一、软硬链接
见一见
-
软连接

-
硬连接
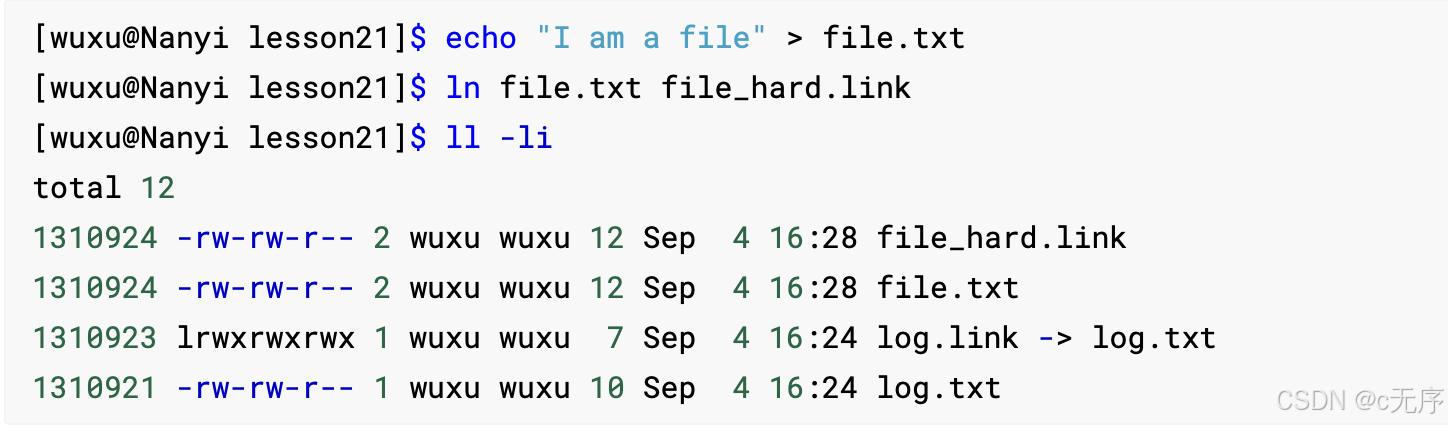
通过观察我们发现以下几点:
1.ll - i后,软连接形成的文件有指向,并且软连接的Inode编号与对应文件的Inode编号不一样
2.ll - i后,硬连接形成的文件与对应的文件Inode编号一样
3.软连接的硬连接数为1,硬连接的硬连接数为2
特征+作用
-
软连接是一个独立的文件,因为有独立的inode number
软连接的内容:目标文件所对应的路径字符串;也就是我们可以通过cat软连接,就能够打印文件的内容,软连接也就类似于windows中的快捷键,比如桌面看到的软件保存的是其它的路径,在系统中可能你要运行的可执行程序在一个很深的目录下,就可以在较上层的目录中建立软链接。

【问题】我们把软连接删除了会影响目标文件吗?
并不会,因为它们两个是独立的文件;就像小白刚接触电脑一样,卸载软件只是把快捷方式拖到回收站,其实并没有删除软件;但是目标文件删除了,软连接绝对跑不出来的
【软连接的作用】--快速使用文件
我们现在要在外层建立软连接,目标文件在lesson21内部,测试发现通过cat外层的软连接,也可以打印文件里的内容

在系统中 ll /usr/lib64有很多库,包括动态库静态库等,我们就可以发现这里有很多软连接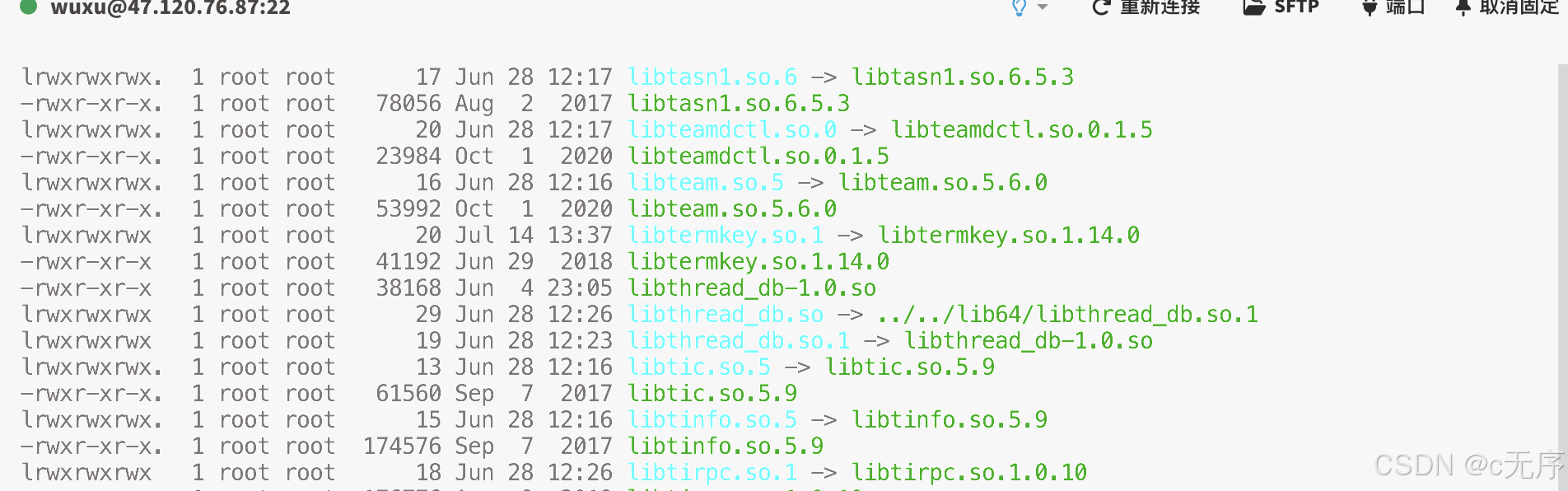
-
硬连接不是一个独立的文件,因为它没有独立的inode number,它用的是目标文件的inode
硬连接(Hard Link)是一种特殊的文件系统特性,它允许用户创建多个指向同一inode(索引节点)的文件名。硬连接使得一个文件可以有多个名称,每个名称都指向文件系统的同一数据块集合。
硬连接的创建和删除:
-
创建硬连接:使用
ln命令可以创建硬连接,例如ln -s 原始文件 硬连接文件。 -
删除硬连接:要删除硬连接,需要删除原始文件或所有指向同一inode的硬连接。例如,使用
rm 硬连接文件可以删除硬连接,但如果原始文件仍然存在,硬连接文件会重新创建。
硬连接的特点:
-
inode共享:硬连接允许多个文件名指向同一inode。这意味着,对于硬连接文件,只有原始文件(即创建硬连接的文件)的inode会被删除或重命名,其他硬连接文件仍然有效。
-
文件内容共享:由于硬连接共享相同的inode,它们共享文件的所有数据块。这意味着,对其中一个硬连接文件进行的修改会立即反映在所有硬连接文件上。
-
不可跨文件系统:硬连接必须在同一文件系统中创建,因为inode是文件系统内部的唯一标识。
-
不可跨目录:硬连接不能跨目录创建,每个硬连接必须位于原始文件的目录内。
-
无法创建到目录:硬连接不能创建到目录,因为目录的inode包含了指向子目录和文件的指针,而不是文件的数据。
-
文件删除限制:删除原始文件不会删除其他硬连接文件,因为它们共享同一个inode。要删除所有硬连接文件,必须先删除所有硬连接。
硬连接的用途:
-
文件备份:通过创建硬连接,可以创建文件的备份,而不需要复制文件的内容。
-
链接文件:在某些情况下,硬连接可以用来创建多个文件名指向同一数据,例如,在文件名发生冲突时,可以创建一个硬连接来指向正确的文件。
-
目录管理:硬连接可以用来简化目录结构,例如,在目录中创建一个指向主目录的硬连接,以方便访问。
【知识点】关于文件属性硬连接数
硬连接数(Hard Link Count)是指一个文件系统中某个inode(索引节点)所拥有的硬连接数量。每个inode在文件系统中都是唯一的,它用于存储文件或目录的元数据和指向数据块的指针。硬连接数是指有多少个文件名指向这个inode。
硬连接数与文件删除行为有关:
-
硬连接数减少:当一个硬连接被删除时,指向该inode的硬连接数会减少。如果原始文件(即创建硬连接的文件)的硬连接数降至零,那么该文件及其数据块将被删除。
-
文件删除限制:即使原始文件被删除,只要还有其他硬连接指向该inode,文件的数据块就不会被删除。这是因为文件系统认为文件仍然在使用中,因此不能释放其数据块。
-
硬连接数限制:不同的文件系统可能有不同的硬连接数限制。例如,某些文件系统可能不允许创建超过一定数量的硬连接。
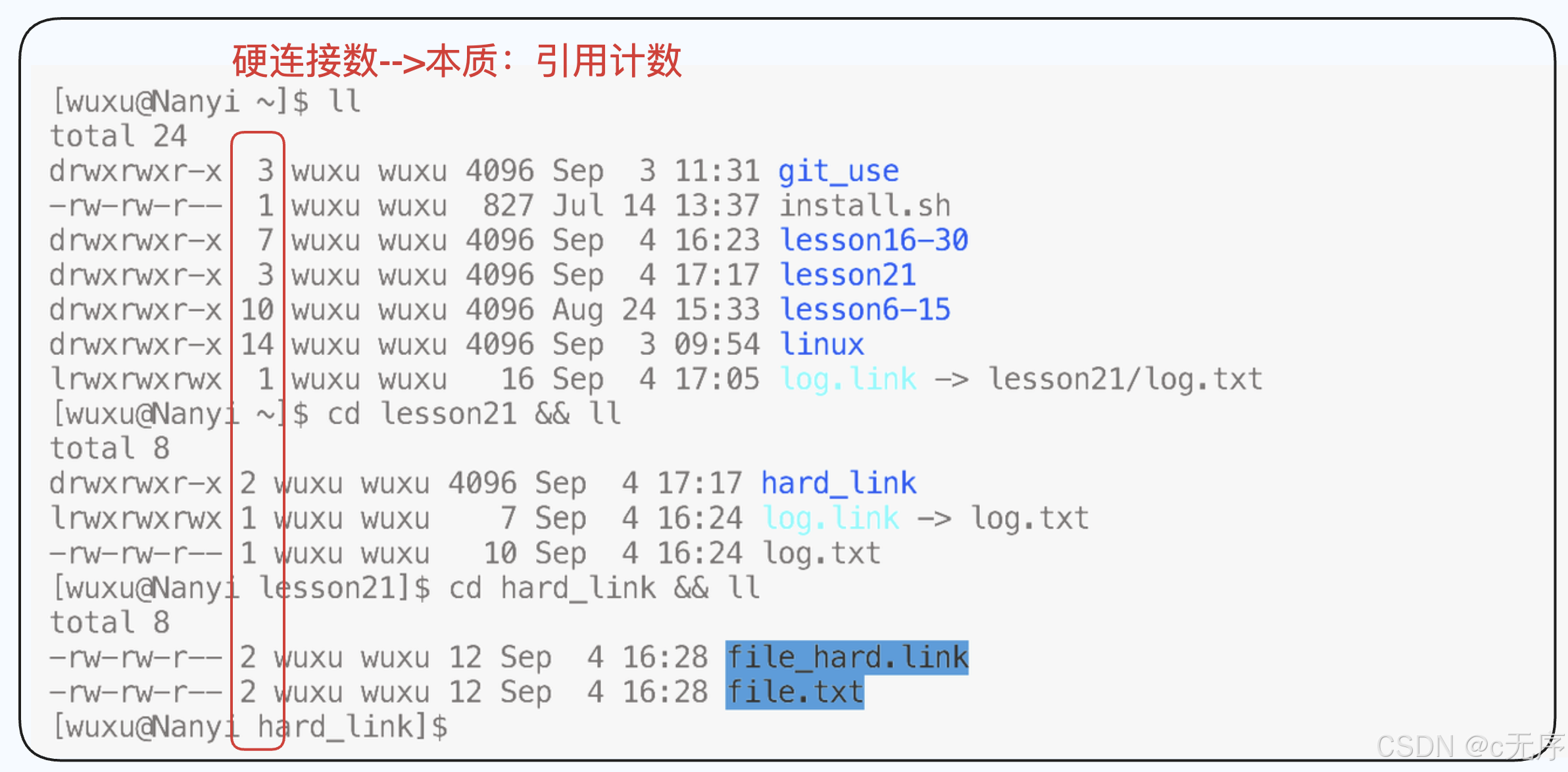
我们先看hard_link中file_hard.link 与 file.txt的硬连接数为2,这就说明这两个文件指向的是同一块空间,通过两个任意一个文件都可以访问这块空间。
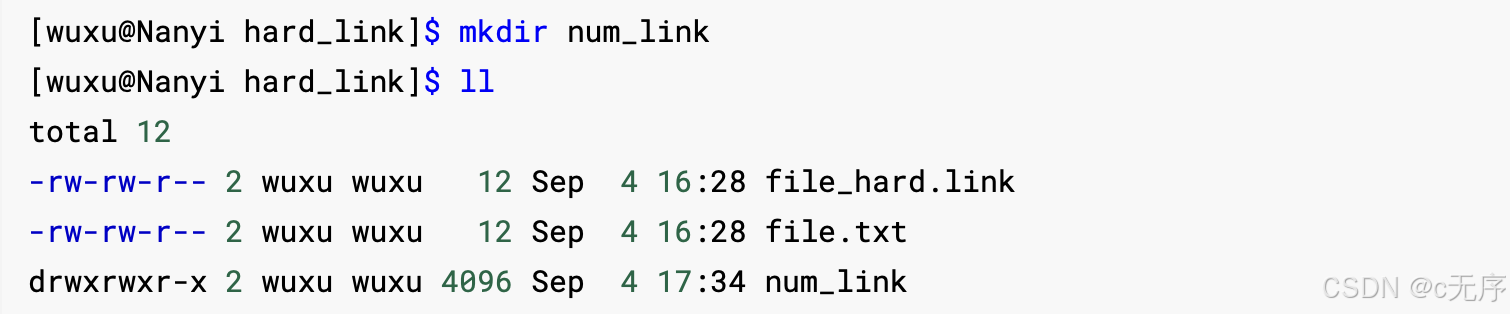
我们此时再创建一个目录,发现目录的硬连接数为2这是为什么呢?
因为一个目录中有隐藏文件,隐藏文件分别是 .当前路径 ..上级目录,正是因为有这两个隐藏文件,我们才可以使用cd..,也就是说任何一个目录,刚开始新建的时候,引用计数一定是2
当前目录下新建一个目录,上级目录的硬连接数会增加,因为新目录的名称指向了上级目录的inode。
目录A内部,新建一个目录,会让A目录的引用计数自动+1,一个目录内部有几个目录:A引用计数-2
注意:在Linux系统中,不允许给目录建立硬连接,目的是为了避免形成路径环绕
二、动静态库
在Linux操作系统中,库文件(Library)分为动态库(Dynamic Libraries)和静态库(Static Libraries)。它们是共享代码和资源的方式,用于在编译和运行时提供给应用程序使用。
-
动态库(Dynamic Libraries)
动态库在运行时加载,它们通常以.so(在Linux上)或.dll(在Windows上)为扩展名。动态库的好处是它们可以在程序运行时被动态加载,这意味着应用程序不需要将库代码包含在可执行文件中,从而减小了可执行文件的大小。
动态库的使用步骤如下:
-
编译时链接:在编译应用程序时,链接器(Linker)会查找动态库的路径,并链接到相应的库文件。
-
运行时加载:当应用程序运行时,操作系统会动态加载指定的动态库,并将其内容加载到内存中。
-
链接器处理:链接器会处理动态库的链接信息,并将相应的函数和数据映射到应用程序的内存空间。
-
内存管理:动态库的内容被加载到内存中,应用程序可以直接调用库中的函数。当应用程序结束时,操作系统会负责释放动态库占用的内存。
-
静态库(Static Libraries)
静态库在编译时链接,它们通常以.a为扩展名。静态库将库代码直接包含在可执行文件中,这使得可执行文件的大小变大,但好处是应用程序不需要在运行时动态加载库,从而提高了运行效率。
静态库的使用步骤如下:
-
编译时链接:在编译应用程序时,链接器会将静态库的内容直接包含到可执行文件中。
-
运行时加载:由于静态库已经被包含在可执行文件中,因此应用程序不需要在运行时动态加载库。
-
内存管理:静态库的内容被包含在可执行文件中,应用程序可以直接调用库中的函数。当应用程序结束时,静态库占用的内存与可执行文件一起被释放。
静态库的制作打包与使用
【故事引入】
张三是一名学霸,李四是位学渣;现在老师要求自己写一个math库和print库并且能够实现;李四什么也不会,于是就找张三说:“张三,这份作业你帮我做呗,你把代码给我,我请你吃顿饭”;张三一想:这个可以唉,但是如果我把我的源代码给了李四,老师一看就知道我们两个作业是一样的,于是张三将几个.c代码实现的文件,打包成库,复制给李四,然后教李四怎么调用这个库文件,于是这个作业就这样过去了
下面是张三的文件和代码


生成静态库
-
gcc -c mymath.c -o mymath.o / gcc -c myprint.c -o myprint.o

先讲源文件汇编后盛出.o文件,但是它还不能运行,因为还差最后一步链接;
-
ar -rc libwork.a mymath.o myprint.o
ar(Archiver)是一个用于创建和维护静态库的工具,它通常与GNU Binutils工具集一起提供。ar命令允许您创建新的静态库、修改现有库、提取库中的文件、列出库中的内容等。
指令
ar -rc libwork.a mymath.o myprint.o的解释如下:
ar:这是Archiver命令的名称。
-r:这个选项用于增加(add)文件到库文件中。当您使用-r选项时,ar会添加指定的对象文件(.o文件)到库文件中。
-c:这个选项用于创建(create)一个新的库文件。如果您没有指定库文件,ar会创建一个新的库文件。如果您指定了库文件,ar会创建一个新版本的库文件。
libwork.a:这是库文件的名称,.a是静态库文件的扩展名。
mymath.o:这是您想要添加到库文件中的第一个对象文件。
myprint.o:这是您想要添加到库文件中的第二个对象文件。当您运行这个指令时,
ar会创建一个新的库文件(如果它还不存在)或更新现有的库文件。它会将mymath.o和myprint.o这两个.o文件添加到库文件libwork.a中。这些.o文件包含了编译后的C语言代码,当它们被添加到库文件中时,它们会与库文件中的其他.o文件链接,以便在程序中使用。
ps:库文件开头必须以lib开头
-
查看静态库中的目录列表


main.c内容
#include "mymath.h"
#include "myprint.h"
int main(){
Print("hello I am Print\n");
return 0;
}
我们编译发现没有这样的文件或目录,原因就是 mymath.h 既不在当前路径下,也不在默认路径下。所以我们要告诉编译器,你要往哪个地方去找头文件,于是需要加一个选项-I + 指定路径;

此时还有报错,但是与上一次相比,这次我们找到了头文件,但是链接器在尝试链接可执行文件时找不到名为Print的函数,所以还需要在gcc上加入-L + 路径选项,告诉编译器从哪里链接

此时又报错了,这是因为我们指明了库的路径,但是没有指明是哪一个库,万一这里面有几百上千的库总不能让编译器一个一个去找吧,于是后面还需要加上是哪个库,加上--l + 库名称
真正库的名称需要去掉前缀lib和后缀.a

库搜索路径
1.从左到右搜索 -L 指定的目录
2.由环境变量指定的目录(LIBRARY_PATH)
3.由系统指定的目录/usr/lib /usr/local/lib
动态库的打包与使用
依旧是之前的代码和文件

生成动态库
首先,需要分别编译mymath.c和myprint.c文件,生成.o文件
gcc -fPIC -c myprint.c -o myprint.o
gcc -fPIC -c mymath.c -o mymath.o
这里使用到的-PIC是位置无关代码(PIC,Position Independent Code)是一种特殊的编译代码格式,它允许编译器生成的代码在内存中的任何位置执行,而不会产生错误或性能问题。PIC代码的一个关键特性是它不依赖于程序在内存中的加载地址。后续我们介绍原理,这里我们先使用
-
gcc -shared -o libwork.so myprint.o mymath.o
-shared:这是一个选项,告诉编译器创建一个共享库(Shared Object)而不是一个可执行文件。共享库可以在多个程序之间共享,并且可以被动态加载和链接到程序中。
然后打包发给李四

使用动态库
main.c内容
#include "mymath.h"
#include "myprint.h"
int main(){
Print("I am Print()\n");;
printf("%d + %d = %d\n",5,15,add(5,15));
return 0;
}此时我们执行代码

什么情况?怎么还报错,怎么就找不到
我们用ldd查看一下链接情况

这是因为LD_LIBRARY_PATH环境变量的问题:运行可执行文件时,它可能会使用LD_LIBRARY_PATH环境变量来查找库文件。如果这个环境变量没有正确设置,或者它不包含./lib目录,那么可执行文件就无法找到库文件。可以设置LD_LIBRARY_PATH环境变量,或者将其包含在~/.bashrc或~/.bash_profile文件中。
这个是动态库,因为动态库要在程序运行的时候,要找到动态库加载并运行!

这样我们就连到了

静态库为什么没有这个问题??
因为编译期间,已经将库中的代码拷贝到我们的可执行程序内部了!加载和库就没有关系了!
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【Linux-基础IO】软硬链接+动静态库

发表评论 取消回复