前言
Google发布的XLNet在问答、文本分类、自然语言理解等任务上都大幅超越BERT,XLNet提出一个框架来连接语言建模方法和预训练方法。我们所熟悉的BERT是denoising autoencoding模型,最大的亮点就是能够获取上下文相关的双向特征表示,所以相对于标准语言模型(自回归)的预训练方法相比,基于BERT的预训练方法具有更好的性能,但是这种结构同样使得BERT有着它的缺点:
- 生成任务表现不佳:预训练过程和生成过程的不一致,导致在生成任务上效果不佳;
- 采取独立性假设:没有考虑预测[MASK]之间的相关性(位置之间的依赖关系),是对语言模型联合概率的有偏估计(不是密度估计);
- 输入噪声[MASK],造成预训练-精调两阶段之间的差异;
- 无法适用在文档级别的NLP任务,只适合于句子和段落级别的任务;
鉴于这些利弊,作者提出一种广义自回归预训练方法XLNet,该方法:
- enables learning bidirectional contexts by maximizing the expected likelihood over all permutations of the factorization orde
- overcomes the limitations of BERT thanks to its autoregressive formulation
前情提要
首先在此之前需要了解一下预训练语言模型的相关联系和背景,这里推荐两篇文章,一篇是邱锡鹏老师的关于NLP预训练模型的总结Paper:Pre-trained Models for Natural Language Processing: A Survey,我之前对它有写过阅读笔记:论文阅读笔记:超详细的NLP预训练语言模型总结清单!,还有一篇就是:nlp中的预训练语言模型总结(单向模型、BERT系列模型、XLNet),其中总结的也相当的全面精辟到位。
目前无监督表示学习这一块,自回归(autogression)语言建模和自动编码(autoencoding)无疑是最成功的两个。对于ELMO、GPT等预训练模型都是基于传统的语言模型(自回归语言模型AR),自回归语言模型天然适合处理生成任务,但是无法对双向上下文进行表征,因此人们反而转向自编码思想的研究(如BERT系列模型)。
那AE就完美了嘛?自编码语言模型(AE)虽然可以实现双向上下文进行表征,但是依旧存在不适于生成任务的问题,就和上面说的BERT的缺点一样,以BERT为代表的系列模型:
- BERT系列模型引入独立性假设,没有考虑预测[MASK]之间的相关性;
- MLM预训练目标的设置造成预训练过程和生成过程不一致;
- 预训练时的[MASK]噪声在finetune阶段不会出现,造成两阶段不匹配问题;
对于AE和AR两种模型在各自的方向优点,有什么办法能构建一个模型使得同时具有AR和AE的优点并且没有它们缺点呢?这也是XLNet诞生的初衷,对于XLNet:
- 不再像传统AR模型中那样使用前向或者反向的固定次序作为输入,XLNet引入排列语言模型,采用排列组合的方式,每个位置的上下文可以由来自左边和右边的token组成。在期望中,每个位置都要学会利用来自所有位置的上下文信息,即,捕获双向上下文信息。
- 作为一个通用的AR语言模型,XLNet不再使用data corruption,即不再使用特定标识符号[MASK]。因此也就不存在BERT中的预训练和微调的不一致性。同时,自回归在分解预测tokens的联合概率时,天然地使用乘法法则,这消除了BERT中的独立性假设。
- XLNet在预训练中借鉴了Transformer-XL中的segment recurrence机制的相对编码方案,其性能提升在长文本序列上尤为显著。
- 由于分解后次序是任意的,而target是不明确的,所以无法直接使用Transformer-XL,论文中提出采用“reparameterize the Transformer(-XL) network”以消除上述的不确定性。
排列语言模型
受无序NADE(Neural autoregressive distribution estimation)的想法的启发,提出一个排列组合语言模型,该模型能够保留自回归模型的优点,同时能够捕获双向的上下文信息。例如一个长度为T的序列,其排序组合为T!,如果所有排列组合次序的参数共享,那么模型应该会从左右两个方向的所有位置收集到信息。但是由于遍历 T! 种路径计算量非常大(对于10个词的句子,10!=3628800)。因此实际只能随机的采样 T! 里的部分排列,并求期望;
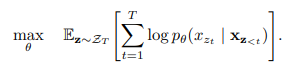
为了更好的理解,看下面这张图:
假设输入的序列是[1,2,3,4], 排列共有4x3x2=24种,选其中的四种分别为[3,2,4,1],[2,4,3,1],[1,4,2,3],[4,3,1,2]。在预测位置3的单词时,第一种排列看不到任何单词,第二种排列能看到[2,4],第三种排列能看到[1,2,4],第四种排列能看到[4],所以预测位置3的单词时,不仅能看到上文[1,2],也能看到下文的[4],所以通过这种方式,XLNet模型能同时编码上下文信息。
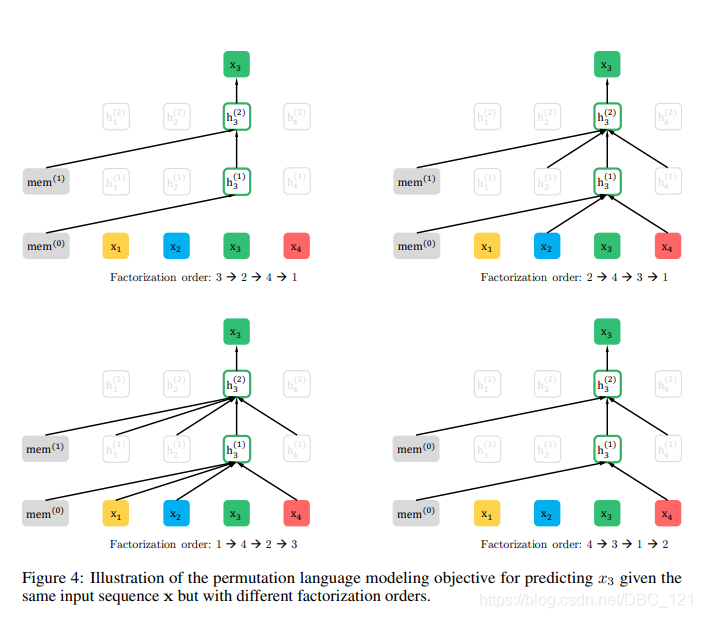
PLM的本质就是LM联合概率的多种分解机制的体现,将LM的顺序拆解推广到随机拆解,但是需要保留每个词的原始位置信息(PLM只是语言模型建模方式的因式分解/排列,并不是词的位置信息的重新排列!)
但是有个问题需要注意,上面提出的排列语言模型,在实现过程中,会存在一个问题,举个例子,还是输入序列[1, 2, 3, 4]肯定会有如下的排列[1, 2, 3, 4],[1,2,4,3],第一个排列预测位置3,得到如下公式 P ( 3 ∣ 1 , 2 ) P(3|1,2) P(3∣1,2),第二个排列预测位置4,得到如下公式 P ( 4 ∣ 1 , 2 ) P(4|1,2) P(4∣1,2),这会造成预测出位置3的单词和位置4的单词是一样的,尽管它们所在的位置不同。论文给出具体的公式解释如下:
那怎么解决没有目标(target)位置信息的问题?那就是下面要讲的Two-Stream Self-Attention。

Two-Stream Self-Attention
除了上述之外,模型的实现过程中还有两点要求
- 在预测当前单词的时候,只能使用当前单词的位置信息,不能使用单词的内容信息。
- 在预测其他单词的时候,可以使用当前单词的内容信息
为了满足同时这两个要求,XLNet提出了双流自注意力机制,结构如下:
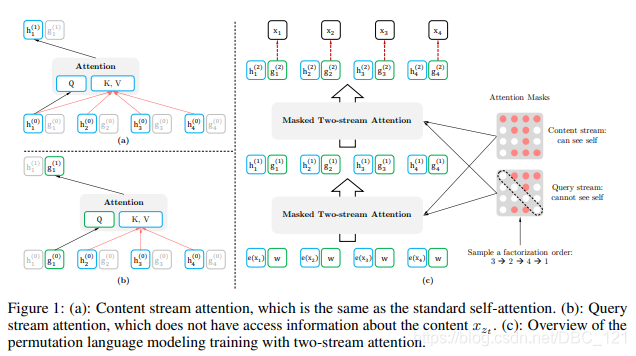
下文用 g z t g_{z_t} gzt 表示,上下文的内容信息用 x z < t x_{z<t} xz<t 表示,目标的位置信息 z t z_t zt ,目标的内容信息
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 论文阅读笔记-XLNet: Generalized Autoregressive Pretraining for Language Understanding

发表评论 取消回复