爬虫post收尾以及cookie加代理
目录
1.post请求收尾
2.cookie加代理
post收尾
post请求传参有两种格式,载荷中有请求载荷和表单参数,我们需要做不同的处理。
1.表单数据:data=字典传参
content-type:
application/x-www-form-urlencoded; charset=UTF-8(这种方法是上一篇文章讲到的)
查询字符串参数:跟在url后面的参数
2.请求载荷:json=字典
content-type 告知服务端传入的参数类型是什么类型
application/json;charset=UTF-8 传入的参数是个json格式数据
两种处理办法:
一:
1- 伪装指定content-type
2- 传参还是使用data参数,参数值是一个json字符串
二:
直接使用json参数=字典
第一种方法:
import requests
url = 'https://join.qq.com/api/v1/position/searchPosition?timestamp=1727440821893'
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/129.0.0.0 Safari/537.36',
'content-type':'application/json;charset=UTF-8'
}
data = '{"projectIdList":[1],"keyword":"","bgList":[],"workCountryType":0,"workCityList":
[],"recruitCityList":[],"positionFidList":[],"pageIndex":3,"pageSize":10}'
res = requests.post(url,data=data,headers=headers)
print(res.text)
第二种方法:
import requests
url = 'https://join.qq.com/api/v1/position/searchPosition?timestamp=1727440821893'
data = {"projectIdList":[1],"keyword":"","bgList":[],"workCountryType":0,"workCityList":
[],"recruitCityList":[],"positionFidList":[],"pageIndex":3,"pageSize":10}
res = requests.post(url,json=data)
print(res.text)
cookie
cookie是存储在浏览器中的一组键值对,用来保存当前用户身份
存在时效性的,会过期,过期的时间一般都是服务端指定
如果访问的目标网站需要cookie, 处理的办法:
1.直接复制浏览器中登录之后的cookie, 伪装(请求头)中有一个cookie
存储在客户端(浏览器)中的一组键值对, 能够用于保存一些状态, 但有个要求:必须要先登录。
import requests
url = 'https://my.4399.com/forums/index-getMtags?type=game&page=1'
headers = {
'cookie':'UM_distinctid=18f5d84be7ab12-0d4fcf3a09be2e-26001d51-1fa400-18f5d84be7bf28;
_4399tongji_vid=171526094309656; _4399stats_vid=17152609431943750; _gprp_c="";
smidV2=202405111957567078c442e11c09b2676e719231c52c1f00ffe8aacc95bce90; home4399=yes;
Puser=3073859018; Pnick=%E4%B8%AD%E9%87%8E%E5%B7%A7%E5%AE%89%E6%9B%BC%E5%A6%AE; Qnick=;
Sauth=4078826105%7C3073859018%7C1724907026%7C1725771373%7Cad31369854452fbfe2af%7C%E4%B8%AD%
E9%87%8E%E5%B7%A7%E5%AE%89%E6%9B%BC%E5%A6%AE%7C%E4%B8%AD%E9%87%8E%E5%B7%A7%E5%AE%89%E6%9B%B
C%E5%A6%AE%7C47e7e4cfced0bcb5a19d88b03d094613;
Hm_lvt_334aca66d28b3b338a76075366b2b9e8=1724391240,1724906618,1724932650;
ptusertype=my.4399_login; zone_guide_date=1724947200; zone_guide_time=2;
_4399tongji_st=1724933289; USESSIONID=e61b6eb4-3e07-48dd-b354-c9fe6ef545d2;
Hm_lvt_5c9e5e1fa99c3821422bf61e662d4ea5=1724906645,1724932678,1724933289;
HMACCOUNT=13108745FF137EDD;
Hm_lvt_e5a07b5994f78634294b9c347a5be7d2=1724906645,1724932678,1724933289; phlogact=l1493;
Uauth=4399|1|2024829|my.|1724933589815|d59a0688a9891db73745cf920f83aa63;
Pauth=4078826105|3073859018|t3ce7n2813b76b1e854c4b9428c211e1|1724933589|10002|690950f30d878
aa6ed7e245af0c9fb18|2; ck_accname=3073859018; Xauth=6b199edef659802ab9fac4d9eea16604;
Hm_lpvt_e5a07b5994f78634294b9c347a5be7d2=1724933589;
Hm_lpvt_5c9e5e1fa99c3821422bf61e662d4ea5=1724933589;
Pmtime=85fe178bc1e94ed171d3%7C1724933590; ol=1'
}
res = requests.get(url,headers=headers)
res.encoding = 'utf-8'
print(res.text)
爬虫获取群组数据:
1- 找数据所在的url
https://my.4399.com/forums/index-getMtags?type=game&page=1
2- 请求成功之后,得到的反馈信息是要先登录(明明浏览器已经登录了,为什么还要登录,因为浏览器和代码没有关系)
3- 如何解决登录问题:
1- 带上登录之后的cookie:当你登录完成之后,会保存一些用户信息在里面,cookie中保存的内容不会永久有效,时间期
限(服务端决定)
优点:简单直接,缺点:会过期
2.通过模拟登录,登录成功之后获取cookie(大部分网站实现登录,密码都进行了加密,所以这种方式不适用所有
网站,但是4399可以直接传入明文,服务端没做密码是否为密文的检测,只做了密码是否正确的检测)
# 1- 登录请求
# 2- 获取数据请求
# 模拟登录
login_url = 'https://ptlogin.4399.com/ptlogin/login.do?v=1'
# post请求传入参数
import requests
data = {
'loginFrom':'uframe',
'postLoginHandler':'refreshParent',
'layoutSelfAdapting':'false',
'externalLogin':'qq',
'displayMode':'embed',
'layout':'vertical',
'appId':'u4399',
'css':'https://uc.img4399.com/root/css/ptlogin.css?a3993b7',
'mainDivId':'embed_login_div',
'includeFcmInfo':'false',
'level':'0',
'regLevel':'4',
'userNameLabel':'4399用户名',
'userNameTip':'请输入4399用户名',
'welcomeTip':'欢迎回到4399',
'sec':'1',
'password':'hkyx8888', # 4399服务端支持密码传入明文,但是其它网站的登录不一定支持
'username':'3073859018',
}
# 登录之后的响应对象 如果登录成功,服务端返回cookie,保存在响应对象中
login_res = requests.post(login_url,data=data)
# 目标url
url = 'https://my.4399.com/forums/index-getMtags?type=game&page=2'
res = requests.get(url,cookies=login_res.cookies)
res.encoding = 'utf-8'
print(res.text)
因为访问群组页面,需要先登录账号
爬虫也可以先登录,服务端会返回cookie(包含了用户信息)
再获取目标url的时候带上登录后的cookie
小tips:
我们可以看到data里面的数据, 有这么多的键值对, 都从网上赋值过来的文本数据, 那怎么一键变为键值对数据呢?
这个其实很简单, 我们在pycharm里面打开替换文本的工具(Ctrl+r快捷键打开)。
注意: 需要点亮星星哦, 就是最上面中间的地方, .*那个符号。
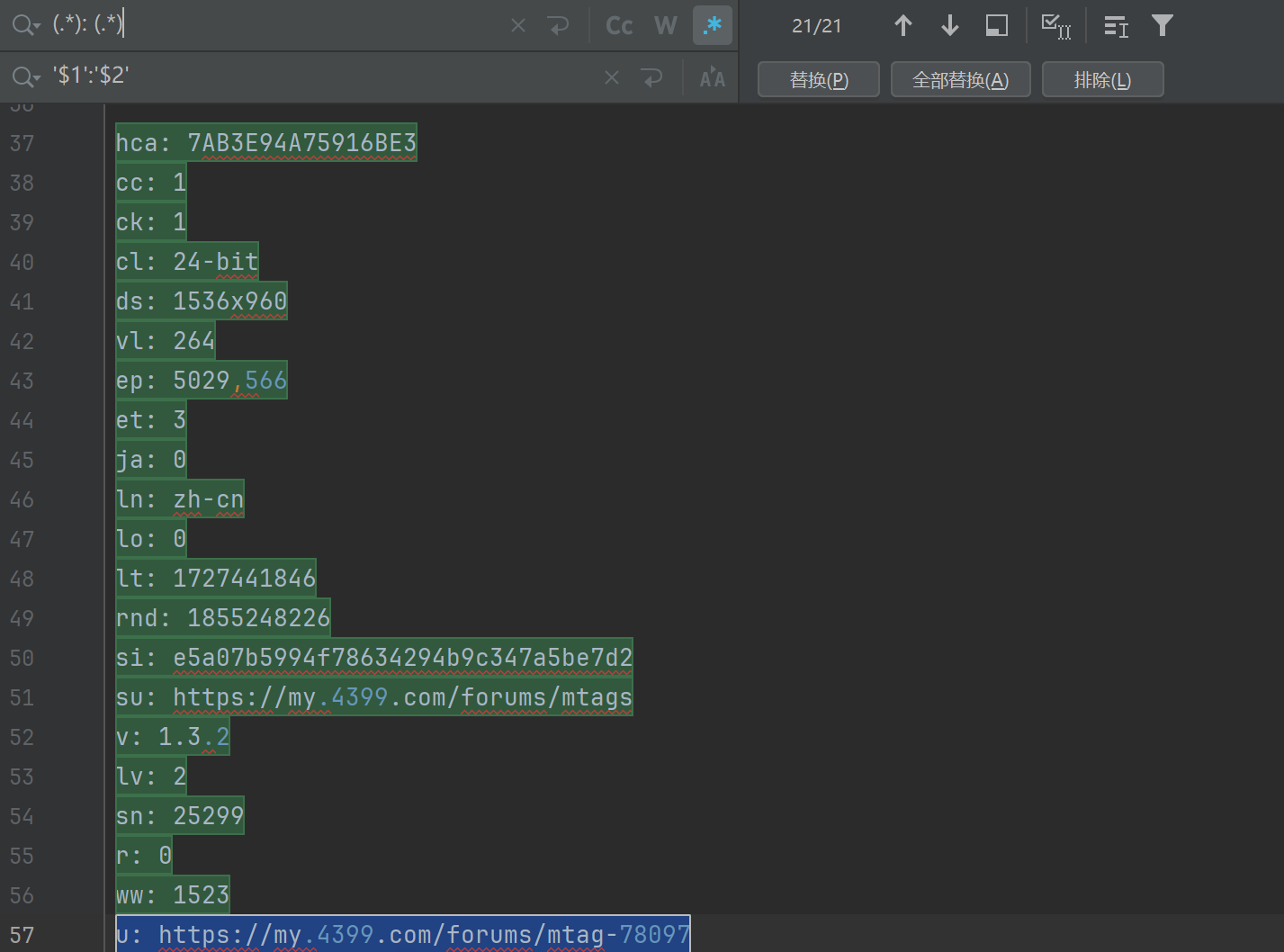
代码区自动会帮我们选中需要替换的区域
我们点击全部替换, 然后再给它放到一个字典里面去。
d = {
'hca': '7AB3E94A75916BE3',
'cc': '1',
'ck': '1',
'cl': '24-bit',
'ds': '1536x960',
'vl': '264',
'ep': '5029,566',
'et': '3',
'ja': '0',
'ln': 'zh-cn',
'lo': '0',
'lt': '1727441846',
'rnd': '1855248226',
'si': 'e5a07b5994f78634294b9c347a5be7d2',
'su': 'https://my.4399.com/forums/mtags',
'v': '1.3.2',
'lv': '2',
'sn': '25299',
'r': '0',
'ww': '1523',
'u': 'https://my.4399.com/forums/mtag-78097'
}
以后大家可以多使用这种方法哦, 既方便又快捷, 但是需要注意的是在我们把修改好的数据全部放到新的字典里面去的时候, 每一句话的最后一行都要加分号。
实战:
获取腾讯招聘的招聘项目每一个框里面的数据(应届生的岗位投递信息, 就最下方最大的红色框里面的信息)。
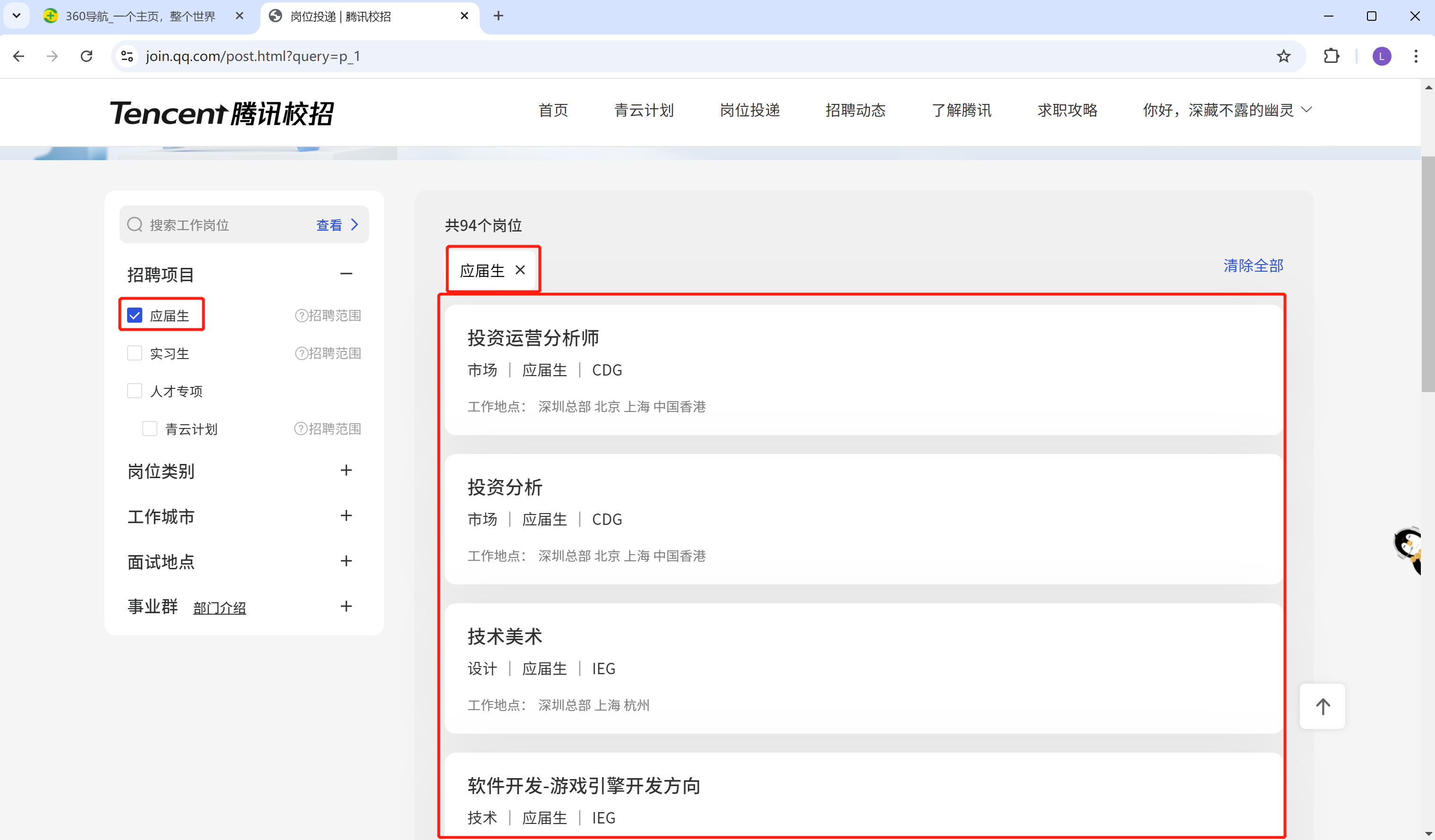
自己先尝试的去做一做, 不要马上看答案哦。
参考答案:
import requests
pageIndex = 1
count = 1
# 分页获取数据
while True:
url = 'https://join.qq.com/api/v1/position/searchPosition?timestamp=1727532633390'
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36",
"cookie": "UserInfo=1kij6FX225E8Xm5SldigGuGG8cYEEgz+nyKdgtlbiSLV5y/bsU4j/m2d1S8+dYWCQx0yLKUpGj4XJ3ZRiN5VrTuBbk3TnGGbSg7faVuROyuNOoS5p+gSyNqCS6nc51VLWrECSpiILWyPk2xP32aoS1cWGP37hTHHQzLZeJYd/QsSTJ/sSuDenS9g26yEgmphPnHE0Bfq/EDG1XZUS41Pni2nwHYHeEgEfhNspL25x67XXcVhZg+b7NYaSnklM/I2GLEH8c3gXpVU6/4jC4i6kg==; loginMark=02"
}
data = {
'bgList': [],
'pageIndex': pageIndex,
'pageSize': 10,
'positionFidList': [],
'projectIdList': [1, 2, 12, 14],
'recruitCityList': [],
'workCityList': [],
'workCountryType': 0
}
response = requests.post(url, headers=headers, json=data)
data = response.json()
if data['data']['positionList'] is not None:
for i in data['data']['positionList']:
# 工作岗位
work_title = i['positionTitle']
# 应届生的背景
bgs = i['bgs']
# 工作地点
workCities = i['workCities']
print(count)
print("工作岗位:", work_title)
print("应届生的背景:", bgs)
print("工作地点:", workCities)
count += 1
else:
break
pageIndex += 1
这个实战题你写出来了吗?如果写出来的话, 给自己一个掌声哦。
以上就是爬虫post收尾以及cookie的所有内容了, 如果有哪里不懂的地方,可以把问题打在评论区, 欢迎大家在评论区交流!!!
如果我有写错的地方, 望大家指正, 也可以联系我, 让我们一起努力, 继续不断的进步.
学习是个漫长的过程, 需要我们不断的去学习并掌握消化知识点, 有不懂或概念模糊不理解的情况下,一定要赶紧的解决问题, 否则问题只会越来越多, 漏洞也就越老越大.
人生路漫漫, 白鹭常相伴!!!
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 爬虫post收尾以及cookie加代理

发表评论 取消回复