中文译名:SCOTT: 思维链一致性蒸馏
会议:Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
链接:SCOTT: Self-Consistent Chain-of-Thought Distillation - ACL Anthology
摘要:
尽管思维链 CoT 可以显著提高性能,但这种收益仅在足够大的 LMs 中才能观察到。更令人担忧的是,几乎无法保证生成的理由与 LM 的预测一致或忠实地证明决策的合理性。在这项工作中,我们提出了 SCOTT,这是一种忠实的知识蒸馏方法,用于从规模大几个数量级的教师模型中学习一个小型、自洽的 CoT 模型。为了形成更好的监督,我们通过对比解码从大型 LM(教师)中引出支持黄金答案的理由,这鼓励教师生成仅在考虑答案时才更合理的标记。为了确保忠实的蒸馏,我们使用教师生成的理由以反事实推理 目标来学习学生 LM,这防止学生忽略理由做出不一致的预测。实验表明,在产生相当的最终任务性能的同时,我们的方法可以生成比基线更忠实的 CoT 理由。进一步的分析表明,这样的模型在做决策时更尊重理由;因此,我们可以通过改进其理由来更多地提高其性能。
现有工作:
主要出于计算效率或任务性能的考虑,提议从大型 LMs 中学习推理。他们提示一个大型 LM (教师)为下游数据集生成理由,然后用于训练一个小型 LM (学生)。
存在问题:
- LMs 容易产生幻觉,这意味着它们经常生成与输入无关的文本。因此,教师可能无法生成完全支持答案的主题相关理由。
- 学生可能将理由生成和答案预测视为两个独立的过程。 这是由于问题和答案之间的虚假相关性,学生将其作为推理捷径。
上面的两个问题共同导致一个不忠实的学生,会生成空洞的理由,且可能做出与理由不一致的预测。
文中的方法:
方法设计:
分别从两个方面增强普通的知识蒸馏 KD 过程。
- 为了从教师那里引出更多主题相关的理由,我们提议利用对比解码,旨在将每个理由与答案联系起来。这种技术鼓励教师生成仅在考虑答案时更合理的标记,而不是在不考虑答案时也相当合理的标记。
对比解码技术:通过向教师模型提供扰动答案(空字符串或错误答案),计算每个标记的合理性增长,以获得更一致的教师模型,使其生成的理由更符合主题且能更好地支持黄金答案。 - 为了训练一个忠实的学生,我们要求学生进行反事实推理,即当理由导致不同答案时相应地进行预测:通过要求教师为抽样的错误答案生成理由来获得训练数据
反事实推理训练:通过将正确答案替换为错误答案获取反事实理由,训练学生模型更加忠实于生成的理由进行预测,避免忽略理由导致的不一致预测。
目标:
- 从大型语言模型中引出一致的理由,即那些能很好地证明黄金答案的理由,作为监督
- 训练一个自洽的学生模型来忠实推理, 即根据其生成的理由进行相应的回答
具体描述:
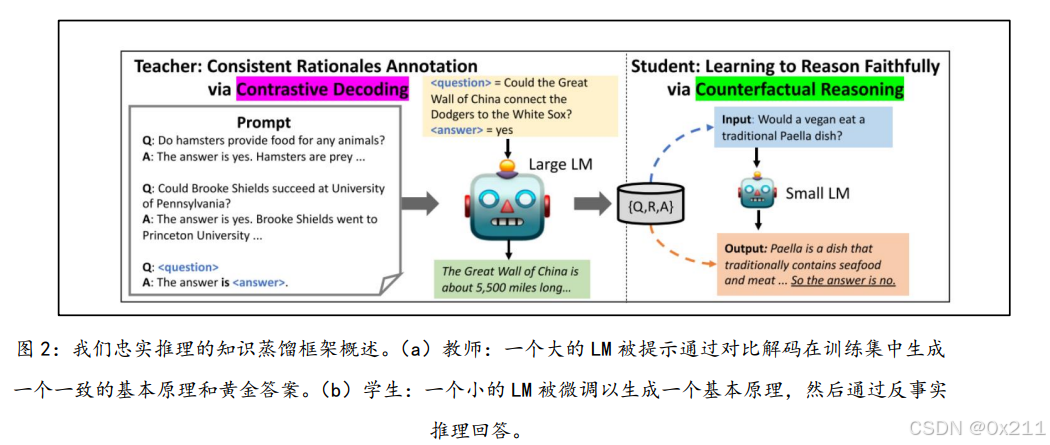
数据集:
使用上 文学习自动从教师模型中获取理由,而不是要求人类为每个问 题 - 答案元组{q, a∗}标注一个理由。
思路是在提供新实例之前,用仅几个标注示例作为演示来提示一个冻结的语言模型作为教师。每个示例由从训练集中随机抽样的问题 q、黄金答案 a∗和一个人类标注的理由 r 组成,该理由说明 a∗为什么是正确的。
提示词的策略如上图。
训练:
在这项工作中,我们专注于自我合理化范式,其中学生首先生成一个理由,然后根据生成的理由预测答案。这与相关工作不同,后者进行事后合理化,即在预测答案后生成理由,或者进行多任务学习,将理由生成视为除答案预测之外的辅助任务。原因是后两种范式中理由的生成从设计上不影响决策,因此理由的忠实性首先无法 得到保证。
蒸馏一个自相一致的学生模型:
常规的知识蒸馏中,如果老师模型输出了不相关的文本(幻觉),导致生成的理由不支持给定的答案,这种理由和答案的不一致性将被学生模型学到,从而误导学生认为答案预测和理由生成是相互独立的;学生模型会通过采取推理捷径来学习预测答案而不考虑生成的理由。
上述问题导致一个不可信的学生模型,其生成的理由不能始终如一地证明答案的合理性。
文章提出了两个相应的技术

对比解码
对比解码基于这样一个假设,即模型在生成理由时,应该更倾向于生成那些在考虑答案时更合理的标记。通过向教师模型提供扰动答案(可以是空字符串或错误答案),计算每个标记的合理性增长。
扩展了一种先前称为对比解码的技术,用于开放式文本生成
核心思想是搜索仅在考虑答案时更合理的理由标记,而不是在不考虑答案时也相当合理的标记。
向同一教师提供一个干扰答案a'来建模幻觉行为,然后获得给定答案 a ∗时任何标记 ti的合理性增长
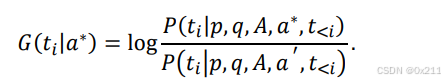
设计了两种干扰答案的方式: 将 a '设置为空字符串或除 a ∗之外的错误答案
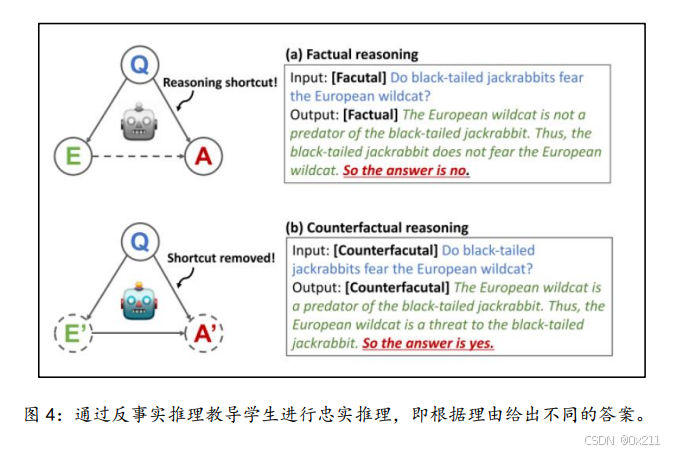
反事实推理
反事实推理是一种假设在某些条件发生改变的情况下,结果会如何不同的思维方式。在本文的方法中,反事实推理用于训练学生模型更加忠实于理由进行预测。具体操作是将教师模型中原本的黄金答案替换为错误答案a^',按照与之前相同的方式(例如使用相同的采样策略)让教师模型生成相应的反事实理由r^'。然后,训练学生模型在接收到反事实理由时,应该预测出与该反事实理由相对应的错误答案a^'。这样可以迫使学生模型不能仅仅依赖于问题和答案之间可能存在的虚假相关性,而是要真正根据理由进行预测,从而提高学生模型对理由的忠实性。
为了鼓励学生对其生成的理由进行忠实推理,训练学生进行反事实推理,即当理由导致不同答案时相应地进行预测,在学生被要求对同一问题根据理由给出不同的答案
实验结果:
- 对比解码可以导致一个更一致的教师,其生成的理由更支持黄金答案。
- 在更一致的 理由 - 答案 对上进行训练,学生学会更好地将答案预测与理由生成联系起来。
- 通过反事实推理作为辅助训练目标,学生学会不采用推理捷径, 而是更加尊重理由。
- 尽管更加忠实,但我们的模型与基线模型的性能相当。
- 消融研究表明,尽管表现更好,但更大的学生模型更容易不一致。我们的方法无论学生模型的大小如何,都能稳健地纠正这种不一致性。
- 有了一个更忠实的学生,我们可以通过纠正其理由来更好地提高其性能,展示了我们的方法 在模型改进中的效用。
总结
优点: 对比解码能有效鼓励教师生成更符合主题、更具区分性的理由;反事实推理使得学生模型更加忠实于生成的理由进行预测。
缺点:对比解码增加了计算成本;方法侧重于提高理由忠实性而非性能提升。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » [论文阅读]SCOTT: Self-Consistent Chain-of-Thought Distillation

发表评论 取消回复