【ViT】对图片进行分类(论文复现)
本文所涉及所有资源均在传知代码平台可获取
概述
Transformer架构虽然已经成为自然语言处理任务的标准,但是它在计算机视觉的应用仍然有限,先前的视觉任务中,注意力大多与卷积结合使用。ViT模型的出现,证明了对CNN的依赖是不必要的,直接应用于图像补丁序列的纯Transformer架构可以在图像分类任务中表现良好
模型结构
模型总体框架
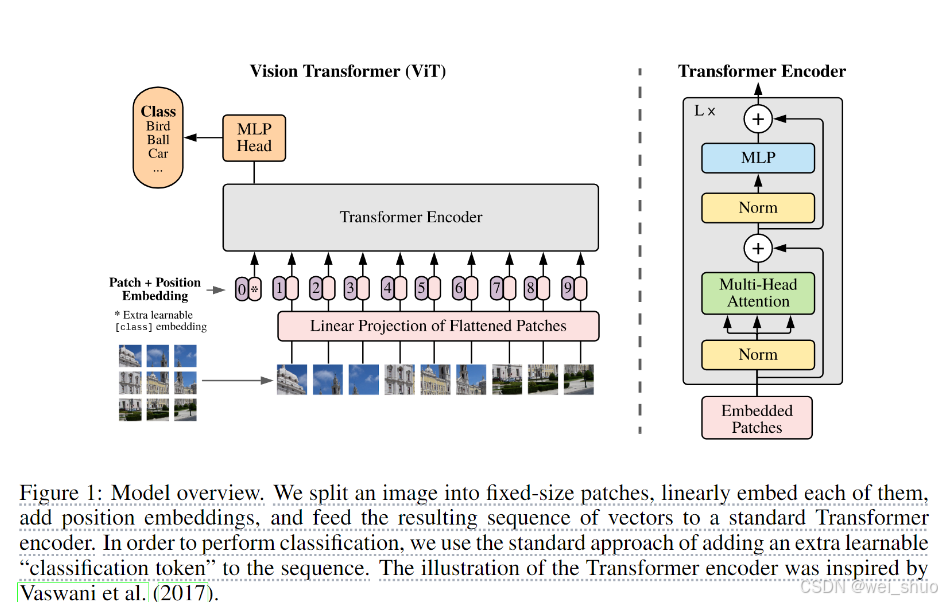
上述是ViT模型的基本框架,可以大致分为三个主要部分
- Patch_embed(将图片分成一系列的patches
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【ViT】对图片进行分类(论文复现)

发表评论 取消回复