前言
这篇文章看起来有点像Photo-slam的续作,行文格式和图片类型很接近,而且貌似是出自同一所学校的,所以推测可能是Photo-slam的优化与改进方法,接下来具体看看改进了哪些地方。

1.背景介绍
- Nerf虽然有前景,但将NeRF集成到SLAM系统中遇到了几个障碍,包括高计算需求,长时间的训练,有限的泛化性,过度依赖视觉线索,以及对灾难性遗忘的敏感性。
- 现有的高斯飞溅SLAM (GS-SLAM)方法在处理有限数量的高斯原语时,难以在实时约束下实现卓越的渲染性能。这些问题源于算法的计算需求与可用处理资源之间的不一致,这可能导致训练和优化过程不足。
GS-SLAM方法总结
MonoGS和SplaTAM是对耦合GS-SLAM算法的开创性贡献,它们开创了一种通过梯度反向传播同时优化高斯原语和相机姿态估计的方法。Gaussian-SLAM引入了子地图的概念来解决灾难性遗忘的问题。此外,LoopSplat扩展了Gaussian- slam的工作,采用基于高斯飞溅的环闭合配准来提高姿态估计精度。然而,依赖于3DGS的密集计算来估计每帧的相机姿态,这对这些方法实现实时性能提出了挑战。
为了克服这一问题,人们提出了解耦的GS-SLAM方法。splat - slam和IG-SLAM利用预训练的密集束调整进行相机姿态跟踪,利用代理深度图进行地图优化。RTG-SLAM采用帧到模型的ICP进行跟踪,并通过关注最突出的不透明高斯函数来呈现深度。GS-ICP-SLAM通过利用G-ICP和3DGS之间的共享协方差,利用高斯原语的尺度对齐,实现了非常高的速度(高达107 FPS)。Photo-SLAM采用ORB-SLAM3进行跟踪,并引入了从粗到精的地图优化,实现了鲁棒性能。
2.关键内容
作者首先提出问题:GS-SLAM固有的计算偏差现象,接着分析了他的不利影响:T这种不对齐会严重影响计算效率,阻碍真实感渲染的快速收敛,对实时GS-SLAM的性能产生不利影响。最后提出了解决方案:为了克服这些障碍,我们提出了一种新的自适应计算对齐策略,该策略旨在加速3DGS过程,优化计算资源分配,有效控制模型复杂性,从而提高3DGS在实时SLAM应用中的整体有效性和实用性。
2.1 计算偏差
SLAM环境下真实感渲染中出现的计算偏差主要有三个方面:训练不足、长尾优化和弱约束致密化。这些因素降低了渲染质量,增加了地图尺寸。这些因素严重阻碍了GS-SLAM的实时应用,限制了其在资源受限设备中的适用性。
1)训练不足:与不受实时性限制的典型3DGS不同,SLAM领域内的在线渲染需要同时执行定位、建图和渲染,且速度与输入传感器数据的频率同步。为了实现这一点,目前大多数实时GS-SLAM方法都依赖于关键帧进行映射和渲染。然而,这些方法通常在渲染优化中总共只能实现几千次迭代,明显落后于3DGS的数万次迭代。由于训练不足,优化过程没有完全收敛,对在线渲染质量产生不利影响。
最近几位研究人员的观察表明,在3DGS中逐像素反向传播存在重大的计算挑战。由于多个GPU线程争夺访问共享高斯原语,这需要序列化原子操作,从而限制了并行化效率,因此该过程成为瓶颈。不幸的是,这个缺点被集成到以前的GS-SLAM实现中。在本文中,我们利用快速的飞溅式反向传播来减少线程争用。这种方法不仅实现了与基线相比迭代次数增加3倍,而且还保持了相同的运行时。这一进步显著缓解了训练不足的问题,大大提高了实时GS-SLAM的绘制质量。
2)长尾优化:为了减轻灾难性遗忘的问题,GS-SLAM中常见的方法是从关键帧池中随机选择一个关键帧进行周期性再训练。然而,这种方法可能导致次优的长尾优化,如图3所示。具体来说,最早的关键帧的再训练频率往往超过最近添加的关键帧。这种差异的产生是因为随着摄像机在环境中移动,关键帧池不断扩大,这可能导致再训练努力的分布不均匀,并且新传入关键帧的PSNR呈下降趋势。(所以才需要滑动窗口吧)
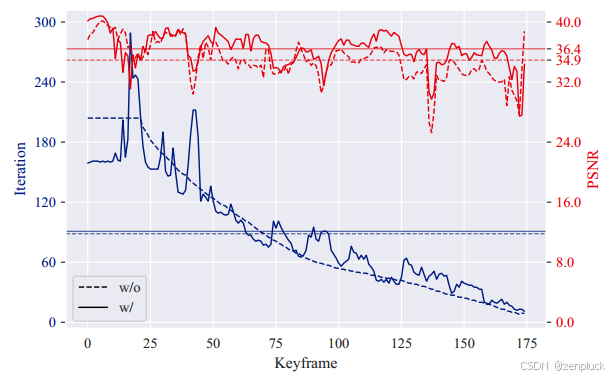
在本文中,我们提出了一种创新的自适应优化策略,即根据训练损失从池中选择再训练关键帧来抵消长尾效应。通过采用这种方法,我们的目标是提高具有较低PSNR值的关键帧的再训练频率。通过这样做,我们的自适应策略确保在关键帧池中更公平地分配再训练工作,优化每个关键帧对系统整体性能的贡献。
3)弱约束致密化:在GS-SLAM环境下,致密化是逼真渲染的关键组成部分,包括几何致密化和自适应致密化。几何致密化涉及将彩色点云转换为初始化的高斯基元,用于每个新识别的关键帧,为环境提供基本的几何结构。另一方面,自适应致密化使用分裂和克隆等操作来细化高斯原语,这些操作由梯度和原语本身的大小引导。这些致密化仅受简单修剪策略的限制,该策略消除了低不透明度的高斯原语。然而,新兴研究表明,这种方法不足以将模型的大小管理在最佳范围内。在本文中,我们引入了不透明度正则化损失来鼓励高斯原语学习低不透明度,从而不仅有利于修剪过程以消除不重要的原语,而且还保持了高保真渲染。
2.2 自适应计算对齐
为了解决实时GS-slam中真实感渲染的计算不对齐问题,我们提出了一种自适应计算对齐策略,称为CaRtGS。下面,我们将详细概述该策略的关键步骤。
1)快速飞溅反向传播:在传统的3DGS训练pipeline中,反向传播阶段的计算要求很高,因为它需要将梯度信息从像素传播到高斯基元。这个过程需要计算每个飞溅像素对
(
i
,
j
)
(i, j)
(i,j)的梯度,遵循聚合步骤。在每次迭代中,GPU线程
i
+
1
i+1
i+1应用标准
α
−
b
l
e
n
d
i
n
g
α-blending
α−blending逻辑从接收状态
X
i
,
j
X_{i,j}
Xi,j过渡到
X
i
+
1
,
j
X_{i+1,j}
Xi+1,j,并将更新后的信息整合到梯度计算中。这个过程可以用数学表示为:
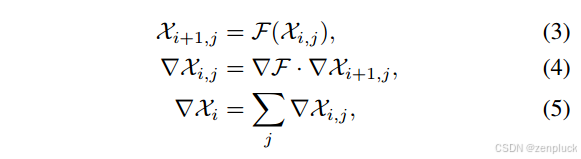
逐像素传播在GS-SLAM中广泛使用,将建图线程到像素并以相反的深度顺序处理splat。线程 j 按照拼合的顺序计算拼合的部分梯度,通过原子操作更新每个拼合的累积梯度。但是,这种方法可能导致线程之间争用共享内存访问,从而导致妨碍性能的序列化操作。
为了应对这一挑战,我们采用了一种新的并行化策略,将重点从基于像素的处理转移到基于飞溅的处理。这种策略允许每个线程独立地维护splat的状态,并有效地交换像素状态信息。线程 i 可以计算第 i 个splat的梯度贡献,需要在前 i 个splat混合后的像素 j 状态。
在向前传递期间,线程存储每N条像素的透光率T和累积颜色RGB,为后向传播做准备。这些存储状态包括初始条件 X + 0 , j , X N , j , ⋅ ⋅ ∀ j X+{0,j}, X{N,j},··∀j X+0,j,XN,j,⋅⋅∀j。在向后传递开始时,tile中的每个线程生成像素状态 X i , j X_{i,j} Xi,j。然后,线程进行快速协作共享以交换像素状态。
我们引入了以飞溅为中心的并行性,每个线程一次处理一个高斯飞溅,显著减少了争用。梯度计算依赖于一组逐像素、逐像素值,有效地遍历splat⇔像素关系表。在向前传递期间,我们为每32次飞溅保存像素状态。对于向后传递,splats被分组为32个bucket,每个bucket由CUDA warp处理。warp利用warp内部洗牌来有效地构建他们的状态表段。
与逐像素传播的Photo-SLAM相比,这种改进有效地解决了训练不足的问题。
2)自适应优化:尽管 long-tail 传播总体上达到了足够的训练,但每个关键帧迭代的长尾分布是一个挑战。为了解决这个问题,我们建议使用基于训练损失L的自适应优化来增强飞溅的方法,以确保在关键帧池K上更公平地分配迭代。
给定一个关键帧池
K
k
K_k
Kk,其中包含关键帧{
v
1
,
v
2
,
…
,
v
k
v1, v2,…, vk
v1,v2,…,vk},则维持两个集合:
R
k
R_k
Rk = {r1, r2,…, rk},它跟踪每个关键帧的剩余训练迭代,
L
k
L_k
Lk = {
l
1
,
l
2
,
…
,
l
k
l1, l2,…, lk
l1,l2,…,lk}记录每个关键帧的最后一次训练损失值。当检测到新的关键帧
v
k
+
1
v_{k+1}
vk+1时,我们更新我们的池如下:
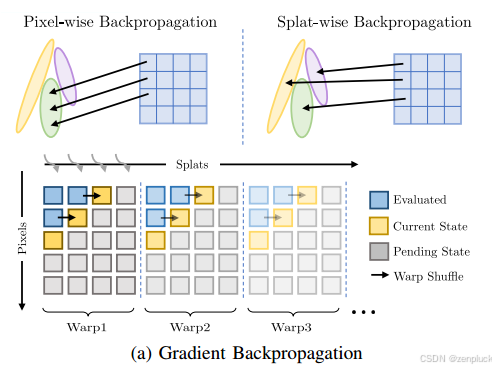
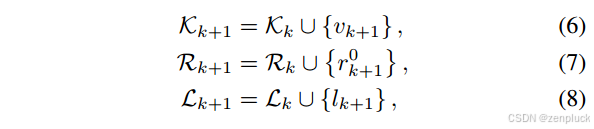
其中
r
k
+
1
0
r^ 0_{ k+1}
rk+10为分配给新关键帧的初始训练迭代次数,
l
k
+
1
l_{k+1}
lk+1为其初始训练损失值。然后,我们从剩余迭代的关键帧子集中随机选择一个关键帧
v
′
v'
v′,定义为 {vi |ri > 0,∀ri∈Rk},来训练3D高斯地图G。训练后,我们将所选关键帧的训练迭代次数减1,将r ’ 调整为 r ’ - 1,并更新相应的训练损失值l '。当{vi |ri > 0时,∀ri∈Rk}为空,我们根据Lk更新Rk如下:
其中dkQ(·)给出了前dk个最大的元素,dk = max(1, k /d), d是一个超参数。该方法优先考虑具有较高训练损失值的关键帧。
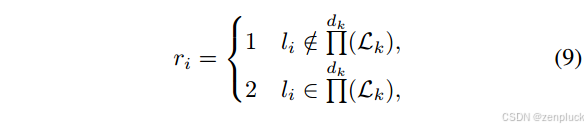
3)不透明度正则化(Opacity Regularization):在3DGS的典型应用中,利用渲染损失 l r e n d e r l_{render} lrender来细化三维高斯基元。为了有效地管理内存使用和模型大小,我们设计了一种策略,鼓励在对渲染过程没有贡献的区域消除高斯分布。由于高斯的存在主要是由它的不透明度o来表示的,我们在这个属性上强加了一个正则化项 L o L_o Lo。我们的训练损失L的完整公式如下:
其中λssim为权重因子,λo为正则化系数,N为高斯基元总数。
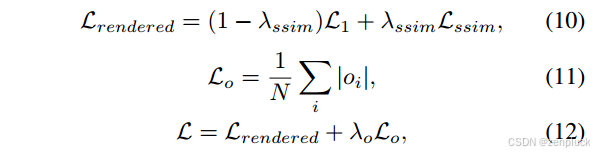
2.3总体流程
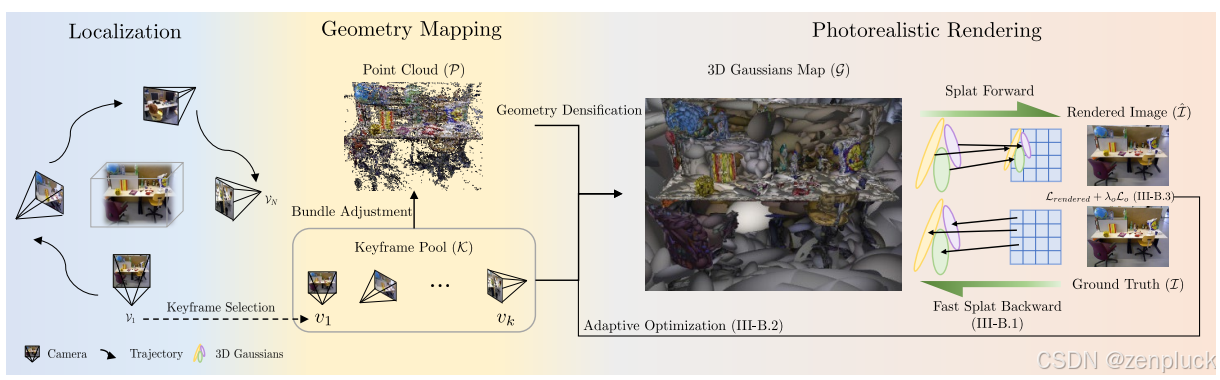
在Photo-SLAM的基础上,我们采用ORB- slam3作为前端跟踪器,该跟踪器不仅提供输入图像Vi的高效6自由度相机姿态估计,还提供彩色点云p。在定位模块中,前端跟踪器通过Levenberg-Marquardt (LM)算法最小化2D ORB关键点pi与匹配的3D点pi之间的重投影误差,交互式地改进相机方向R和位置t。在几何建图模块中,前端跟踪器对一组共可见的3D点PL和关键帧KL执行BA调整,以生成彩色点云Pi。给定一个彩色点云Pi,我们将其转换为一组初始化的高斯基元Gi。随后,我们通过几何致密化操作将Gi合并到三维高斯地图G中。利用3DGS,我们可以得到给定6自由度相机姿态的高保真渲染。
3.文章贡献
- 我们对GS-SLAM中存在的计算偏差现象进行了深入的分析。
- 我们引入了一种自适应计算对齐策略,有效地解决了训练不足、长尾优化和弱约束致密化问题,在实时约束下使用更少的高斯原语实现了高保真渲染。
4.个人思考
- 本文针对Photo-slam中出现的一些痛点问题,有的放矢,对Photo-slam提出了进一步的优化。
- 总的来说解决了三个问题,我个人觉得,第一个解决方案的创新性很高,相当于对GS渲染的反向传播过程进行优化,并将他运用到Photo-slam上面。第二个解决的长尾问题是针对于Photo-slam的具体优化,之前我就觉得这个地方需要改进,他这个通过损失来判断迭代哪些关键帧的方法让我眼前一亮。虽然简单,但是之前没有人这样做。
- 这些方法切实地对已有方法进行优化,覆盖了大部分方面,让Photo-slam的效果更上了一层楼,总之这个工作还是非常不错的。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » GS-SLAM论文阅读笔记-CaRtGS

发表评论 取消回复