裸土未覆盖检测数据集 1000张 裸土检测 带标注voc yolo

裸土未覆盖检测数据集 1000张 裸土检测 带标注voc yolo


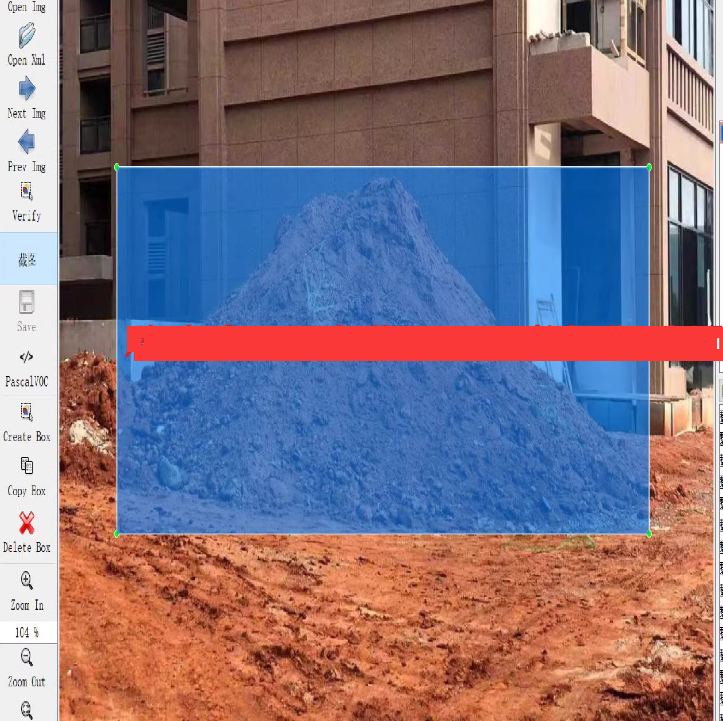
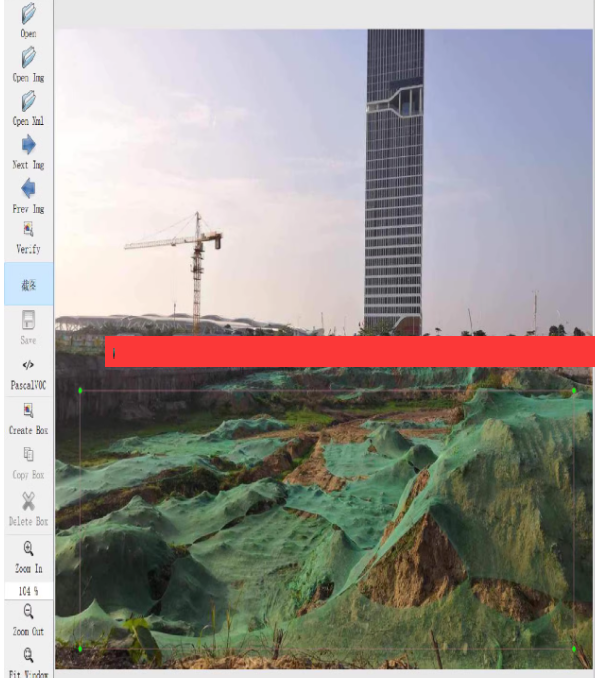
裸土未覆盖检测数据集介绍
概述
裸土未覆盖检测数据集是一个专门用于检测和识别图像中未被植被或其他材料覆盖的裸露土壤区域的数据集。该数据集包含1000张图像,每张图像都带有详细的标注信息,支持多种格式,如VOC(Pascal VOC)和YOLO(You Only Look Once)。这类数据集对于环境监测、土地管理以及城市规划等领域非常有用。
数据集特点
- 规模:共包含1000张高分辨率图像。
- 多样性:图像涵盖了不同的地理区域、季节变化、光照条件以及天气状况,以确保模型能够适应多样的实际场景。
- 标注质量:每张图像都有精确的手动标注,确保了高质量的训练数据。
- 标注格式:
- VOC格式:符合Pascal VOC标准的XML文件,包含了图像的基本信息、对象类别以及边界框坐标。
- YOLO格式:每个目标用一个文本行表示,格式为
class_id x_center y_center width height,所有坐标值都是归一化的。
标注信息
-
VOC格式:
<annotation> <folder>images</folder> <filename>image_0001.jpg</filename> <size> <width>800</width> <height>600</height> <depth>3</depth> </size> <object> <name>bare_soil</name> <bndbox> <xmin>150</xmin> <ymin>100</ymin> <xmax>400</xmax> <ymax>300</ymax> </bndbox> </object> </annotation> -
YOLO格式
0 0.375 0.25 0.375 0.375解释:
0表示类别ID(假设0代表裸土),x_center和y_center是边界框中心点的归一化坐标,width和height是边界框的宽度和高度的归一化值。
应用领域
- 环境监测:监测裸土区域,评估土地侵蚀风险。
- 土地管理:帮助管理者识别需要植被覆盖或采取其他保护措施的区域。
- 城市规划:在城市扩展过程中,监测裸土区域以进行合理的绿化规划。
- 农业:监测农田中的裸土区域,优化耕作和灌溉策略。
获取方式
通常情况下,研究人员可以通过官方提供的链接或相关机构网站下载该数据集。请注意,使用时应遵循相应的许可协议和引用要求。
关键代码示例
1. 下载数据集
假设我们已经有了数据集的下载链接,可以使用 Python 的 requests 库来下载数据集:
import requests
import os
# 定义下载链接和保存路径
url = 'http://example.com/path/to/bare_soil_dataset.zip' # 替换为实际的下载链接
save_path = './bare_soil_dataset.zip'
# 检查是否已经下载过
if not os.path.exists(save_path):
print("Downloading dataset...")
response = requests.get(url, stream=True)
with open(save_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
if chunk:
f.write(chunk)
print("Download complete.")
else:
print("Dataset already exists.")
# 解压数据集
import zipfile
with zipfile.ZipFile(save_path, 'r') as zip_ref:
zip_ref.extractall('./bare_soil_dataset')2. 解析 VOC 格式的标注文件
以下是一个解析 VOC 格式标注文件的函数:
import xml.etree.ElementTree as ET
def parse_voc_annotation(anno_file):
tree = ET.parse(anno_file)
root = tree.getroot()
annotations = []
for obj in root.findall('object'):
name = obj.find('name').text
bndbox = obj.find('bndbox')
xmin = int(bndbox.find('xmin').text)
ymin = int(bndbox.find('ymin').text)
xmax = int(bndbox.find('xmax').text)
ymax = int(bndbox.find('ymax').text)
annotations.append({
'class_name': name,
'bbox': [xmin, ymin, xmax, ymax]
})
return annotations3. 加载图像并显示标注框
我们可以使用 OpenCV 来加载图像,并使用 Matplotlib 来显示图像及其标注框:
import cv2
import matplotlib.pyplot as plt
def load_image(image_path):
return cv2.imread(image_path)
def display_image_with_annotations(image, annotations):
fig, ax = plt.subplots()
ax.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
for anno in annotations:
bbox = anno['bbox']
rect = plt.Rectangle((bbox[0], bbox[1]), bbox[2] - bbox[0], bbox[3] - bbox[1],
fill=False, edgecolor='red', linewidth=2)
ax.add_patch(rect)
plt.show()
# 示例用法
image_path = './bare_soil_dataset/images/image_0001.jpg'
anno_path = './bare_soil_dataset/annotations/image_0001.xml'
image = load_image(image_path)
annotations = parse_voc_annotation(anno_path)
display_image_with_annotations(image, annotations)4. 使用数据集进行训练
如果您打算使用这个数据集进行深度学习模型的训练,可以使用 PyTorch 或 TensorFlow 等框架。以下是一个简单的 PyTorch DataLoader 示例:
import torch
from torch.utils.data import Dataset, DataLoader
from PIL import Image
import numpy as np
class BareSoilDataset(Dataset):
def __init__(self, image_dir, anno_dir, transform=None):
self.image_dir = image_dir
self.anno_dir = anno_dir
self.transform = transform
self.images = os.listdir(image_dir)
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
img_name = self.images[idx]
image = Image.open(os.path.join(self.image_dir, img_name)).convert("RGB")
anno_name = img_name.replace('.jpg', '.xml')
anno_path = os.path.join(self.anno_dir, anno_name)
annotations = parse_voc_annotation(anno_path)
if self.transform:
image = self.transform(image)
return image, annotations
# 创建 DataLoader
dataset = BareSoilDataset(image_dir='./bare_soil_dataset/images',
anno_dir='./bare_soil_dataset/annotations')
dataloader = DataLoader(dataset, batch_size=4, shuffle=True, num_workers=2)
# 遍历数据
for images, annotations in dataloader:
# 在这里进行模型训练
pass这些代码示例涵盖了从下载数据集到解析标注文件,再到显示图像和创建数据加载器的基本步骤。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 裸土未覆盖检测数据集 1000张 裸土检测 带标注voc yolo

发表评论 取消回复