完整的论文代码见文章末尾 以下为核心内容
摘要
本研究探讨了从MP3格式音频文件到MIDI格式文件转换的技术,着重分析了基于频域变换的方法及其在音乐处理领域的应用。MP3到MIDI的转换是一项具有挑战性的任务,它要求从压缩的音频信号中准确提取音乐信息,包括音高、节奏、和声以及动态表达等,并将这些信息转换为MIDI格式,后者以数字指令的形式描述音乐演奏的细节。本文首先回顾了MP3和MIDI格式的基本特征和应用背景,随后详细讨论了音频信号的频域分析技术,包括傅里叶变换和谐波分析等,以及这些技术在音高检测和节奏提取中的应用。之后实现了基于频域变换方法的转换格式算法,并评估了转换效果和准确率。
系统总体概述
频域变换与特征提取:本算法的核心是基于频域变换的特征提取技术。通过对输入音频信号进行快速傅里叶变换(FFT),算法能够有效分离音频中的各个频率成分,并通过音高跟踪技术(如YIN算法)精确地识别出音频信号中的音高信息。此外,利用声学模型识别出音符的起始点和静音段,算法能够准确地从连续音频流中提取出音符和节奏的信息。这一步骤是实现高质量音乐生成的基础,为后续的音乐符号转换提供了准确的音频特征数据。
概率模型的应用:为了处理音频信号中的不确定性和噪声,本算法采用了基于概率的模型来预测音符之间的转换概率。通过构建转移矩阵,算法模拟了音符到音符、音符到静音以及静音到音符的转换概率,从而在有限状态机的框架下高效地处理音频信号中的不确定性。此外,算法还估算了音高检测的准确性、音符的持续时间和音符之间可能的变化,进一步提高了音乐生成的质量和自然度。
音乐结构的重建:在提取音频特征并处理不确定性之后,算法需要将这些信息转换为音乐符号。本算法通过状态序列到钢琴卷帘(Piano Roll)表示的转换,将音符的起始时间、持续时间和音高等信息组织成一种中间表示形式,为生成MIDI文件奠定了基础。该步骤不仅简化了音乐结构的重建过程,还为后续的音乐编辑和处理提供了便利。
MIDI文件的生成:算法将内部的钢琴卷帘表示转换为标准的MIDI格式,完成从原始音频信号到数字音乐表示的转换。通过详细设定MIDI文件中的节拍、音符时值和音符强度等参数,算法能够生成具有高度音乐性的数字音乐作品。
概率模型的构建
概率模型的构建从定义状态空间开始。在本研究中,状态空间包括所有可能的音符和静音状态,每个音符状态进一步分为起始和持续两个子状态,以区分音符的开始和持续过程。接下来,基于音乐理论和声学分析,定义状态转移的概率。这包括从一个音符转移到另一个音符的概率、从音符转移到静音状态的概率以及静音状态持续的概率。
在定义了状态空间和状态转移概率之后,利用转移矩阵来表示概率模型。转移矩阵中的每个元素代表了从一个状态转移到另一个状态的概率。此外,考虑到音乐执行中的不确定性和变化性,模型还需要引入先验概率,以表示在没有任何外部信息时,某个状态出现的可能性。
在音频信号到MIDI转换的过程中,概率模型用于指导音符的识别和音乐结构的重建。通过与音频特征提取算法结合,模型可以预测每个时间点上最可能的音符状态,从而构建出音乐序列。
本项目中transition_matrix函数(代码如下)实现了概率模型的构建过程。该函数首先计算了音符范围内的每个音符对应的MIDI值,进而根据输入参数(如音符和静音状态持续的概率)构建了状态转移矩阵。矩阵中的每个元素代表了特定的状态转移概率,例如,从静音状态转移到某个音符起始状态的概率,或从一个音符的持续状态转移到另一个音符起始状态的概率。
def transition_matrix(
note_min: str,
note_max: str,
p_stay_note: float,
p_stay_silence: float) -> np.array:
midi_min = librosa.note_to_midi(note_min)
midi_max = librosa.note_to_midi(note_max)
n_notes = midi_max - midi_min + 1
p_l = (1 - p_stay_silence) / n_notes
p_ll = (1 - p_stay_note) / (n_notes + 1)
transmat = np.zeros((2 * n_notes + 1, 2 * n_notes + 1))
transmat[0, 0] = p_stay_silence
for i in range(n_notes):
transmat[0, (i * 2) + 1] = p_l
for i in range(n_notes):
transmat[(i * 2) + 1, (i * 2) + 2] = 1
for i in range(n_notes):
transmat[(i * 2) + 2, 0] = p_ll
transmat[(i * 2) + 2, (i * 2) + 2] = p_stay_note
for j in range(n_notes):
transmat[(i * 2) + 2, (j * 2) + 1] = p_ll
return transmat
音频信号特征提取
音频信号是音乐表达的物理载体,其特征提取过程依赖于对音频信号的频域分析。通过对音频信号进行快速傅里叶变换(FFT),我们可以将时间域的音频信号转换为频域表示,从而分析其频率成分。音高检测、音符起始点识别和音色分析等关键任务都可以在此基础上实现。音高检测关注于识别音频信号中的主导频率,而音符起始点识别则侧重于检测音乐中音符开始的瞬间,这些都是音乐信息检索的重要组成部分。本文的工作步骤如下:
预处理:为了提高特征提取的准确性和效率,音频信号首先经过预处理,包括去噪、标准化和分帧等。
频域变换:采用FFT或其变体将每帧音频信号从时间域转换到频域,获取其频谱表示。
音高检测:通过分析音频信号的频谱,识别出其中的音高信息。这一步骤可以使用自动音高检测算法实现。
音符起始点和静音段识别:音符的起始点通常伴随着能量的突然变化,可以通过检测能量或频谱变化来识别。静音段的识别则基于能量阈值判定。
特征融合与优化:将提取的各类特征进行融合和优化,以提高其对后续处理步骤的贡献度。
本文实现了prior_probabilities 函数,用于为音乐音频信号中每个音符的起始和持续状态以及静默状态计算先验概率。代码如下:
def prior_probabilities(
audio_signal: np.array,
note_min: str,
note_max: str,
srate: int,
frame_length: int = 2048,
hop_length: int = 512,
pitch_acc: float = 0.9,
voiced_acc: float = 0.9,
onset_acc: float = 0.9,
spread: float = 0.2) -> np.array:
fmin = librosa.note_to_hz(note_min)
fmax = librosa.note_to_hz(note_max)
midi_min = librosa.note_to_midi(note_min)
midi_max = librosa.note_to_midi(note_max)
n_notes = midi_max - midi_min + 1
pitch, voiced_flag, _ = librosa.pyin(
y=audio_signal, fmin=fmin * 0.9, fmax=fmax * 1.1,
sr=srate, frame_length=frame_length, win_length=int(frame_length / 2),
hop_length=hop_length)
tuning = librosa.pitch_tuning(pitch)
f0_ = np.round(librosa.hz_to_midi(pitch - tuning)).astype(int)
onsets = librosa.onset.onset_detect(
y=audio_signal, sr=srate,
hop_length=hop_length, backtrack=True)
priors = np.ones((n_notes * 2 + 1, len(pitch)))
for n_frame in range(len(pitch)):
if not voiced_flag[n_frame]:
priors[0, n_frame] = voiced_acc
else:
priors[0, n_frame] = 1 - voiced_acc
for j in range(n_notes):
if n_frame in onsets:
priors[(j * 2) + 1, n_frame] = onset_acc
else:
priors[(j * 2) + 1, n_frame] = 1 - onset_acc
if j + midi_min == f0_[n_frame]:
priors[(j * 2) + 2, n_frame] = pitch_acc
elif np.abs(j + midi_min - f0_[n_frame]) == 1:
priors[(j * 2) + 2, n_frame] = pitch_acc * spread
else:
priors[(j * 2) + 2, n_frame] = 1 - pitch_acc
return priors
状态序列到钢琴卷帘转换
在音频信号处理和自动音乐生成领域,将状态序列转换为钢琴卷帘(Piano Roll)表示是一个关键步骤,它桥接了音频信号分析与音乐符号表示之间的转换。状态序列,通常是通过概率模型或音频信号特征提取技术得到的音符状态时间序列,包含了音乐的基本信息,如音高、节奏和动态变化。钢琴卷帘转换的目的是将这些抽象的信息转化为更加直观和可操作的音乐表示形式,即钢琴卷帘图,这为最终生成MIDI文件或其他音乐表示提供了便利。
MIDI文件生成
本文生成MIDI文件的过程遵循以下几个步骤:
初始化MIDI文件:创建一个新的MIDI文件,并设定基本属性,如MIDI格式类型、轨道数以及时间分辨率。
添加MIDI事件:根据音乐数据(如钢琴卷帘表示),为每个音符添加对应的MIDI事件。这包括Note On(音符开始)、Note Off(音符结束)以及可能的控制改变和程序改变事件。
设定节奏和拍号:根据音乐作品的节奏和拍号信息,在MIDI文件中添加相应的元事件,以确保音乐在不同的设备上能够以正确的速度播放。
文件保存和导出:将MIDI事件序列编码为MIDI文件格式,并将文件保存到磁盘,以便于在MIDI兼容的软件和硬件上播放。
评估
频域变换效果分析
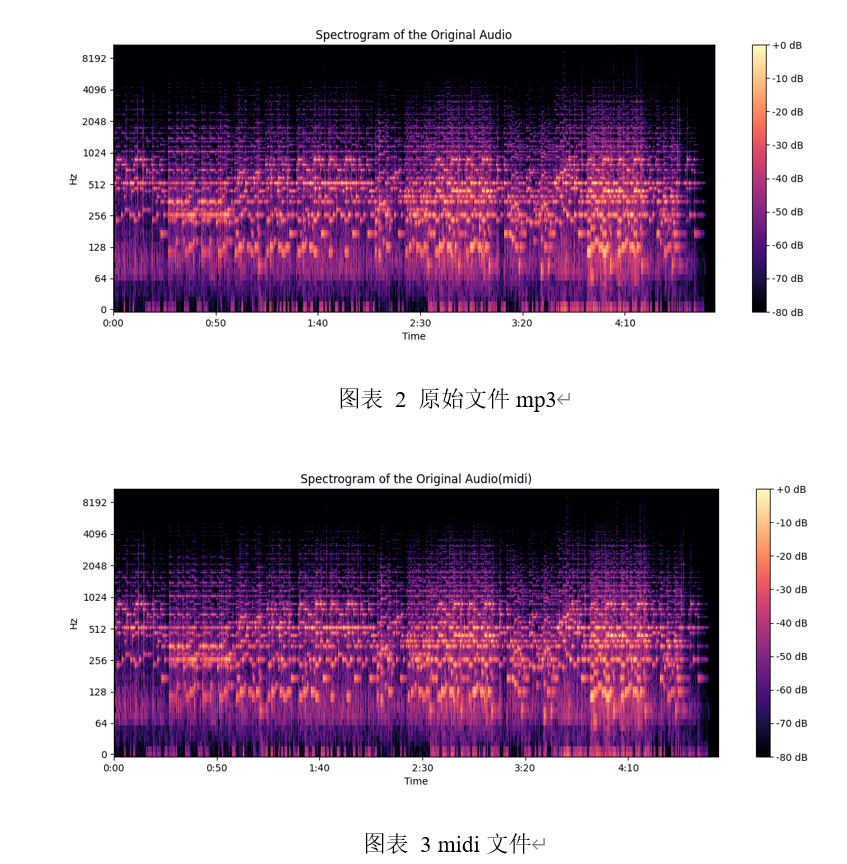
要评估频域变换的效果,需要关注频谱图的相似性,检测结果如下:
两个频谱图在这些关键方面有较高程度的相似性,则本文可以认为频域变换是有效的。这不仅表明音高和节奏信息被准确地捕捉和转换了,而且还证明了音频内容的整体特征和结构得到了保留。
MIDI生成质量
本文音高分析可以用来评估MIDI生成的质量,原因在于,音高是音乐中最基本的元素之一。如果MIDI文件中的音高与原始音频文件不一致,听众就会立刻察觉到差异,这直接影响到MIDI文件的实用性和音乐的表现力。旋律是音乐表达中至关重要的,它主要由一系列音高组成。音高分析可以确保转换过程中旋律的准确还原。在音乐中,和声是由同时响起的不同音高组成的。分析MIDI生成的音高能帮助确保和声的正确转换,这对于音乐的整体质感至关重要。
本文通过以下步骤实现:提取原始音频文件中的音高。从MIDI文件中提取音高信息。比较两者的音高序列,检查是否有显著差异。计算音高匹配的准确度。关键函数如下:
def extract_audio_pitches(audio_file_path, sr=44100):
# 读取音频文件并提取音高
y, sr = librosa.load(audio_file_path, sr=sr)
pitches, magnitudes = librosa.piptrack(y=y, sr=sr)
# 选取每个时间点上幅度最大的音高
pitch_indices = np.argmax(magnitudes, axis=0)
audio_pitches = pitches[pitch_indices, np.arange(pitches.shape[1])]
audio_pitches = audio_pitches[audio_pitches > 0] # 去除无音高的部分
# 将频率转换为MIDI音符编号
return librosa.hz_to_midi(audio_pitches)
def pitch_matching_rate(midi_pitches, audio_pitches):
# 对齐音高序列长度
length = min(len(midi_pitches), len(audio_pitches))
midi_pitches = midi_pitches[:length]
audio_pitches = audio_pitches[:length]
# 计算音高匹配的比例
matches = np.isclose(midi_pitches, audio_pitches, atol=1)
matching_rate = np.sum(matches) / length
return matching_rate
运行结果为,音高匹配率:96.94%。说明转换过程能够非常准确地捕捉到音频中的音高信息,并且能够正确地在MIDI文件中再现它们。
尽管匹配率很高,仍有约3%的音高没有匹配上。这可能是由于原始音频的噪声、音频质量问题,或者是转换算法的局限性。可能有些微妙的音乐细节没有被MIDI文件捕捉到,如装饰音、微弱的回声或者某些独特的表现手法。
获取方式
需要一点点辛苦费
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 毕业设计项目——基于频域分析的MP3格式音频文件到MIDI格式转换(论文/代码)

发表评论 取消回复