CDAS支持整库级别的表结构和数据的实时同步,还支持表结构变更的同步。本文为您介绍CREATE DATABASE AS(CDAS)的使用方法,并提供了多种使用场景下的示例。
背景信息
CDAS是CTAS语法的一个语法糖,用于实现整库同步、多表同步的功能。阿里云Flink引擎会将CDAS语句中每个需要同步的表翻译成一个对应的CTAS语句。因此,CDAS还拥有CTAS的数据同步和表结构变更同步的能力,常用于全自动化的数据集成场景。此外,阿里云Flink还能对源表进行优化,复用一个源表节点读取多业务表的数据。这对于MySQL CDC数据源场景尤为适用,因为不仅可以减少数据库的连接数,还能避免重复拉取Binlog数据,以降低数据库的读取压力。
使用限制
-
仅Flink计算引擎vvr-4.0.11-flink-1.13及以上版本支持CDAS语法。
重要
CDAS语法不支持进行调试。
-
仅Flink计算引擎vvr-4.0.13-flink-1.13及以上版本支持分库合并同步。
-
CDAS支持的上下游存储列表如下。
连接器名称
源表
结果表
备注
√
×
不支持同步MySQL视图。
√
×
无。
√
×
-
暂不支持分库合并同步。
-
暂不支持同步MongoDB元信息。
-
支持通过CDAS语句将MongoDB中的数据及表结构变更同步至目标表。具体的配置要求请参见使用MongoDB Catalog。
×
√
无。
×
√
如果下游是Hologres,CDAS在默认情况下会为每个表创建相应数量(connectionSize参数值)个连接。此时您可以使用connectionPoolName参数,让配置相同名称连接池的表可以共享连接池。
说明
-
在将数据同步到Hologres时,如果您的上游源表包含了Fixed Plan不支持类型的数据,建议通过INSERT INTO语句的方式,在Flink内部做类型转换后将数据同步到Hologres。不要用CDAS方式创建Sink结果表进行数据同步,因为这种方式会无法走Fixed Plan,写入性能较差。
-
实时计算Flink版仅支持读写Hologres内表,因此Hologres实例必须是独占实例,不支持Hologres共享集群实例。
×
√
仅支持EMR的StarRocks。
×
√
-
仅Flink计算引擎vvr-6.0.7-flink-1.15及以上版本支持Paimon结果表。
-
暂不支持同步到Paimon DLF 2.0结果表。
-
前提条件
-
执行CDAS语法前,确保工作空间中已注册目标端的Catalog,详情请参见管理元数据。
-
执行CDAS语法前,如果您需要访问不同账号下的上下游资源、以及使用RAM用户或RAM角色等身份访问时,请确保登录Flink全托管的账号具有读写上下游资源的权限,否则会因为权限不足导致读写操作失败。
注意事项
-
使用VVR 8.0.6及以上版本时,CDAS作业启动后,支持添加新表后从作业快照重启,从而捕获到新的表。详情请参见示例三:源库新增表加入数据同步。
-
使用VVR 8.0.5及以下版本时,CDAS作业启动后,作业同步的表已经确定,数据库中新增的表不会自动捕捉,也无法通过重启作业的方式捕获到。如果需要同步新增的表,您可以选择以下任一种方案:
-
原有CDAS作业不变,启动一个新的作业同步新增的表。例如
// 新建CTAS作业同步新增加的表new_table CREATE TABLE IF NOT EXISTS new_table AS TABLE mysql.tpcds.new_table /*+ OPTIONS('server-id'='8008-8010') */; -
停止现有CDAS作业,清理已同步的数据后,以全新状态重启CDAS作业来重新同步数据。
-
功能特性
| 功能 | 详情 |
| 支持实时同步整库(或者多张表)的全量和增量数据到每张对应的结果表中。 | |
| 在实时同步整库数据的同时,还支持将每张源表的表结构变更(加列等)实时同步到结果表中。 | |
| 支持使用正则表达式定义库名,匹配数据源的多个分库下的源表,合并后同步到下游每张对应表名的结果表中。 | |
| CDAS作业启动后,如果源库新增表,支持从作业快照重启,从而捕获到新的表,对新增表进行数据同步。 | |
| 支持使用STATEMENT SET语法将多个CDAS和CTAS语句作为一个作业一起提交,并支持对源表节点的合并复用,降低对数据源的压力。 |
启动流程
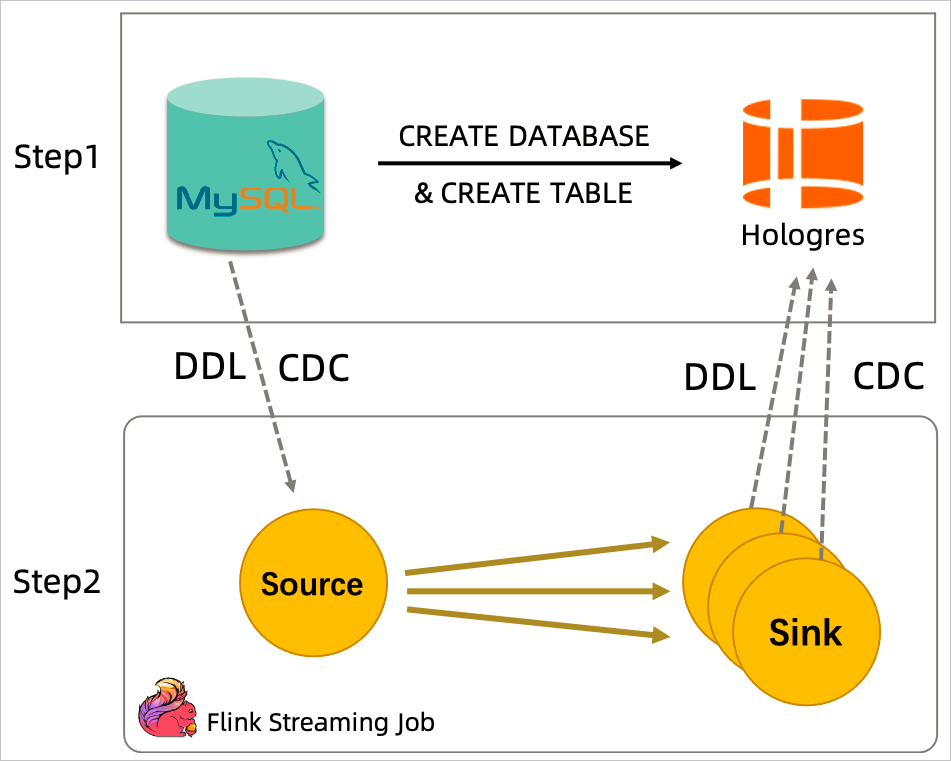
当执行CDAS语句时,阿里云Flink将会按照以下流程执行:
-
检查目标存储中是否存在目标库和结果表。
-
如果不存在目标库,则通过目标端Catalog去目标存储中创建相应的目标库。
-
如果存在目标库,则跳过建库,并检查目标库是否存在该结果表。
-
如果不存在,则在目标库中创建相应的结果表,该结果表具有和源库中表相同的表名和Schema。
-
如果存在,则跳过建表。
-
-
-
提交和启动相应的数据同步作业。将源库中的数据以及Schema变更同步到目标库下的表中。
例如,从MySQL到Hologres的CDAS数据同步流程如下图所示。
表结构变更同步策略
因为CDAS是CTAS语法的一个语法糖,所以表结构变更能力与CTAS一致,详情请参见CREATE TABLE AS(CTAS)语句。
基本语法
CREATE DATABASE IF NOT EXISTS <target_database>
[COMMENT database_comment]
[WITH (key1=val1, key2=val2, ...)]
AS DATABASE <source_database>
INCLUDING { ALL TABLES | TABLE 'table_name' }
[EXCLUDING TABLE 'table_name']
[/*+ OPTIONS(key1=val1, key2=val2, ... ) */]
<target_database>:
[catalog_name.]db_name
<source_database>:
[catalog_name.]db_nameCDAS语法复用了CREATE DATABASE语法的基本结构,其中的参数解释如下表所示。
| 参数 | 说明 |
| target_database | 数据同步的目标数据库名,可以指定具体的Catalog名称。 |
| COMMENT | 目标库的描述,默认使用source_database的描述。 |
| WITH | 目标库的参数,详情请参见管理元数据中对应的Catalog文档。 说明 key和value都需要为字符串类型,例如'sink.parallelism' = '4'。 |
| source_database | 数据同步的源库名称,可以指定具体的Catalog名称。 |
| INCLUDING ALL TABLES | 同步源库中的所有表。 |
| INCLUDING TABLE | 同步源库中指定的表。支持使用竖线(|)分隔指定多个表,也可以使用正则表达式指定符合某一规则的表。例如INCLUDING TABLE 'web.*'表示要同步源库中所有web开头的表。 |
| EXCLUDING TABLE | 用于指定不需要同步的表,支持使用竖线(|)分隔指定多个表,也可以使用正则表达式指定符合某一规则的表,例如INCLUDING ALL TABLES EXCLUDING TABLE 'web.*'表示同步源库中所有不是web开头的表。 |
| OPTIONS | 源表的参数,详情请参见对应连接器支持的源表WITH参数。 说明 key和value都需要为字符串类型,例如'server-id' = '65500'。 |
说明
因为IF NOT EXISTS关键字为必填,所以如果目标库或结果表在目标存储中并不存在,则会先创建该目标库和结果表,否则跳过创建步骤。创建的结果表Schema会使用源表的Schema,包括主键以及物理字段的字段名和字段类型,不包括计算列、meta字段、Watermark。其中源表到结果表的字段类型会经过类型映射,详见对应连接器文档中的类型映射。
示例
示例一:整库同步
CDAS通常会配合数据源的Catalog和目标的Catalog一起使用。例如,MySQL Catalog和Hologres Catalog结合CDAS语法,完成MySQL到Hologres的全量和增量数据同步。使用MySQL Catalog可以自动解析源表的Schema及相应的参数,而不用手动编写DDL。
假设已在工作空间中注册了名为holo的Hologres Catalog和名为mysql的MySQL Catalog,MySQL中有一个名为tpcds的库。您可以使用以下语句将tpcds库下的24张表全部同步到Hologres中,包括未来的数据变更和表结构变更,无需提前在Hologres中创建表。
USE CATALOG holo;
CREATE DATABASE IF NOT EXISTS holo_tpcds -- 在hologres中创建holo_tpcds库。
WITH ('sink.parallelism' = '4') -- 可选,指定目标库的参数,每个holo sink默认使用4并发。
AS DATABASE mysql.tpcds INCLUDING ALL TABLES -- 同步mysql中tpcds库下所有表。
/*+ OPTIONS('server-id'='8001-8004') */ ; -- 可选,指定mysql-cdc源表的额外参数。说明
Hologres支持在创建目标Database时指定WITH参数,这些参数仅对当前作业生效,用于控制写入结果表时的行为,不会持久化到Hologres中。支持的WITH参数详情请参见实时数仓Hologres。
示例二:分库合并同步
对于分库合并同步的场景,需要利用正则表达式的库名来匹配所要同步的多个分库。使用CDAS可以将上游多个分库下相同表名的数据合并同步到Hologres目标库对应表名的同一张表中,库名和表名会作为额外的两个字段写入到每张结果表中。为保证主键唯一性,库名、表名和原主键一起作为对应Hologres表的新联合主键。
假设MySQL实例中有order_db01~order_db99多个分库,每个分库下都有order、order_detail等多张表。您可以使用以下语句将99个分库下的order、order_detail等表全部同步到Hologres中,包括未来的数据变更和表结构变更,无需提前在Hologres中创建表。
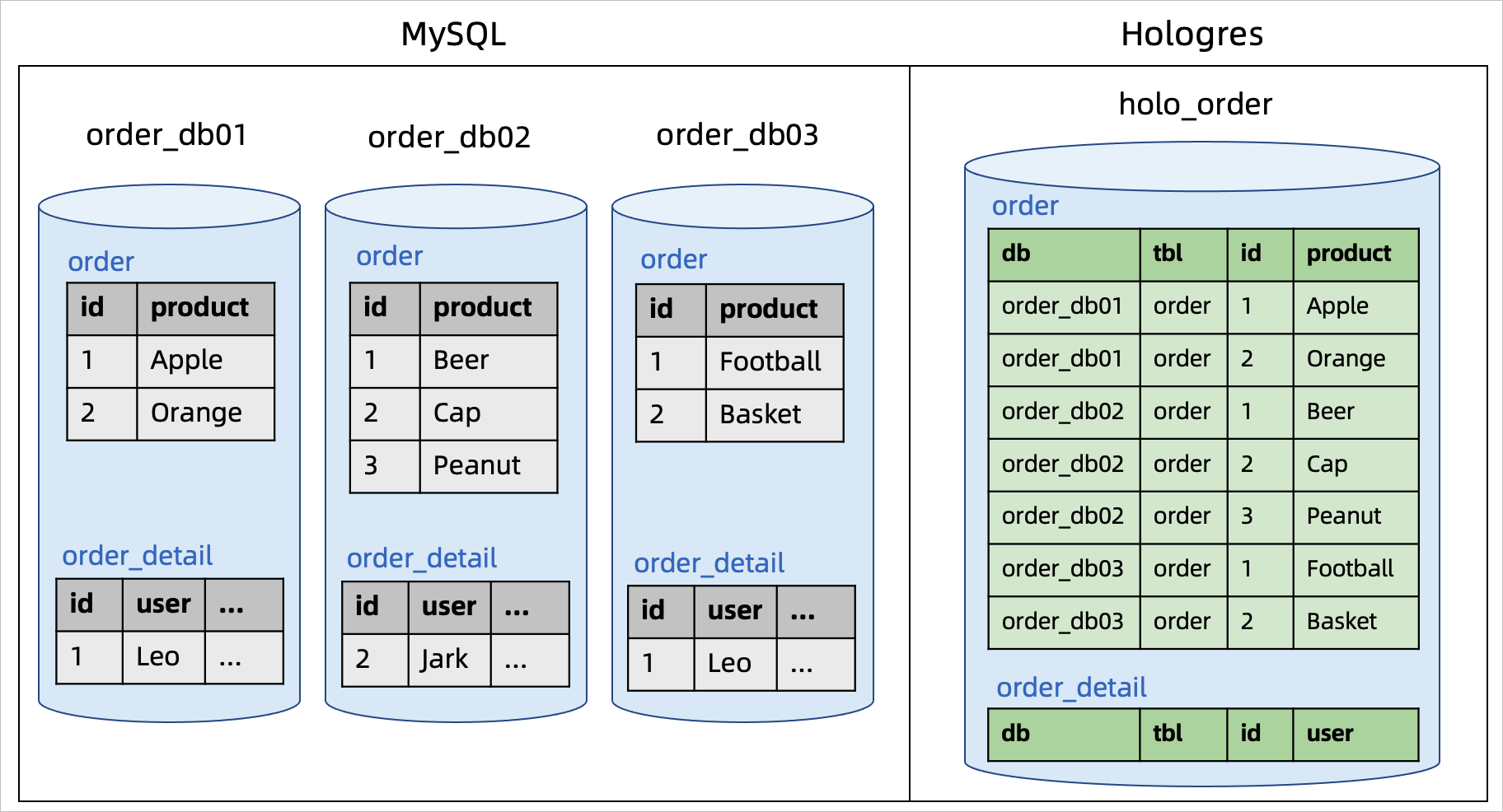
USE CATALOG holo;
CREATE DATABASE IF NOT EXISTS holo_order--在Hologres中创建holo_order库,包括mysql中order分库的所有表。
WITH('sink.parallelism'='4') --可选,指定目标库的参数,每个HologresSink默认并发为4。
AS DATABASE mysql.`order_db[0-9]+` INCLUDING ALL TABLES --同步mysql中order_db分库下所有表。
/*+OPTIONS('server-id'='8001-8004')*/; --可选,指定mysql-cdc源表的额外参数。示例三:源库新增表加入数据同步
使用VVR 8.0.6及以上版本时,CDAS作业启动后,如果源库新增表,支持从作业快照重启,从而捕获到新的表,对新增表进行数据同步。
-
SQL作业开发时需要增加以下语句,开启CDAS新增表读取功能。
SET 'table.cdas.scan.newly-added-table.enabled' = 'true'; -
当出现新增的表需要同步时,停止作业并勾选停止前创建一次快照。
-
在SQL开发中,重新部署这个SQL作业。
-
在作业运维页面单击目标作业名称,状态集管理页签,单击历史。
-
在作业快照列表中,找到停止作业时创建的快照。
-
单击目标快照操作列,选择更多 > 从该快照恢复作业。
-
在作业启动配置对话框,配置作业启动信息,详情请参见作业启动。
重要
新增表功能只能用于默认的initial启动模式。
示例四:多CDAS&CTAS语句
实时计算Flink版支持使用STATEMENT SET语法将多个CTAS语句作为一个作业一起提交,并且可以对Source进行优化,复用一个Source节点读取多业务表的数据。这对于MySQL CDC数据源场景尤为适用,因为这可以减少server-id的使用,减少对数据库的连接数和读取压力。
说明
对于Source复用优化,需要这些Source表的options保持完全一致,才能合并成功进行复用。
假设MySQL实例中有tpcds、tpch、user_db01~user_db99(分库分表)多个库。您可以通过组合多条CDAS和CTAS语句,将MySQL实例下的所有库和表都同步到Hologres,只需一个Flink作业便能完成所有表的同步,只需一个Source便能读取所有表的数据,代码示例如下。
USE CATALOG holo;
BEGIN STATEMENT SET;
-- 同步user分库分表。
CREATE TABLE IF NOT EXISTS user
AS TABLE mysql.`user_db[0-9]+`.`user[0-9]+`
/*+ OPTIONS('server-id'='8001-8004') */;
-- 同步TPCDS库。
CREATE DATABASE IF NOT EXISTS holo_tpcds
AS DATABASE mysql.tpcds INCLUDING ALL TABLES
/*+ OPTIONS('server-id'='8001-8004') */ ;
-- 同步TPCH库。
CREATE DATABASE IF NOT EXISTS holo_tpch
AS DATABASE mysql.tpch INCLUDING ALL TABLES
/*+ OPTIONS('server-id'='8001-8004') */ ;
END;示例五:多CDAS语句整库同步到Kafka
在使用多个CDAS语句整库同步到Kafka时,由于不同的数据库中可能存在相同的表,为了防止topic冲突,需要使用cdas.topic.pattern配置。cdas.topic.pattern定义了创建topic的名称的格式,其中可通过{table-name}占位符来替换为表名。如:当设置'cdas.topic.pattern'='db1-{table-name}',对于上游表名为table1的表,在Kafka中对应的topic名称为db1-table1。
假设MySQL实例中有tpcds、tpch多个库。您可以通过如下方式将MySQL实例下的所有库和表都同步到Kafka,避免topic冲突,代码示例如下。
USE CATALOG kafkaCatalog;
BEGIN STATEMENT SET;
-- 同步TPCDS库。
CREATE DATABASE IF NOT EXISTS kafka
WITH ('cdas.topic.pattern' = 'tpcds-{table-name}')
AS DATABASE mysql.tpcds INCLUDING ALL TABLES
/*+ OPTIONS('server-id'='8001-8004') */ ;
-- 同步TPCH库。
CREATE DATABASE IF NOT EXISTS kafka
WITH ('cdas.topic.pattern' = 'tpch-{table-name}')
AS DATABASE mysql.tpch INCLUDING ALL TABLES
/*+ OPTIONS('server-id'='8001-8004') */ ;
END;实时计算Flink版提供MySQL整库同步到Kafka的能力,通过引入Kafka作为中间层,并使用CDAS整库同步或CTAS整表同步到Kafka来解决
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » [实时计算flink]CREATE DATABASE AS(CDAS)语句

发表评论 取消回复