目录
引言
在众多排序算法的大家庭中,计数排序以其独特的原理和高效的性能占据着一席之地。它不像一些常见的比较排序算法那样通过反复比较和交换元素来实现排序,而是采用了一种基于计数的策略。这种独特的方式使得计数排序在某些特定场景下表现出卓越的效率,成为了算法领域中一个值得深入研究的对象。
本文将对计数排序进行全面而深入的解析,涵盖其原理、实现细节、性能特点以及广泛的应用领域
计数排序的原理
⭐核心概念
计数排序的基本思想是利用一个额外的数组来统计待排序数组中每个元素出现的次数,然后根据这些统计信息来确定每个元素在排序后的位置。它假设待排序的元素都是非负整数,并且这些整数的取值范围是已知的。通过统计每个整数在待排序数组中出现的次数,我们可以创建一个计数数组,其中计数数组的下标对应待排序元素的值,而数组中的值则表示该元素出现的次数。
⭐工作流程
1.确定计数范围
- 首先,需要找出待排序数组中的最大值
max和最小值min。计数数组的大小count_array_size将被设置为max - min + 1,以确保能够容纳待排序数组中所有可能出现的元素的计数信息。
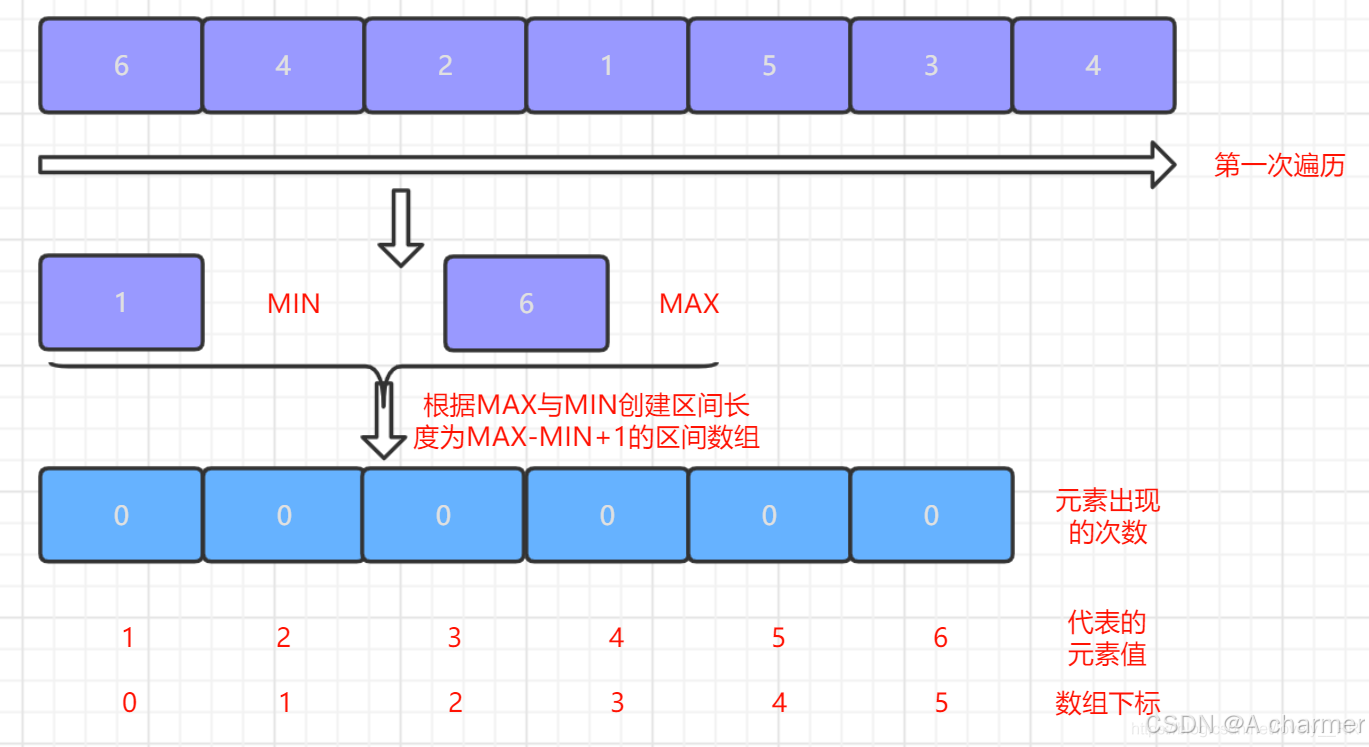
2.统计元素出现次数
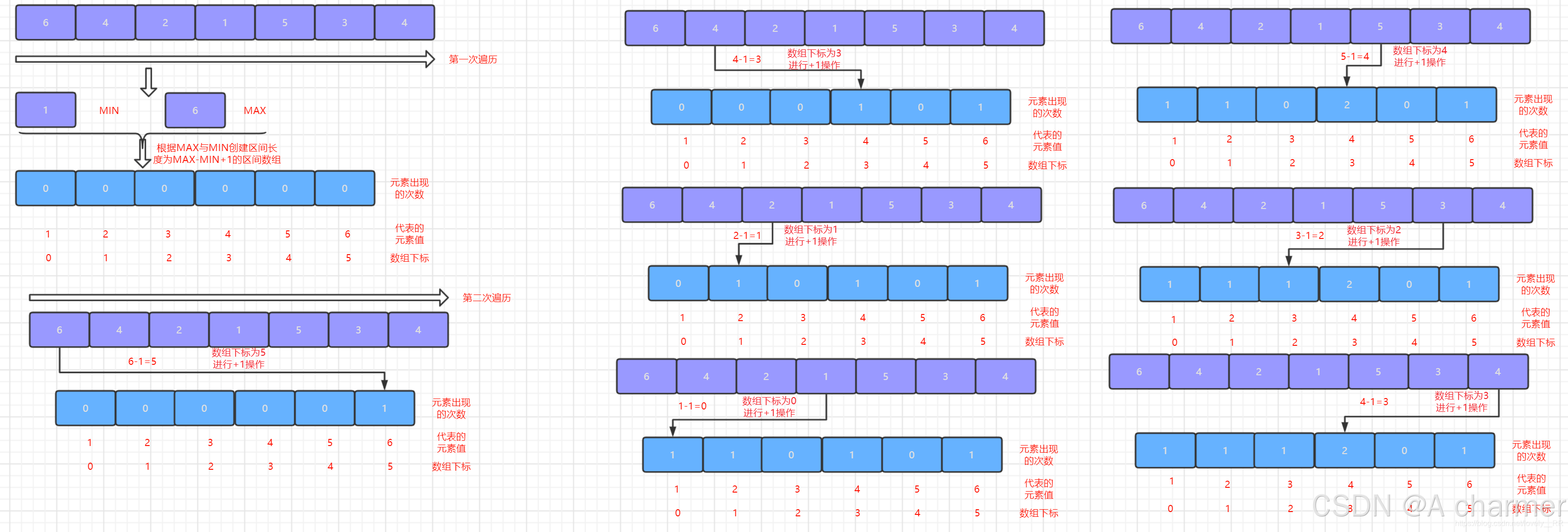
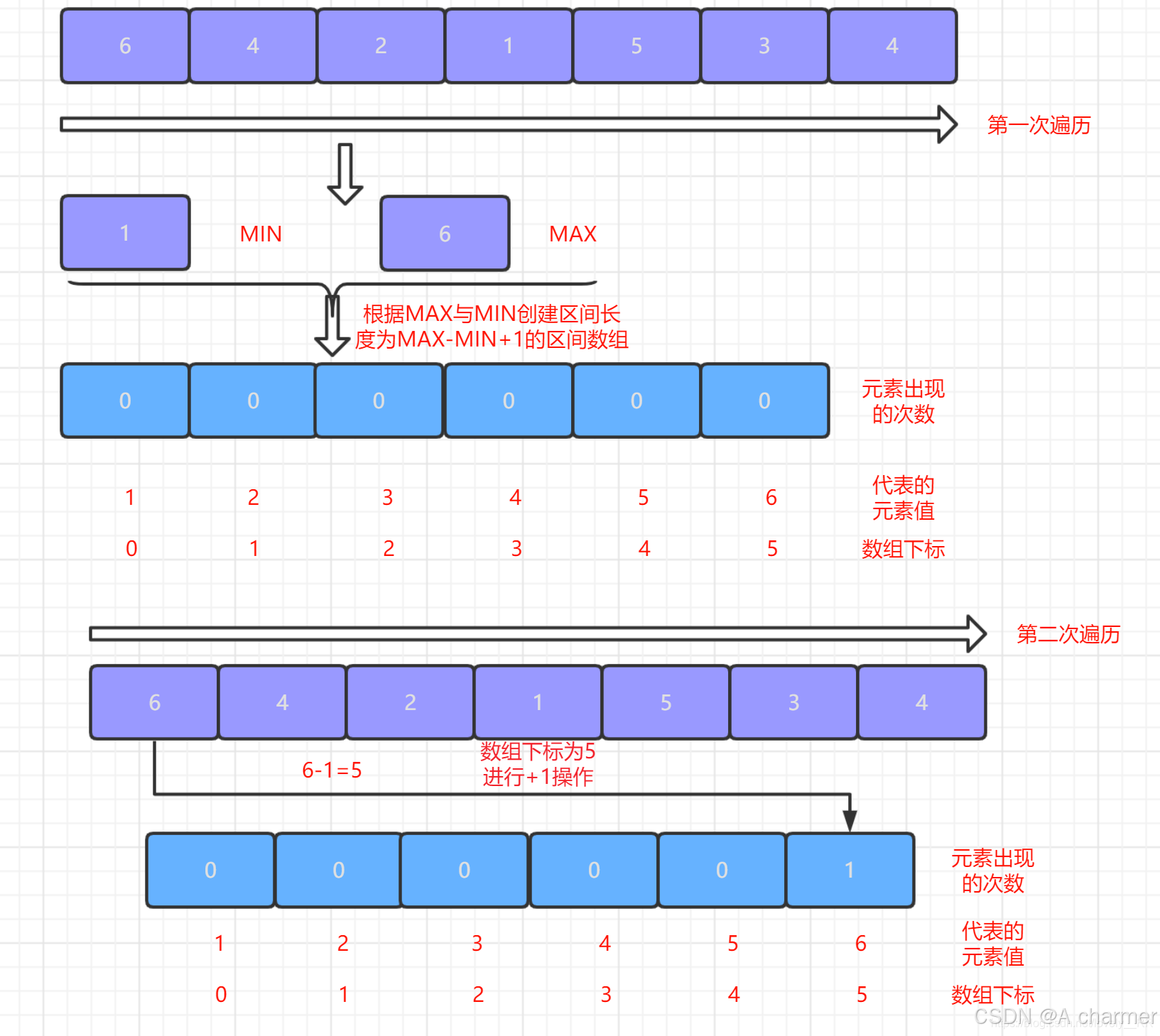
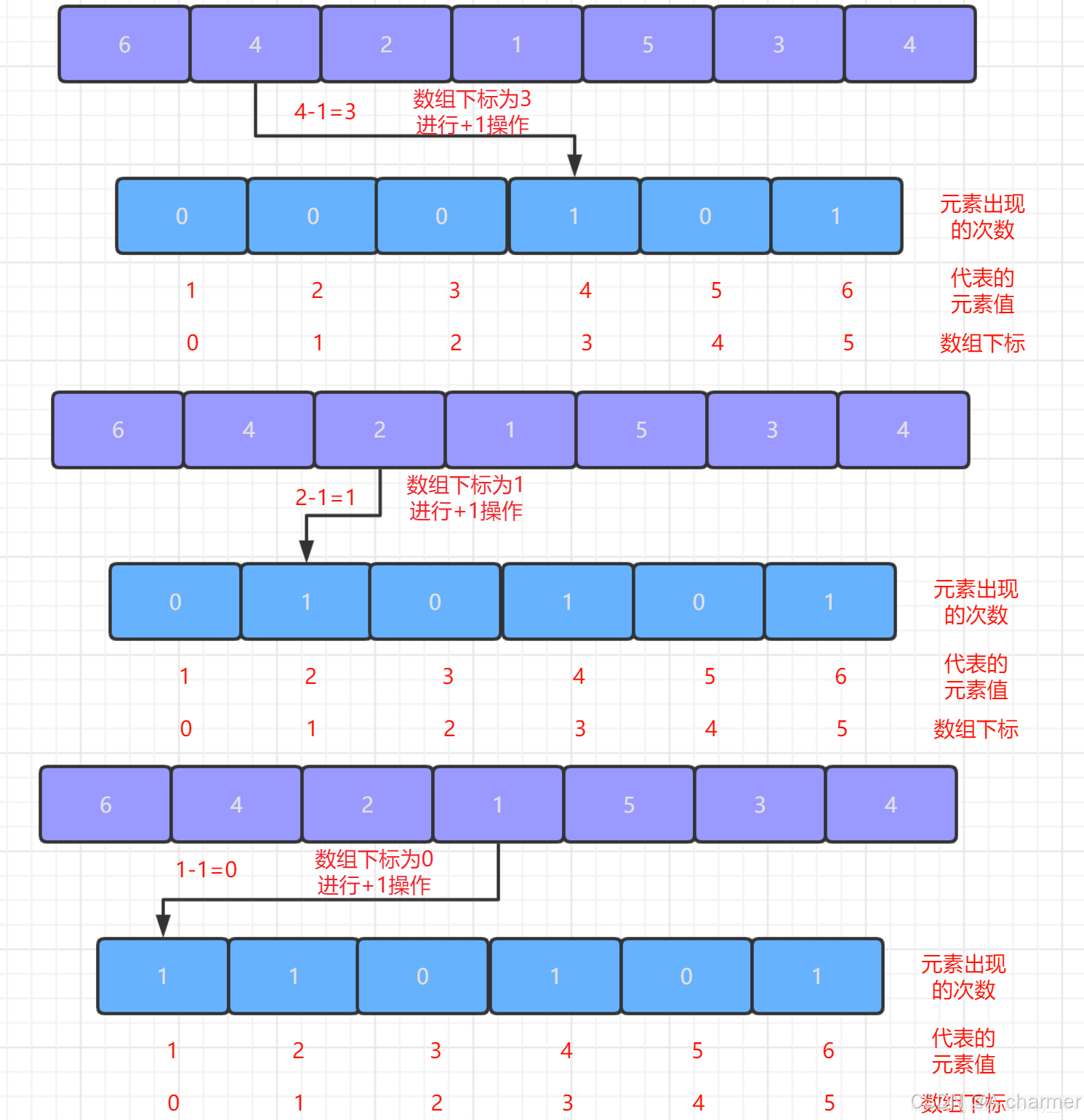
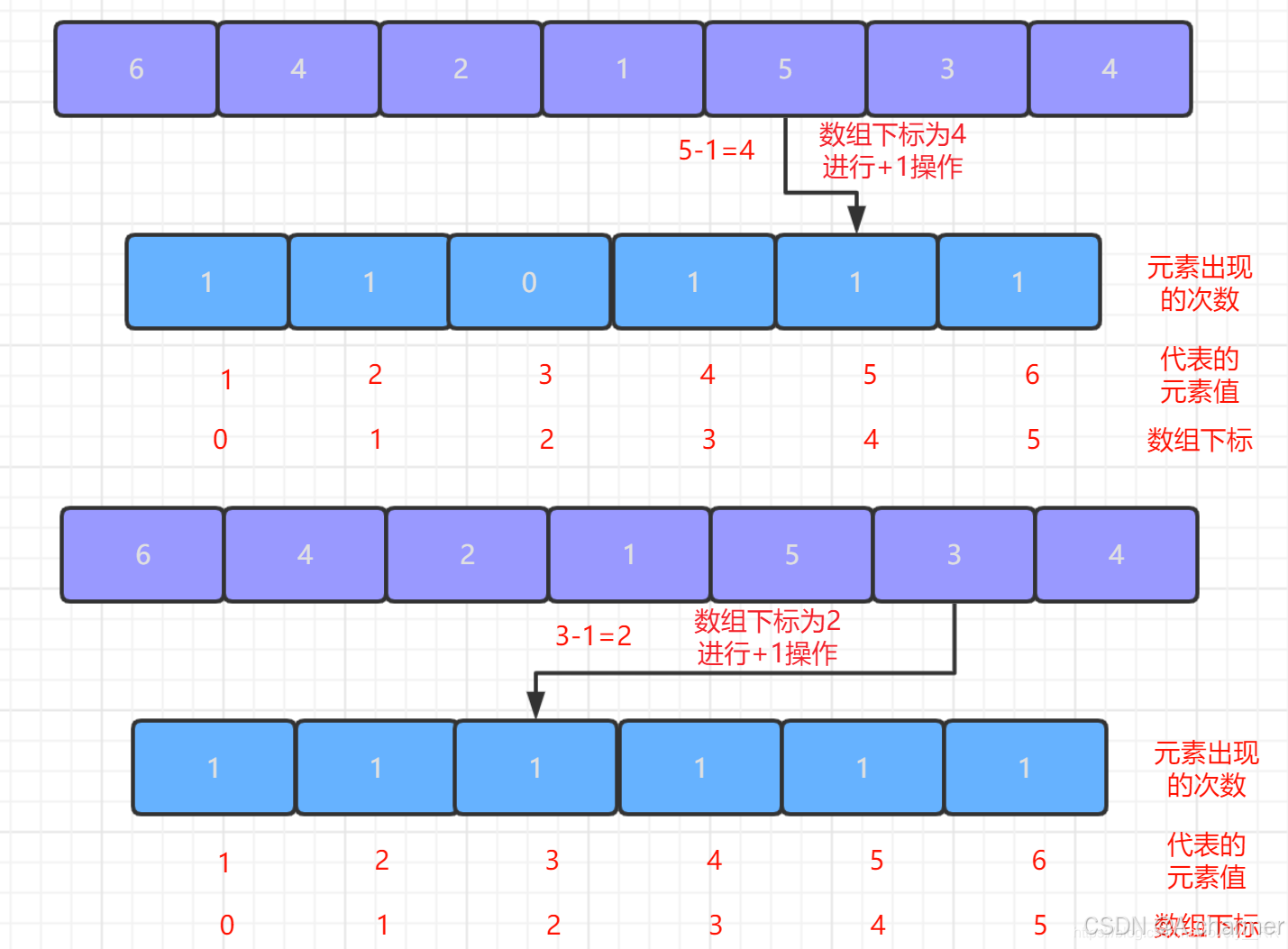
- 遍历待排序数组,对于每个元素
num,将计数数组中对应下标num - min的值加 1。这一步操作完成后,计数数组中的每个位置就存储了相应元素在待排序数组中出现的次数。
图解如下,详细过程请看下文 :
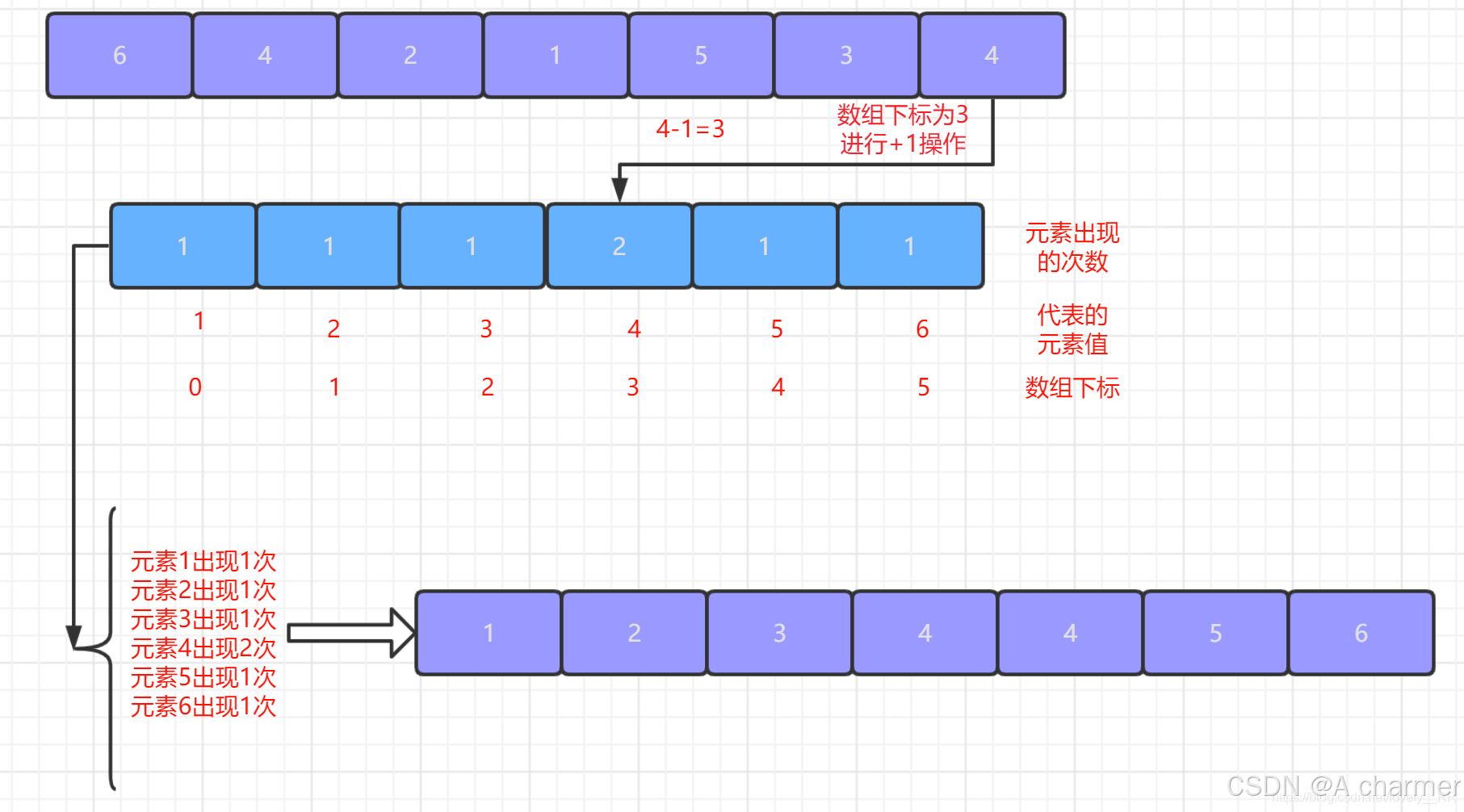
3.计算累计计数
- 对计数数组进行修改,使其每个位置存储的是小于等于当前位置索引的元素的总数。具体来说,从计数数组的第二个元素开始,将当前元素的值与前一个元素的值相加,得到累计计数。这个累计计数将用于确定每个元素在排序后的数组中的最终位置。
4.放置元素到正确位置
- 创建一个与待排序数组大小相同的结果数组
result_array。从待排序数组的末尾开始遍历,对于每个元素num,根据其在计数数组中的累计计数,将其放置到结果数组的正确位置。放置完成后,将计数数组中对应位置的值减 1,以确保下一个相同元素能够放置到正确的位置。
动图如下:
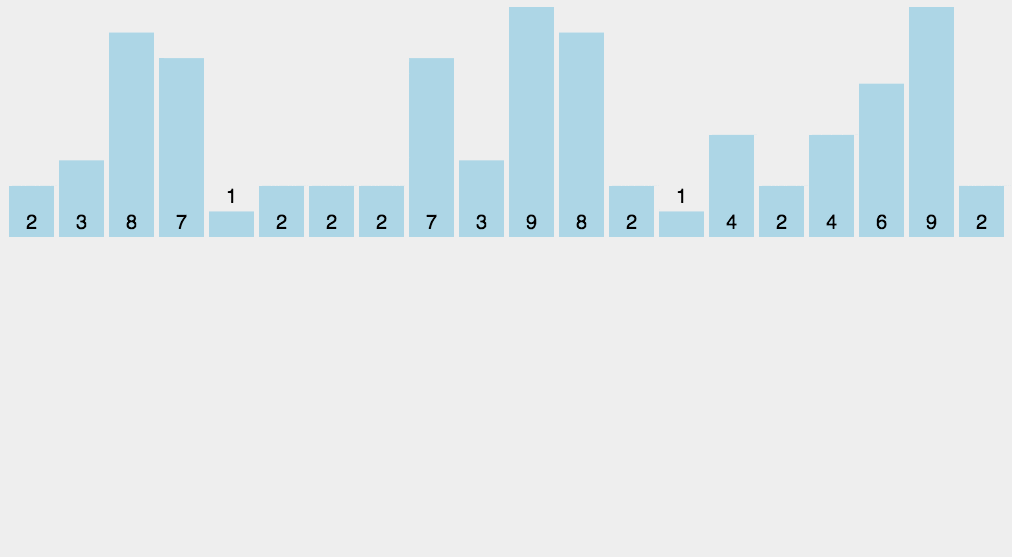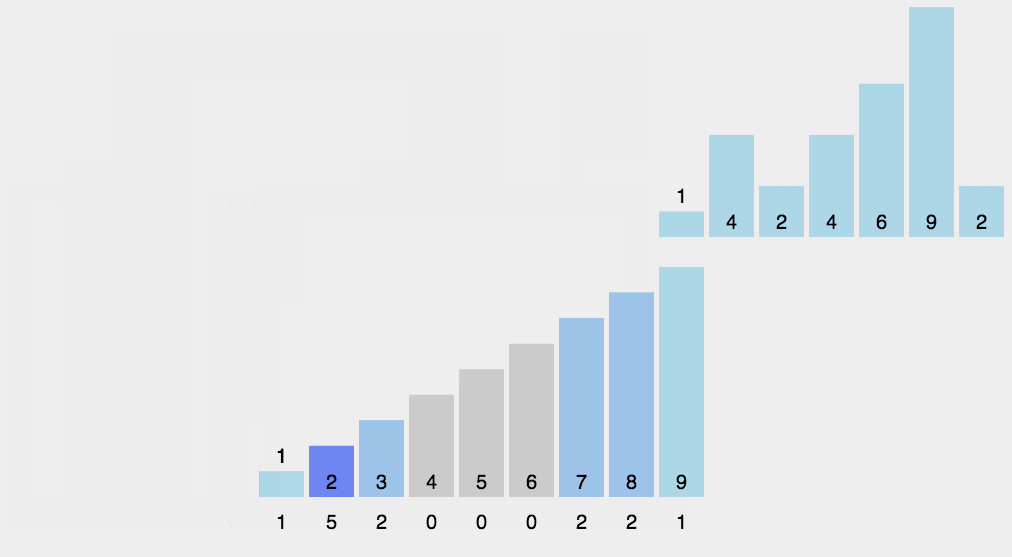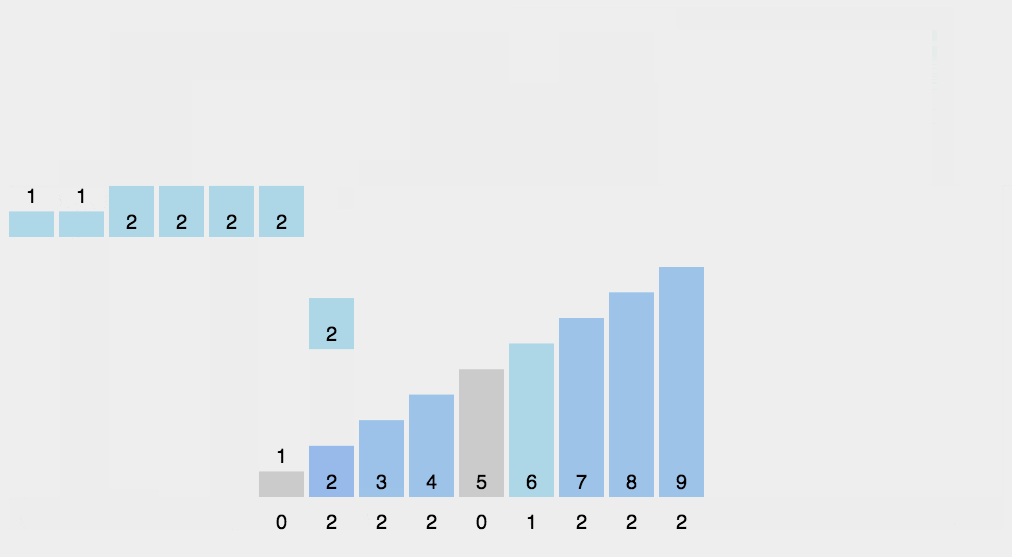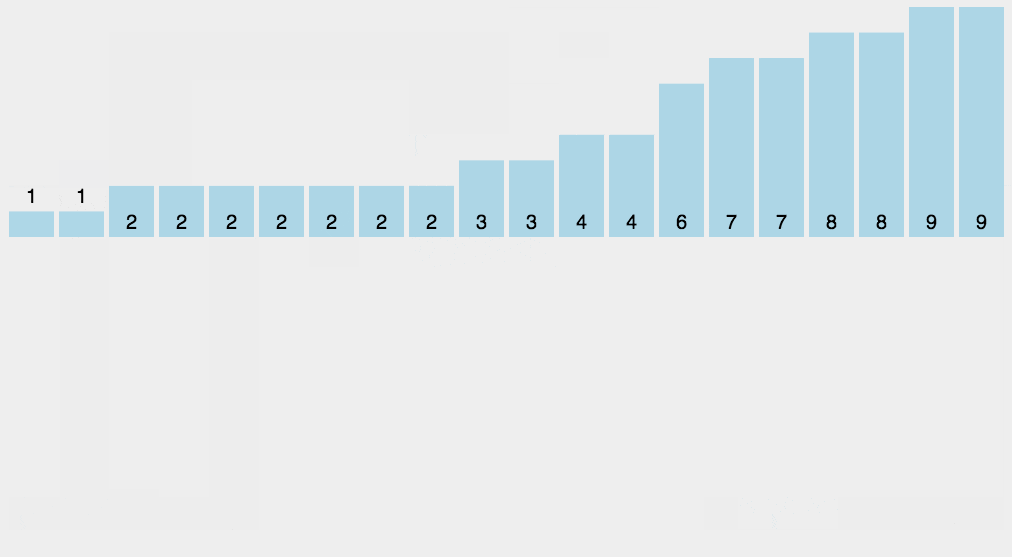
计数排序的实现
⭐代码示例(以 C++ 为例)
// 计数排序函数
std::vector<int> countingSort(std::vector<int> arr) {
// 找出待排序数组中的最大值和最小值
int max_value = arr[0];
int min_value = arr[0];
for (int num : arr) {
if (num > max_value) {
max_value = num;
}
if (num < min_value) {
min_value = num;
}
}
// 计算计数数组的大小
int count_array_size = max_value - min_value + 1;
// 创建计数数组并初始化为 0
std::vector<int> count_array(count_array_size, 0);
// 统计元素出现次数
for (int num : arr) {
count_array[num - min_value]++;
}
// 计算累计计数
for (int i = 1; i < count_array_size; i++) {
count_array[i] += count_array[i - 1];
}
// 创建结果数组
std::vector<int> result_array(arr.size());
// 放置元素到正确位置
for (int i = arr.size() - 1; i >= 0; i--) {
// 根据计数数组确定元素在结果数组中的位置
result_array[count_array[arr[i] - min_value] - 1] = arr[i];
// 更新计数数组,以便下一个相同元素能放置到正确位置
count_array[arr[i] - min_value]--;
}
return result_array;
}

⭐时间复杂度分析
- 时间复杂度:计数排序的时间复杂度为
,其中
是待排序数组的长度,
是待排序数据的取值范围。在上述代码中,统计元素出现次数的循环需要遍历待排序数组,时间复杂度为
。计算累计计数的循环需要遍历计数数组,时间复杂度为
。放置元素到正确位置的循环也需要遍历待排序数组,时间复杂度为
- 空间复杂度:计数排序的空间复杂度为
⭐稳定性分析
计数排序是一种稳定的排序算法。这是因为在放置元素到正确位置的步骤中,我们是从待排序数组的末尾开始遍历的。当遇到相同的元素时,会将它们依次放置到结果数组中相对靠前的位置,从而保证了相等元素在排序后的相对顺序与它们在原始数组中的顺序相同。这种稳定性在一些特定的应用场景中非常重要,例如在需要对具有相同值的元素进行后续处理时,稳定的排序算法可以确保结果的准确性和可预测性。
计数排序的性能特点
⭐优点
- 高效性:在待排序数据的取值范围相对较小且已知的情况下,计数排序的时间复杂度可以接近线性,这使得它在处理大量数据时非常高效。相比于一些复杂的比较排序算法,如快速排序和归并排序,在特定条件下计数排序能够更快地完成排序任务。
- 稳定性:如前所述,计数排序是稳定的排序算法。这一特性使得它在处理需要保持元素相对顺序的场景时非常有用,例如在对多个具有相同关键字的记录进行排序时,稳定的排序算法可以确保这些记录在排序后的相对顺序不变。
- 简单易懂:计数排序的原理相对简单,其实现过程也不复杂,不需要进行复杂的比较和交换操作。这使得它在教学和一些简单的排序任务中很受欢迎,容易被初学者理解和掌握。
⭐缺点
- 取值范围限制:计数排序依赖于待排序元素的取值范围。如果取值范围过大,将会导致计数数组的大小变得非常大,从而占用大量的内存空间。例如,如果要对一个包含大量整数的数组进行排序,而这些整数的取值范围非常广泛,那么创建的计数数组可能会消耗大量的内存,甚至可能超出计算机的内存限制。
- 元素类型限制:计数排序通常适用于非负整数或可以映射到非负整数范围内的元素。对于其他类型的元素,如字符串、浮点数等,需要进行额外的处理才能使用计数排序。这种额外的处理可能会增加算法的复杂性和时间开销。
- 不适用于动态数据:计数排序在处理静态数据时表现出色,但对于动态数据的添加和删除操作,它并不是一个很好的选择。因为每次对数据进行修改后,都需要重新计算计数数组,这将会带来较大的时间开销。如果需要频繁地对数据进行动态修改和排序,其他更适合动态操作的排序算法,如二叉搜索树或堆排序,可能会更加合适。
计数排序的应用场景
⭐整数排序
当需要对大量整数进行排序,且这些整数的取值范围相对较小且已知时,计数排序是一个非常理想的选择。例如,在对学生的考试成绩进行排序(成绩通常是在一个有限的范围内,如 0 到 100 分),或者对一些简单的计数数据进行排序时,计数排序可以快速地完成任务,并且具有高效的性能。
⭐基数排序的辅助算法
基数排序是一种用于对多位数进行排序的算法,它通常需要多次使用稳定的排序算法对每个数位进行排序。计数排序由于其稳定性和高效性,常被用作基数排序中对单个数位进行排序的辅助算法。通过对每个数位上的数字进行计数排序,可以逐步将多位数按照正确的顺序排列。
⭐数据统计与分析
在一些数据统计和分析任务中,我们可能需要先对数据进行排序,然后进行进一步的处理。如果数据满足计数排序的适用条件,使用计数排序可以快速地对数据进行初步整理,为后续的分析工作提供便利。例如,在统计一个时间段内不同事件发生的次数,并按照事件发生的顺序进行排序时,计数排序可以快速地完成排序任务,使得后续的统计分析更加高效。
结论
计数排序是一种独特而高效的排序算法,它在特定的场景下展现出了卓越的性能。通过基于计数的原理,它能够在较短的时间内对数据进行排序,并且具有稳定性的优点。然而,它也存在着一些局限性,如取值范围限制、元素类型限制和不适用于动态数据等。在实际应用中,我们需要根据数据的特点和具体的需求来选择合适的排序算法。当数据满足计数排序的适用条件时,它无疑是一个非常好的选择,可以为我们提供快速、准确的排序解决方案,提高程序的运行效率和性能。
同时,对计数排序的深入理解也有助于我们更好地理解算法设计的思想和方法,为进一步探索和研究其他相关算法奠定基础。
感谢你看到最后,点个赞再走吧!我的主页【A Charmer】
为了更好地了解读者对计数排序的理解和兴趣,欢迎参与以下投票:
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 深度解析计数排序:原理、特性与应用

发表评论 取消回复