目录
题目:DAMEX: Dataset-aware Mixture-of-Experts for visual understanding of mixture-of-datasets
数据集感知的专家混合模型,用于混合数据集的视觉理解
Abstract
通用普通的detector的构建提出了一个关键问题:我们如何才能在大型混合数据集上有效地训练模型。答案在于,在单个模型中,学习特定于数据集的特征并集成他们的知识。以前的方法通过在一个共同的主干上使用单独的检测头来实现这一点,但这会导致参数显着增加。
在这项工作中,我们提出了专家混合作为解决方案,突出了 MoE 比可扩展性工具多得多。我们提出了 Dataset-Aware Mixture-of-Experts, DAMEX,我们通过学习将每个数据集标记路由到其映射的专家来训练专家成为数据集的“专家”。在通用对象检测基准上的实验表明,我们比最先进的平均高出 +10.2 AP 分数,并且比我们的非 MoE 基线提高了平均 +2.0 AP 分数。我们还观察到在将数据集与 (1) 有限可用性、(2) 不同领域和 (3) 不同标签集混合时的持续收益。此外,我们定性地表明 DAMEX 对专家表示崩溃具有鲁棒性。
1. Introduction
建议专家混合不仅仅是可扩展的学习者,而是为数据集混合构建通用模型的有效和高效的解决方案。在 vanilla MoE 的基础上,我们引入了一种新的数据集感知混合专家模型 DAMEX,该模型学习解开 MoE 层的特定数据集特征,同时汇集非 MoE 层的信息。DAPEX学会将令牌路由到相应的专家,以便在推理过程中,它通过网络自动选择测试图像的最佳路径。我们使用基于DINO[42]的检测体系结构来开发我们的方法
contributions
3. 传统的MOE
在论文的 "3.1 Routing of tokens" 部分,作者介绍了如何在Mixture-of-Experts (MoE) 模型中进行令牌路由。以下是公式的解释:
-
令牌和专家表示:
- 输入令牌表示为 x∈RDx∈RD,其中 DD 是令牌的维度。
- 专家集合表示为 {ei}i=1∣E∣{ei}i=1∣E∣,其中 ∣E∣∣E∣ 是专家的总数。
- 路由器变量表示为 Wr∈RE×DWr∈RE×D,这是一个权重矩阵,用于确定每个专家的选择概率。
-
计算专家选择概率:
-
首先,计算每个专家的选择得分 gxgx: gx=Wr⋅xgx=Wr⋅x 这是路由器变量 WrWr 与输入令牌 xx 的点积。
-
然后,计算每个专家 eiei 的选择概率 pi(x)pi(x): pi(x)=exp(gxi)∑j=1∣E∣exp(gxj)pi(x)=∑j=1∣E∣exp(gxj)exp(gxi) 这里,exp(gxi)exp(gxi) 是指指数函数 egxiegxi,分母是所有专家得分指数的总和。这个公式实现了一个softmax函数,它将每个专家的得分转换为一个概率分布,其中每个概率表示选择对应专家处理输入令牌的可能性。
-
-
令牌路由:
- 接下来,使用top-k策略来选择概率最高的k个专家来处理令牌。在论文中,kk 被设置为1,意味着只选择概率最高的一个专家。
- 计算输出 yy 作为选定专家处理过的令牌的加权组合: y=∑i∈top-kpi(x)ei(x)y=∑i∈top-kpi(x)ei(x) 这里,ei(x)ei(x) 是被选中的专家对输入令牌 xx 进行处理后的输出。输出 yy 是根据每个专家被选中的概率 pi(x)pi(x) 加权后的结果。
通过这种方式,MoE模型能够将输入数据分配给最擅长处理该数据的专家,从而提高整个模型的效率和性能。这种方法也有助于提高模型的可扩展性和处理不同类型数据的能力。
负载均衡损失:
在论文的 "3.2 Load balancing among the experts" 部分,作者讨论了如何在MoE模型中的专家之间进行负载平衡。以下是公式的解释:
1. 专家的重要性损失(Importance Loss):
- 对于每个专家 \( e_i \),计算其重要性 \( I_i \):
\[
I_i = \sum_{x \in \mathcal{M}} p_i(x)
\]
这里,\( \mathcal{M} \) 是一批输入令牌的集合,\( p_i(x) \) 是选择专家 \( e_i \) 处理令牌 \( x \) 的概率。重要性 \( I_i \) 表示专家 \( e_i \) 被选中的总次数。
- 然后,计算重要性损失 \( L_{\text{importance}} \):
\[
L_{\text{importance}} = \frac{\text{Var}(I)}{\text{Mean}(I)^2}
\]
这里,\( \text{Var}(I) \) 是重要性 \( I \) 的方差,\( \text{Mean}(I) \) 是 \( I \) 的均值。这个损失函数旨在最小化专家重要性的方差,从而确保所有专家的使用相对均衡。
2. 专家的负载损失(Load Loss):
- 对于每个专家 \( e_i \),计算其负载 \( L_i \):
\[
L_i = \sum_{x \in \mathcal{M}} \Phi(p_i(x))
\]
这里,\( \Phi \) 是正态分布 \( N(0, \sigma^2 I) \) 的累积分布函数(CDF),其中 \( \sigma = \frac{\text{gate noise}}{|E|} \)。负载 \( L_i \) 表示专家 \( e_i \) 被分配的令牌数量。
- 然后,计算负载损失 \( L_{\text{load}} \):
\[
L_{\text{load}} = \frac{\text{Var}(L)}{\text{Mean}(L)^2}
\]
这里,\( \text{Var}(L) \) 是负载 \( L \) 的方差,\( \text{Mean}(L) \) 是 \( L \) 的均值。这个损失函数旨在最小化专家负载的方差,从而确保所有专家的负载相对均衡。
3. 负载平衡的辅助损失(Load Balancing Auxiliary Loss):
- 最后,计算负载平衡的辅助损失 \( L_{\text{load-balancing}} \):
\[
L_{\text{load-balancing}} = L_{\text{importance}} + \frac{L_{\text{load}}}{2}
\]
这个损失函数结合了重要性损失和负载损失,以确保在训练过程中专家的使用和负载都保持均衡。
通过引入这个负载平衡的辅助损失,MoE模型可以更有效地利用所有专家,避免某些专家过载而其他专家闲置,从而提高模型的整体性能和稳定性。
4. 方法
DAMEX(Dataset-aware Mixture-of-Experts)的Loss计算方法涉及到一个辅助的交叉熵损失函数。这个损失函数的设计是为了训练MoE(Mixture-of-Experts)路由器,以便根据输入令牌的数据集来源将它们路由到相应的专家。
在DAMEX中,每个数据集被分配给一个特定的专家。这意味着,不是所有来自相同数据集的令牌都有相同的标签,而是它们被分配给特定的专家进行处理。这里的“标签”实际上是指目标专家的索引,而不是传统意义上图像分类任务中的类别标签。
举例来说,假设我们有三个数据集:COCO、DOTA和ImageNet。每个数据集都分配给了一个不同的专家。如果一个输入令牌来自COCO数据集,那么根据映射函数\( h \),它将被分配给负责COCO数据集的专家,假设这个专家是专家1(\( e_1 \))。因此,这个令牌的目标标签就是1,表示它应该被路由到专家1。路由器的任务是预测这个令牌应该被路由到哪个专家,预测的概率由\( p_i(x) \)给出,其中\( i \)是专家的索引,\( x \)是输入令牌。
辅助损失\( \mathcal{L}_{\text{DAMEX}} \)的计算公式为:
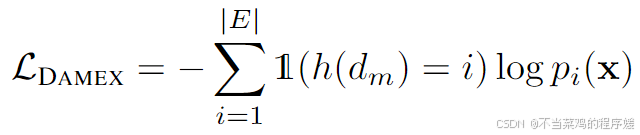
在这个公式中,\( 1\left(h(d_m)=i\right) \)是一个指示函数,当\( h(d_m) \)等于\( i \)时,它的值为1,否则为0。这意味着只有当预测的专家索引\( i \)与目标专家索引相匹配时,才会计算损失。\( p_i(x) \)是模型预测的第\( i \)个专家被选中的概率。
通过这种方式,DAMEX训练路由器将所有来自特定数据集的视觉令牌发送到其对应的专家,从而确保MoE的有效利用,并避免表示崩溃。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 论文阅读MOE-DAMEX

发表评论 取消回复