21题(简单):
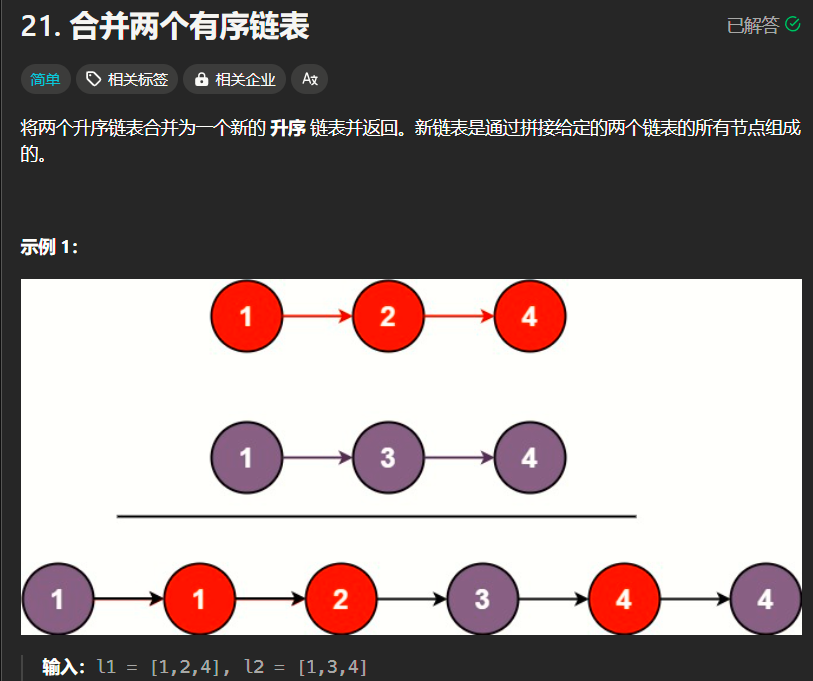
分析:
按要求照做就好了,这种链表基本操作适合用c写,python用起来真的很奇怪
python代码:
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def mergeTwoLists(self, list1: Optional[ListNode], list2: Optional[ListNode]) -> Optional[ListNode]:
if list1 and list2:
p=ListNode()
head=p
while 1:
if list1==None:
p.next=list2
break
elif list2==None:
p.next=list1
break
else:
if list1.val>list2.val:
p.next=list2
p=p.next
list2=list2.next
else:
p.next=list1
p=p.next
list1=list1.next
return head.next
else:
return list1 if list1 else list2
22题(中等)
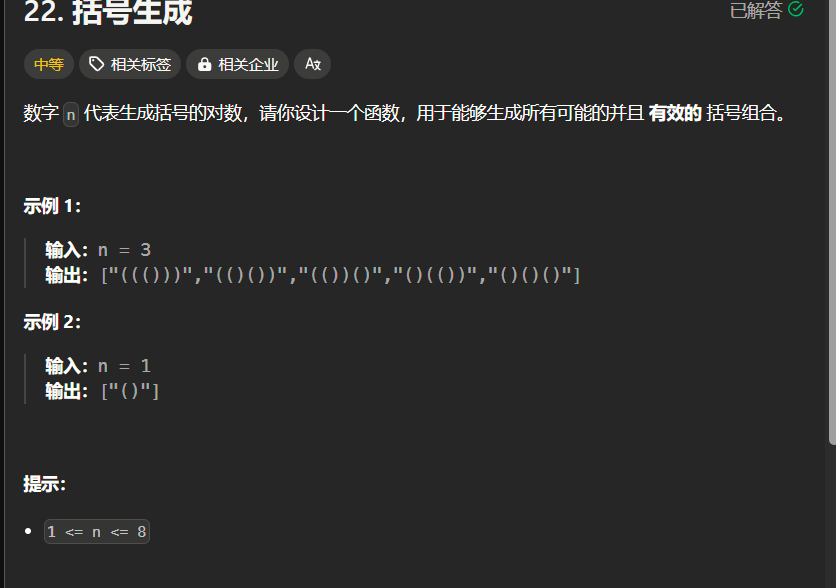
分析:
这个题明显要用递归才行,如果用循环真不好做,我们每次确定第n位,但是n+1位有2种(或一种情况),这个要丢进数组里面,下一次循环要对数组每一个进行进一步操作,能做但是很麻烦,我们知道循环适合线性的东西,没必要在非线性的情况下使用循环,除非特别需要,东西我觉得还是用着适合的地方好
python代码:
class Solution:
def generateParenthesis(self, n: int) -> List[str]:
res=[]
def backcall_track(s,left,right):
if left==right:
if left!=n:
s+='('
backcall_track(s,left+1,right)
else:
res.append(s)
return
else:
if left<n:
backcall_track(s+'(',left+1,right)
if right<n:
backcall_track(s+')',left , right+1)
backcall_track('',0,0)
return res
23题(困难):
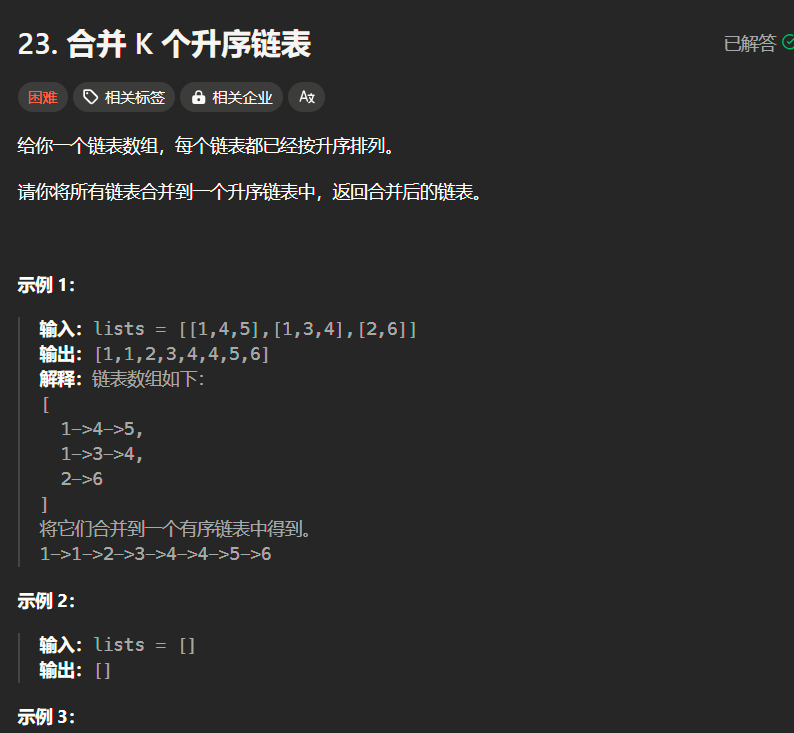
分析:
真不配这个难度,因为这个直接暴力求解都行,和第一个(21题)没区别,python没有指针,初始化感觉挺麻烦,你看了我代码就发现,我的head第一个往往都是空,返回head.next,因为我不想浪费空间重新拿创建,所以我更倾向于用它给的空间,这样看起来说实话有点别扭。但是第一个的赋值要在我们弄或者建立索引单独弄也别扭,以后再补上c++的吧
python代码
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def mergeKLists(self, lists: List[Optional[ListNode]]) -> Optional[ListNode]:
p=ListNode()
res=p
if len(lists)==0:
return None
while 1:
k=0
for i in range(len(lists)):
if lists[k]==None:
k=i
if lists[i] and lists[i].val<lists[k].val:
k=i
if lists[k]==None:
break
print(k)
p.next=lists[k]
p=p.next
lists[k]=lists[k].next
return res.next if res.next else None
24题:
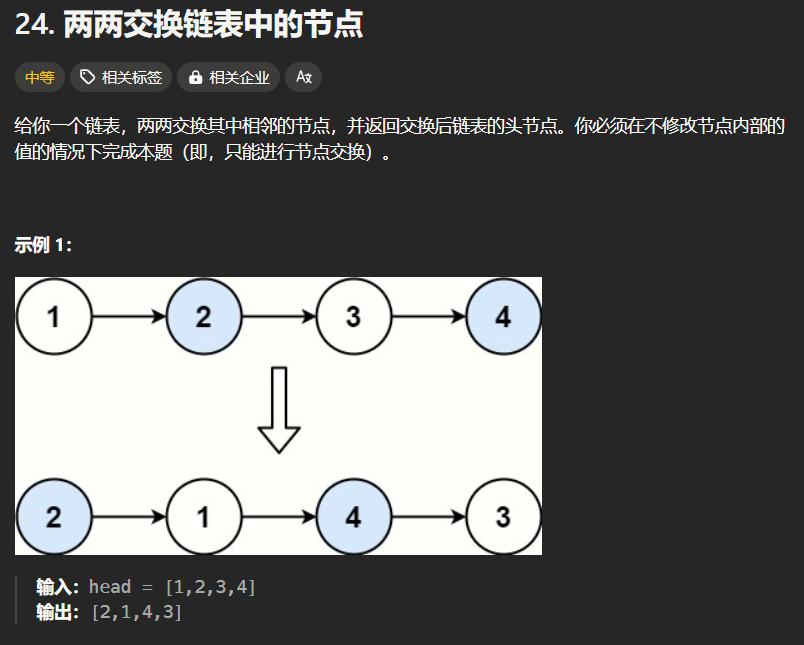
分析:
链表基础操作
python代码:
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def swapPairs(self, head: Optional[ListNode]) -> Optional[ListNode]:
if head==None:
return None
p=head
res=None
if p.next!=None:
res=p.next
q=p.next.next
p.next.next=p
p.next=q
else:
return head
while p.next!=None:
if p.next.next!=None:
q=p.next.next.next
p.next.next.next=p.next
p.next=p.next.next
p.next.next.next=q
p=p.next.next
else:
break
return res
题25(困难):
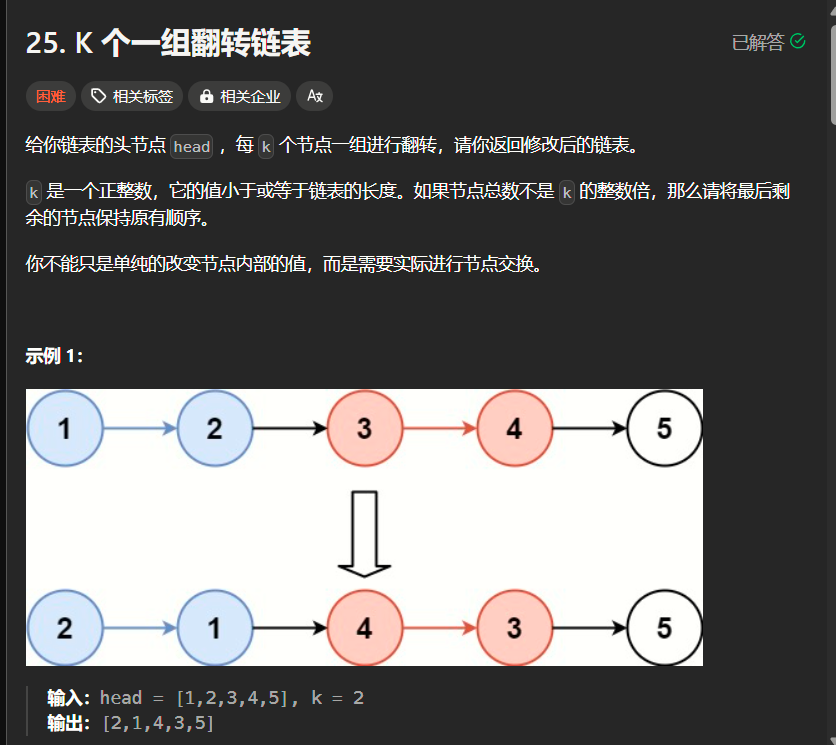
分析:
有意思,但是难度不配困难。思路其实挺清晰,我们知道链表时候插入数据但是不适合查找数据,本题因为要交换k个数据就说明一定要查找数据,因为你不知道要找第几个,而是要传入k,这个时候肯定要寻求数组的帮助,我们定义一个长度为k的数组,每次拿k个,这样我们要哪个就方便了
python代码:
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def reverseKGroup(self, head: Optional[ListNode], k: int) -> Optional[ListNode]:
res=ListNode(0,head)
p=res
while 1:
node_list=[]
flag=1
q=p
for i in range(k):
if q.next==None:
flag=0
break
else:
q=q.next
node_list.append(q)
last_node=q.next
if flag:
for i in range(k):
p.next=node_list[k-i-1]
p=p.next
p.next=last_node
else:
break
return res.next
题26(简单):
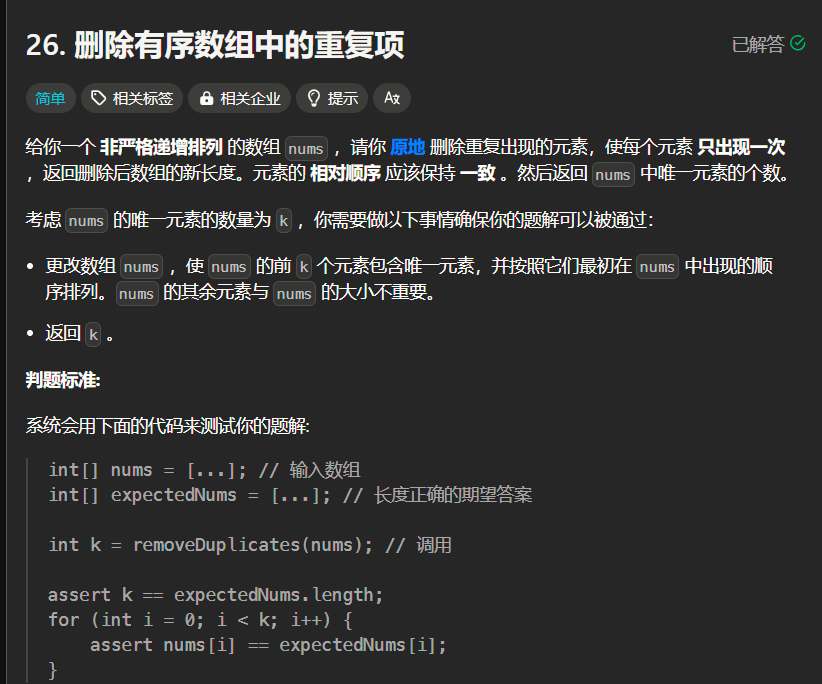
分析:
这个不重复,直接使用set数据类型吧,注意注意,这题还考了一个知识点:在python,可变数据类型要怎么改变实参,内置方法就行,切片不行
python代码:
class Solution:
def removeDuplicates(self, nums: List[int]) -> int:
set_nums=set(nums)
new_nums=list(set_nums)
#注意好像-1在set中很大
new_nums.sort()
for i in range(len(new_nums)):
nums[i]=new_nums[i]
return len(new_nums)
题27(简单):
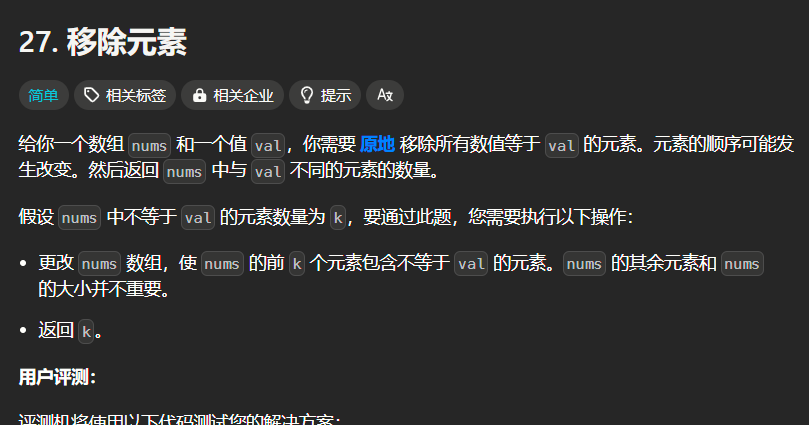
分析:
和上面一样,remove会改变的
python代码:
class Solution:
def removeElement(self, nums: List[int], val: int) -> int:
while val in nums:
nums.remove(val)
return len(nums)
题28(简单):
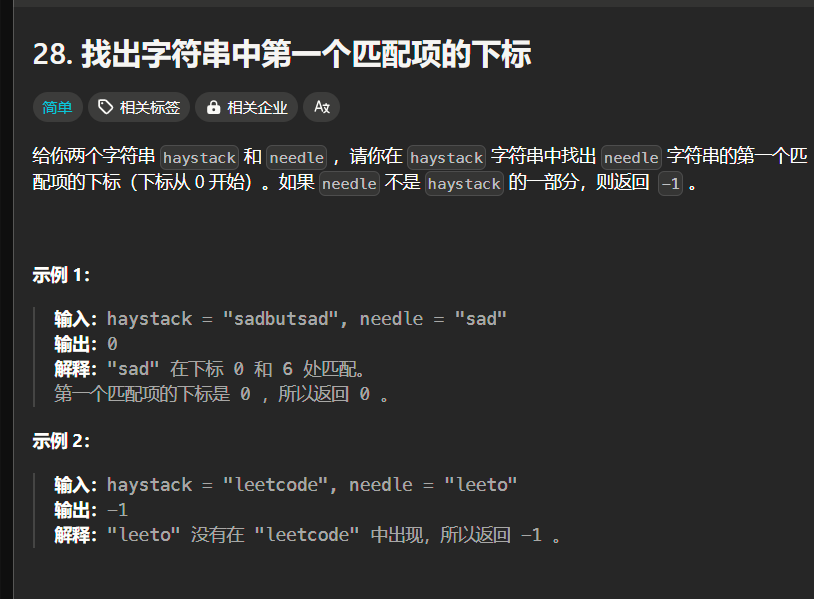
分析:
略
python代码:
class Solution:
def strStr(self, haystack: str, needle: str) -> int:
return haystack.find(needle)#注:这种写法比较装,以后不建议这样写,建议逐语句写
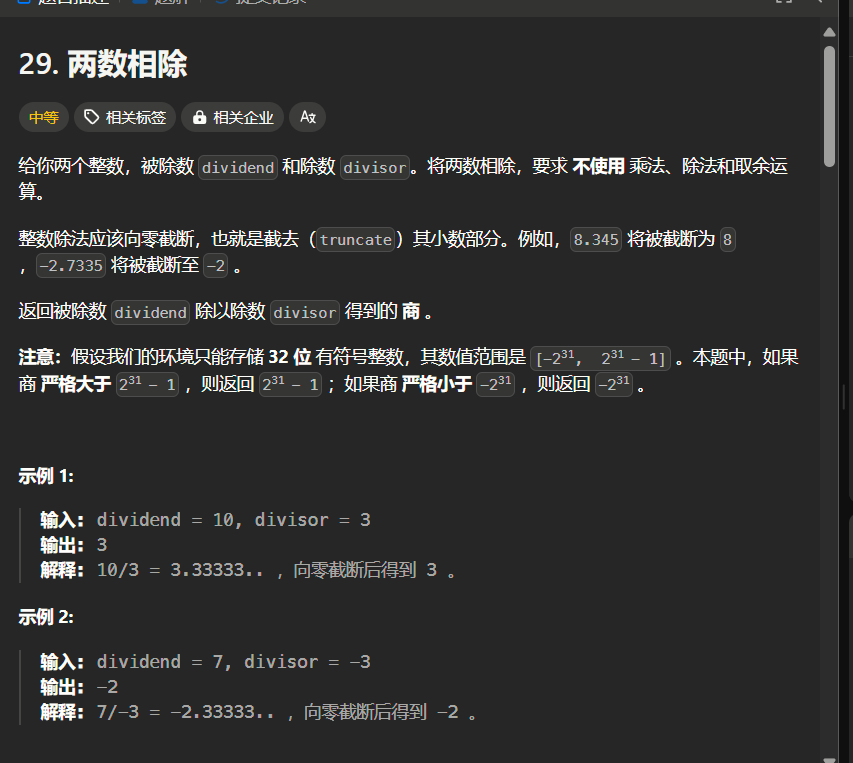
题29(中等):
分析:
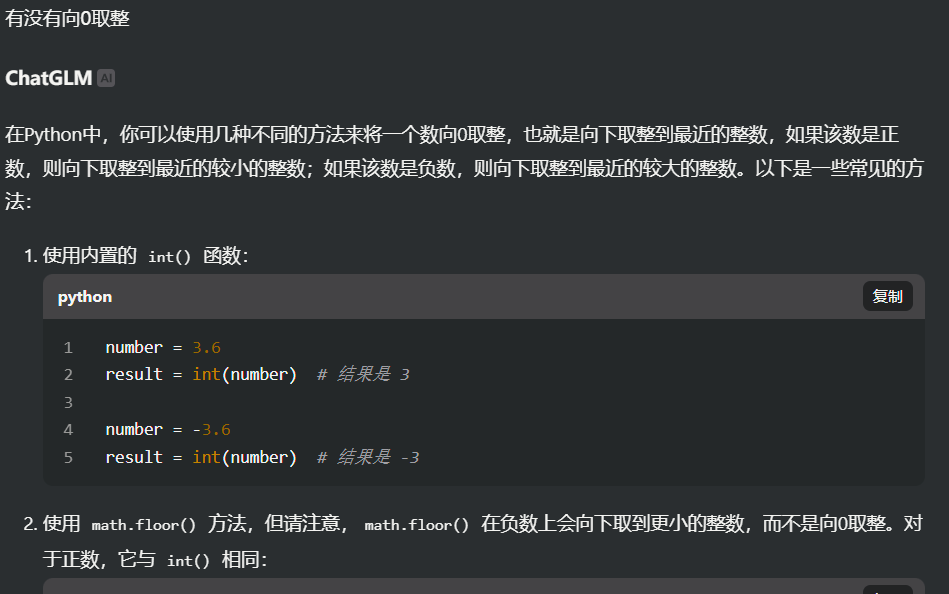
可以多用gpt作为辅助,很多不知道的基础知识可以问出来
python代码:
class Solution:
def divide(self, dividend: int, divisor: int) -> int:
res = int(dividend / divisor)
if res > 2**31 - 1:
return 2**31-1
elif res < -2**31:
return -2**31
else:
return res
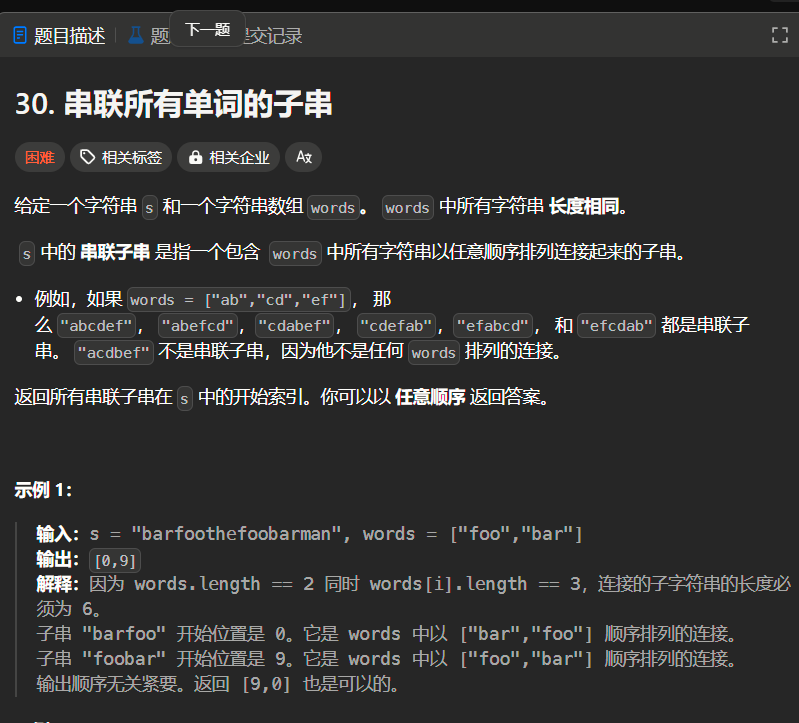
题30(困难):
分析:
说实话,我第一反应是找所有words的位置来减少时间复杂度,结果来一个
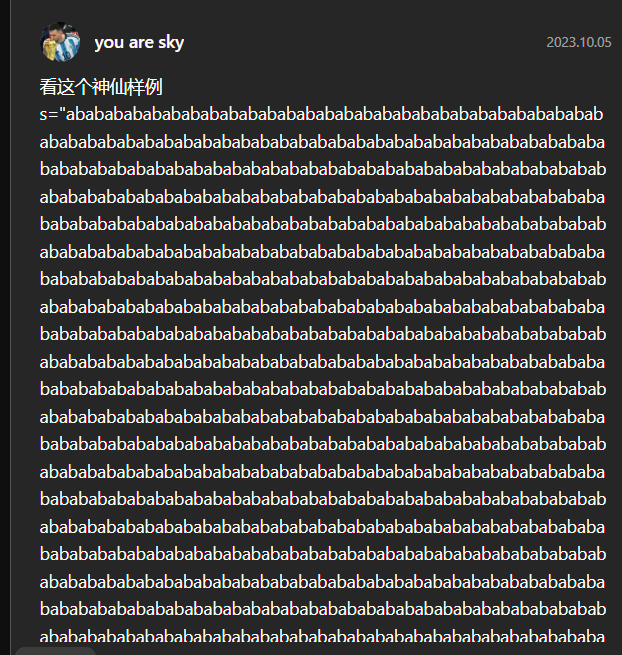
最后迫不得已暴力求解了
python代码:
class Solution:
def findSubstring(self, s: str, words: List[str]) -> List[int]:
word_len=len(words)
word_size=len(words[0])
if word_len*word_size>len(s) or word_len==0:
return []
res=[]
def in_word(word,words):
w1=[word[word_size*i:word_size*(i+1)] for i in range(word_len)]
w1.sort()
w2=sorted(words)
if w1==w2:
return 1
else:
return 0
for i in range(len(s)-word_size*word_len+1):
word=s[i:i+word_size*word_len]
if in_word(word,words):
res.append(i)
return res
总结:
我发现我都注释没怎么写过,导致写得时候思路没有特别清晰,所以要开始写注释了
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 力扣21~30题

发表评论 取消回复