引言
RAMS数据集(RAMS:Richly Annotated Multilingual Schema-guided Event Structure)由约翰斯·霍普金斯大学于2020年发布,是一个以新闻为基础的事件抽取数据集。它标注了9,124个事件,涵盖了139种不同的事件类型和65种元素角色类型。事件类型涉及多个领域,如:
- 生命事件(life)
- 冲突事件(conflict)
- 灾难事件(disaster)
- 司法事件(justice)
- 联络事件(contact)
- 政府事件(government)
而元素角色类型包括如:
- 地点(place)
- 参与者(participant)
- 目的地(destination)
- 起源(origin)
- 受害者(victim)
- 被告人(defendant)
这个数据集非常适合用于事件抽取、自然语言处理任务,特别是对事件结构、事件角色的识别和分类。
一、特点(features)
- 事件类型多样化:涵盖多个领域,增强了事件抽取任务的广泛性和复杂性。
- 角色标注详细:为每个事件详细标注了不同的角色,为构建事件图、进行因果推理等任务提供了丰富的上下文信息。
- 结构化标注:不仅仅提供文本,还为每个事件及其参与者标注了详细的语义信息,使其适用于高层次的文本分析。
二、下载(download)
- 可以通过访问官方下载网站进行最新和历史数据集的下载。
- 也可以通过访问我的主页提供的数据集来进行下载。
三、数据集(database)
3.1 数据
数据被分成 train/dev/test 三个文件,

每个数据文件的每一行包含一个 json 字符串,
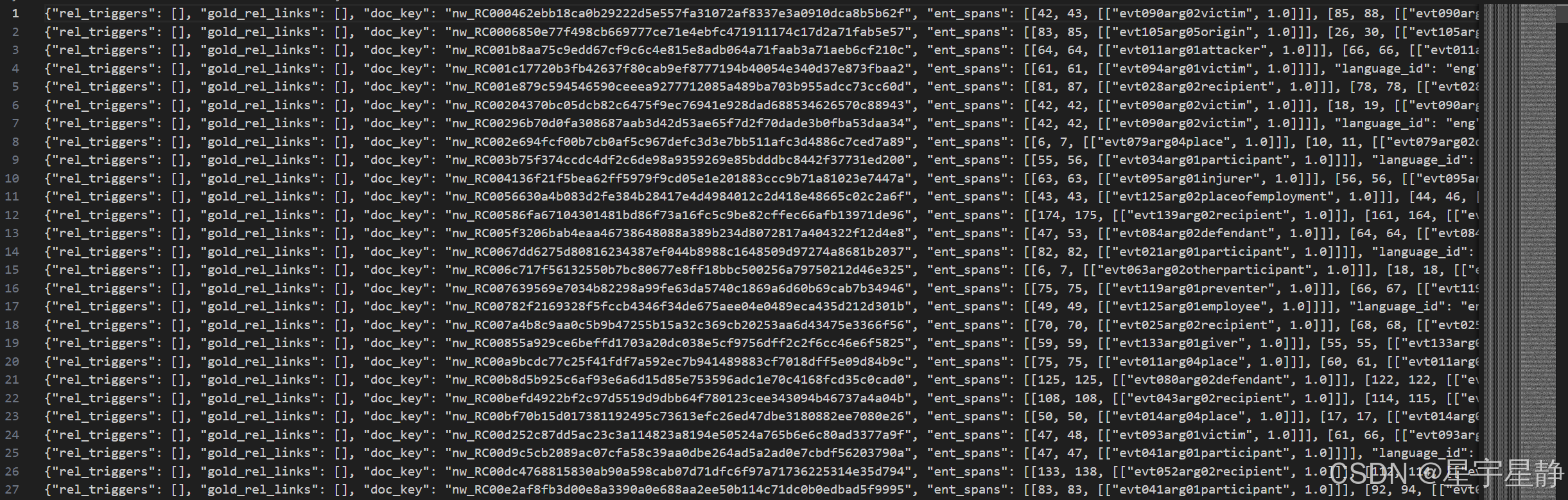
每个 json 包含:
ent_spans:开始和结束(包含)索引以及事件/参数/角色字符串。evt_triggers:开始和结束(包括)索引以及事件类型字符串。sentences:文档文本gold_evt_links:遵循上述格式的三元组(事件、论点、角色)source_url:文本来源split:它属于哪个数据分割doc_key:它对应于哪个单独的文件(

所有其他字段都是多余的,以允许 RAMS 的未来迭代。
格式化之后的一条数据(train.jsonlines的第1行)如下展示:
{
"rel_triggers": [],
"gold_rel_links": [],
"doc_key": "nw_RC000462ebb18ca0b29222d5e557fa31072af8337e3a0910dca8b5b62f",
"ent_spans": [
[
42,
43,
[
[
"evt090arg02victim",
1.0
]
]
],
[
85,
88,
[
[
"evt090arg01killer",
1.0
]
]
],
[
26,
26,
[
[
"evt090arg04place",
1.0
]
]
]
],
"language_id": "eng",
"source_url": "https://www.washingtonpost.com/news/powerpost/paloma/daily-202/2016/06/17/daily-202-more-republicans-ditch-trump-conclude-he-cannot-win/5763a1e0981b92a22d0f8a36/",
"evt_triggers": [
[
69,
69,
[
[
"life.die.deathcausedbyviolentevents",
1.0
]
]
]
],
"split": "train",
"sentences": [
[
"Transportation",
"officials",
"are",
"urging",
"carpool",
"and",
"teleworking",
"as",
"options",
"to",
"combat",
"an",
"expected",
"flood",
"of",
"drivers",
"on",
"the",
"road",
"."
],
[
"(",
"Paul",
"Duggan",
")"
],
[
"--",
"A",
"Baltimore",
"prosecutor",
"accused",
"a",
"police",
"detective",
"of",
"\u201c",
"sabotaging",
"\u201d",
"investigations",
"related",
"to",
"the",
"death",
"of",
"Freddie",
"Gray",
",",
"accusing",
"him",
"of",
"fabricating",
"notes",
"to",
"suggest",
"that",
"the",
"state",
"\u2019s",
"medical",
"examiner",
"believed",
"the",
"manner",
"of",
"death",
"was",
"an",
"accident",
"rather",
"than",
"a",
"homicide",
"."
],
[
"The",
"heated",
"exchange",
"came",
"in",
"the",
"chaotic",
"sixth",
"day",
"of",
"the",
"trial",
"of",
"Baltimore",
"Officer",
"Caesar",
"Goodson",
"Jr.",
",",
"who",
"drove",
"the",
"police",
"van",
"in",
"which",
"Gray",
"suffered",
"a",
"fatal",
"spine",
"injury",
"in",
"2015",
"."
],
[
"(",
"Derek",
"Hawkins",
"and",
"Lynh",
"Bui",
")"
]
],
"gold_evt_links": [
[
[
69,
69
],
[
85,
88
],
"evt090arg01killer"
],
[
[
69,
69
],
[
42,
43
],
"evt090arg02victim"
],
[
[
69,
69
],
[
26,
26
],
"evt090arg04place"
]
]
}1. sentences:
- 文档内容被分为多个句子:
- 句子1:"Transportation officials are urging carpool and teleworking as options to combat an expected flood of drivers on the road."
- 句子2:"(Paul Duggan)"
- 句子3:"A Baltimore prosecutor accused a police detective of ‘sabotaging’ investigations related to the death of Freddie Gray."
- 句子4:"The heated exchange came in the chaotic sixth day of the trial of Baltimore Officer Caesar Goodson Jr."
2. evt_triggers(事件触发器):
[69, 69]对应的词是句子3中的 "homicide",标注事件类型为 "life.die.deathcausedbyviolentevents"(与暴力事件导致的死亡相关)。
3. ent_spans(实体标注,开始和结束索引,以及事件角色):
[42, 43]对应的词是句子3中的 "Freddie Gray",角色为 "victim"(受害者)。[85, 88]对应的词是句子4中的 "Caesar Goodson Jr.",角色为 "killer"(凶手)。[26, 26]对应的词是句子3中的 "Baltimore",角色为 "place"(地点)。
4. gold_evt_links(事件-论点-角色三元组):
- 第一个三元组:触发词 "homicide",论点是 "Caesar Goodson Jr.",角色是 "killer"。
- 第二个三元组:触发词 "homicide",论点是 "Freddie Gray",角色是 "victim"。
- 第三个三元组:触发词 "homicide",论点是 "Baltimore",角色是 "place"。
5. source_url:
6. split:
- 样本属于 训练集(train)。
7. doc_key:
- 对应的文档ID为 "nw_RC000462ebb18ca0b29222d5e557fa31072af8337e3a0910dca8b5b62f",该ID用于唯一标识文档。
四、数据处理
import json
def load_data(file_path):
data = []
with open(file_path, 'r') as f:
for line in f:
data.append(json.loads(line))
return data
def save_to_json(data, file_path):
with open(file_path, 'w') as f:
json.dump(data, f, indent=4)
def extract_event_data(entry):
sentences = [" ".join(s) for s in entry["sentences"]]
text = [item for sublist in entry["sentences"] for item in sublist]
# text = entry["sentences"]
# text = " ".join(sentences)
# 处理实体
ent_spans = [(span[0], span[1], span[2][0][0]) for span in entry["ent_spans"]]
# 处理事件触发词
evt_triggers = [(trigger[0], trigger[1], trigger[2][0][0]) for trigger in entry["evt_triggers"]]
# 处理事件-论点链接
evt_links = entry["gold_evt_links"]
return text, ent_spans, evt_triggers, evt_links
def prepare_training_data(entries):
dataset = []
for entry in entries:
text, ent_spans, evt_triggers, evt_links = extract_event_data(entry)
# 生成训练样本
dataset.append({
'text': text,
'entities': ent_spans,
'triggers': evt_triggers,
'links': evt_links
})
return dataset
if __name__ == '__main__':
train_data = load_data("./train.jsonlines")
training_dataset = prepare_training_data(train_data)
save_to_json(training_dataset, 'train.json')
print(training_dataset[0])
4.1 加载并解析数据
首先,加载JSON格式的数据文件,并解析其中的字段。
import json
def load_data(file_path):
data = []
with open(file_path, 'r') as f:
for line in f:
data.append(json.loads(line))
return data
train_data = load_data('train.json')
4.2 数据预处理
将文档中的句子、事件触发词、角色和实体进行标注与转换,以便用于事件抽取模型。我们可以提取句子、事件触发词及角色信息。
def extract_event_data(entry):
sentences = [" ".join(s) for s in entry["sentences"]]
text = " ".join(sentences)
# 处理实体
ent_spans = [(span[0], span[1], span[2][0][0]) for span in entry["ent_spans"]]
# 处理事件触发词
evt_triggers = [(trigger[0], trigger[1], trigger[2][0][0]) for trigger in entry["evt_triggers"]]
# 处理事件-论点链接
evt_links = entry["gold_evt_links"]
return text, ent_spans, evt_triggers, evt_links
# 示例提取
for entry in train_data:
text, ent_spans, evt_triggers, evt_links = extract_event_data(entry)
print(f"文本: {text}")
print(f"实体: {ent_spans}")
print(f"事件触发词: {evt_triggers}")
print(f"事件-论点链接: {evt_links}")
4.3 生成模型输入
为了进行事件抽取,常见的输入是文本与相应的事件触发器和角色。我们可以构建一个数据集,将文本标注为序列标注任务或使用分类任务标注事件触发词和论点。
def prepare_training_data(entries):
dataset = []
for entry in entries:
text, ent_spans, evt_triggers, evt_links = extract_event_data(entry)
# 生成训练样本
dataset.append({
'text': text,
'entities': ent_spans,
'triggers': evt_triggers,
'links': evt_links
})
return dataset
training_dataset = prepare_training_data(train_data)
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 信息抽取数据集处理——RAMS

发表评论 取消回复