主要适用于二分法, 也可以使用多个逻辑回归实现多分类
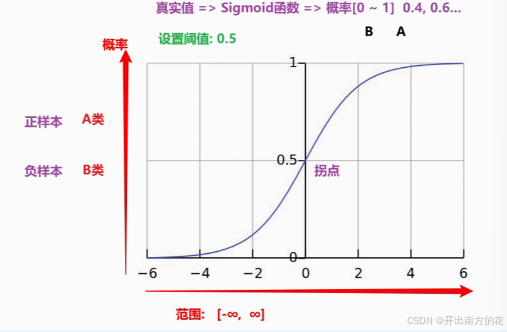
逻辑回归 = 线性回归结果 -> Sigmoid函数 => 概率
概率范围: [0, 1] => 设置阈值(假设: 大于0.5 => A)
一. 逻辑回归简介
应用场景

数学知识
sigmoid函数

概率

极大似然估计
核心思想
设模型中含有待估参数w,可以取很多值。已经知道了样本观测值,从w的一切可能值中(选出一个使该观察值出现的概率为最大的值,作为w参数的估计值,这就是极大似然估计。(顾名思义:就是看上去那个是最大可能的意思)
举个例子
假设有一枚不均匀的硬币,出现正面的概率和反面的概率是不同的。假定出现正面的概率为𝜃, 抛了6次得到如下现象 D = {正面,反面,反面,正面,正面,正面}。每次投掷事件都是相互独立的。 则根据产生的现象D,来估计参数𝜃是多少?
P(D|𝜃) = P {正面,反面,反面,正面,正面,正面}
= P(正面|𝜃) P(正面|𝜃) P(正面|𝜃) P(正面|𝜃) P(正面|𝜃) P(正面|𝜃)
=𝜃 *(1-𝜃)*(1-𝜃)𝜃*𝜃*𝜃 = 𝜃4(1 − 𝜃)
问题转化为:求此函数的极大值时,估计𝜃为多少

对数函数

二. 逻辑回归原理
逻辑回归 = 线性回归结果 -> Sigmoid函数 => 概率
概率范围: [0, 1] => 设置阈值(假设: 大于0.5 => A)
概念

损失函数
原理: 每个样本预测值有A B两个类别, 真实类别对应的位置, 概率越大越好



三. 逻辑回归API函数和案例
逻辑回归API

癌症预估分类案例
数据介绍

代码实现
# 导包
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 1. 加载数据
data = pd.read_csv('data/breast-cancer-wisconsin.csv')
# 查看数据基本信息
data.info()
# 2. 数据处理
# 2.1 用np.NaN替换?
data = data.replace('?', np.NaN)
data.info()
# 2.2 删除缺失值, 按行删除
data.dropna(inplace=True) # 默认按行删除 => axis=0 or index
data.info()
# 2.3 手动提取数据, 即: 特征 和 标签
x = data.iloc[:, 1:-1]
# y = data.iloc[:, -1]
# y = data['Class']
y = data.Class
# 查看数据
print('特征\n', x.head())
print('标签\n', y.head())
# 2.4 数据集划分
x_train, x_test, y_train, y_test = train_test_split(
x, y,
test_size=0.2,
random_state=21
)
# 3. 特征工程
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4. 模型训练
estimator = LogisticRegression()
estimator.fit(x_train, y_train)
# 5. 模型预测
y_predict = estimator.predict(x_test)
# 6.模型评估
print('准确率(预测前)', estimator.score(x_test, y_test))
print('准确率(预测后)', accuracy_score(y_test, y_predict))
四. 分类问题评估
混淆矩阵
概念
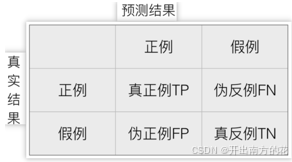
真实值是 正例的样本中,被分类为 正例 的样本数量有多少,叫做真正例(TP,True Positive)
真实值是 正例的样本中,被分类为 假例 的样本数量有多少,叫做伪反例(FN,False Negative)
真实值是 假例的样本中,被分类为 正例 的样本数量有多少,叫做伪正例(FP,False Positive)
真实值是 假例 的样本中,被分类为假例的样本数量有多少,叫做真反例(TN,True Negative)
举例

代码演示
import pandas as pd
from sklearn.metrics import confusion_matrix
# 1. 准备样本数据10条, 6个恶性, 4个良性
y_train = [
'恶性', '恶性', '恶性', '恶性', '恶性', '恶性',
'良性', '良性', '良性', '良性'
]
# 2. 准备标签
label = ['恶性', '良性']
df_label = ['正例', '反例']
# 3. 准备预测值, 即: 模型A => 预测对了3个恶性, 4个良性
y_predict_A = [
'恶性', '恶性', '恶性', '良性', '良性', '良性',
'良性', '良性', '良性', '良性'
]
# 4. 准备预测值, 即: 模型B => 预测对了6个恶性, 1个良性
y_predict_B = [
'恶性', '恶性', '恶性', '恶性', '恶性', '恶性',
'良性', '恶性', '恶性', '恶性'
]
# 5. 基于A模型, 构建混淆矩阵
cmA = confusion_matrix(y_train, y_predict_A, labels=label)
print('混淆矩阵A: \n', cmA)
# 6. 转成df对象
df_A = pd.DataFrame(cmA, index=df_label, columns=df_label)
print('df对象A:\n', df_A)
# 7. 基于B模型, 构建混淆矩阵
cmB = confusion_matrix(y_train, y_predict_B, labels=label)
print('混淆矩阵B: \n', cmB)
# 转成df对象
df_B = pd.DataFrame(cmB, index=df_label, columns=df_label)
print('df对象A:\n', df_B)
精确率(Precision)

计算规则:tp /(tp + fp)
print('A 的精确率', precision_score(y_train, y_predict_A, pos_label='恶性'))
print('B 的精确率', precision_score(y_train, y_predict_B, pos_label='恶性'))
召回率(Recall)
召回率(Recall), 也叫: 查全率, 真正例 在所有正例(真实值) 中的占比 计算规则:tp /(tp + fn)
print('A 的召回率', recall_score(y_train, y_predict_A, pos_label='恶性'))
print('B 的召回率', recall_score(y_train, y_predict_B, pos_label='恶性'))
F1-score(F1值)
F1-Score, 简称叫: F1值, 综合 精确率 和 召回率 计算规则:(2 * precision * recall) / precision + recall
print('A 的F1值', f1_score(y_train, y_predict_A, pos_label='恶性'))
print('B 的F1值', f1_score(y_train, y_predict_B, pos_label='恶性'))
ROC曲线-AUC指标
概念原理
真正率假正率

-
正样本中被预测为正样本的概率TPR (True Positive Rate)
-
负样本中被预测为正样本的概率FPR (False Positive Rate)
通过这两个指标可以描述模型对正/负样本的分辨能力
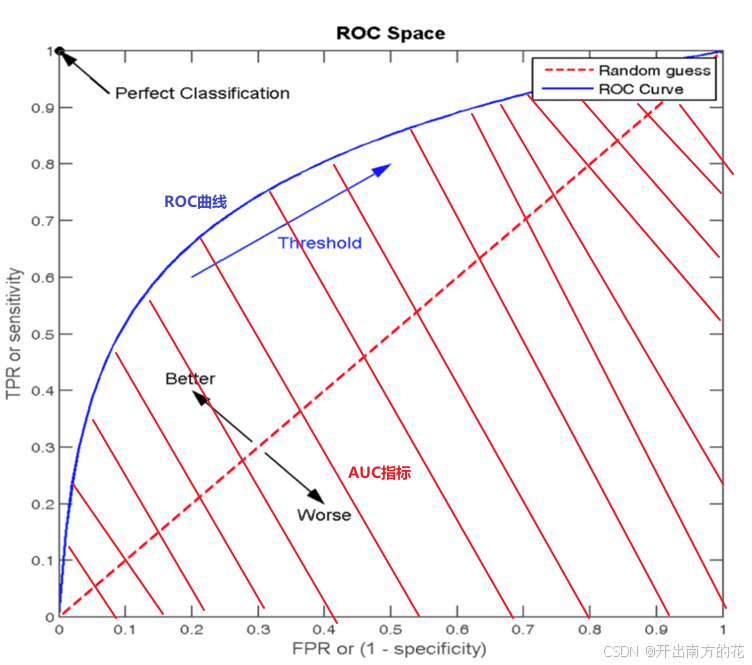
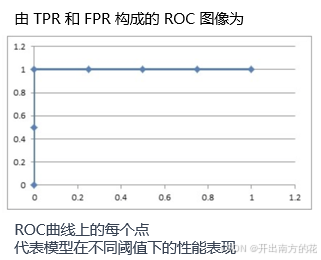
ROC曲线
ROC曲线(Receiver Operating Characteristic curve)是一种常用于评估分类模型性能的可视化工具
ROC曲线以模型的真正率TPR为纵轴,假正率FPR为横轴,它将模型在不同阈值下的表现以曲线的形式展现出来
AUC指标
AUC(Area Under the ROC Curve)曲线下面积
ROC曲线的优劣可以通过曲线下的面积(AUC)来衡量,AUC越大表示分类器性能越好
当AUC=0.5时,表示分类器的性能等同于随机猜测
当AUC=1时,表示分类器的性能完美,能够完全正确地将正负例分类。
特殊点
-
点(0, 0) :所有的
负样本都预测正确,所有的正样本都预测为错误相当于点的(FPR值0, TPR值0)
-
点(1, 0) :所有的
负样本都预测错误,所有的正样本都预测错误相当于点的(FPR值1, TPR值0) ---最不好的效果
-
点(1, 1):所有的
负样本都预测错误,表示所有的正样本都预测正确相当于点的(FPR值1,TPR值1)
-
点(0, 1):所有的
负样本都预测正确,表示所有的正样本都预测正确相当于点的(FPR值0,TPR值1) ---最好的效果
手动计算演示
计算步骤
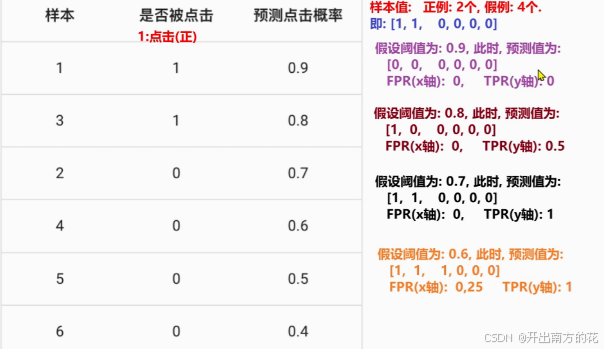
结果图
API
ROC曲线-AUC指标
from sklearn.metrics import roc_auc_score sklearn.metrics.roc_auc_score(y_true, y_score) 计算ROC曲线面积,即AUC值 y_true:每个样本的真实类别,必须为0(反例),1(正例)标记 y_score:(或者是y_predict)预测得分,可以是正例的估计概率、置信值或者分类器方法的返回值
分类评估报告
sklearn.metrics.classification_report( y_true, y_pred, labels=[], target_names=None ) y_true:真实目标值 y_pred:估计器预测目标值 labels:指定类别对应的数字 target_names:目标类别名称 return:每个类别精确率与召回率
总结
ROC曲线
ROC曲线以模型的真正率TPR、假正率FPR为y/x轴,它将模型在不同阈值下的表现以曲线的形式展现出来。
AUC指标
AUC越大表示分类器性能越好
当AUC=0.5时,表示分类器的性能等同于随机猜测
当AUC=1时,表示分类器的性能完美,能够完全正确地将正负例分类
五. 电信客户流失预测案例
案例分析
数据基本处理
主要是查看数据行/列数量
对字符串类别数据数据进行one-hot处理: get_dummies(要处理的df对象)
查看标签分布情况
特征筛选
分析哪些特征对标签值影响大
对标签进行分组统计,对比0/1标签分组后的均值等
初步筛选出对标签影响比较大的特征,形成x、y
划分数据集: x_train, x_test, y_train, y_test
模型训练
样本均衡情况下模型训练
样本不平衡情况下模型训练
交叉验证网格搜素等方式模型训练
模型评估
准确率
精确率
召回率
F1-score
Roc_AUC指标计算
导包
import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score from sklearn.model_selection import train_test_split
数据处理函数
# 1. 定义函数, 表示: 数据预处理.
def dm01_数据预处理():
# 1. 加载数据.
churn_df = pd.read_csv('data/churn.csv')
# 查看数据集.
# churn_df.info()
# 2. 数据预处理, 把 字符串列(object) => 数字列, 采用 one-hot: 热编码.
churn_df = pd.get_dummies(churn_df)
# churn_df.info()
# print(churn_df.describe())
# print(churn_df.head(10))
# 3. 因为热编码之后, 帮我们拆列了, 所以删除不用的列.
churn_df.drop(['Churn_No', 'gender_Male'], axis=1, inplace=True) # 默认: axis=0 按行删, 1的时候表示按列删.
# churn_df.info()
# print(churn_df.head(10))
# 4. 修改列名, 把: 'Churn_Yes' => 'flag'
churn_df.rename(columns={'Churn_Yes': 'flag'}, inplace=True)
churn_df.info()
print(churn_df.head())
# 5. 查看 数据(流失 与 不流失)的分布情况.
print(churn_df.flag.value_counts())
查看数据
# 2. 定义函数, 表示: 数据查看. 绘图.
def dm02_特征筛选():
# 其实就是基于上述 处理后的数据集, 绘制: 计数柱状图, countplot()
# 1. 读取数据集.
churn_df = pd.read_csv('data/churn.csv')
# 2. 类型转换
churn_df = pd.get_dummies(churn_df)
# 3. 删除不需要的列
churn_df.drop(['Churn_No', 'gender_Male'], axis=1, inplace=True)
# 4. 修改列名
churn_df.rename(columns={'Churn_Yes': 'flag'}, inplace=True)
# 5. 查看数据集.
print(churn_df.head())
# 6. 查看 数据集分布情况.
print(churn_df.flag.value_counts())
print(churn_df.columns) # 查看所有的列名
# 7. 绘制: 计数柱状图
sns.countplot(data=churn_df, x='Contract_Month', hue='flag')
plt.show()
模型训练-评估-预测
# 3. 定义函数, 表示: 模型训练, 评估, 预测.
def dm03_模型训练和评估():
# 1. 读取数据集.
churn_df = pd.read_csv('data/churn.csv')
# 2. 数据的预处理.
# 2.1 类型转换
churn_df = pd.get_dummies(churn_df)
# 2.2 删除不需要的列
churn_df.drop(['Churn_No', 'gender_Male'], axis=1, inplace=True)
# 2.3 修改列名
churn_df.rename(columns={'Churn_Yes': 'flag'}, inplace=True)
# 3. 特征工程.
# 3.1 选取: 指标, 标签.
# 特征: 月租会员, 是否使用互联网服务, 支付方式
x = churn_df[['Contract_Month', 'internet_other', 'PaymentElectronic']]
# 标签
y = churn_df['flag']
# 查看下数据集.
print(x.head())
print(y.head())
# 3.2 划分训练集和测试集.
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=21)
# 4. 模型训练.
# 4.1 创建 逻辑回归模型.
estimator = LogisticRegression()
# 4.2 训练模型
estimator.fit(x_train, y_train)
# 5. 模型预测.
y_predict = estimator.predict(x_test)
print(f'预测值: {y_predict}')
# 6. 模型评估.
print(f'正确率(准确率): {estimator.score(x_test, y_test)}')
print(f'正确率(准确率): {accuracy_score(y_test, y_predict)}')
# 参1: 真实值 参2: 预测值
print(f'精确率: {precision_score(y_test, y_predict)}')
print(f'召回率: {recall_score(y_test, y_predict)}')
print(f'F1值: {f1_score(y_test, y_predict)}')
# ROC曲线的面积 => AUC指标.
print(f'ROC曲线的面积(AUC指标): {roc_auc_score(y_test, y_predict)}')
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 机器学习篇-day04-逻辑回归-分类评估-混淆矩阵-精确率-召回率-F1值

发表评论 取消回复