论文名称是 Visual Instruction Tuning 视觉指令微调
摘要
我们首次尝试仅使用语言模型GPT-4来生成多模态的语言-图像指令跟随数据。
通过在生成的数据上进行指令微调,我们引入了LLaVA(Large Language and Vision Assistant):一个端到端训练的大型多模态模型,它将视觉编码器与LLM(Large Language Model)连接起来,用于通用的视觉和语言理解。
构建了两个评价基准。
llava的效果:在一个合成的多模态指令遵循数据集上相对于GPT-4获得了85.1%的相对分数
当在Science QA上进行微调时,LLaVA和GPT-4的协同作用达到了92.53%的新的状态-of-the-art准确率。
我们使GPT-4生成的视觉指令调优数据、我们的模型和代码公开可用。
介绍
开放世界的视觉理解能力(包含 分类、检测 detection、分段 segmentation、标题生成 captioning、视觉生成和视觉编辑 visual generation and editing)
LLM的能力:对齐的LLMs在遵循人类指令方面的强大能力
文章主要贡献:
(1)多模态指令跟随数据,我们提出了一种数据改格式化的方法和流程,利用ChatGPT或GPT-4将图像-文本对转化为合适的指令执行格式。
(2)多模态大模型,LMM,CLIP+Vicuna,多模态推理数据集 Science QA
(3)LLaVA-Bench 包含两个有挑战的基准:图像、指令和详细注解。
(4)开源:生成的多模态指令数据、代码库、模型检查点和视觉聊天演示。
2 相关工作
指令调优:指令调优对应的模型有 InstructGPT [ 37]/ChatGPT [35], FLAN-T5 [ 11 ], FLAN-PaLM [ 11 ], and OPT-IML。 这种方法简单却能有效地提高LLMs的零样本和少样本泛化能力。因此,借鉴NLP领域的思想到计算机视觉领域是很自然的。更广泛地说,教师-学生蒸馏思想已经在其他领域,如图像分类中,与基础模型一起进行了研究。
Flamingo 视为 多模态领域的GPT3模型,因为它在零样本任务迁移和上下文学习方面的出色表现。
OpenFlamingo [5] 和 LLaMA-Adapter [59] 是开源项目,它们使 LLaMA 能够使用图像输入,为构建开源的多模态LLMs铺平了道路。
虽然这些模型在任务迁移泛化性能方面表现出潜力,但它们并没有使用视觉语言指令数据进行明确的微调,因此在多模态任务中的表现通常逊色于仅语言任务。
在这篇论文中,我们的目标是填补这一空白并研究其有效性。最后请注意,视觉指令微调 visual instruction tuning 与视觉提示微调 visual prompt tuning [23]不同:前者旨在提升模型遵循指令的能力,而后者旨在提高模型适应时的参数效率。
3 GPT 辅助的视觉指令数据生成
4 视觉指令微调
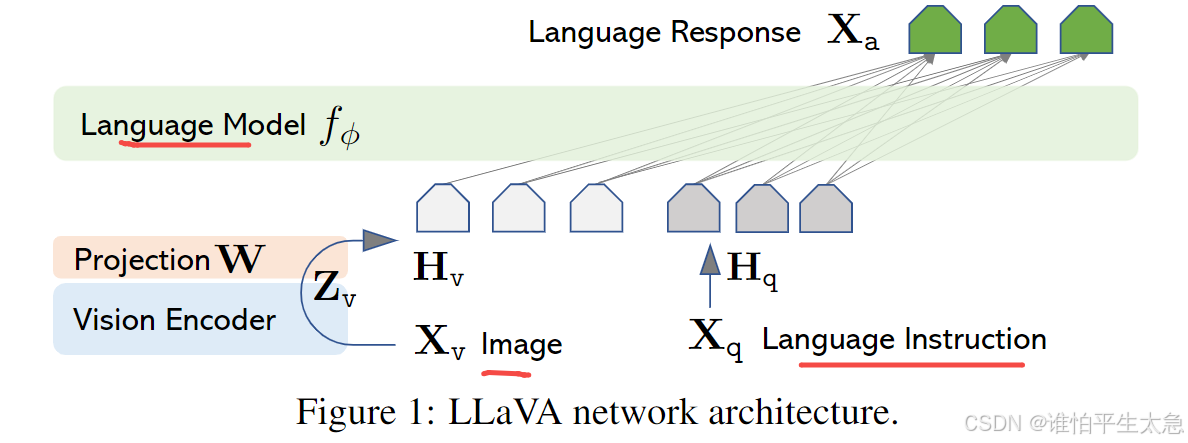
4.1 结构
用vision encoder对image进行编码,编码后用投影矩阵W 将其映射成和 语言嵌入Hq 相同维度的 视觉嵌入 Hv
[使用一个简单的线性层将图像特征连接到词嵌入空间]
也可以考虑更复杂的图像和语言表示之间的连接方案,比如Flamingo中的门控交叉注意力(gated cross-attention)和BLIP-2中的Q前缀(Q-former)。
4.2 训练
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » llava论文阅读

发表评论 取消回复