Comment: Accepted to CVPR 2023
Task Residual for Tuning Vision-Language Models(用于视觉语言模型调优的任务残差)
摘要
大规模视觉语言模型在大规模数据上预训练学到了广泛的视觉表征和视觉概念。原则上,当VLM视觉语言模型被迁移到数据有限的下游任务时,应当适当地继承原学习到的知识架构。现有的高效的迁移学习方法ETL包含两个分支(PT提示调优和AT适配器调优)要么损害的先验知识,要么过度偏向于先验知识,其中提示调优丢弃了预训练的基于文本的分类器,并构建了一个新的分类器,而适配器调优完全依赖于预训练的特征。
为了解决这个问题,本文为VLM提出一种高效的调优方法,叫做任务残差调优(Task Residual Tuning, TaskRes),该方法直接在基于文本的分类器上进行执行,并且将预训练模型的先验知识和目标任务的新知识进行解耦。具体来说,TaskRes保持从VLM中继承的原始分类器冻结,然后利用一组与先验无关的参数作为原始参数的残差从而为目标任务获得一个新的分类器,因此能够保证先验知识的可靠稳定性,还能灵活地探索任务特定知识。
所提出的TaskRes简单而有效,在11个基准数据集上明显优于先前的ETL方法,同时工作量小。
Introduction
在过去的十年,基于深度学习的视觉识别方法取得巨大的成功。SOTA方法一般在大量图像和离散的标签上训练。离散标签是通过将详细的文本描述(例如 American curl cat)转换为简单的标量,这极大地简化了损失函数的计算。然而,这也导致了两个明显的局限:(1)文本描述中丰富的语义未得到充分利用(2)经过训练的模型仅限于识别密集类。
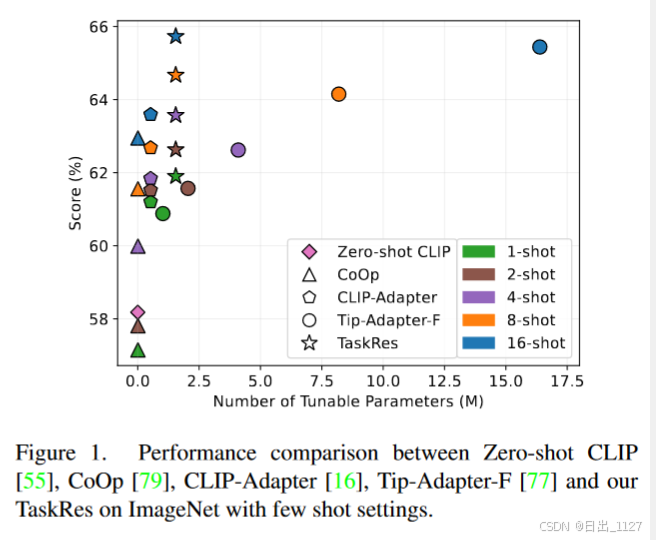
最近大规模视觉语言模型通过文本监督学习视觉表征来消除这些限制。例如,文本和图像在预训练过程中通过对比损失被编码并映射到一个统一的空间中。然后,预训练的文本编码器可用于合成基于文本的分类器,用于图像识别,给定相应的自然语言描述,如图 2 (a) 所示。这些预训练的 VLM 已经以zero-shot的方式在各种下游任务上表现出强大的可转移性。然而,上述模型的有效性在很大程度上取决于其大规模架构和训练数据集。例如,CLIP 拥有多达 4.28 亿个参数,并使用 4 亿个文本图像对进行训练,而 Flamingo拥有多达 800 亿个参数,并使用惊人的 21 亿个文本图像对进行训练。这使得在数据量较少的情况下对下游任务的模型进行完全微调是不切实际的。
因此,在预训练的VLM上进行高效的迁移学习ETL越来越受欢迎。ETL以参数和数据高效的方式迁移到下游任务中。ETL 的核心有两个方面:(1)继承了 VLM 的知识结构,这些知识结构是可迁移的;(2) 在数据有限的情况下高效地探索特定任务的知识。然而,大多数现有的ETL方法,即提示调优PT和适配器调优AT,要么损害VLM的先验知识,要么以不适当的方式学习任务特定的新知识。
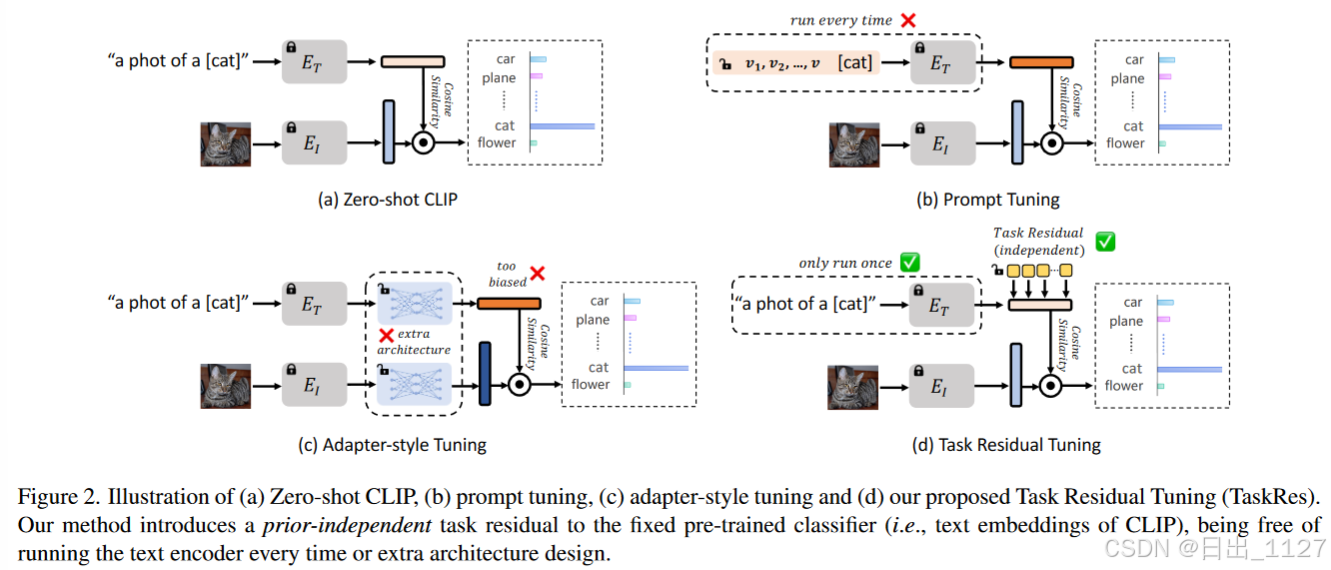
解释图2:
a.Zero-shot CLIP利用预训练的文本编码器合成文本分类器,即利用自然语言描述来识别和分类图像。
b.以CoOp为例,不使用预训练的基本文本的分类器,而是学习一个连续的提示来合成一个新的分类器,这会丢失先验知识。因此CoOp 在 ImageNet 上的 1/2-shot 学习中比 Zero-shot CLIP 低 1.03%/0.37%(见图 1)
c.CLIP-Adapter保留了预训练的分类器,但是学习新任务时过度偏向先验知识,即将预训练的分类器权重转换为特定任务的权重。这导致新知识的探索能力低,准确率低。
为了在预训练 VLM 上实现更好的 ETL,本文提出一种名为 Task Residual Tuning (TaskRes) 的高效调优方法,该方法直接在基于文本的分类器上执行,并显式地将预训练模型的旧知识与目标任务的新知识解耦。其基本原理是,解耦能够更好地从 VLM 继承旧知识,并实现更灵活的特定于任务的知识探索,即学习到的知识与任务无关。具体来说,TaskRes 保持原始分类器权重的冻结状态,并引入了一组与先验无关的参数,这些参数被添加到权重中。这些为适应目标任务而调整的参数因此被称为“任务残差”。
为了深入了解 TaskRes 的工作原理,本文在 11 个基准数据集中进行了广泛的实验,并对学习到的任务残差进行了系统调查。实验结果表明,引入任务残差可以显著提高迁移性能。本文可视化了学习到的任务残差的大小与将预训练模型转移到下游任务的难度之间的相关性,并观察到大小随着转移难度的增加而增加。这表明残差会自动适应任务以充分探索新知识,从而在 11 个不同的数据集上实现最先进的性能。此外,值得注意的是,本文方法需要最少的实现工作,即从技术上讲,只需添加一行代码。
本文贡献
(1)本文首次强调通过 ETL 将知识从预训练的 VLM 迁移到下游任务的必要性,揭示了现有调优范式的陷阱,并进行了深入分析,以表明将旧的预训练知识和新的任务特定知识解耦是关键。
(2)本文提出一种高效调优方法,称为任务残差调优 (TaskRes),它可以实现更好的VLM旧知识继承和更灵活的任务特定知识探索。
(3)TaskRes 使用方便,需要一些调优参数和轻松实现。
Preliminaries
本文简要介绍了所采用的VLM,即对比语言-图像预训练模型(CLIP),并回顾了VLM上ETL(迁移学习)的两种主流方法,即提示调优和适配器式调优。
Contrastive Language-Image Pre-training
CLIP 模型旨在通过自然语言监督获得视觉表示。CLIP在4亿个图像-文本对上进行训练,其中来自图像编码器的图像特征和来自文本编码器的文本特征使用对比学习损失在统一的嵌入空间内对齐,使 CLIP 能够有效地捕获广泛的视觉概念并学习一般的视觉表示。在测试时,CLIP 可以将查询图像分类为 K 个可能的类别。这是通过计算查询图像嵌入 z 与文本嵌入之间的余弦相似度来实现的,前者是从图像编码器获得的,后者是通过将文本(例如,“{class} 的照片}”)输入到文本分支中而得出的。第i个类别的预测概率表示为
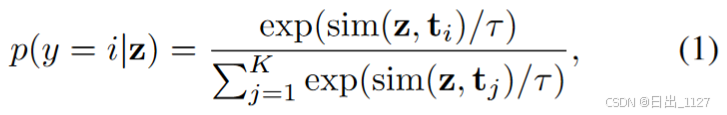
Revisiting Previous Tuning Paradigms
受到 ETL 方法在自然语言处理中成功的启发,例如提示调优PT和适配器式调优,最近的进展(例如CoOp和CLIP-Adapter)将他们的想法借用到 VLM 上的 ETL。
CoOp 首次为VLM引入了提示调优。CoOp 没有使用固定的文本提示上下文,例如“A photo of a”,而是使用 M 个可学习上下文向量 {vm} 作为特定于任务的模板。然后,提供给文本编码器的提示将变为 {v1,v2, · · · vM ,ci},其中 ci 是第i个类的嵌入。在整个训练过程中,CoOp 会冻结预训练VLM的参数,只调整可学习提示向量 {vm}。
适配器式调优为预训练模型引入了具有可调参数 ω 的附加模块 φω(·),以将预训练特征 f 转换为新特征 f ′。通常,适配器式调优可以表述为
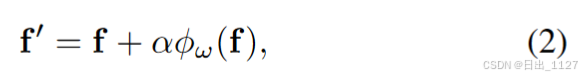
其中α是缩放因子。在 CLIP-Adapter 中,适配器模块 φω 由两个线性变换层和它们之间的 ReLU激活函数组成。CLIP-Adapter 研究了视觉和文本适配器,即分别将适配器模块应用于CLIP的图像和文本分支,并表明它们具有可比的性能。在下游任务的训练期间,适配器式调优仅调整其适配器模块。
Approach
Pitfalls of Existing ETL Paradigms on VLMs
我们重新思考对预训练VLM的先验知识和下游任务的新知识的使用。一方面,在大规模数据集训练的VLM已经学习了广泛的视觉概念,这些概念适用于广泛的下游视觉任务,从而实现了均质化。知识迁移时应妥善保留先前的知识。另一方面,尽管预训练中使用了大量数据,但下游任务中不可避免地存在领域偏移或不确定的概念。特定于下游任务的新知识应适当补充到先前知识中。然而,现有的 ETL 范式并没有很好地考虑上述原则,存在以下两个问题:
Pitfall 1: Lack of guarantees of prior knowledge preservation in prompt tuning.提示调优中缺乏对先验知识保留的保证
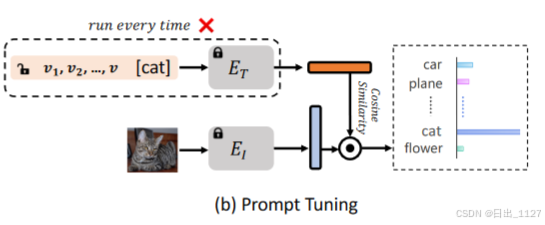
尽管预训练的文本分支(文本编码器和投影层)的权重在提示调优中被冻结,但原始分类边界或多或少受到了损害。这是因为输入提示的调优最终会得到一个新的边界,如果没有显式的正则化,它可能会忘记旧知识。因此,提示调优的性能会受到限制。例如,CoOp在 ImageNet 上的 1/2-shot学习中的性能不如 Zero-shot CLIP(图1).
Pitfall 2: Limited flexibility of new knowledge exploration in adapter-style tuning.适配器式调优中缺乏对新知识探索的灵活性
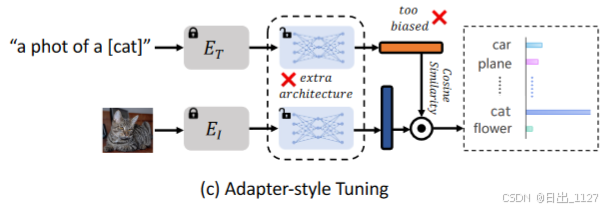
下游任务中的数据分布往往与预训练分布存在分布偏移,一些特定于任务或细粒度的视觉概念可能无法被预训练的VLM很好地学习,例如,从CLIP对于卫星图像数据集EuroSAT。因此,需要适当地探索有关下游任务的新知识。适配器式调优可能无法充分探索特定于任务的知识,因为适配器的输入严格限于旧的/预训练的特征,如图 2c所示。无论预训练的特征是否适合下游任务,适配器的结果都只取决于预训练的特征,这使得适配器式调优在学习新知识方面的灵活性有限。
Task Residual Tuning
由于现存的 ETL 范式面临上述问题,本文提出了任务残差调优(TaskRes)以简单的方式解决这些问题。TaskRes 明确地将预训练 VLM 中旧知识的维护与与任务特定知识的学习分离,并且任务特定知识不会过度偏向于预训练的特征。
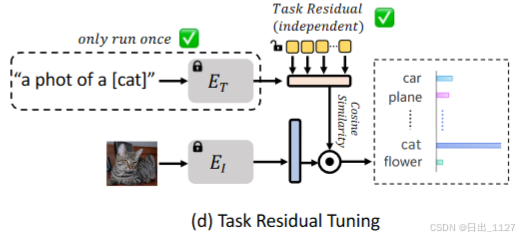
Fixed base classifier.固定的基本分类器
如图 2(d)所示, TaskRes 直接在基于文本的分类器(即文本嵌入)上进行调优。基本分类器是预训练VLM的文本嵌入,例如 CLIP。我们将基本分类器表示为 t ∈ RK×D,其中 K 是类别的数量,D 是特征维度。保证基本分类器权重冻结,以防止它被损坏。
Prior-independent task residual.先验无关的任务残差
为了不受先验知识的限制来学习任务特定知识,本文提出任务残差,这是一组不依赖于基本分类器的可调参数 x ∈ RK×D。我们的任务残差按因子 α 进行缩放,并按元素添加到基本分类器中,为目标任务构建一个新的分类器 t′,写为

Tuning for downstream tasks.
在调优过程中,只调优与先验无关的任务残差,同时保持基本分类器(连同图像分支)不变,实现可靠的旧知识保存和灵活的新知识探索。给定一个图像,CLIP 的固定图像分支提取其嵌入 z ∈ RD。然后,将第i个类的预测概率计算为
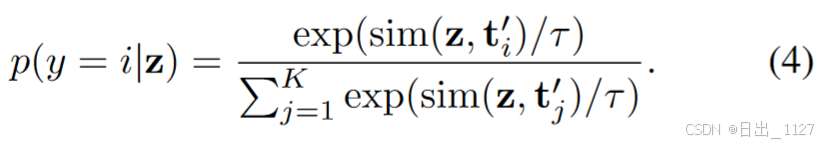
根据预测概率,下游任务损失(交叉熵损失)仅通过标准的反向传播来更新任务残差。
Experiment
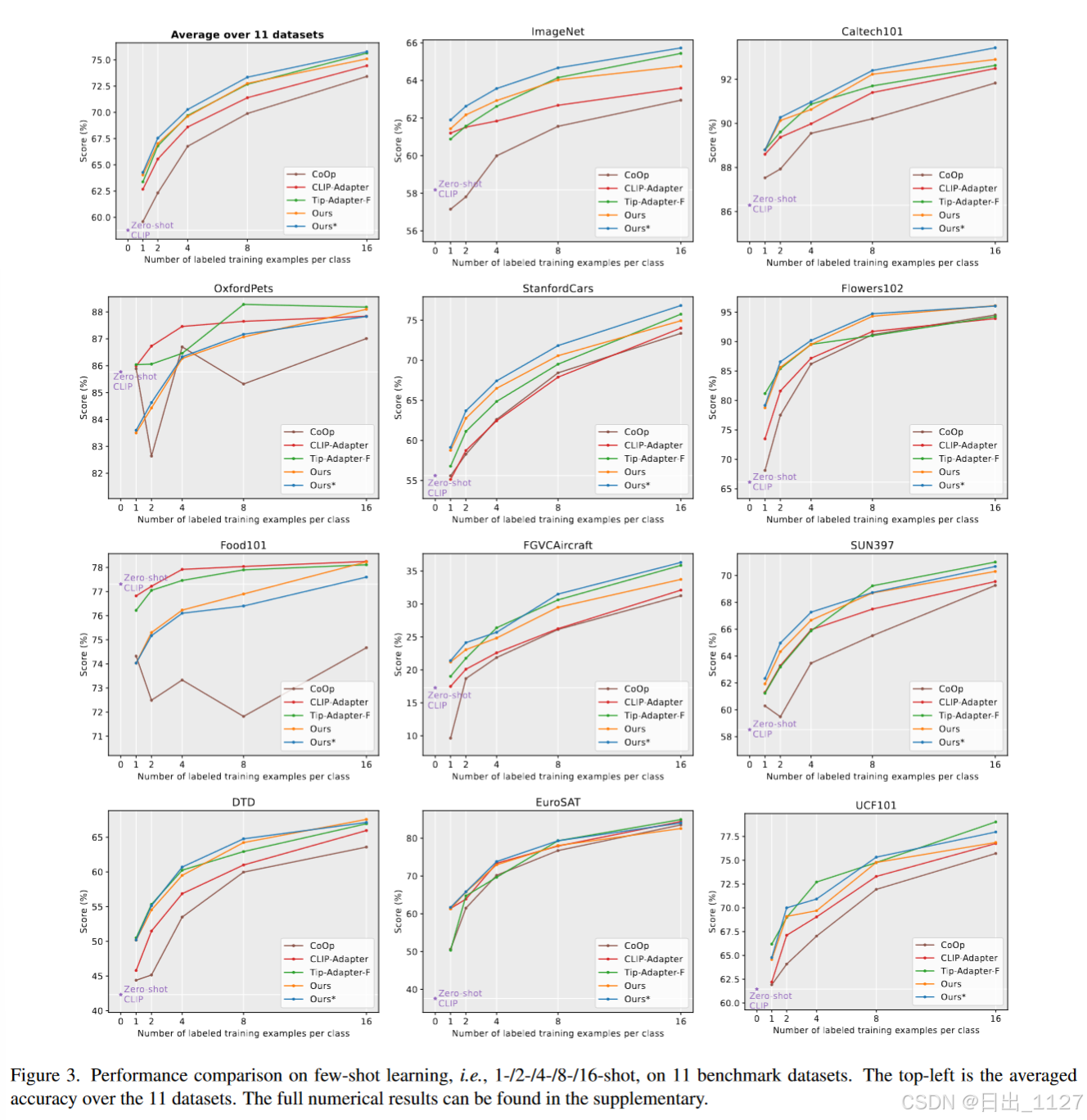
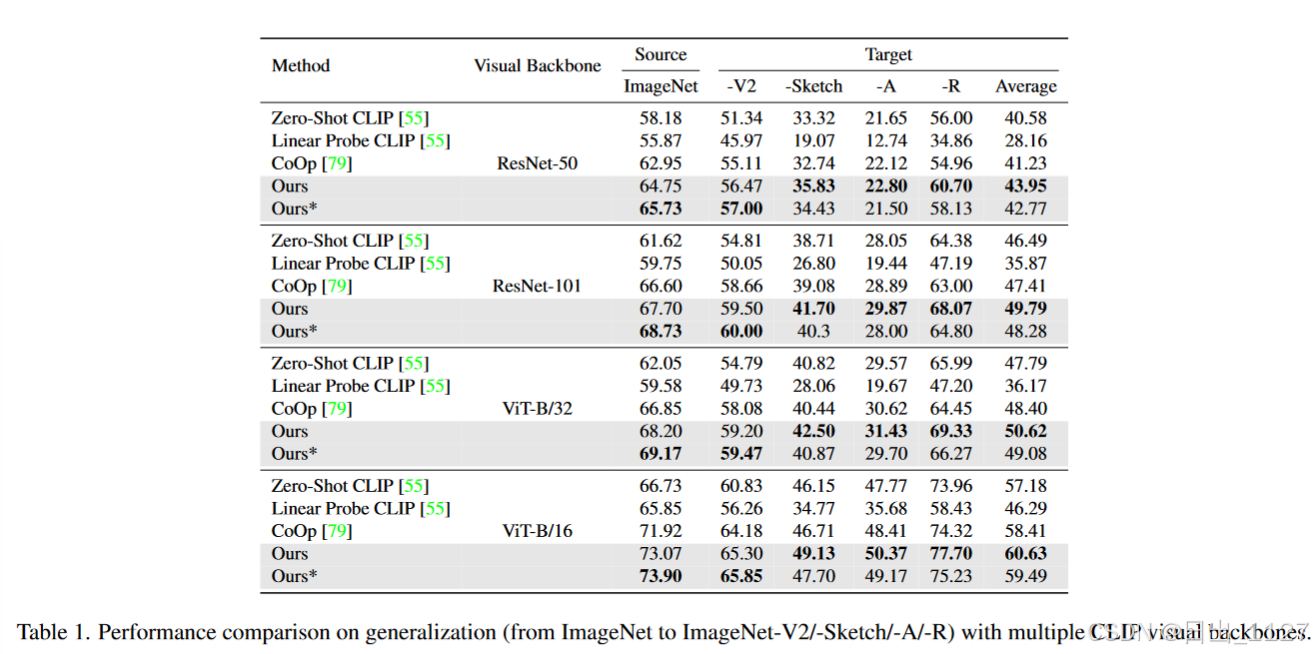
Conclusion,Limitation and Future Work
本文提出了一种VLM调优的新方法,即 TaskRes。TaskRes 通过将分类器显式解耦为两个关键部分,从而对 VLM 进行高效的迁移学习 (ETL):具有丰富先验知识的未被损坏的基本分类器和独立于基本分类器的任务残差,以便更好地探索特定任务的知识。有趣的是,学习到的任务残差的大小与将预训练的 VLM 转移到目标下游任务的难度高度相关。这可能会激发社区从新的角度考虑 ETL,例如,为 ETL 建模“任务到任务转移难度”。尽管 TaskRes 很简单,但广泛的实验已经证明了它的有效性。
然而,本文方法有一些局限性。例如,本文方法在两个数据集上遇到了负迁移,即 OxfordPets (1-shot) 和 Food101 (1-/2-/4-/8shot)。本文推测,这种情况发生在两个情况下:(i) 下游任务的相对转移难度较高,如图 4 所示
(ii) Zero-shot CLIP 已经对它们实现了相当的精度。此外,这项工作中对迁移难度的评估是启发式的。
随着基础模型的快速发展,建立精确可靠的指标来评估预训练基础模型向下游任务的迁移难度变得越来越重要。对迁移难度的全面研究,包括分布分析,需求量很大。此外,我们可以将迁移难度扩展到概念层面,并通过探索在特定数据集上训练的 CLIP 模型来研究性能与视觉概念出现频率之间的相关性,例如在 YFCC15M上训练的 SLIP。
*******附TaskRes代码文件(内含自己理解的注释,若有错误请各位及时指正啊)
import os
import os.path as osp
from re import template
import torch
import torch.nn as nn
from torch.nn import functional as F
from torch.cuda.amp import GradScaler, autocast
from dassl.engine import TRAINER_REGISTRY, TrainerX
from dassl.metrics import compute_accuracy
from dassl.utils import load_pretrained_weights, load_checkpoint
from dassl.optim import build_optimizer, build_lr_scheduler
from clip import clip
from clip.simple_tokenizer import SimpleTokenizer as _Tokenizer
from trainers.imagenet_templates import IMAGENET_TEMPLATES, IMAGENET_TEMPLATES_SELECT
torch.backends.cuda.matmul.allow_tf32 = True # zyr:tf32代表tensorfloat32,矩阵乘法可以更快运行
torch.backends.cudnn.benchmark = True # zyr:启用基准模式,根据输入数据大小和卷积层的配置选择最佳的卷积算法
torch.backends.cudnn.deterministic = False # zyr:使用非确定性算法,适用于不需精确可重复性但需最佳性能的情况
torch.backends.cudnn.allow_tf32 = True # zyr:允许在卷积操作中使用tf32进行加速
_tokenizer = _Tokenizer()
CUSTOM_TEMPLATES = {
"OxfordPets": "a photo of a {}, a type of pet.",
"OxfordFlowers": "a photo of a {}, a type of flower.",
"FGVCAircraft": "a photo of a {}, a type of aircraft.",
"DescribableTextures": "{} texture.",
"EuroSAT": "a centered satellite photo of {}.",
"StanfordCars": "a photo of a {}.",
"Food101": "a photo of {}, a type of food.",
"SUN397": "a photo of a {}.",
"Caltech101": "a photo of a {}.",
"UCF101": "a photo of a person doing {}.",
"ImageNet": "a photo of a {}.",
"ImageNetSketch": "a photo of a {}.",
"ImageNetV2": "a photo of a {}.",
"ImageNetA": "a photo of a {}.",
"ImageNetR": "a photo of a {}.",
}
def load_clip_to_cpu(cfg):
backbone_name = cfg.MODEL.BACKBONE.NAME
url = clip._MODELS[backbone_name]
model_path = clip._download(url)
try:
# loading JIT archive
model = torch.jit.load(model_path, map_location="cpu").eval()
state_dict = None
except RuntimeError:
state_dict = torch.load(model_path, map_location="cpu")
model = clip.build_model(state_dict or model.state_dict())
return model
class TextEncoder(nn.Module):
def __init__(self, clip_model):
super().__init__()
self.transformer = clip_model.transformer # zyr:这里的transformer模块包含若干个transformer层(包含注意力层和前馈网络)
self.positional_embedding = clip_model.positional_embedding
self.ln_final = clip_model.ln_final
self.text_projection = clip_model.text_projection
self.dtype = clip_model.dtype
def forward(self, prompts, tokenized_prompts):
x = prompts + self.positional_embedding.type(self.dtype)
x = x.permute(1, 0, 2) # NLD -> LND
x = self.transformer(x)
x = x.permute(1, 0, 2) # LND -> NLD
x = self.ln_final(x).type(self.dtype)
# x.shape = [batch_size, n_ctx, transformer.width]
# take features from the eot embedding (eot_token is the highest number in each sequence)
x = x[torch.arange(x.shape[0]), tokenized_prompts.argmax(dim=-1)] @ self.text_projection
# zyr:先提取每个样本序列中结束标记的特征向量,然后映射到共享特征空间中
return x
# TaskRes(-Text)
class TaskResLearner(nn.Module):
def __init__(self, cfg, classnames, clip_model, base_text_features):
super().__init__()
self.device = clip_model.dtype # zyr:存储CLIP模型的数据类型
self.alpha = cfg.TRAINER.TaskRes.RESIDUAL_SCALE # zyr:残差缩放因子
print(">> DCT scale factor: ", self.alpha)
self.register_buffer("base_text_features", base_text_features) # zyr:创建缓冲区存储基本文本特征,保证训练和测试过程中不会更新
self.text_feature_residuals = nn.Parameter(torch.zeros_like(base_text_features)) # zyr:创建可训练参数x,即text_feature_residuals
def forward(self):
return self.base_text_features + self.alpha * self.text_feature_residuals # t + a * x
# # TaskRes-Image
# class TaskResLearner(nn.Module):
# def __init__(self, cfg, classnames, clip_model, base_text_features):
# super().__init__()
# self.device = clip_model.dtype
# # feat_dim = base_text_features.size(-1)
# self.alpha = cfg.TRAINER.TaskRes.RESIDUAL_SCALE
# print(">> DCT scale factor: ", self.alpha)
# self.register_buffer("base_text_features", base_text_features)
# self.text_feature_residuals = nn.Parameter(torch.zeros_like(base_text_features[0:1]))
# def forward(self):
# # print(self.base_text_features.dtype, self.text_feature_residuals.dtype)
# return self.base_text_features, self.alpha * self.text_feature_residuals
def _get_base_text_features(cfg, classnames, clip_model, text_encoder):
device = next(text_encoder.parameters()).device
if clip_model.dtype == torch.float16:
# zyr:判断数据类型是否为float16,如果是就移动到GPU上运行,提高效率节省内存;否则就继续在CPU上运行
text_encoder = text_encoder.cuda()
dataset = cfg.DATASET.NAME
if dataset == "ImageNet":
TEMPLATES = IMAGENET_TEMPLATES_SELECT
else:
TEMPLATES = []
TEMPLATES += [CUSTOM_TEMPLATES[dataset]]
with torch.no_grad():
text_embeddings = [] # zyr:定义一个列表用于存储本文嵌入向量
for text in classnames:
# zyr:依次遍历每一个类别
tokens = clip.tokenize([template.format(text) for template in TEMPLATES]) # tokenized prompts are indices
# zyr:以cat类别为例,tokes存储cat类别所有模板的token表示
embeddings = clip_model.token_embedding(tokens).type(clip_model.dtype)
if clip_model.dtype == torch.float16:
text_embeddings.append(text_encoder(embeddings.cuda(), tokens.cuda())) # not support float16 on cpu
else:
text_embeddings.append(text_encoder(embeddings.cuda(), tokens.cuda()))
# zyr:将文本编码器处理得到的文本嵌入向量存到text_embeddings列表中
text_embeddings = torch.stack(text_embeddings).mean(1)
# zyr:将列表中内容堆叠,形状为[num_cls,num_templates,dim],mean(1)后形状为[num_cls,dim]
text_encoder = text_encoder.to(device)
return text_embeddings.to(device)
def _get_enhanced_base_text_features(cfg, classnames, clip_model, text_encoder, pretraiend_model):
# zyr:通过加载预训练模型来增强text_encoder,用于生成增强的文本特征嵌入
device = next(text_encoder.parameters()).device
if clip_model.dtype == torch.float16:
text_encoder = text_encoder.cuda()
pretrained_text_projection = torch.load(pretraiend_model)
# zyr:以下段代码将预训练模型的权重加载到文本编码器中,确保text_encoder能够利用预训练的知识
# zyr:以下包括获取当前模型的状态字典、更新text_projection权重,计算参数总数并打印相关信息
state_dict = text_encoder.state_dict() # zyr:返回当前模型的状态字典,包含所有参数的权重和偏置的字典
state_dict['text_projection'] = pretrained_text_projection['state_dict']['weight'].t()
text_encoder.load_state_dict(state_dict)
print(">> Pretrained text encoder loaded!")
params = pretrained_text_projection['state_dict']['weight'].size(0) * \
pretrained_text_projection['state_dict']['weight'].size(1)
print(">> Text projection parameters: ", params)
print(pretrained_text_projection['state_dict'].keys())
dataset = cfg.DATASET.NAME
if dataset == "ImageNet":
TEMPLATES = IMAGENET_TEMPLATES_SELECT
else:
TEMPLATES = []
TEMPLATES += [CUSTOM_TEMPLATES[dataset]]
with torch.no_grad():
text_embeddings = []
for text in classnames:
tokens = clip.tokenize([template.format(text) for template in TEMPLATES]) # tokenized prompts are indices
embeddings = clip_model.token_embedding(tokens).type(clip_model.dtype)
if clip_model.dtype == torch.float16:
text_embeddings.append(text_encoder(embeddings.cuda(), tokens.cuda())) # not support float16 on cpu
else:
text_embeddings.append(text_encoder(embeddings.cuda(), tokens.cuda()))
text_embeddings = torch.stack(text_embeddings).mean(1)
text_encoder = text_encoder.to(device)
return text_embeddings.to(device)
# TaskRes by Tao Yu, Oct 4, 2022
class CustomCLIP(nn.Module):
def __init__(self, cfg, classnames, clip_model):
super().__init__()
self.image_encoder = clip_model.visual
self.logit_scale = clip_model.logit_scale
self.dtype = clip_model.dtype # float16
text_encoder = TextEncoder(clip_model)
# zyr: cfg.TRAINER.TaskRes.ENHANCED_BASE参数代表预训练的模型
if cfg.TRAINER.TaskRes.ENHANCED_BASE == "none":
print(">> Use regular base!")
base_text_features = _get_base_text_features(cfg, classnames, clip_model, text_encoder)
else:
print(">> Use enhanced base!")
base_text_features = _get_enhanced_base_text_features(
cfg, classnames, clip_model, text_encoder, cfg.TRAINER.TaskRes.ENHANCED_BASE)
self.prompt_learner = TaskResLearner(cfg, classnames, clip_model, base_text_features)
def forward(self, image):
try:
image_features = self.image_encoder(image.type(self.dtype))
except:
image_features = self.image_encoder(image.float())
# TaskRes-Text
text_features = self.prompt_learner()
# # TaskRes-Image
# text_features, image_res = self.prompt_learner()
# image_features += image_res
# zyr:现在最后一个维度上计算L2范数,并且确保输出维度与输入一致,后面进行归一化
image_features = image_features / image_features.norm(dim=-1, keepdim=True)
text_features = text_features / text_features.norm(dim=-1, keepdim=True)
logit_scale = self.logit_scale.exp()
logits = logit_scale * image_features @ text_features.t()
return logits
@TRAINER_REGISTRY.register()
class TaskRes(TrainerX):
"""Context Optimization (TaskRes).
Task Residual for Tuning Vision-Language Models
https://arxiv.org/abs/2211.10277
"""
def check_cfg(self, cfg):
assert cfg.TRAINER.TaskRes.PREC in ["fp16", "fp32", "amp"]
def build_model(self):
cfg = self.cfg
classnames = self.dm.dataset.classnames
print(f"Loading CLIP (backbone: {cfg.MODEL.BACKBONE.NAME})")
clip_model = load_clip_to_cpu(cfg)
if cfg.TRAINER.TaskRes.PREC == "fp32" or cfg.TRAINER.TaskRes.PREC == "amp":
# CLIP's default precision is fp16
clip_model.float()
print("Building custom CLIP")
self.model = CustomCLIP(cfg, classnames, clip_model)
print("Turning off gradients in both the image and the text encoder")
for name, param in self.model.named_parameters():
if "prompt_learner" not in name:
param.requires_grad_(False)
else:
print(name)
if cfg.MODEL.INIT_WEIGHTS:
load_pretrained_weights(self.model.prompt_learner, cfg.MODEL.INIT_WEIGHTS)
self.model.to(self.device)
self.model = self.model.float()
# NOTE: only give prompt_learner to the optimizer
self.optim = build_optimizer(self.model.prompt_learner, cfg.OPTIM)
self.sched = build_lr_scheduler(self.optim, cfg.OPTIM)
self.register_model("prompt_learner", self.model.prompt_learner, self.optim, self.sched)
self.scaler = GradScaler() if cfg.TRAINER.TaskRes.PREC == "amp" else None
# Note that multi-gpu training could be slow because CLIP's size is
# big, which slows down the copy operation in DataParallel
device_count = torch.cuda.device_count()
if device_count > 1:
print(f"Multiple GPUs detected (n_gpus={device_count}), use all of them!")
self.model = nn.DataParallel(self.model)
def forward_backward(self, batch):
image, label = self.parse_batch_train(batch)
prec = self.cfg.TRAINER.TaskRes.PREC、
# zyr:amp代表自动混合精度,否则代表全精度
if prec == "amp":
with autocast():
output = self.model(image)
loss = F.cross_entropy(output, label)
self.optim.zero_grad()
self.scaler.scale(loss).backward()
self.scaler.step(self.optim)
self.scaler.update()
else:
output = self.model(image)
loss = F.cross_entropy(output, label)
self.model_backward_and_update(loss)
loss_summary = {
"loss": loss.item(),
"acc": compute_accuracy(output, label)[0].item(),
}
if (self.batch_idx + 1) == self.num_batches:
self.update_lr()
return loss_summary
def parse_batch_train(self, batch):
input = batch["img"]
label = batch["label"]
input = input.to(self.device)
label = label.to(self.device)
return input, label
def load_model(self, directory, epoch=None):
if not directory:
print("Note that load_model() is skipped as no pretrained model is given")
return
names = self.get_model_names()
# By default, the best model is loaded
model_file = "model-best.pth.tar"
if epoch is not None:
model_file = "model.pth.tar-" + str(epoch)
for name in names:
model_path = osp.join(directory, name, model_file)
if not osp.exists(model_path):
raise FileNotFoundError('Model not found at "{}"'.format(model_path))
checkpoint = load_checkpoint(model_path)
state_dict = checkpoint["state_dict"]
if self.cfg.DATASET.NAME == 'ImageNetA' or self.cfg.DATASET.NAME == 'ImageNetR':
if self.cfg.DATASET.NAME == 'ImageNetA':
from .imagenet_a_r_indexes_v2 import find_imagenet_a_indexes as find_indexes
else:
from .imagenet_a_r_indexes_v2 import find_imagenet_r_indexes as find_indexes
imageneta_indexes = find_indexes()
state_dict['base_text_features'] = state_dict['base_text_features'][imageneta_indexes]
state_dict['text_feature_residuals'] = state_dict['text_feature_residuals'][imageneta_indexes]
epoch = checkpoint["epoch"]
# Ignore fixed token vectors
if "token_prefix" in state_dict:
del state_dict["token_prefix"]
if "token_suffix" in state_dict:
del state_dict["token_suffix"]
print("Loading weights to {} " 'from "{}" (epoch = {})'.format(name, model_path, epoch))
# set strict=False
self._models[name].load_state_dict(state_dict, strict=False)
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » TaskRes(论文解读):Task Residual for Tuning Vision-Language Models

发表评论 取消回复