原理
基础概念
决策树属于判别模型。
决策树算法属于监督学习方法。
决策树是一种树状结构,通过做出一系列决策(选择)来对数据进行划分,这类似于针对一系列问题进行选择。
决策树的决策过程就是从根节点开始,测试待分类项中对应的特征属性,并按照其值选择输出分支,直到叶子节点,将叶子节点的存放的类别作为决策结果。
决策树算法是一种归纳分类算法,它通过对训练集的学习,挖掘出有用的规则,用于对新数据进行预测。
决策树归纳的基本算法是贪心算法,自顶向下来构建决策树。
在决策树的生成过程中,分割方法即属性选择的度量是关键。
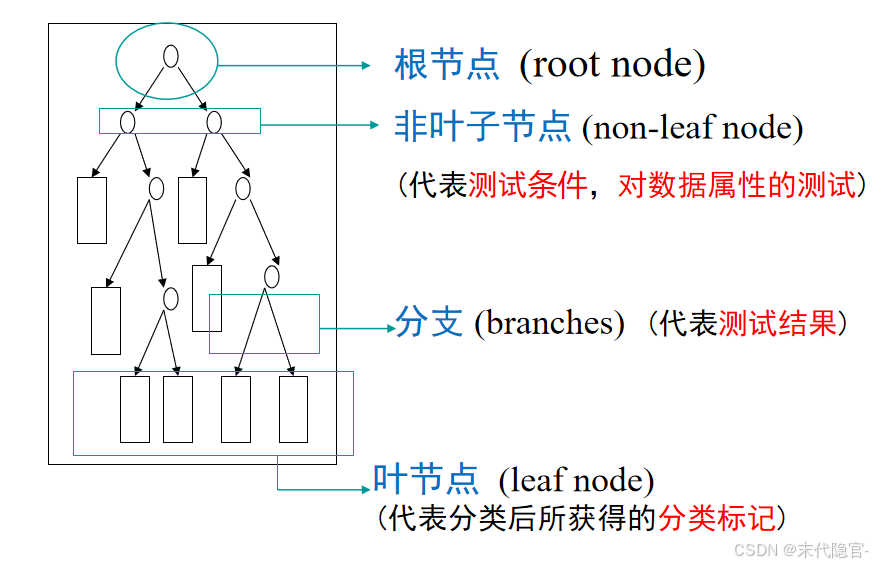
决策树分类
分类树:分类树的目标变量是确定的,分类的。分类树被用来去预测不同的类别。图1就是一个简单的分类树的例子,我们的目标预测为是否选择作为男朋友。分类树不局限于二元分类,多元分类也是可行的。
回归树:回归树就是当目标变量是数值的时候。举一个例子,比如你想预测一个房子的卖价,这就是一个连续的数值变量。
决策树的特点
优点:
推理过程容易理解,计算简单,可解释性强。
比较适合处理有缺失属性的样本。
可自动忽略目标变量没有贡献的属性变量,也为判断属性变量的重要性,减少变量的数目提供参考。
缺点:
容易造成过拟合,需要采用剪枝操作。
忽略了数据之间的相关性。
对于各类别样本数量不一致的数据,信息增益会偏向于那些更多数值的特征。
决策树的三种基本类型
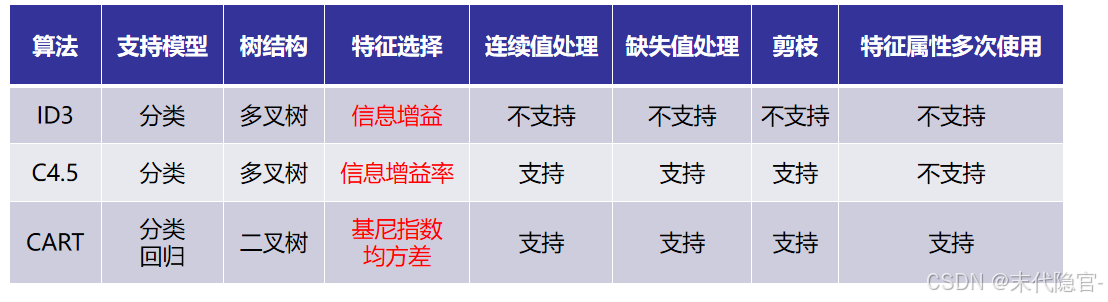
ID3算法
基础概念
ID3 算法是以信息论为基础,以信息增益为衡量标准,从而实现对数据的归纳分类。
在信息论中,期望信息越小(熵),那么信息增益就越大,从而纯度就越高。ID3算法的核心思想就是以信息增益来度量属性的选择,选择分裂后信息增益最大的属性进行分裂。该算法采用自顶向下的贪婪搜索遍历可能的决策空间; 在信息增益中,重要性的衡量标准就是看特征能够为分类系统带来多少信息,带来的信息越多,该特征越重要。
ID3算法的做法是每次选取当前最佳的特征来分割数据,并按照该特征的所有可能取值来切分。
算法步骤
其大致步骤为:
1.初始化特征集合和数据集合。
2.计算数据集合信息熵和所有特征的条件熵,选择信息增益最大的特征作为当前决策节点。
3.更新数据集合和特征集合(删除上一步使用的特征,并按照特征值来划分不同分支的数据集合)。
4.重复 2,3 两步,若子集值包含单一特征,则为分支叶子节点。
信息熵
ID3算法使用信息增益为准则来选择划分属性,"信息熵"是度量样本结合纯度的常用指标,集合信息的度量方式称为香农熵或者简称为熵,这个名字来源于信息论之父克劳德·香农。熵定义为信息的期望值。在信息论与概率统计中,熵是表示随机变量不确定性的度量。在明确熵的概念之前,我们需要知道信息的定义,如果待分类的事物可能划分在多个分类之中,则符号的信息定义为 :

通过上式,我们可以得到所有类别的信息。香农用信息熵的概念来描述信息源的不确定程度。信息熵越大,不纯度越高,即不确定性越大;信息熵越小,纯度越高。
信息熵的公式如下:

进一步理解,根据公式

条件熵
原概念
H(Y|X)表示在已知随机变量 X 的条件下随机变量 Y 的不确定性。
条件熵 H(Y|X)定义为 X 给定条件下 Y 的条件概率分布的熵对 X 的数学期望:

在ID3算法中的条件熵


A是特征,i是特征取值, 
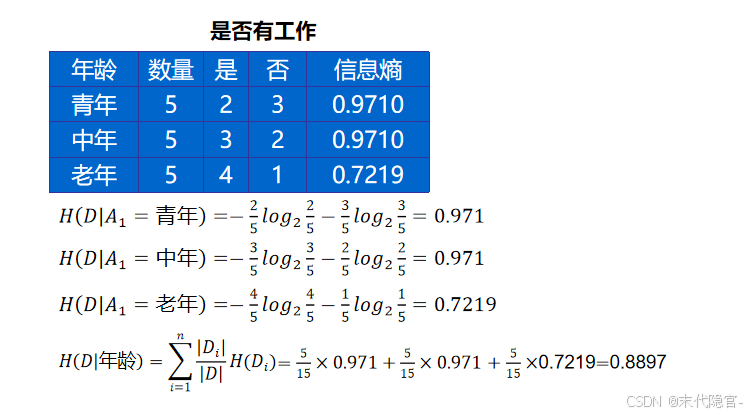
信息增益
信息熵:表示随机变量的不确定性。 条件熵:在一个条件下,随机变量的不确定性。信息增益代表了在一个条件下,信息复杂度(不确定性)减少的程度。信息增益是相对于特征而言的。
信息增益:信息熵 - 条件熵。表示在一个条件下,信息不确定性减少的程度。 如果选择一个特征后,信息增益最大(信息不确定性减少的程度最大),那么我们就选取这个特征。即表示由于该特征使得对数据集的分类的不确定性减少的程度。
信息增益偏向取值较多的特征。即当特征的取值较多时,根据此特征划分更容易得到纯度更高的子集,因此划分之后的熵更低,由于划分前的熵是一定的,因此信息增益更大,因此信息增益偏向取值较多的特征。
信息增益越大,表示使用该属性划分样本集D的效果越好,因此ID3算法在递归过程中,每次选择最大信息增益的属性作为当前的划分属性。
ID3算法缺点
缺点 ID3 没有剪枝策略,容易过拟合;
信息增益准则对可取值数目较多的特征有所偏好,因为更多取值情况代表了树要分裂非常多的叶子结点,并且每个叶子结点上的样本数很少,越小的数据自己其"纯度"显然越容易高,导致了信息增益会很大;
只能用于处理离散分布的特征并且只能处理分类问题;
没有考虑缺失值;
训练决策树通常是很耗时间的,因为熵计算比较耗时。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 决策树(1)

发表评论 取消回复