在操作持久化C++结构体时提供良好的性能。例如,考虑下面的声明:
persistent int i;
以及代码片段:
i =: i + 1;
在传统C++中这是一条指令。为了提供接近的性能,增加一个持久变量的值时,不能产生进程切换进行持久化对象。因此数据库管理系统必须和程序运行在同一个地址空间中。类似的,工程对象需要尽可能缓存在主存中,延迟写回磁盘。
因此Object Design等商业面向对象数据库采用创新架构实现目标。
很不幸,工程应用市场并没有发展壮大,太多的厂商争夺一个小众市场。所有的面向对象数据库厂商要么失败,要么转型提供其他商品。例如Object Design公司更名为Excelon,开始销售XML服务。
在我们看来,这个市场失败的原因有:
- 缺乏实际用途。面向对象数据库厂商提供给客户的便利是不用编写装配程序和拆解程序。这不是个重要的服务,客户不会愿意为此支付大笔金钱。
- 缺乏标准。所有面向对象数据库厂商的产品互不兼容。
- 重新链接一切。如果某个操作数据的C++方法发生改变,所有使用这个方法的程序都需要重新链接。这是一个严重的管理问题。
- 缺乏编程语言统一支持。如果企业有一个独立的非C++程序需要访问数据,将无法使用任何面向对象数据库产品。
当然面向对象数据库产品不是为商业数据处理应用而设计的。不仅缺乏强大的事务和查询系统,还和应用程序运行在同一个地址空间中。这意味着应用可以无限制的操作所有磁盘数据,无法实现数据保护。在商业数据处理市场中,保护和授权非常重要。此外面向对象数据库明显回退到了CODASYL时代,使用低级别的“逐记录”语言和手动编写的查询优化算法。因此这些产品没能渗透巨大的数据库市场。
有一家叫做O2的公司有着不同的商业计划。O2支持面向对象数据模型,但不使用C++。他们将一个高阶声明式语言OQL嵌入到编程语言中。他们提供的是接近于一个带有声明式查询语言的语义数据模型,包装成面向对象数据库。而且他们关注的是商业数据处理,而非工程应用领域。
O2也很不幸。俗语道“看美国,知天下”。新产品必须在北美证明自己。其他地区时刻关注着美国市场的接受程度。O2是一家法国公司,由弗朗索瓦·班西仑从法国国家信息与自动化研究所分拆创立。由于前面的俗语,O2虽有先进产品,却难以吸引欧洲市场。O2意识到需要获取美国市场,搬迁到美国的时候已经太迟了。太迟了,面向对象数据库时代已经堕入漩涡。如果O2创设在美国,拥有美国风险资本支持,它的市场机会如何呢?这是个有趣的猜想。
经验13
除非用户面临重大困难,产品无法销售给他们。
经验14
如果没有编程语言社区支持,持久语言无立足之地。
10. 对象-关系型时代
对象-关系型时代缘起于一个简单的问题。INGRES创立之初,团队被地理信息系统(GIS)所吸引,提出了支持GIS的机制。1982年左右,下面这个简单的GIS问题困扰着INGRES研究团队。如果开发者希望在数据库中保存地理位置信息,例如需要保存一组交汇点:
交汇点(交汇点标识,经度,纬度,其他数据)
我们需要在数据库中保存地理点(经度,纬度)。如果我们要查找矩形(经度0,纬度0,经度1,纬度1)中的交汇点,SQL查询是:
SELECT 交汇点标识 FROM 交汇点 WHERE 经度0 < 经度 < 经度1 AND 纬度0 < 纬度 < 纬度1
很不幸,这是一个二维查询。INGRES中的B-树是一维访问方法,无法高效执行二维搜索,因此关系型系统无法快速执行这类查询。
“通知土地主人”问题更麻烦。在加州,只要有人要求变更某块土地的划分,必须举行公开听证,通知一定距离内的土地主人。
假设所有土地都是矩形,保存在下面的表中。
土地(土地标识,最小经度,最大经度,最小纬度,最大纬度)
开发者需要扩展问题中的土地矩形,扩张合适的距离,使用坐标(经度0,经度1,纬度0,纬度1)建立一个“超矩阵”。通知所有与超矩阵相交的土地的主人。处理这个任务的最高效的查询是:
SELECT 土地标识 FROM 土地 WHERE 最大经度 > 经度0 AND 最大纬度 > 纬度0 AND 最小经度 < 经度1 AND 最大纬度 < 纬度1
使用B-树访问方法同样无法高效执行这种查询。此外,程序员需要一点时间来确认查询语句是正确的,因为同时存在几种性能一般的查询方法。总之,即使是简单的GIS查询也很难通过SQL表达,并且在标准B-树上执行时的性能非常糟糕。
下面的观察结果推动了对象-关系型方案的发展。早期关系型系统支持整数、浮点数、字符串和常见运算符。主要因为它们是IMS支持的数据类型,而IMS正是关系型系统最初的竞争对手。而IMS选择这些数据类型,则因为它们是目标市场——商业数据处理所需要的。关系型系统选择了B-树,因为可以提升商业数据处理中常见查询的性能。后来关系型系统扩展了商业数据处理数据类型,支持日期、时间和货币。最近又新增了紧凑十进制数和二进制块。
在GIS等其他市场中,这些不是合适的数据类型,B-树也不是合适的访问方法。要占领特定市场,产品必须提供市场所需的数据类型。厂商想要占领的细分市场众多,将产品与一组特定数据类型和索引策略绑定是不合适的。相反应当允许用户自行添加需要的类型,例如定制数据库管理系统来满足特定需求。这样的定制功能对商业数据处理非常有用,每过一段时间就会有新的数据类型需求出现。
所以对象-关系型方案向SQL引擎增加了
- 自定义数据类型
- 自定义运算符
- 自定义函数,以及
- 自定义访问方法
主要的对象-关系型研究原型是Postgres。
将对象-关系型方法应用到GIS时,人们只是新增了地理点和地理矩形数据类型。有了它们,上面的表可以表达为
交叉点(交叉点标识,地理点,其他数据) 土地(土地标识,土地矩形)
当然,产品必须具有与数据类型相应的SQL运算符。在这个应用中,运算符是“!!”(点在矩形中)和“##”(矩形相交)。上面的两个查询变成:
SELECT 交叉点标识 FROM 交叉点集 WHERE 点 !! "经度0,经度1,纬度0,纬度1"
和
SELECT 土地标识 FROM 土地集 WHERE 土地矩形 ## "经度0,经度1,纬度0,纬度1"
要支持自定义运算符,数据库要允许程序员指定一个自定义函数执行运算。因此对于上面的例子,我们需要函数:
Point-in-rect(点,矩形)
和
Box-in-box(矩形,矩形)
这两个函数返回布尔值。在计算运算符时,数据库调用函数,传入两个参数,对运算结果执行适当的操作。
要占领GIS市场,厂商需要像四叉树、R-树这样的多维索引系统。总值,一个高性能GIS数据库管理系统可以通过合适的自定义数据类型、自定义运算符、自定义函数、自定义访问方法构造出来。
Postgres的主要贡献是指出了这种扩展性质所需要的引擎机制。之前的关系型引擎都是通过硬编码来支持特定的数据类型、运算符和访问方法。必须抛弃硬编码逻辑,替换成更灵活的架构。[STON90]介绍了Postgres模式细节。
我们今天使用的自定义函数还有另外一个起源,就是1980年代中期Sybase率先在数据库管理系统中引入 存储过程 。初始的想法是在TPC-B测试中提供更好的性能。TPC-B使用下面的命令模拟兑现支票业务:
BEGIN TRANSACTION UPDATE account SET balance = balance - X WHERE account_number = Y UPDATE teller SET cash_drawer = cash_drawer - X WHERE teller_number = Z UPDATE bank SET cash = cash - Y INSERT INTO log(account_number=Y, check=X, Teller=Z) COMMIT
这个事务需要在数据库系统和应用之间进行5-6轮消息传递。对于简单的处理过程,上下文切换成本昂贵,严重制约了系统性能。
定义一个存储过程,降低切换时间就成为了更聪明的方法:
DEFINE cash_check (X, Y, Z)
BEGIN TRANSACTION
UPDATE account SET balance = balance - X
WHERE account_number = Y
UPDATE teller SET cash_drawer = cash_drawer - X
WHERE teller_number = Z
UPDATE bank SET cash = cash - Y
INSERT INTO log(account_number=Y, check=X, Teller=Z)
COMMIT
END cash_check
此时,应用只需要执行存储过程,传入参数,例如:
EXECUTE cash_check ($100, 79246, 15)
相比之前的5-6轮消息传递,现在只需要数据库管理系统和应用通讯一次,大幅提高了TPC-B测试速度。为了提高TPC-B等标准性能测试成绩,所有厂商都实现了存储过程。当然这需要它们定义专用的(小型)编程语言执行控制流,处理错误消息。存储过程必须能够正确处理各种条件,例如“账户余额不足”。
实际上存储过程是使用专用语言编写的自定义函数,而是僵化的,只能使用常量作为参数执行。
Postgres的自定义数据类型和自定义函数扩展了上述概念,支持在处理SQL查询时,调用由通用编程语言编写的代码。
Postgres为自定义数据类型、自定义函数和自定义访问方法实现了一套复杂的机制。此外,Postgres也实现了继承、指针(引用)类型构造函数、集合和数组概念。这些特性让Postgres在面向对象潮流鼎盛时期成为“面向对象式”系统。
后来Bucky等人的基准测试工作表明,Postgres的主要优势在于自定义数据类型和自定义函数。在传统关系型系统上模拟面向对象结构非常容易且高效。这项工作再次证明了R++和SDM开发者数年前已经发现的事实:支持聚合和通用仅仅带来微弱的性能收益。换句话说,对象关系型模型的主要贡献是为存储过程和自定义访问方法提供了更好的机制。
对象-关系型模型在商业上获得了一些成功。Illustra公司对Postgres进行了商业开发。经过最初几年苦苦寻求市场之后,Illustra赶上了“互联网浪潮”,成为“数字空间专用数据库”。如果开发者想在数据库中存储文本和图像,并与传统数据类型结合,Illustra引擎可以实现这个目标。在互联网浪潮达到顶峰时,Informix收购了Illustra。从Illustra看来,联手Informix的原因有两个:
a) 每个对象关系型应用内都有事务处理子程序。要在这个领域取得成功,必须具有高性能联机事务处理引擎。Postgres从未关注联机事务处理性能,添加这些特性的成本非常高。将现有功能整合到一个高性能引擎中更有意义。
b) 为了获取成功,Illustra需要说服其他供应商将自己的软件套件转换为自定义数据类型和自定义函数。这是项庞大工作,很少有厂商愿意参与,除非Illustra能够证明对象关系型系统有着巨大的市场机会。Illustra遇到了“先有鸡还是先有蛋”的问题:要获得市场份额,需要支持自定义数据类型和自定义函数;要支持自定义数据类型和自定义函数,需要市场份额。
Informix提供了解决问题的方案,合并后的新公司成功的将面向对象关系型技术推向GIS市场和海量内容仓库(如美国有线电视新闻网和英国广播公司所设想的)市场。然而对象关系型系统仍被商业数据处理市场排除在外。当然Informix公司的财务困境让新技术推广遇到困难,阻碍了对象关系型系统的广泛应用。
对象关系型技术逐渐被市场接受。例如,用自定义函数实现数据挖掘算法效率更高。数据挖掘概念由Red Brick创建,近期被甲骨文公司采纳。将TB级数据移动到中间件的处理代码中,不如将代码移到数据库管理系统效率高,可以减少所有通信开销。近期我们看到,对象关系型技术也开始用于支持XML处理。
在更广泛的商业市场中,对象关系型技术受到的障碍之一是缺少标准。每个厂商都有独立的定义和调用函数的方法,大多数厂商都支持Java自定义函数,但微软不支持。除非(直到)主要厂商就定义和调用规范达成一致,对象关系型技术不会得到迅猛发展。
经验14
对象关系型系统有两个主要优势:将代码放入数据库(模糊了代码和数据的差别),以及自定义访问方法。
经验15
新技术的广泛应用及需要制定标准,也需要大力推广。
11. 半结构化数据
在过去的五年中,关于“半结构化”数据的工作大量涌现。最初的例子是[MCHU97]的方案。最近的各种基于XML的方案都具有相似风格。目前XMLSchema和XQuery是基于XML数据的标准。
这类工作体现出两个基本点:
- 模式最后
- 复杂的面向网络的数据模型
我们将本节分别讨论这两点。
11.1. 模式最后
第一点是不需要预制模式。 “模式优先” 系统需要首先设置模式,然后加载符合模式的数据记录实例。因此数据库始终与预制模式一致,数据库管理系统拒绝任何与模式不匹配的记录。以前所有的数据模型都要求数据库管理员首先设定模式。
在这类方案中,不需要提前设定模式,可以最后设定,甚至没有模式。在 “模式最后” 系统中,数据实例必须具有自描述性质,因为可能不存在为数据记录提供意义的模式。如果缺少自描述性质,记录只是“一串比特”。
要产生一个自描述记录,需要用描述属性含义的元数据标记属性。下面是几个手动标记示例:
Person:
Name: Joe Jones
Wages: 14.75
Employer: My_accounting
Hobbies: skiing, bicycling
Works for: ref (Fred Smith)
Favorite joke: Why did the chicken cross the road? To get to the other side
Office number: 247
Major skill: accountant
End Person
Person:
Name: Smith, Vanessa
Wages: 2000
Favorite coffee: Arabian
Passtimes: sewing, swimming
Works_for: Between jobs
Favorite restaurant: Panera
Number of children: 3
End Person
可以看出两条记录分别描述了两个人,每个属性符合下列三个特征之一:
- 它只出现在一条记录中,在另外的记录里没有。
- 它只出现在一条记录中,但在另外的记录中,存在含义相同的属性(例如Pastimes和Hobbies)。
- 它同时出现在两条记录中,但格式或含义不同(例如Works_for和Wages)
显然比较这两条记录很难。这是一个 语义异构 的例子:描述公共对象(本例中的人员)的信息不服从共同表示规范。语义异构给查询带来了麻烦,缺少了可以作为建立索引决策和查询执行策略的基础的结构。
“模式最后”的倡导者关注的应用是这样的:用户将数据作为自由文本输入,例如使用文字处理程序(可以使用简单的元数据对文档结构添加注解)。此时,要求在用户添加数据前提供模式是不合理的。“模式最后”的倡导者会考虑对输入数据进行自动或半自动标记,构造上述的半结构化记录。
相反,如果有一个用于输入数据的业务表单(对前面的人员数据来说是很自然的),“模式优先”方法已经在发挥作用了。设计表单的人通过设定允许输入的内容,在实值上定义了模式。因此“模式最后”主要适用于以自由文本作为输入的应用。
为了分析“模式最后”的效果,我们提出了下面的模式,将应用分为四类:
- 具有严格结构化数据
- 具有严格结构化数据和一些文本
- 具有半结构化数据
- 具有文本
严格结构化数据必须服从模式要求,通常包括业务流程所操作的所有数据。例如考虑一个典型的公司工资单数据库,数据必须严格遵守结构,否则打印程序可能产生错误结果。人们不能容忍业务流程所依赖的数据丢失或格式错误。对于严格结构化数据,应当坚持“模式优先”。
大公司的人事记录是典型的第二类数据应用。有很多严格结构化的数据,例如职工的健康计划和附加福利。还有一些自由文本字段,例如经理在考核员工时的评论。员工考核表单通常是严格严格的,唯一可以输入自由文本的地方是评论框。同样的,在这里“模式首先”是正确的方法,应用很容易使用支持文本数据类型的对象关系型数据库管理系统实现。
第三类叫做半结构化数据。我们想到的最好的例子是招聘广告和简历。数据具有一些结构,但是数据实例展示的字段和表现方式大有不同,也不存在实例必须遵循的模式。半结构化数据通常以文本文档方式输入,解析并寻找重要信息,“分解”到存储引擎中合适的字段中。这时“模式最后”是个好主意。
第四类数据是纯文本:没有结构的文档。此时没有明显的结构可以利用。几十年来,信息检索系统一直关注这类数据。信息检索研究者对半结构化数据没有兴趣,他们关注的是基于文档文本内容的检索方法。这里没有可以进行归纳的模式,即“没有任何模式”。
“模式最后”访问只能处理上述分类中的第三类数据。除了简历和广告,很难想出例子。支持者(学者居多)认为大学课程简介符合这类特点。然而我们所了解知道的每所大学都有严格的课程简介格式,包含若干个文本框。大多都有一个输入数据的标准表单,和一个系统(手动或自动)拒绝不符合格式的课程简介。因此课程简介是第二类数据,不是第三类。在我们看来,对第三类数据进行仔细检查的应用,将产生更少的第三类数据实例。此外,最大的简历网站(Monster.com)近期开始采用数据输入商业表单。他们已经从第三类切换到第二类,大概是为了让数据实例更加一致(从而更容易比较)。
语义异构问题在企业中存在已久。企业在数据仓库项目上花费大量资金,设计标准模式,将运营数据转换成标准模式。在大多数组织中,语义异构在数据库的基础上进行处理,也就是说,对不同模式的数据统一处理。数据仓库项目常常预算超支,模式同质化工作非常困难。每个“模式最后”应用必须面对逐记录处理时的语义异构问题,这个问题的成本更高。这也是尽量避免“模式最后”的一个理由。
总之,“模式最后”只适用于上述分类中的第三类应用。这类里面很难找出令人信服的例子。如果要说点什么,当前趋势是将第三类应用迁移到第二类中,可能是为了让语义异构问题更好处理。最后,第三类应用似乎只有少量数据。因此,我们将“模式最后”数据库看作一个小众市场。
11.2. XML数据模型
现在我们转向XML数据模型。过去描述模式的方法是文档类型定义(DTD),在将来,数据模型将使用XMLSchema描述。DTD和XMLSchema用于处理格式化文档结构。它们看起来像文档标记语言,像是SGML的子集。由于文档结构可能非常复杂,这些文档规范标准必然也非常复杂。作为文档规范体系,我们对这些标准没有异议。
DTD和XMLSchema标准稳定之后,数据库管理系统研究者开始尝试用它们来描述结构化数据。作为结构化数据模型,我们认为二者都有严重缺陷。首先粗略地说,它们提供的方法都已经在之前的数据模型中给出过。而它们包含的新功能又太过复杂,以至于从未有人认真研究过。
例如使用XMLSchema表示的数据模型具有下列特性:
- XML记录可以拥有层级,如同IMS。
- XML记录可以通过“链接”引用其他记录,如同CODASYL。
- XML记录可以拥有枚举属性,如同SDM。
- XML记录可以从其他记录以多种方式派生,如同SDM。
另外XMLSchema的一些特性是数据库管理系统社区已经知道的,但由于过度复杂,从未在以往的数据模型中应用过的。例如联合类型:记录属性可以是一系列类型中的某一个。比如在人事数据库中,字段“为之工作”可以是企业部门编号,或借调员工的外部公司名字。此时“为之工作”可以是字符串或整数,分别表示不同含义。
联合类型上的B-树索引非常复杂。实际上,必须为联合类型中的每个基础类型分配索引。每个访问联合类型的查询也需要不同的查询计划。如果两个联合类型分别包含N和M个基础类型,在连接它们时,需要协调的查询计划数量至少是二者的最大值。由于这些原因,从未有人认真考虑过将联合类型引入数据库管理系统。
显然XMLSchema是迄今最复杂的数据模型。在“保持简易”(KISS)维度上,它和关系模型是两个极端。很难想象如此复杂的东西用作结构化数据模型。我们可以预见未来有三种情况。
情况1:XMLSchema因为过度复杂而失败。 情况2:人们提出一种非常简单的“面向数据”XMLSchema子集。 情况3:XMLSchema开始流行。十年之内,当初促使科德发明关系模型的在IMS和CODASYL中遇到的所有问题再次出现。到那时,某位雄心勃勃的研究员,假设叫做Y,掸去科德论文上的浮尘。“大辩论”将再次上演。故事以同样的方式结束。科德在1981年获得图灵奖,作为对其贡献的褒奖。在这个故事里,研究员Y将在2015年左右获得图灵奖。
公平地说,XML系列的支持者的确从历史中学到了东西。他们提出了“逐集合”查询语言XQuery,提供了某种程度的数据独立性。但如同CODASYL时代的发现,为网络数据模型提供视图非常困难(比关系型模型更难)。
11.3. 总结
对XML/XMLSchema/XQuery进行总结是一种挑战,因为涉太及多因素。显然XML将成为流行的网络即时数据传输格式。理由很简单:XML可以跨越防火墙,其他格式不行。两个企业的服务器之间总会设置防火墙,因此跨企业数据移动将使用XML。大部分企业希望采用相同的方式在内部和外部移动数据,有足够的理由相信,XML将称为统一的数据移动标准。
因此各种类型的系统和应用都必须准备好收发XML。将关系数据库产生的元组集合转换为XML很简单,对于关系型引擎,只需要一个自定义函数。将对象关系型引擎产生的元组集合转换成XML是简单的。对于拥有对象关系型引擎的人,只需要一个自定义函数。同样也可以使用另一个自定义函数,接受XML输入,转换成元组保存在数据库中。对象关系型技术简化了必要的格式转换,其他系统也同样需要转换机制。
构建在XML之上的高级数据移动机制(如SOAP)也将开始流行。显然可以跨越防火墙的远程过程调用将更加有用。因此SOAP比其他RPC方案具有优势。
我们怀疑原生XML数据库管理系统是否会变得流行。XML数据库管理系统需要十数年时间才能成为性能媲美当今主流产品的引擎。此外,“模式最后”只在特定市场中具有吸引力。过于复杂的网络模型违背了“保持简易”原则。XML模式需要一个简洁的子集,可以轻松映射到当前的关系型数据库管理系统。如此开发新引擎的意义何在?由此我们认为原生XML数据库管理系统是一个小众市场。
现在考虑XQuery。它的(核心)子集很容易映射到供应商的关系型SQL系统。例如Informix使用自定义函数实现了XQuery操作符“//”。在大多数现有引擎上实现XQuery子集相当简单。因此主流系统不太可能同时支持SQL和XMLSchema同XQuery的子集。后者将被转换为SQL。
XML有时被宣传成解决前文中提到的语义异构问题的方案。事实远非如此。两个人都将数据元素标记为“工资”,并不表示这两个数据具有可比性。可能一个是以法郎发放的包含了餐补的税后工资,另一个是以美元发放的税前工资。还有,如果你把一个数据叫做“橡胶手套”,而我称其为“乳胶护手”,那么XML无法确定二者是同一概念。因此XML的作用将仅限于提供构造公共模式的词汇表。
此外,我们相信使用公共模式的企业间数据共享进展缓慢。因为语义异构问题难以解决。虽然W3C在这个领域建立了语义网络项目,我们对其未来的影响并不乐观。毕竟几十年来人工智能社区一直在研究知识表示系统,但收效甚微。语义网络与这些工作非常相似。鉴于Web服务依赖于各系统间的信息传递,不要指望语义网络概念迅速取得成功。
更准确地说,我们认为企业间信息共享受制于:
- 在合作中获取较高经济价值的企业。航空公司多年来一直在不同预订系统间共享数据。
- 语义简单的应用程序(如电子邮件),数据类型是文本,不涉及复杂的语义翻译。
- 应用市场由巨头掌控。像沃尔玛和戴尔在同供应商共享数据时很少遇到困难。他们只需要说:“要是你想卖系统给我,就这样和我的系统进行对接。”如果有足够强大的巨头制定标准,企业间信息共享可以很轻松实现。
我们以一段讽刺的注解结尾。几年前,OLE-DB受到微软的大力推广,现在则是XML系列。微软推广OLE-DB是因为无法控制ODBC,并且认为OLE-DB存在竞争优势。现在微软认为Java和J2EE等跨平台扩展是一个巨大的威胁,所以大力推广XML和SOAP,试图阻止Java成功。
有充分的理由相信,几年后微软会在其他关于数据库管理系统的标准中发现竞争优势。就像OLE-DB被遗弃夭折,微软大概会把XML系列送上同样的命运旅途,当营销策略决定改变的时候。
不那么讽刺的说法是,技术进步不断改变规则。例如,未来几年进入市场的微型传感器技术将对系统软件产生巨大影响。我们预计数据库管理系统及其接口将受到某种(尚不明确方式)波及。
因此我们预计未来将出现一系列新的数据库管理系统标准。在不断变化的世界中,强大的适应性对数据库管理系统至关重要,这样才能处理好任何新的“大事件”。关系型数据库管理系统具有这种特性,原生XML数据库管理系统则没有。
经验16
“模式最后”是一个小众市场。
经验17
XQuery几乎就是语法不同的关系型SQL。
经验18
XML不能解决企业内部和外部的语义异构问题。
12. 轮回
本文研究了三十年来的数据模型思想。显然我们经历了一个“轮回”,从一个复杂数据模型开始,接着是复杂模型和简单模型的大辩论。简单模型在可理解性和支持数据独立性方面都展示出优势。
接着研究者提出了大量的扩展方案,但都没有获得市场关注,因为无法提供显著的效用,覆盖复杂度产生的成本。只有自定义函数和自定义访问方法得到了市场关注,但它们都是性能构造,不是数据模型构造。现在的方案是以往所有方案并集的超集。也就是说,我们已经走了一个轮回。
XML倡导者和关系型支持者之间的争论与四分之一世纪以前的首次“大辩论”非常相似:将简单数据模型同复杂数据模型进行比较,将关系型与“第二代CODASYL”进行比较。唯一的区别在于“第二代CODASYL”拥有高级查询语言。在“第二代CODASYL”中实现逻辑数据独立性将更加困难,因为它比第一代更复杂。
我们见证了历史的重演。如果原生XML数据库管理系统得到关注,客户会遇到逻辑数据独立性和复杂度问题。
要避免重蹈覆辙,最好站在前人的肩膀上,而非他们脚下。从整体上看,如果我们不吸取历史经验教训,必将再次犯错。
从更高的层次来讲,我们几乎没有看到新的数据模型思想。过去20年里提出的所有东西几乎都是在重新发明四分之一世纪前的方案。值得注意的新概念只有:
数据库内嵌代码(来自关系型阵营) 模式最后(来自半结构化数据阵营)
模式最后看来是一个小众市场,我们不认为它是突破性思想。数据库内嵌代码则是非常好的思想。在我们看来,设计一个让代码和数据具有平等地位的数据库管理系统非常有用。如此,数据库管理系统附加组件(如存储过程、触发器、警报)可以成为一等公民。关系型模型只完成了部分工作,也许现在是彻底完成这项任务的时候了。
13. 参考文献
略
14. 附录(18条经验)
经验1
物理和逻辑数据独立性非常重要。
经验2
树状模型存在很多限制。
经验3
为树状模型提供复杂的逻辑重组非常困难。
经验4
“逐记录”接口需要程序员执行手动查询优化,这很困难。
经验5
网络结构比层级结构更灵活,但也更复杂。
经验6
网络结构的加载和恢复工作远比层级结构复杂。
经验7
无论使用何种数据模型,“逐集合”语言都很好,它改进了物理数据独立性。
经验8
简单数据模型比复杂模型更容易实现逻辑数据独立性。
经验9
技术争论的结果往往由市场巨头决定,和技术本身关系不大。
经验10
查询优化器可以战胜大部分程序员,除了顶级的“逐记录”数据库管理系统程序员。
经验11
功能依赖性理论对普通人来说难以理解。“易于理解”是“保持简易”原则的原因之一。
经验12
除非提供了巨大的性能或功能改进,否则新构造将一事无成。
经验13
除非用户面临重大困难,产品无法销售给他们。
经验14
如果没有编程语言社区支持,持久语言一事无成。
经验14
对象关系型系统有两个主要优势:将代码放入数据库(模糊了代码和数据的差别),以及自定义访问方法。
经验15
新技术的广泛应用及需要制定标准,也需要大力推广。
经验16
“模式最后”是一个小众市场。
经验17
XQuery几乎就是语法不同的关系型SQL。
经验18
XML不能解决企业内部和外部的语义异构问题。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 回到原点再出发

发表评论 取消回复