unordered_map和unordered_set
一.unordered_set
1.unordered_set类的介绍
- unordered_set的声明如下,Key就是unordered_set底层关键字的类型。
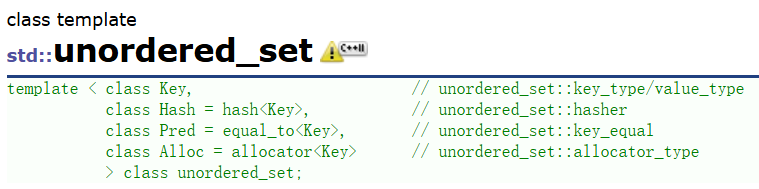
-
unordered_set默认
要求Key支持转换为整形,如果不支持或者想按自己的需求走可以自行实现支持将Key转成整形的仿函数传给第⼆个模板参数。 -
unordered_set默认
要求Key支持比较相等,如果不支持或者想按自己的需求走可以自行实现支持将Key比较相等的仿函数传给第三个模板参数。 -
unordered_set底层存储数据的内存是从空间配置器申请的,如果需要可以自己实现内存池,传给第四个参数。
-
一般情况下,我们都不需要传后三个模板参数。
-
unordered_set底层是用
哈希桶实现,增删查平均效率是O(1),迭代器遍历不再有序,为了跟set
区分,所以取名unordered_set。 -
set和unordered_set的功能高度相似,只是底层结构不同,有一些性能和使用的差异,这里只讲他们的差异部分。
2.unordered_set和set的使用差异
-
查看文档我们会发现unordered_set的支持增删查且跟set的使用一模一样,关于使用我们这里就不再赘述和演示了。
-
unordered_set和set的第一个差异是对key的要求不同,
set要求Key支持小于比较,而unordered_set要求Key支持转成整形且支持等于比较,要理解unordered_set的这个两点要求得后续我们结合哈希表底层实现才能真正理解,也就是说这本质是哈希表的要求。 -
unordered_set和set的第⼆个差异是迭代器的差异,
set的iterator是双向迭代器,unordered_set是单向迭代器,其次set底层是红黑树,红黑树是⼆叉搜索树,走中序遍历是有序的,所以set迭代器遍历是有序+去重。而unordered_set底层是哈希表,迭代器遍历是无序+去重。
int main()
{
//迭代器遍历有序+去重
set<int> s = { 5,4,2,6,8,5,6,9,7,4,2,3,1 };
set<int>::iterator sit = s.begin(); //双向迭代器
while (sit != s.end())
{
cout << *sit << " "; //1 2 3 4 5 6 7 8 9
++sit;
}
cout << endl;
//迭代器遍历无序+去重
unordered_set<int> us = { 5,4,2,6,8,5,6,9,7,4,2,3,1 };
unordered_set<int>::iterator usit = us.begin(); //单向迭代器
while (usit != us.end())
{
cout << *usit << " "; //5 4 2 6 8 9 7 3 1
++usit;
}
cout << endl;
return 0;
}
- unordered_set和set的第三个差异是性能的差异,整体而言大多数场景下,unordered_set的增删
查改更快一些而更常用,因为红黑树增删查改效率是O(logN) ,而哈希表增删查平均效率是O(1) ,O(logN) 与O(1)差距不大。具体可以参看下面代码的演示的对比差异。
void test_set()
{
const size_t N = 1000000;
unordered_set<int> us;
set<int> s;
vector<int> v;
v.reserve(N);
srand(time(0));
for (size_t i = 0; i < N; ++i)
{
//v.push_back(rand()); //N比较大时,重复值比较多
v.push_back(rand() + i); //重复值相对少
//v.push_back(i); //没有重复,有序
}
size_t begin1 = clock();
for (auto e : v)
{
s.insert(e);
}
size_t end1 = clock();
cout << "set insert:" << end1 - begin1 << endl;
cout << "set插入数据个数:" << s.size() << endl << endl;
size_t begin2 = clock();
us.reserve(N);
for (auto e : v)
{
us.insert(e);
}
size_t end2 = clock();
cout << "unordered_set insert:" << end2 - begin2 << endl;
cout << "unordered_set插入数据个数:" << s.size() << endl << endl;
int m1 = 0;
size_t begin3 = clock();
for (auto e : v)
{
auto ret = s.find(e);
if (ret != s.end())
{
++m1; //找到:次数+1
}
}
size_t end3 = clock();
cout << "set find:" << end3 - begin3 << " -> " << m1 << endl;
int m2 = 0;
size_t begin4 = clock();
for (auto e : v)
{
auto ret = us.find(e);
if (ret != us.end())
{
++m2; //找到:次数+1
}
}
size_t end4 = clock();
cout << "unorered_set find:" << end4 - begin4 << " -> " << m2 << endl << endl;
size_t begin5 = clock();
for (auto e : v)
{
s.erase(e);
}
size_t end5 = clock();
cout << "set erase:" << end5 - begin5 << endl;
size_t begin6 = clock();
for (auto e : v)
{
us.erase(e);
}
size_t end6 = clock();
cout << "unordered_set erase:" << end6 - begin6 << endl << endl;
}
int main()
{
test_set();
return 0;
}

二.unordered_map
1.unordered_map和map的使用差异
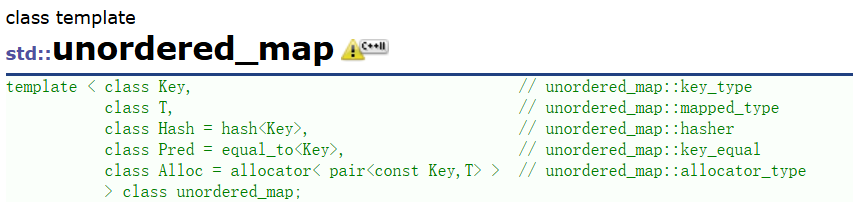
-
查看文档我们会发现unordered_map的支持增删查且跟map的使用一模一样,关于使用我们这里就不再赘述和演示了。
-
unordered_map和map的第一个差异是对key的要求不同,map要求Key支持小于比较,而
unordered_map要求Key支持转成整形且⽀持等于比较,要理解unordered_map的这个两点要求
得后续我们结合哈希表底层实现才能真正理解,也就是说这本质是哈希表的要求。 -
unordered_map和map的第⼆个差异是迭代器的差异,map的iterator是双向迭代器,
unordered_map是单向迭代器,其次map底层是红黑树,红黑树是⼆叉搜索树,走中序遍历是有
序的,所以map迭代器遍历是Key有序+去重。而unordered_map底层是哈希表,迭代器遍历是
Key无序+去重。 -
unordered_map和map的第三个差异是性能的差异,整体而言大多数场景下,unordered_map的
增删查改更快一些,因为红黑树增删查改效率是O(logN) ,而哈希表增删查平均效率是O(1)。
三.unordered_multimap/unordered_multiset
- unordered_multimap/unordered_multiset跟multimap/multiset功能完全类似,支持Key冗余。
- unordered_multimap/unordered_multiset跟multimap/multiset的差异也是三个方面的差异,key的要求的差异,iterator及遍历顺序的差异,性能的差异。
multi版本由于Key冗余,所以不支持operator []。
int main()
{
unordered_map<string, string> dict1;
dict1.insert({ "left", "向左" });
dict1.insert({ "left", "离开" }); //插入失败
dict1.insert({ "left", "留下" }); //插入失败
unordered_multimap<string, string>::iterator it1 = dict1.begin();
while (it1 != dict1.end())
{
cout << it1->first << ":" << it1->second << endl;
++it1;
}
cout << endl;
unordered_multimap<string, string> dict2;
dict2.insert({ "left", "向左" });
dict2.insert({ "left", "离开" }); //插入成功
dict2.insert({ "left", "留下" }); //插入成功
unordered_multimap<string, string>::iterator it2 = dict2.begin();
while (it2 != dict2.end())
{
cout << it2->first << ":" << it2->second << endl;
++it2;
}
cout << endl;
return 0;
}

四.unordered_map/unordered_set的哈希相关接口

Buckets和Hash policy系列的接口分别是跟哈希桶和负载因子相关的接口,日常使用的角度我们不需
要太关注,需要结合哈希表底层,才能明白。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【C++标准模版库】unordered_map和unordered_set的介绍及使用

发表评论 取消回复