论文:《Mamba: Linear-Time Sequence Modeling with Selective State Spaces》
作者1:Albert Gu,现在是CMU(卡内基梅隆大学)助理教授,曾在DeepMind 工作。多年来一直推动SSM架构发展。
作者2:Tri Dao,现为普林斯顿大学计算机科学助理教授。Together AI的首席科学家。斯坦福大学计算机科学系博士毕业。
文章地址:https://arxiv.org/abs/2312.00752
项目地址:https://github.com/state-spaces/mamba.
总体架构
先直接来看一下论文的总体架构。Mamba架构是结合了H3和门控MLP两个架构形成的组合架构,下面的图很清楚。
架构图:我们的简化块设计,将H3块(大多数SSM架构的基础)与现代神经网络中无处不在的MLP块相结合。我们只是均匀地重复Mamba块,而不是交织这两个块。与H3块相比,Mamba用激活函数替换了第一个乘法门。与MLP块相比,Mamba在主分支中添加了一个SSM。对于𝜎,我们使用SiLU/Swish激活(Hendrycks和Gimpel 2016;Ramachandran、Zoph和Quoc V Le 2017)。
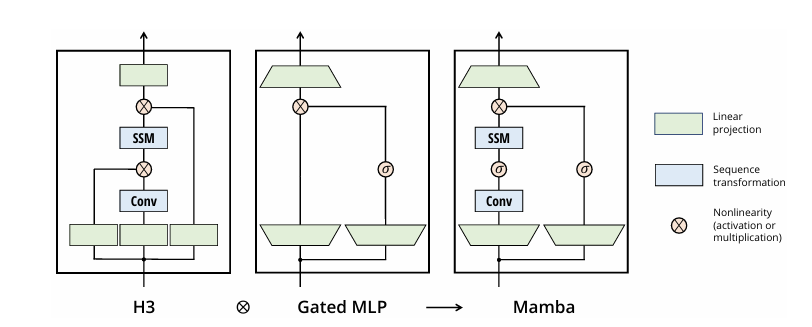
对于最左边的图,SSM 模型要工作,一般会在SSM的输出加上门控,之后再通过线性层。看上图的中间的图,这两个部分跟 Gated MLP右边的支路和最上面的线性层是一样的。所以 SSM 层如果跟Gated MLP 合并的话,在SSM之后增加MLP有点冗余,所以作者进行了组合,把门控和后面的线性层合并,把门控MLP融合到了H3架构中,就是右边的图。
文章中的图3提供了Mamba架构的概览。Mamba是一种新型的神经网络架构,它整合了选择性状态空间模型(Selective State Space Models,简称SSMs)来提高序列建模的效率和性能。以下是对图3的详细分析:
Mamba架构概览
1. 输入和输出:
- 输入(Input):模型接收一个输入序列。
- 输出(Output):模型产生一个输出序列。
2. 核心组件:
- 线性投影(Linear projection):输入数据首先通过一个线性投影层,这有助于将数据转换到一个新的空间,以便于后续处理。
- 状态转换(State transformation):这是SSM的核心,负责根据输入数据更新状态。
- 非线性激活(Nonlinearity / Activation):在状态转换后应用非线性激活函数,增加模型的表达能力。
- 局部卷积层:H3模型在SSM层之前插入了一个局部卷积层,这有助于模型捕捉局部特征并增强其对序列数据的理解。
3. 简化的架构设计:
- Mamba的设计简化了传统的深度序列模型架构,如将H3架构中的SSM层和MLP(多层感知机)层合并为一个单一的块。
4. 参数化和初始化:
- Mamba块中的SSM参数(Δ, A, B, C)是可学习的,并且可以通过输入数据动态调整,这是选择性SSM的核心特点。
技术细节
- 选择性状态空间模型(Selective SSMs):通过使SSM参数成为输入的函数,模型能够根据当前的输入符号有选择地传播或忘记信息。
- 硬件感知算法:尽管选择性SSMs不能使用高效的卷积操作,但通过设计一种硬件感知的并行算法,Mamba能够在循环模式下高效运行。
性能优势
- 快速推理:Mamba模型能够实现比传统Transformer模型快5倍的吞吐量。
- 线性时间复杂度:在序列长度上的计算复杂度为线性,这对于长序列处理尤为重要。
总的来说,图3展示了Mamba架构如何通过整合选择性状态空间模型来优化序列数据处理,同时保持了模型的简洁性和高效性。
SSM简述
Transformer 模型的主要缺点是:自注意力机制的计算量会随着上下文长度的增加呈平方级增长。所以,许多次二次时间架构(指一个函数或算法的增长速度小于二次函数,但大于线性函数),如线性注意力、门控卷积和循环模型,以及结构化状态空间模型(SSM)被开发出来,以解决transformer在长序列上的计算效率低下问题。
所以,上图中架构中的SSM,先简单理解为可以针对一个序列,提取长期记忆,类似Transformer 模型的注意力机制,但是解决了注意力机制的计算量随序列长度平方增长问题。
门控机制
论文中强调最重要的联系:RNNs的经典门控机制是选择性SSMs中SSMs的门控机制的一个实例。我们注意到,RNN门控和连续时间系统的离散化之间的联系已经很好地建立(Funahashi 和 Nakamura, 1993; Tallec 和 Ollivier, 2018)。实际上,定理1是对Gu, Johnson, Goel等人(2021, 引理 3.1)的改进,将其推广到ZOH离散化和输入依赖的门控(证明见附录C)。更广泛地说,SSMs中的Δ可以被视为RNN门控机制的概括。按照先前的工作,我们采用这样的观点:SSMs的离散化是启发式门控机制的原则上的基础。
公式1:
可以看到这就是一个带门控的 RNN。
正如第3.2节中提到的,我们特定的 𝑠Δ,𝜏Δ 选择是基于与RNN门控的联系。特别是,如果一个给定的输入 𝑥t应该被完全忽略(如合成任务中所必需的),所有的D通道都应该忽略它,因此我们将输入投影到1维,然后再重复/广播Δ。
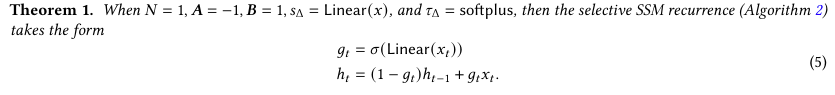
这一部分讨论了选择性状态空间模型(SSMs)中的选择机制与传统RNNs中的门控机制之间的联系。作者通过定理1展示了当特定的条件满足时,SSMs可以模拟RNNs中的门控行为。这表明,通过适当的参数化和离散化,SSMs能够实现类似于传统RNNs中的内容感知推理功能。
对比一下SwiGLU,可以更好的理解图中的门控MLP。

解释选择机制
详细阐述了选择机制的三个特定机械效应。
变量间距:选择性允许过滤掉可能在感兴趣输入之间出现的不相关噪声标记。这在“选择性复制”任务中得到了示例说明,但在常见数据模态中无处不在,特别是对于离散数据——例如语言填充词“um”的存在。这个属性之所以产生,是因为模型可以机械地过滤掉任何特定的输入 𝑥𝑡,例如在门控RNN情况下(定理1)当𝑔𝑡 → 0时。
过滤上下文:已经有实证观察表明,许多序列模型随着上下文长度的增加并没有改善(F. Shi et al. 2023),尽管原则上更多的上下文应该带来更好的性能。一个解释是,许多序列模型在需要时不能有效地忽略不相关的上下文;直观的例子是全局卷积(和一般的LTI模型)。另一方面,选择性模型可以随时简单地重置其状态以去除多余的历史记录,因此它们在原则上随着上下文长度的增加而性能提高。
边界重置:在将多个独立序列拼接在一起的设置中,Transformer可以通过实例化特定的注意力掩码来保持它们的分离,而LTI模型则会在序列之间泄露信息。选择性SSMs也可以在边界处重置其状态(例如 Δ𝑡 → ∞, or Theorem 1 when 𝑔𝑡 → 1)。这些设置可能是人为的(例如,为了提高硬件利用率而将文档打包在一起)或自然的(例如强化学习中的情节边界)。
此外,我们详细阐述了每个选择性参数的效果。
Δ的解释:通常,Δ控制着在多大程度上关注或忽略当前输入𝑥𝑡的平衡。它概括了RNN门控(例如, 𝑔𝑡 in Theorem 1):从机械上看,大的Δ重置状态ℎ并专注于当前输入x,而小的Δ保持状态并忽略当前输入。SSMs(1)-(2)可以被解释为通过时间步长Δ离散化的连续系统,在这个背景下,直觉是大的Δ → ∞代表系统长时间专注于当前输入(因此“选择”它并忘记其当前状态),而小的Δ → 0代表被忽略的瞬态输入。
𝑨的解释。我们注意到,虽然𝑨参数也可以是选择性的,但它最终只通过与Δ的交互𝑨 = exp(Δ𝑨)影响模型。因此,Δ的选择性足以确保(𝑨, B)的选择性,并且是改进的主要来源。我们假设除了Δ之外(或代替Δ)使𝑨也具有选择性可能会有类似的性能,并将其留出以简化。
B和C的解释:正如第3.1节所讨论的,选择性的最重要属性是过滤掉不相关的信息,以便序列模型的上下文可以被压缩成一个高效的状态。在SSM中,修改B和C以使其具有选择性允许更细粒度地控制是否让一个输入𝑥𝑡进入状态ℎ𝑡,或者状态进入输出𝑦𝑡。这些可以被解释为允许模型根据内容(输入)和上下文(隐藏状态)分别调节递归动态。
这一部分深入探讨了选择性状态空间模型(SSMs)中选择机制的具体工作机制和效果,包括变量间距、过滤上下文和边界重置等概念,并对模型中的各个选择性参数进行了详细解释。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【AI学习】Mamba学习(一):总体架构

发表评论 取消回复