[2] Palette: Image-to-Image Diffusion Models ( ACM SIGGRAPH 2022)
作者:Chitwan Saharia、William Chan、Huiwen Chang
单位:Google Research, Brain Team
摘要:
本文基于条件扩散模型开发了一个统一的图像到图像翻译框架,并在四个具有挑战性的图像到图像翻译任务上对该框架进行了评估,即彩色化、修复、未裁剪和JPEG恢复。我们的图像到图像扩散模型的简单实现在所有任务上都优于强GAN和回归基线,而不需要特定任务的超参数调整、架构定制或任何辅助损失或复杂的新技术。我们揭示了L2 vs .去噪扩散目标中的L1损失对样本多样性的影响,并通过实证研究证明了自注意力在神经架构中的重要性。重要的是,我们提倡基于ImageNet的统一评价协议,以人为评价和样本质量分数( FID、Inception Score、预训练ResNet50网络的分类准确率和与原始图像的感知距离)。我们期望这种标准化的评价方案在推进图像到图像翻译研究中发挥作用。最后,我们证明了一般化的多任务扩散模型的性能与或优于特定任务的专家同行。
主要贡献:
基于条件扩散模型开发了一个统一的图像到图像翻译框架,并且在彩色化、修复、未裁剪和JPEG恢复这四个任务上取得了非常好的效果。揭示了L2 vs .去噪扩散目标中的L1损失对样本多样性的影响,并通过实证研究证明了自注意力在神经架构中的重要性。提出了基于ImageNet的统一评价协议。
创新点:
同主要贡献。
简介:
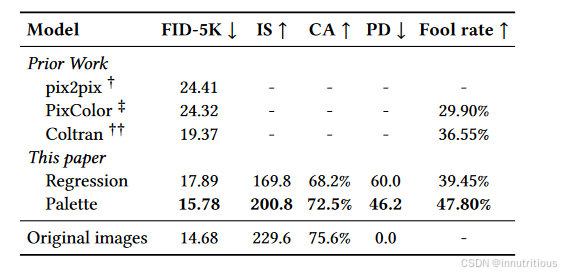
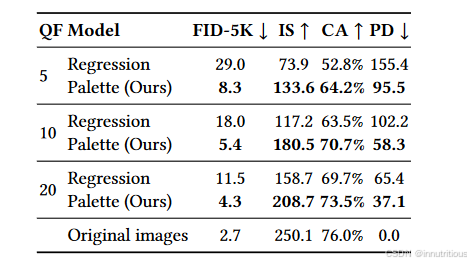
研究了Palette的关键组件,包括去噪损失函数和神经网络架构。我们发现,虽然L2和L1在去噪目标中的损失产生了相似的样本质量分数,但L2导致了更高程度的模型样本多样性,而L1 产生了更保守的输出。我们还发现,从Palette的U - Net架构中移除自注意力层来构建全卷积模型会降低性能。最后,我们提出了基于ImageNet 的修复、未修剪和JPEG修复的标准化评估方案,并报告了多个基线的样本质量评分。我们希望这个基准将有助于推进图像到图像的翻译研究。
框图:
没看具体代码,所以不太清楚它的损失函数是如何处理的。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 车辆重识别(2022ACM SIGGRAPH调色板:图像到图像的扩散模型)论文阅读2024/10/09

发表评论 取消回复