爱彼迎数据集下分析
资源下载
数据集不是完整的,目的是熟练使用Pandas
- 两个数据集
calendar.csvlistings.csv
免费下载:数据集
重要知识点会在中途以标题形式标记出
calendar.csv -数据分析
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
calendar = pd.read_csv('calendar.csv')
calendar.head()
calendar.shape
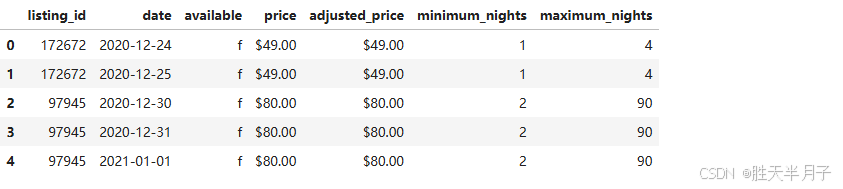
calendar = calendar[['listing_id','date','available','price']]
calendar.head()
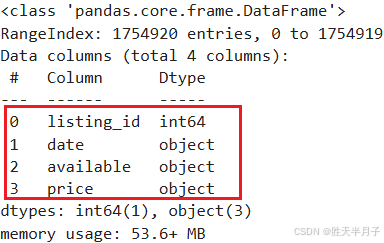
calendar.info()
--------------------------------------------------知识点------------------------------------------------------
object类型 – pandas
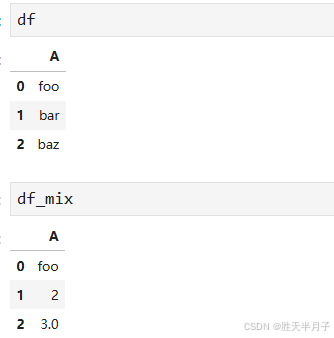
在Python的Pandas库中,object类型通常指的是包含任意Python对象的列。最常见的情况是,当列中包含的是字符串(str)类型数据时,Pandas会将其数据类型定义为object。但object类型也可以包含其他Python对象,如列表、字典、自定义对象等。
import pandas as pd
# 创建一个包含字符串的DataFrame
df = pd.DataFrame({'A': ['foo', 'bar', 'baz']})
print(df.dtypes) # 输出: A object
# 创建一个包含混合类型的DataFrame
df_mix = pd.DataFrame({'A': ['foo', 2, 3.0]})
print(df_mix.dtypes) # 输出: A object
A object
dtype: object
A object
dtype: object
calendar.date.min(),calendar.date.max()
(‘2020-12-24’, ‘2021-12-29’)
# 查看缺失值
calendar.isnull().sum()
listing_id 0
date 0
available 0
price 0
dtype: int64
# 删除缺失值
calendar = calendar.dropna()
calendar['date'] = pd.to_datetime(calendar['date'])
calendar.info()
----------------------------------------------------------知识点---------------------------------------------

datetime64 类型 – pandas
在Pandas中,datetime64 是一种用于表示日期和时间的数据类型,它是NumPy中datetime64类型的扩展。这种类型允许你存储日期和时间数据,并执行各种时间序列操作。
日期和时间操作:你可以使用 datetime64 类型执行各种日期和时间操作,如日期的加减、提取年、月、日等。
import pandas as pd
# 将字符串转换为 datetime64 类型
dates = pd.to_datetime(['2021-01-01', '2021-01-02', '2021-01-03'])
# 创建一个 DataFrame
df = pd.DataFrame({'date': dates})
# 提取年份和月份
df['year'] = df['date'].dt.year
df['month'] = df['date'].dt.month
print(df)
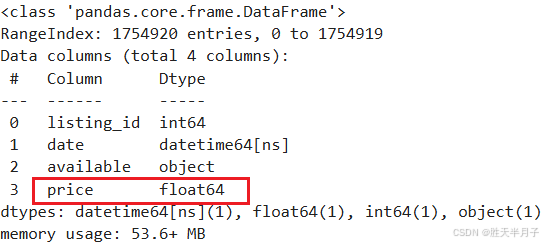
# price object 转换成浮点数类型
calendar['price'] = calendar['price'].str.replace('$','')
calendar['price'] = calendar['price'].str.replace(',','')
calendar['price'] = calendar['price'].astype(float)
calendar.info()
---------------------------------------------知识点-----------------------------------------------------------
float32 比float64节省内存?
是的,float32 类型比 float64 类型节省内存。
在计算机科学中,浮点数的存储是根据 IEEE 754 标准来的。根据这个标准:
float32(或称为 float):占用 4 字节(32位)内存,提供大约 7 位十进制数字的精度。
float64(或称为 double):占用 8 字节(64位)内存,提供大约 15 位十进制数字的精度。
由于 float32 只使用 4 字节,而 float64 使用 8 字节,因此在相同数量的数据项下,float32 会占用一半的内存空间。这种差异在处理大型数据集或在内存受限的环境中尤其重要。
然而,需要注意的是,虽然 float32 节省内存,但它的数值范围和精度都比 float64 要低。在需要较高数值精度的应用中,可能需要使用 float64 类型。在某些情况下,精度的损失可能会导致数值计算的误差累积,影响最终结果的准确性。
---------------------------------------------知识点-----------------------------------------------------------
astype方法
在Pandas中,.astype() 方法用于将数据类型强制转换为指定的类型。这个方法非常有用,因为它允许你改变Pandas对象(如 Series 或 DataFrame)中数据的类型。
import pandas as pd
# 创建一个包含字符串的 Series
s = pd.Series(['1', '2', '3'])
print(s)
# 将字符串转换为整数
s_int = s.astype(int)
print(s_int)
0 1
1 2
2 3
dtype: object
0 1
1 2
2 3
dtype: int32
import pandas as pd
# 创建一个包含字符串的 DataFrame
df = pd.DataFrame({
'A': ['1', '2', '3'],
'B': ['4.0', '5.1', '6.2']
})
# 将列 'A' 转换为整数,将列 'B' 转换为浮点数
df['A'] = df['A'].astype(int)
df['B'] = df['B'].astype(float)
print(df)

提取时间指标 月份统计
请确保 date 列确实是日期时间类型(datetime64[ns])。如果不是,您需要先将其转换为日期时间类型
calendar['date'].dt.strftime('%B')
0 December
1 December
2 December
3 December
4 January
…
1754915 December
1754916 December
1754917 December
1754918 December
1754919 December
Name: date, Length: 1754920, dtype: object
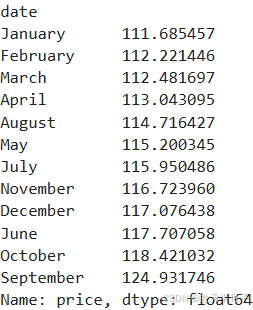
# 统计月份
mean_of_month = calendar.groupby(calendar['date'].dt.strftime('%B'))['price'].mean()
mean_of_month.sort_values()
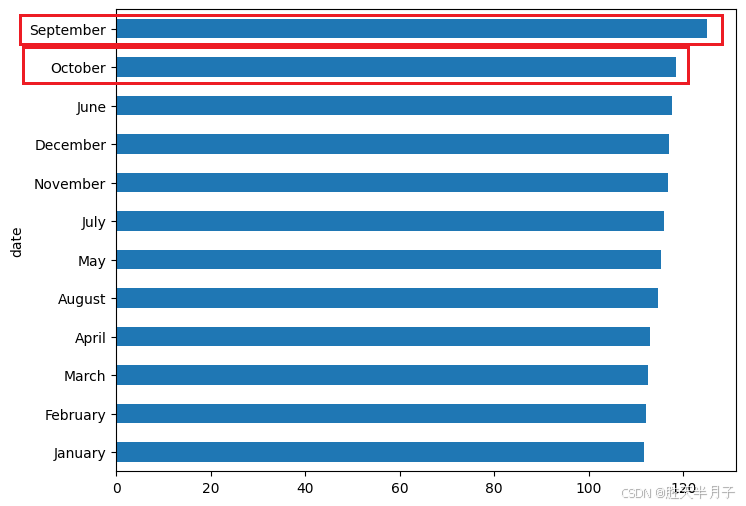
# kind='barh' 参数指定了绘制水平条形图
mean_of_month.sort_values().plot(kind='barh',figsize=(12,8))

星期统计
from datetime import date
calendar['dayofweek'] = calendar.date.dt.day_name() # day_name() 结合from datetime import date使用
calendar.head()
price_week=calendar.groupby(calendar['dayofweek'])['price'].mean()
price_week
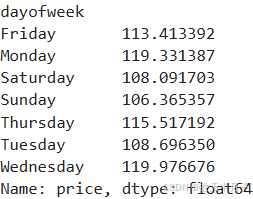
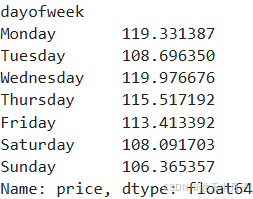
cats=['Monday','Tuesday','Wednesday','Thursday','Friday','Saturday','Sunday']
price_week=calendar.groupby(calendar['dayofweek'])['price'].mean().reindex(cats)
price_week #
查看listings.csv -数据分析
listings = pd.read_csv('listings.csv')
listings.head()
listings.shape
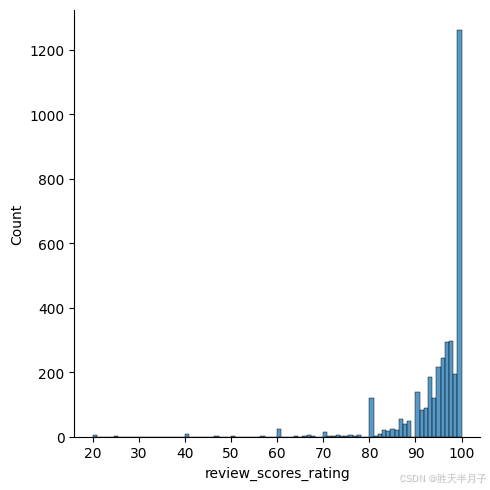
plt.figure(figsize=(20,6))
sns.displot(listings.review_scores_rating.dropna(), kind='hist')
# 去除图表周围的框架线
sns.despine()
# 显示图形
plt.show()
listings['price'] = listings['price'].str.replace('$','')
listings['price'] = listings['price'].str.replace(',','')
listings['price'] = listings['price'].astype(float)
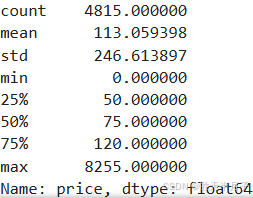
listings['price'].describe()
---------------------------------------------知识点-----------------------------------------------------------
pandas访问器
在Pandas中,访问器(Accessors)是附加到Pandas数据结构(如Series和DataFrame)上的一组方法,它们提供了对数据的额外操作。访问器允许开发者为Pandas对象添加自定义的属性和方法,而不需要修改Pandas的核心代码。一些常见的Pandas内置访问器包括:
.dt:用于Datetime类型的Series或DataFrame的列。它提供了一系列方法来操作日期和时间数据。
例如:df[‘date’].dt.year 提取日期中的年份。
.str:用于字符串操作,适用于object类型的Series或DataFrame的列。它提供了一系列字符串处理方法。
例如:df[‘column’].str.lower() 将字符串列转换为小写。
.cat:用于category类型的Series或DataFrame的列。它提供了一系列方法来操作分类数据。
例如:df[‘category’].cat.categories 查看分类列的类别。
.apply:不是访问器,但是一个强大的工具,可以对Series或DataFrame的行或列应用一个函数。
.agg:用于对DataFrame列进行聚合操作。
.eval 和 .query:.eval 允许在DataFrame上执行字符串表达式,而.query 允许使用字符串表达式来过滤数据。
.rolling、.expanding 和 .diff:这些用于时间序列数据,提供滚动窗口计算、扩展窗口计算和差分计算。
.idxmin 和 .idxmax:用于找到Series中最小值和最大值的索引。
.skew、.kurt、.mad:这些用于计算Series或DataFrame列的偏度、峰度和平均绝对偏差。
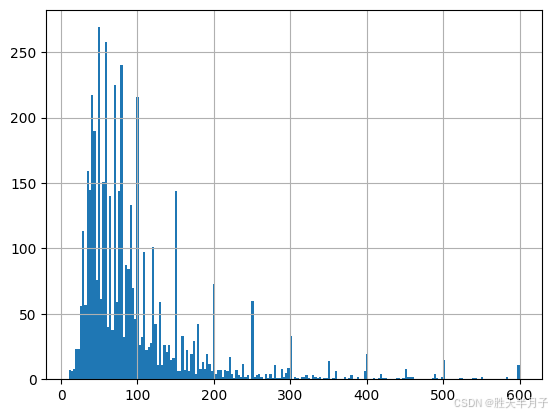
listings.loc[(listings['price']<=600) & (listings['price']>0)].price.hist(bins=200)
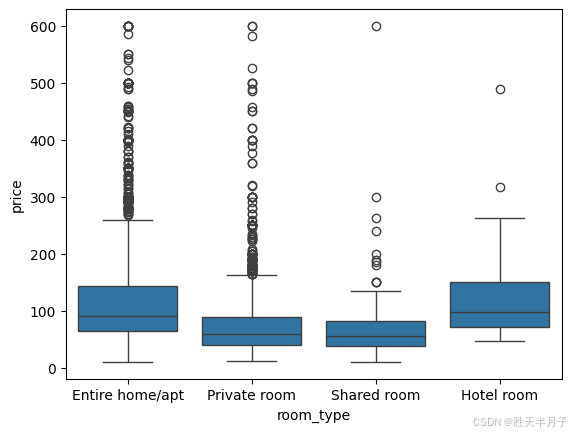
sns.boxplot(y='price',x='room_type',data=listings.loc[(listings['price']<=600) & (listings['price']>0)])
# 箱图的离群点
特别说明:箱盒图里面的极大值(上边缘值)并非最大值,极小值(下边缘值)也不是最小值。如果数据有存在离群点即异常值,他们超出最大或者最小观察值,此时将离群点以“圆点”形式进行展示。
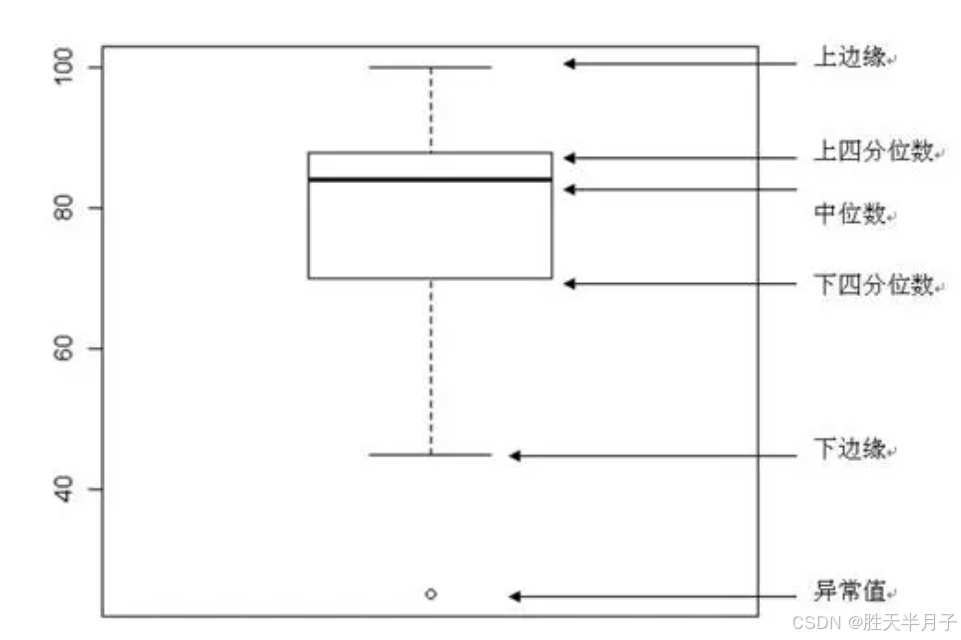
箱盒图的使用场景情况如下:
- 查看可能的异常值数据情况(比如在回归分析前查看是否有异常数据);
- 非参数检验时查看不同类别X时,Y的数据分布情况;
- 其它涉及查看数据分布或者异常值查看时。—知乎:SPSSAU
提取常见设施
listings.amenities[:5]

# 访问器 str
listings.amenities = listings.amenities.str.replace(r'^\[|\]$', '', regex=True).str.replace('"','')
listings.amenities[:5]

listings['amenities'].map(lambda amns : amns.split(','))[:5]
如何统计出每个设施种类的数量呢? 先认识value_counts()函数

---------------------------------------------知识点-----------------------------------------------------------
value_counts()函数
在Pandas中,value_counts() 函数是一个非常有用的方法,它用于计算Series或DataFrame列中每个唯一值出现的次数。这个方法对于数据分析和数据清洗非常有用,因为它可以帮助你快速了解数据的分布情况。
value_counts()方法还有一些有用的参数:
sort: 布尔值,默认为True,表示是否根据计数对结果进行排序。如果设置为False,则按照值在原数据中出现的顺序排序。
ascending: 布尔值,默认为False,表示排序是否为升序。仅在sort=True时有效。
dropna: 布尔值,默认为True,表示是否在计数中包含NaN值。如果设置为False,则NaN值也会被计数。
import pandas as pd
import numpy as np
# 假设 listings 是一个 DataFrame,并且有一个名为 'amenities' 的列
# 例如:
listings = pd.DataFrame({
'amenities': ['WiFi, TV, Kitchen', 'Heating, Parking', 'AC, Balcony', 'WiFi, Kitchen, Elevator']
})
# 输出结果
print(listings)
# 使用 apply 和 lambda 函数拆分字符串,然后使用 np.concatenate 合并列表
amenities_list = np.concatenate(listings['amenities'].map(lambda amns: amns.split(',')))
# 输出结果
print(amenities_list)
amenities
0 WiFi, TV, Kitchen
1 Heating, Parking
2 AC, Balcony
3 WiFi, Kitchen, Elevator
[‘WiFi’ ’ TV’ ’ Kitchen’ ‘Heating’ ’ Parking’ ‘AC’ ’ Balcony’ ‘WiFi’ ’ Kitchen’ ’ Elevator’]
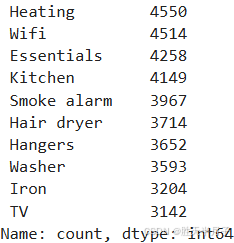
pd.Series(amenities_list).value_counts()

pd.Series(np.concatenate(listings['amenities'].map(lambda amns : amns.split(',')))).value_counts().head(10)
---------------------------------------------知识点-----------------------------------------------------------
concatenate函数
import numpy as np
# 定义两个数组
array1 = np.array([1, 2, 3])
array2 = np.array([4, 5, 6])
# 沿着第一个轴(默认)连接数组
result = np.concatenate((array1, array2))
print(result) # 输出: [1 2 3 4 5 6]
[1 2 3 4 5 6]
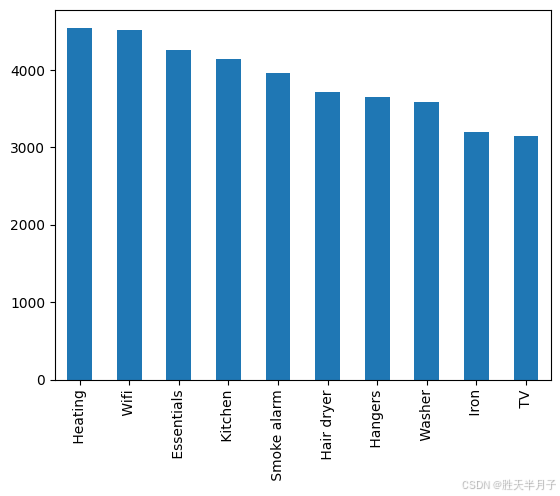
pd.Series(np.concatenate(listings['amenities'].map(lambda amns : amns.split(',')))).value_counts().head(10).plot(kind='bar')
房屋价格热度图分析
listings.bathrooms
0 NaN
1 NaN
2 NaN
3 NaN
4 NaN
…
4810 NaN
4811 NaN
4812 NaN
4813 NaN
4814 NaN
Name: bathrooms, Length: 4815, dtype: float64
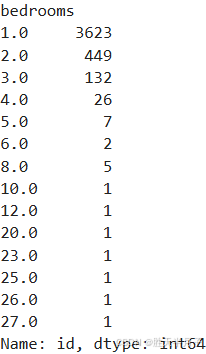
listings.bedrooms.value_counts()
bedrooms
1.0 3651
2.0 457
3.0 139
4.0 32
5.0 9
8.0 5
6.0 2
10.0 1
20.0 1
25.0 1
7.0 1
23.0 1
26.0 1
27.0 1
12.0 1
50.0 1
Name: count, dtype: int64
listings.loc[(listings['price']<=600) & (listings['price']>0)].groupby('bedrooms').count()['id']
加上reset_index
listings.loc[(listings['price']<=600) & (listings['price']>0)].groupby('bedrooms').count()['id'].reset_index()
由于bathrooms 是NaN,随机填充数据

# 定义随机整数的范围
low, high = 0.0, 8.0
# 生成随机整数填充列 'A'
listings['bathrooms'] = np.random.randint(lo`在这里插入代码片`w, high, size=listings.shape[0]).astype(float)
listings.bathrooms
0 5.0
1 1.0
2 0.0
3 7.0
4 4.0
…
4810 7.0
4811 7.0
4812 6.0
4813 5.0
4814 3.0
Name: bathrooms, Length: 4815, dtype: float64
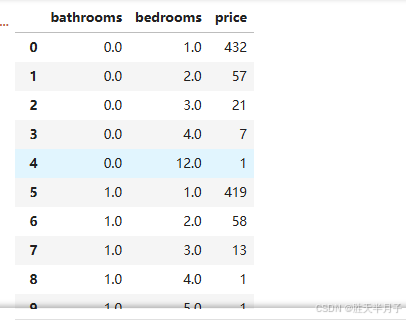
listings.loc[(listings['price']<=600) & (listings['price']>0)].groupby(['bathrooms','bedrooms']).count()['price'].reset_index()
----------------------------------------------------知识点---------------------------------------------------------
pivot()透视表 和 热力图heatmap
在Pandas中,pivot 函数是一种将长格式数据重塑为宽格式数据的有用工具。pivot 函数允许你指定一个或多个列作为新的行标签(索引),一个列作为列标签,以及一个列作为数据值,从而创建一个透视表。
DataFrame.pivot(index=None, columns=None, values=None)
- index:用于指定作为新DataFrame索引。
- columns:用于指定作为新DataFrame行标题。
- values:用于指定填充到新DataFrame中的数值。
pivot_df = listings.loc[(listings['price']<=600) & (listings['price']>0)].groupby(['bathrooms','bedrooms']).count()['price'].reset_index().pivot_table(index='bathrooms', columns='bedrooms', values='price')
pivot_df
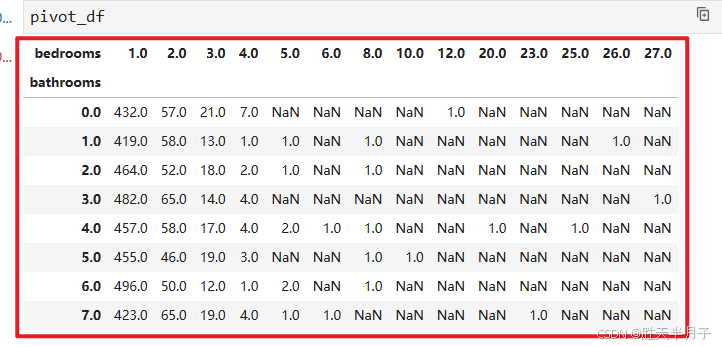
# 由于bathrooms的 数值是伪造的 因此 热力图不可信
sns.heatmap (pivot_df,cmap='Oranges',annot=True,linewidths=0.5,fmt='.0f')
以下是heatmap()函数的一些常用参数:
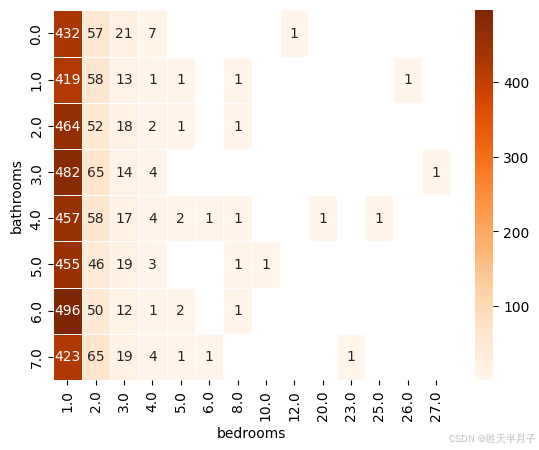
data:要绘制的数据,通常是Pandas的DataFrame。
cmap:颜色映射表,用于定义热图中使用的颜色。‘Oranges’是一种从黄色到深橙色的颜色映射。
annot:布尔值,表示是否在每个单元格中显示数据值。设置为True可以在热图的每个单元格中显示数值。
linewidths:设置热图中单元格之间的线宽。
fmt:字符串格式,定义如何在热图中格式化注释。’.0f’表示显示为没有小数点的浮点数。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Pandas | 使用pandas对爱彼迎数据集分析,加深对数据的理解和函数使用

发表评论 取消回复