前言
Reformer: The Efficient Transformer
原始Transformer结构提出后,其中的Attention的 L 2 L^2 L2 计算复杂度以及整体模型的计算内存空间占用一直都是优化的一个方向。本篇文章提出的Reformer模型,通过改进Attention方式、可逆层等,来优化计算复杂度和内存空间。
Reformer目标
原始Transformer的问题:
- 由于Attenttion计算复杂度为 L 2 L^2 L2
- Encoder 和 Decoder堆叠的层数越多,需要储存的参数量越大,因为我们需要储存层与层之间的连接参数(activations),用于反向传播时的计算,导致内存占用较大。
- 在block layer中,是由self-attention以及FFN组成,其中FFN是两层的神经网络,其中的中间层的hidden size d f f d_{ff} dff 比self attention的hidden size d m o d e l d_{model} dmodel 更大,所以占据了更多的内存空间。
Reformer优化方法:
- Reversible layers:思路来源于RevNet,其是为了解决ResNet层数加深后,需要储存每一层的activations(即每一层的输入),导致memory 消耗过大的问题。Transformer采用这种方式,不需要记录中间层的activations,而只需要储存最后一层的输出,从而通过模型的特定结构,反推出中间层的结果。
- Chunking FFN layers:将FFN分段处理,因为FFN中的输入之间互相独立,进行分段的处理可以降低空间消耗。
- Locality Sensitive Hashing Attention:使用了LSH的方式,将attention score 相近(即Key相似的)的分到同一个bucket中。因为我们经过softmax之后,一个 query 和其他的所有的token的计算 attention score主要是取决于高相似度的几个tokens,所以采用这种方式将近似算得最终的attention score。
模型细节
Locality Sensitive Hashing Attention
LSH其实已经有了很多应用,特别是在相似检索方面。在信息检索,数据挖掘以及推荐系统等应用中,我们经常会遇到的一个问题就是面临着海量的高维数据,查找最近邻。如果使用线性查找,那么对于低维数据效率尚可,而对于高维数据,就显得非常耗时了。为了解决这样的问题,人们设计了一种特殊的hash函数,使得2个相似度很高的数据以较高的概率映射成同一个hash值,而令2个相似度很低的数据以极低的概率映射成同一个hash值。我们把这样的函数,叫做LSH(局部敏感哈希)。LSH最根本的作用,就是能高效处理海量高维数据的最近邻问题。感兴趣的小伙伴可以自行查找翻阅资料,这里贴一个Min-Hash LSH和P-table LSH的实现:
LSH实现
通过上面我们知道,LSH是一种查找最近邻的方法,而在Attention的计算中,我们都知道对于Self-Attention计算中,每个token往往只关注序列中的一小部分token,加上softmax的作用,这种区分更加的明显,可以通过局部敏感哈希(LSH)解决在高维空间中快速找到最近邻居的问题。
我们的目标就是,让附近的向量较大概率的获得相同的哈希值,而远距离的向量则没有,则将每个向量
x
x
x 分配给哈希值h(x)的哈希方法称为局部敏感。 实际上仅要求附近的向量以高概率获得相同的hash,并且hash桶具有高概率的相似大小。实现示意图如下:
研究中使用的局部敏感哈希算法。这种算法使用随机旋转的方法,对投影的点建立分块,建立的规则依据对给定轴的投影进行比较。在本图中,两个点 x、y 由于三次随机旋转投影中的两次都不靠近,所以不太可能有相同的哈希值。而另一个例子中他们投影后都在同一个。具体到公式上的表示,
Q
=
K
Q=K
Q=K,且每个token的query
q
i
q_i
qi , 只能attend到它自己本身以及之前的key
k
i
k_i
ki 。我们将原Attention表示为:
o
i
=
∑
0
≤
j
≤
i
s
o
f
t
m
a
x
(
q
i
⋅
k
j
d
k
)
v
j
=
∑
j
∈
P
i
e
q
i
⋅
k
j
∑
l
∈
P
i
e
q
i
⋅
k
l
d
k
v
j
=
∑
j
∈
P
i
e
x
p
(
q
i
⋅
k
j
−
z
(
i
,
P
i
)
)
v
j
o_i=\sum_{0\leq j\leq i}softmax(\frac{q_i\cdot k_j}{\sqrt{d_k}})v_j=\sum_{j\in P_i}\frac{e^{q_i\cdot k_j}}{\sum_{l\in P_i}e^{q_i\cdot k_l}\sqrt{d_k}}v_j=\sum_{j\in P_i}exp(q_i\cdot k_j-z(i,P_i))v_j
oi=0≤j≤i∑softmax(dkqi⋅kj)vj=j∈Pi∑∑l∈Pieqi⋅kldkeqi⋅kjvj=j∈Pi∑exp(qi⋅kj−z(i,Pi))vj
其中,
P
i
=
{
j
:
i
≥
j
}
P_i=\{j:i\geq j\}
Pi={j:i≥j},
z
(
i
,
P
i
)
z(i,P_i)
z(i,Pi) 是归一化项,
P
i
P_i
Pi 指的是position
i
i
i 可以attend to 的所有位置。

为了实现方便,我们一般是采用look-ahead mask的方式进行,即对于不能attend to的位置,其的score=0,我们采用的是在
q
i
⋅
k
j
q_i\cdot k_j
qi⋅kj 的值之间减去正无穷,然后经过softmax函数之后其 score = 0,这样就不需要对于每个位置
i
i
i 都有单独的
P
i
P_i
Pi,即令
P
~
i
=
0
,
1
,
.
.
.
,
l
⊇
P
i
\tilde{P}_i=0,1,...,l\supseteq P_i
P~i=0,1,...,l⊇Pi,
o
i
=
∑
j
∈
P
~
i
e
x
p
(
q
i
⋅
k
j
−
m
(
j
,
P
i
)
−
z
(
i
,
P
i
)
)
v
j
o_i=\sum_{j\in \tilde{P}_i}exp(q_i\cdot k_j-m(j,P_i)-z(i,P_i))v_j
oi=j∈P~i∑exp(qi⋅kj−m(j,Pi)−z(i,Pi))vj
其中,
m
(
j
,
P
i
)
=
{
∞
j
∉
P
i
0
j
∈
P
i
m(j,P_i)=\left\{\begin{matrix} \infty & j\notin P_i \\ 0 & j \in P_i \end{matrix}\right.
m(j,Pi)={∞0j∈/Pij∈Pi,当我们使用LSH的时候,我们将不会考虑全部的
i
i
i 之前的位置,我们将只考虑与position
i
i
i 在同个hash bucket的keys,即
P
i
=
j
:
h
(
q
i
)
=
h
(
k
j
)
P_i=j:h(q_i)=h(k_j)
Pi=j:h(qi)=h(kj),
h
(
⋅
)
h(\cdot)
h(⋅)是hash函数。最终,对 attention 进行哈希处理的流程如下:
简化的局部敏感哈希注意力,展示了 hash-bucketing、排序和分块步骤,并最终实现注意力机制。
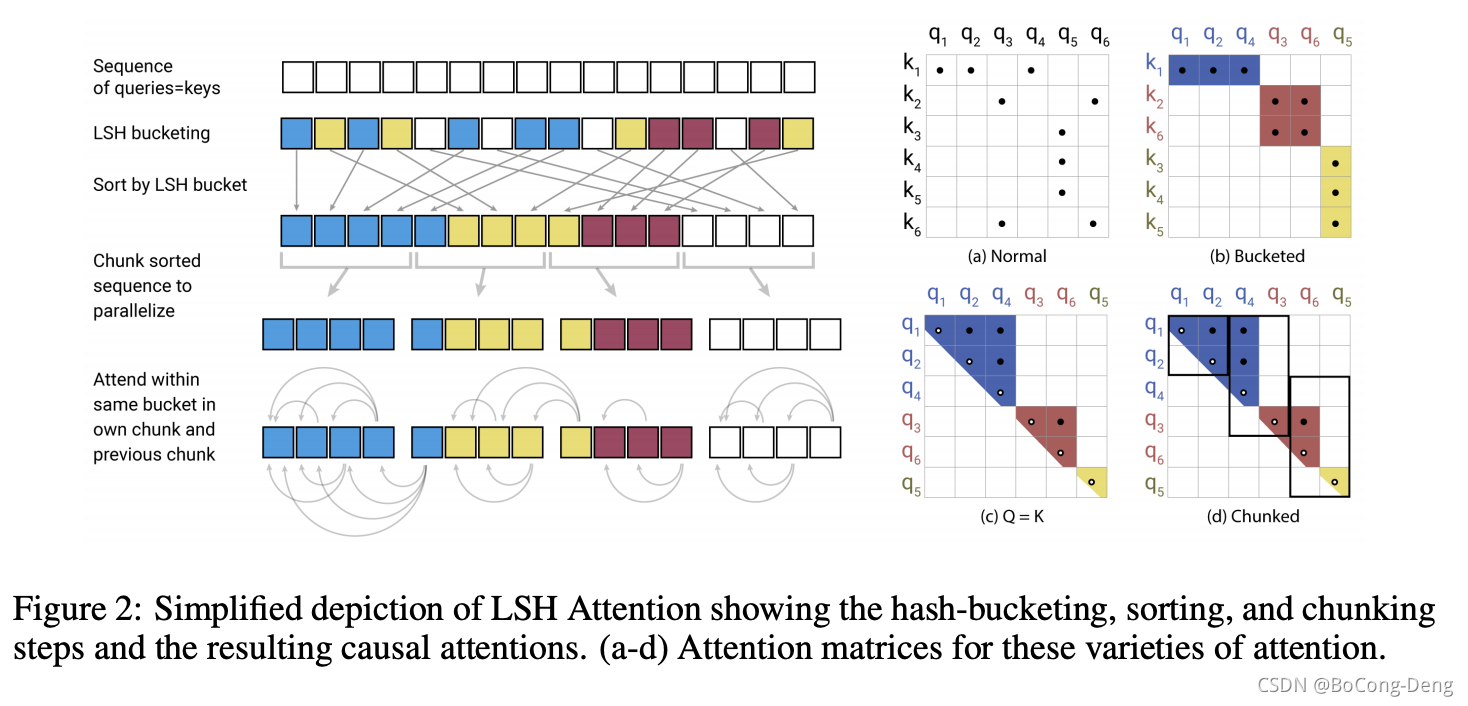
- 图2-a:我们可以看到在 q q q 和 k k k 不同的情况下,即普通的attention机制中,黑点代表的是需要softmax中占主导的位置,注意这边的attention使用的是encoder的attention, 否则 q 3 q_3 q3 是无法attend to k 6 k_6 k6 的。 我们可以清楚看到,对于需要attend 的位置是稀疏的,我们可以利用这个降低我们的时间空间复杂度。
- 图2-b:我们不改变 q q q 和 k k k,但是我们这次使用了LSH就只attend to 相同bucket的位置的keys。我们按照bucket进行排序,然后对于同一个bucket又按照原本的位置进行排序得到图b。我们可以看到,对于同一个bucket,可以出现一个bucket中有多个query但是很少keys的情况,例如图中蓝色的bucket。
- 为了减小bucket中 q q q 和 k k k 不均衡的问题,文章提出了保证通过令 k j = q j ∣ q j ∣ k_j=\frac{q_j}{|q_j|} kj=∣qj∣qj 从而使得 h ( k j ) = h ( q j ) h(k_j)=h(q_j) h(kj)=h(qj) , 即使用了share-QK attention。然后在按照bucket 排序,每个bucket中,仍按照原本的position 位置大小排序。得到图c。这时候就能保证对角线都是attend to的而且 q q q 和 k k k 在bucket中的个数一样(因为 Q = K Q=K Q=K)。我们注意到对角线的点为空心,这是因为我们虽然在正常实现上,我们的 q q q 会attend to本身位置的value,但是在share-QK的实现下,如果attend to本身,会导致其值特别大,其他的值特别小,经过softmax之后,其他都是0,就自己本身是1。所以为了避免这种情况,我们 q q q 不会去attend 自身位置的值,除非只有自己本身可以attend to,例如序列起始token。
- 即使
Q
=
K
Q=K
Q=K了,但是还是会出现一个问题就是,有的bucket中个数多,有的bucket中个数少,出一个极端的情况,对于2个bucket,我们其中一个bucket占据了所有的keys,另一个bucket为空,那么我们的LSH attention就没有起到作用。于是在c的基础上,增加了chunk的操作。具体的操作就是我们在对我们的输入进行排序之后(先bucket排序,同个bucket内按照token 的 position排序)得到新的序列顺序
s
i
s_i
si 即
i
→
s
i
i\rightarrow s_i
i→si 。例如图d中的序列由
[
q
1
,
q
2
,
q
3
,
q
4
,
q
5
,
q
6
]
[q_1,q_2,q_3,q_4,q_5,q_6]
[q1,q2,q3,q4,q5,q6] 到了
[
q
1
,
q
2
,
q
4
,
q
3
,
q
5
,
q
6
]
[q_1,q_2,q_4,q_3,q_5,q_6]
[q1,q2,q4,q3,q5,q6] 。我们将设每个bucket的个数为
m
=
2
l
n
b
u
c
k
e
t
m=\frac{2l}{n_{bucket}}
m=nbucket2l , (
l
l
l 为输入query的个数) 然后对于bucket中的每个query,都可以attend to自己以及前一个bucket 中相同hash 值的key。 即其候选集
P
~
i
\tilde{P}_i
P~i 为(注意候选集之后仍需要保证hash值相同):
P ~ i = ⌊ s i m ⌋ − 1 ≤ ⌊ s j m ⌋ ≤ ⌊ s i m ⌋ \tilde{P}_i=\left \lfloor \frac{s_i}{m} \right \rfloor-1\leq \left \lfloor \frac{s_j}{m} \right \rfloor\leq\left \lfloor \frac{s_i}{m} \right \rfloor P~i=⌊msi⌋−1≤⌊msj⌋≤⌊msi⌋
除此之外还有一个我们需要注意的,就是LSH只是近似结果,我们不能保证相似的输入能在同一个bucket中。为了减轻这个问题,文章中采用了multi-round LSH attention。即我们query通过多轮的LSH,然后将这些轮中相同bucket的query取并集。在
n
r
o
u
n
d
s
n_{rounds}
nrounds 中对于每一轮,我们都有各自的不同的hash 函数
h
1
,
h
2
,
.
.
.
h^1,h^2,...
h1,h2,...:
P
i
=
⋃
r
=
1
n
r
o
u
n
d
s
P
i
(
r
)
P_i=\bigcup_{r=1}^{n_{rounds}}P_i^{(r)}
Pi=r=1⋃nroundsPi(r)
其中,
P
i
(
r
)
=
{
j
:
h
(
r
)
(
q
i
)
=
h
(
r
)
(
q
j
)
}
P_i^{(r)}=\{j:h^{(r)}(q_i)=h^{(r)}(q_j)\}
Pi(r)={j:h(r)(qi)=h(r)(qj)}
Reverible Transformer
对于我们的transformer中的sub-encoder我们的attention和FFN之间的相连,都需要记忆其中的activations,对于多层以及多个sub-encoder,这将会导致大量的内存消耗。我们将借鉴RevNet的思想,我们无需保存中间层的activations,只需要知道最后一层的activations就可以得出中间层的activations,注意这边的activations不是指激活函数,而是指激活函数的输入。保存这些输入的意义在于用于back propagation时的参数更新。RevNet可看文章:
RevNet
每一层的activations可以根据下一层的activations 推导获得,从而我们不需要在内存中储存activations。 在原本的residual layer中,我们的输出activations 是由
y
=
x
+
F
(
x
)
y=x+F(x)
y=x+F(x) 得到。其中
F
F
F 是residual 函数。而在RevNet中,首先将输入
x
x
x 分为两个部分
x
1
x_1
x1 和
x
2
x_2
x2 然后通过不同residual functions:
F
(
⋅
)
F(\cdot)
F(⋅) 和
G
(
⋅
)
G(\cdot)
G(⋅) 得到输出
y
1
y_1
y1 和
y
2
y_2
y2 。其中我们根据以下结构,可以从输出获得输入:
y
1
=
x
1
+
F
(
x
2
)
,
y
2
=
x
2
+
G
(
y
1
)
y_1=x_1+F(x_2),y_2=x_2+G(y_1)
y1=x1+F(x2),y2=x2+G(y1)
由此可以推导:
x
2
=
y
2
−
G
(
y
1
)
,
x
1
=
y
1
−
F
(
x
2
)
x_2=y_2-G(y_1),x_1=y_1-F(x_2)
x2=y2−G(y1),x1=y1−F(x2)
因此,在transformer的sub-encoder block之中,我们令
F
F
F 函数作为我们的Attention层,
G
G
G 函数作为FFN层,注意我们的layer normalization是包含在residual blocks中的:
y
1
=
x
1
+
A
t
t
e
n
t
i
o
n
(
x
2
)
,
y
2
=
x
2
+
F
F
N
(
y
1
)
y_1=x_1+Attention(x_2),y_2=x_2+FFN(y_1)
y1=x1+Attention(x2),y2=x2+FFN(y1)
Chunking
在FFN中,我们例如两层的FFN,通常中间隐藏层的纬度会非常大,例如
d
f
f
=
4
k
d_{ff}=4k
dff=4k 或者更大。 我们通常是一次性计算完全部,但是我们知道FFN的输入是独立的,所以我们为了降低memory的使用,可以进行chunk拆分计算, 每次计算一个chunk,通过时间消耗获取空间:
y
2
=
x
2
+
F
F
N
(
y
1
)
=
[
y
2
(
1
)
;
y
2
(
2
)
;
.
.
.
;
y
2
(
c
)
]
=
[
x
2
(
1
)
+
F
F
N
(
y
1
(
1
)
)
;
x
2
(
2
)
+
F
F
N
(
y
1
(
2
)
)
;
.
.
.
;
x
2
(
c
)
+
F
F
N
(
y
1
(
c
)
)
]
y_2=x_2+FFN(y_1)=[y_2^{(1)};y_2^{(2)};...;y_2^{(c)}]=[x_2^{(1)}+FFN(y_1^{(1)});x_2^{(2)}+FFN(y_1^{(2)});...;x_2^{(c)}+FFN(y_1^{(c)})]
y2=x2+FFN(y1)=[y2(1);y2(2);...;y2(c)]=[x2(1)+FFN(y1(1));x2(2)+FFN(y1(2));...;x2(c)+FFN(y1(c))]
实验结果
- 共享QK的给模型带来训练速度上的提升不大,所以不会切换到共享QK attention来牺牲准确性。
- 可逆transformer中的内存节省不会以准确性为代价。
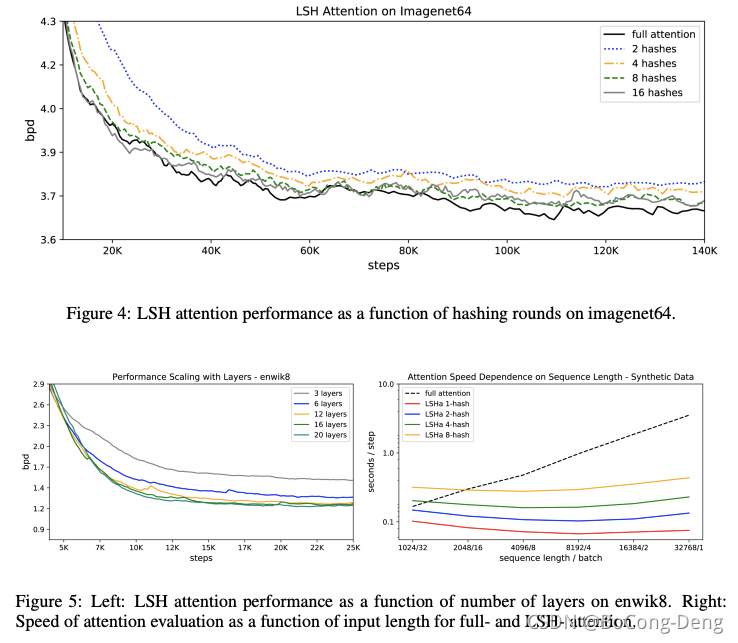
这里主要来看一下LSH Attention结构给模型带来的影响,LSH attention是full attention的近似值,下图4所示,随着hash数量的增加,它变得更加准确。在
n
r
o
u
n
d
s
=
8
n_{rounds} = 8
nrounds=8 时,它已经完全等同于 full attention,模型的计算成本随着hash数的增加而增加,因此可以根据可用的计算预算来调整此超参数。此外,如图5所示,可以在评估时增加hash数,以产生更准确的结果。在图5的右半部分,我们将不同注意力类型的速度与序列长度作图,同时将token总数保持固定。
结论
Reformer将Transformer的建模能力与可在长序列上高效执行的架构相结合,并且即使对于具有大量层的模型也可使用较少的内存。这将有助于大型,参数丰富的Transformer模型变得更加普及和可用。同样,处理长序列的能力为在许多生成任务中使用Reformer开辟了道路。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 论文阅读笔记-Reformer: The Efficient Transformer

发表评论 取消回复