推荐系统召回
2.1 ItemCF:基于物品的协同过滤
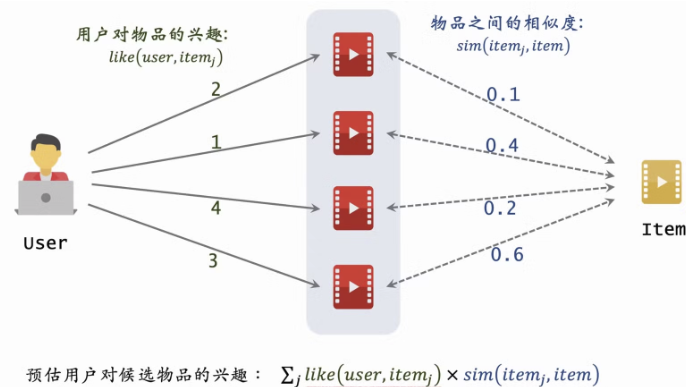

- 这里的 Sim() 不是指物品本身的相似度,而是指喜欢物品的受众群体之间的相似度,上面的公式没有考虑喜欢的程度。
- 考虑喜欢程度公式修改如下:本质是余弦相似度
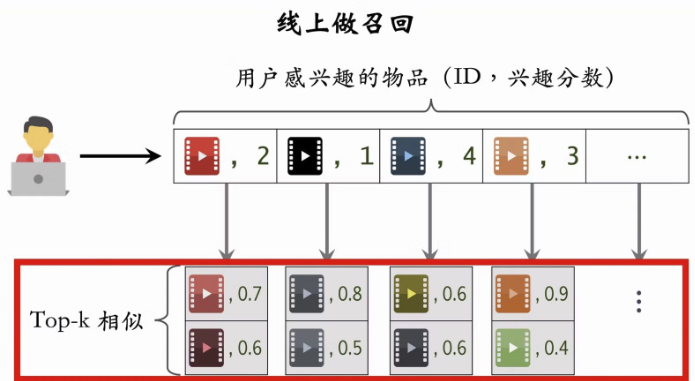
线上环境:
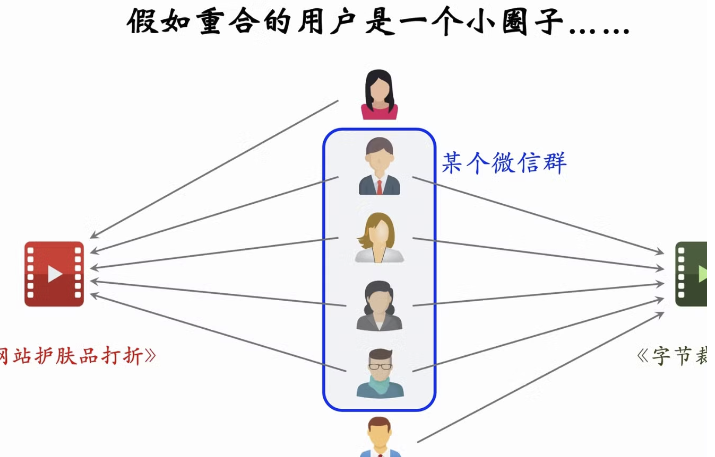
缺点:社群对算法的误导
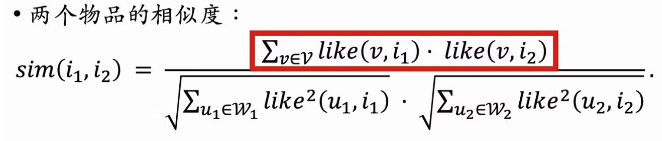


2.2 Swing 召回


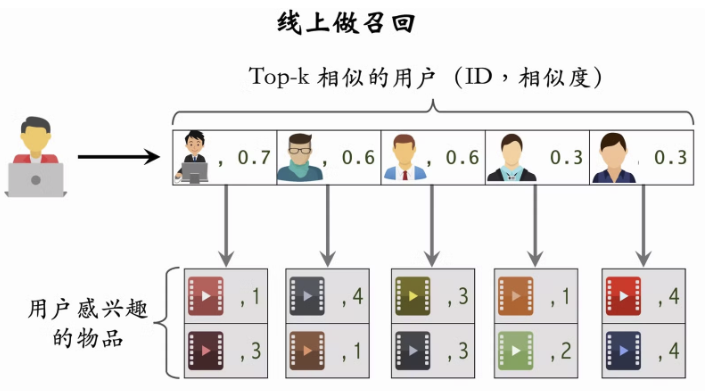
2.3 UserCF: 基于用户的协同过滤
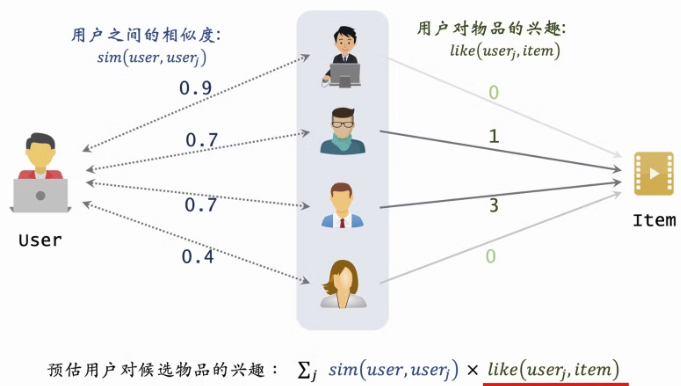

- 缺点:热门的物品无法越无法反应用户的兴趣,需要降低热门物品的权重



2.4 离散特征处理

2.5 矩阵补充



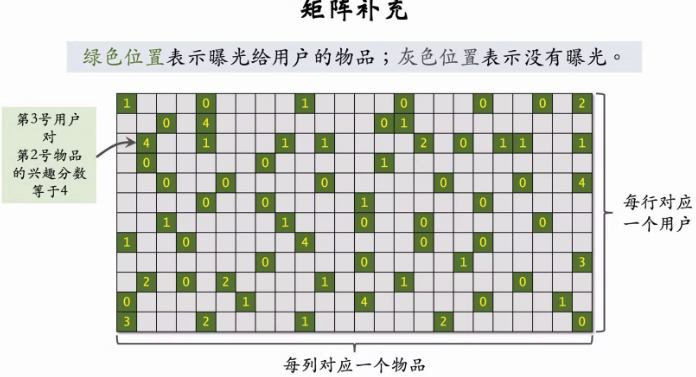
- 矩阵补充方法在实践中效果不好。





- 对向量做归一化,让他们的二范数全都等于1,那么余弦相似度和内积相似度相等。
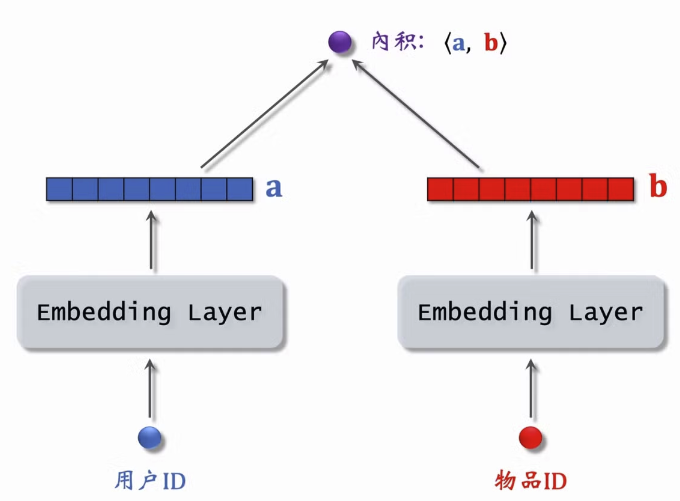
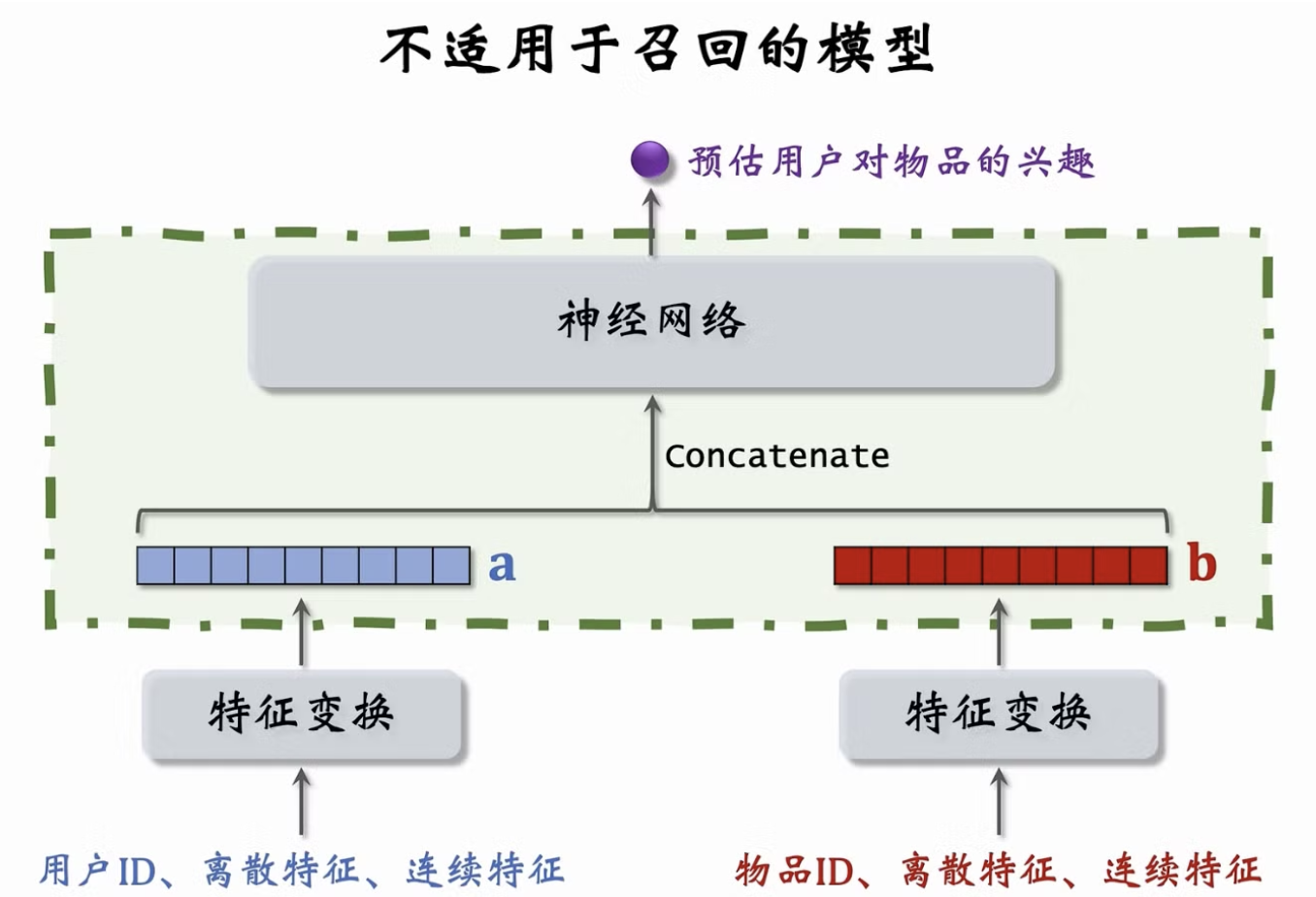
2.6 双塔模型
2.6.1 模型结构
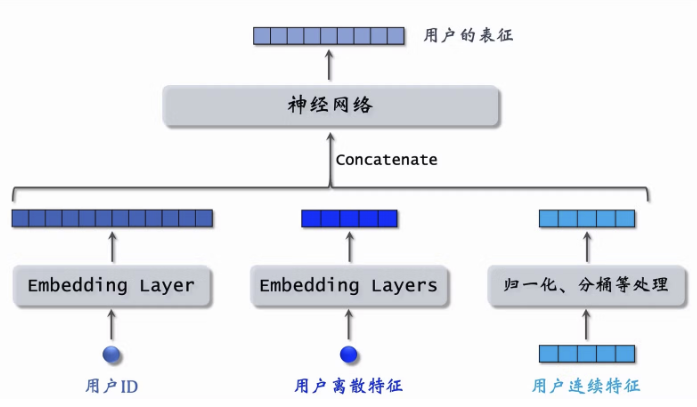
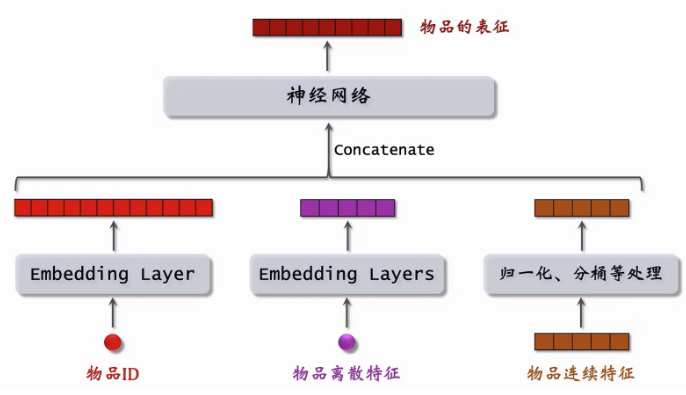
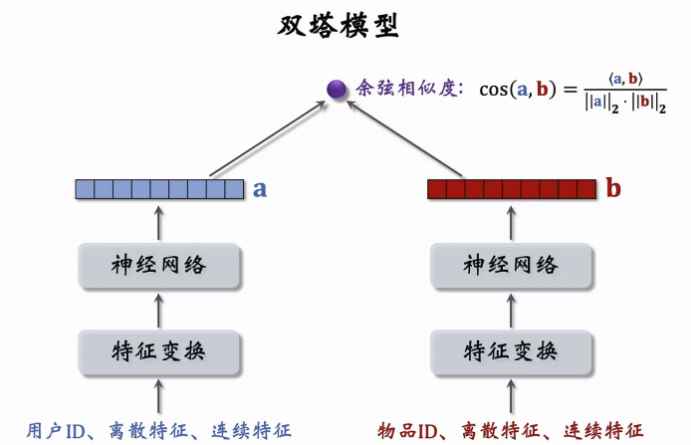
2.6.2 双塔模型的训练

Pointwise 训练

- 这里的1:2或者1:3是经验值。
Pairwise 训练
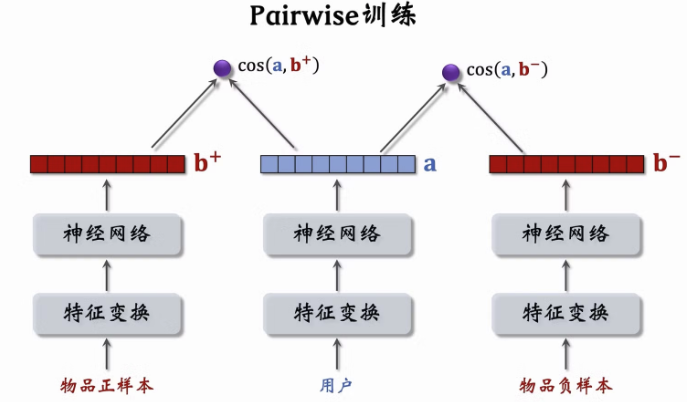

Listwise 训练
【说明】上面有笔误,下面的这行都是“-”

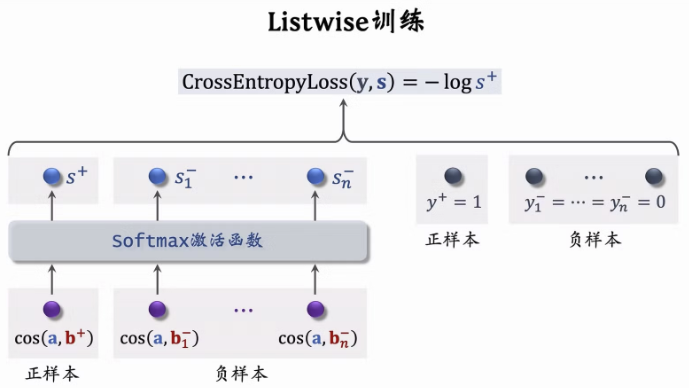
- 之前的召回模型设计是最后一层做后期融合,这里的错误设计在前期就做了融合。这里的计算量太大了(要算预估值的话必须1-1对比才行)。
2.6.3 正负样本

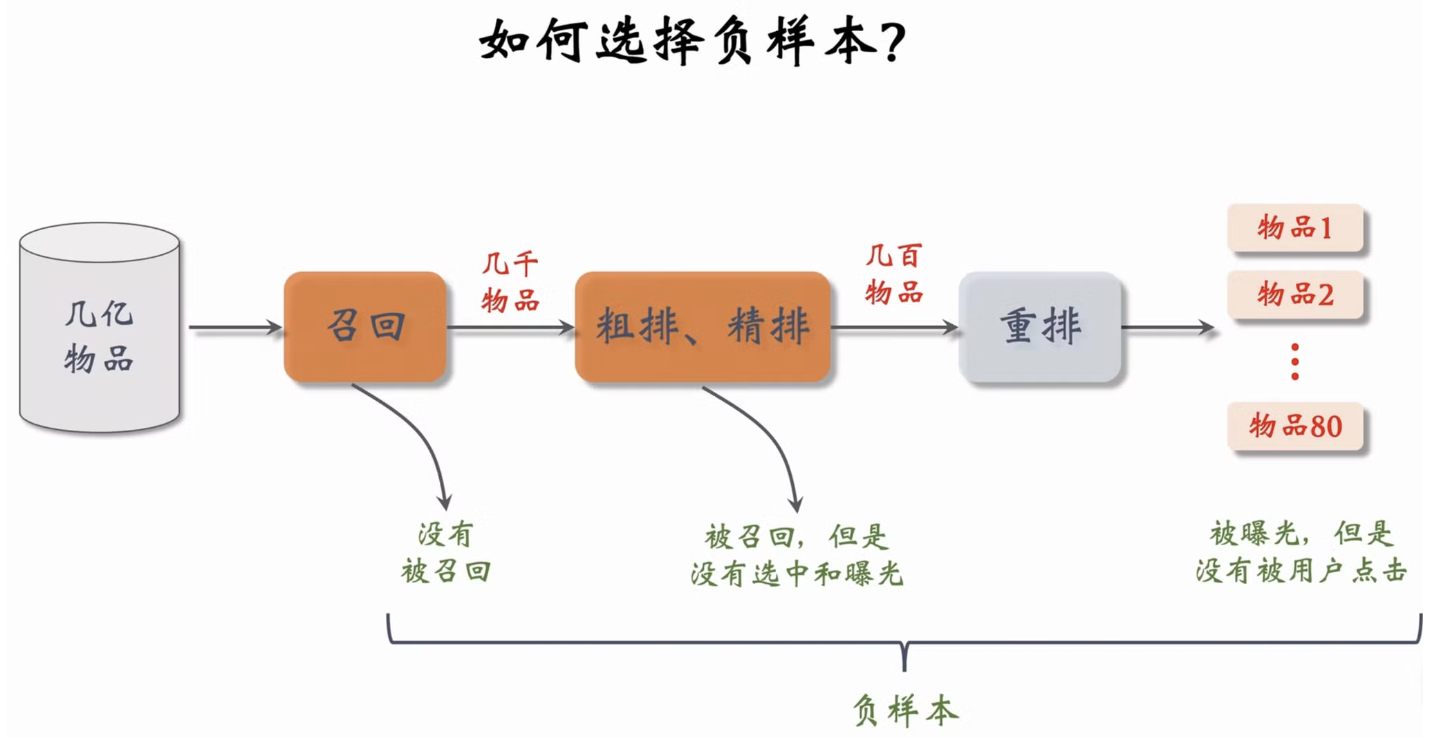
简单负样本


Batch内负样本
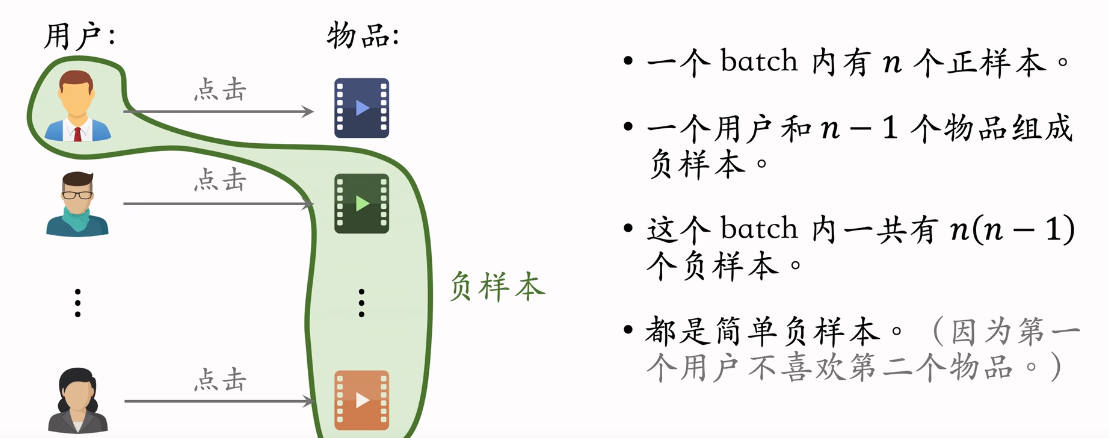


- 在线上做召回的时候不用减掉log p i p_i pi
困难负样本
工业界中的负样本训练数据:

- 混合几种负样本
- 50%的负样本是全体物品(简单负样本)
- 50%的负样本是没通过排序的物品(困难负样本)
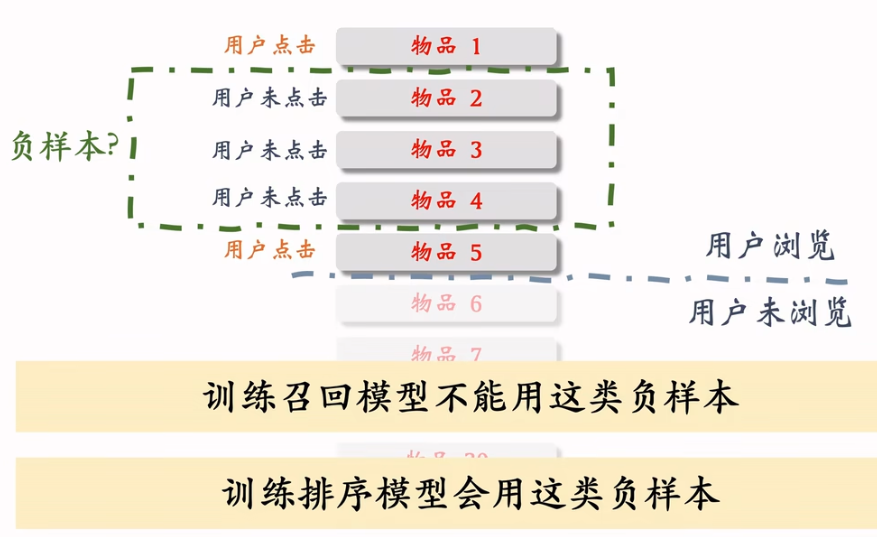
常见错误
- 曝光但未点击的作为负样本

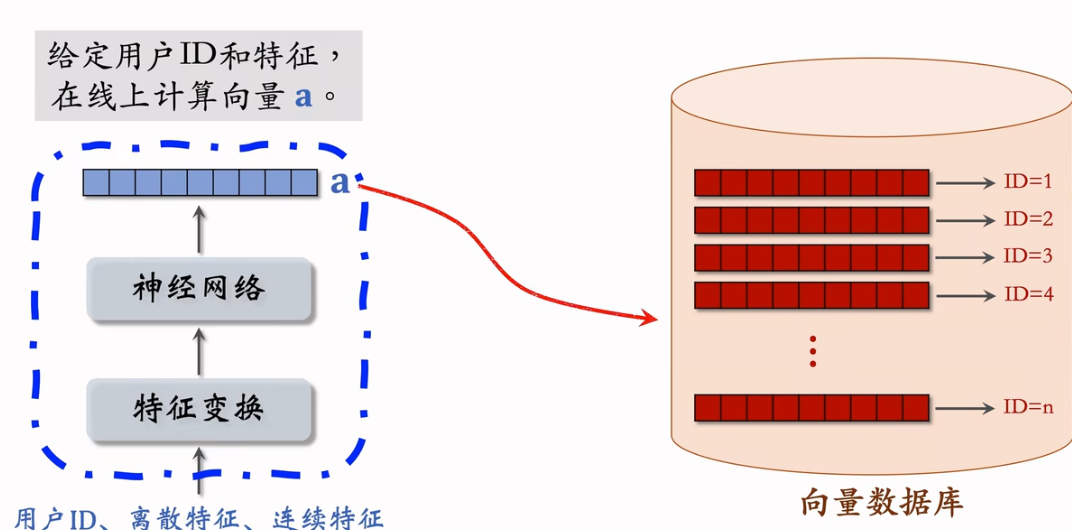
2.6.4 线上召回和模型更新
线上召回

模型更新:全量更新 vs 增量更新


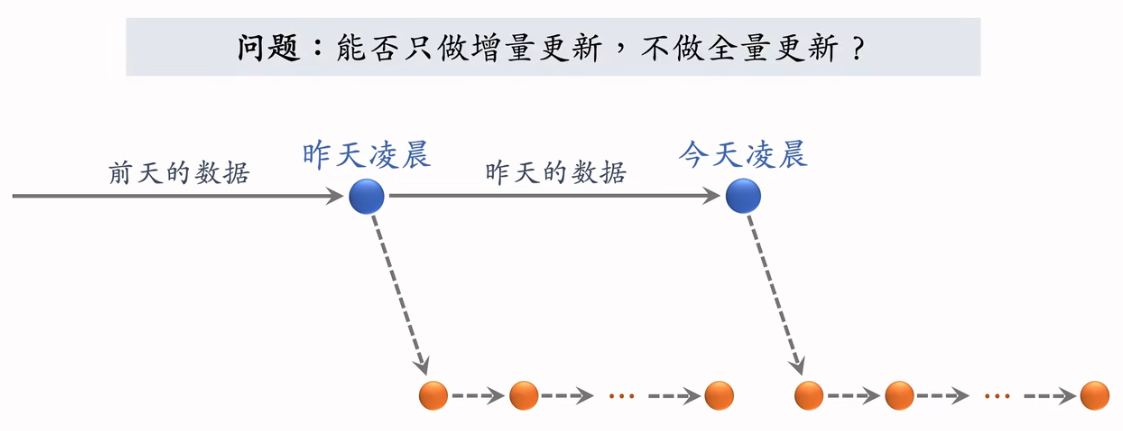
- 增量更新:每隔几十分钟,发布最新的 ID Embedding

2.6.5 双塔模型、自监督学习
自监督的目的是把物品塔训练的更好。
损失函数:
纠偏:
到这里是双塔模型同时训练用户塔和物品塔的过程。

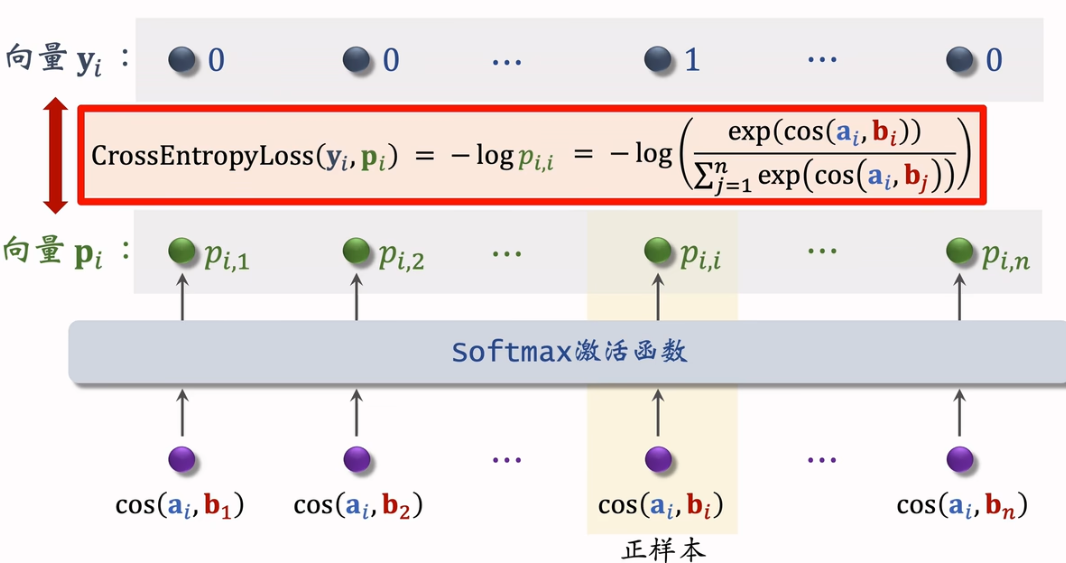


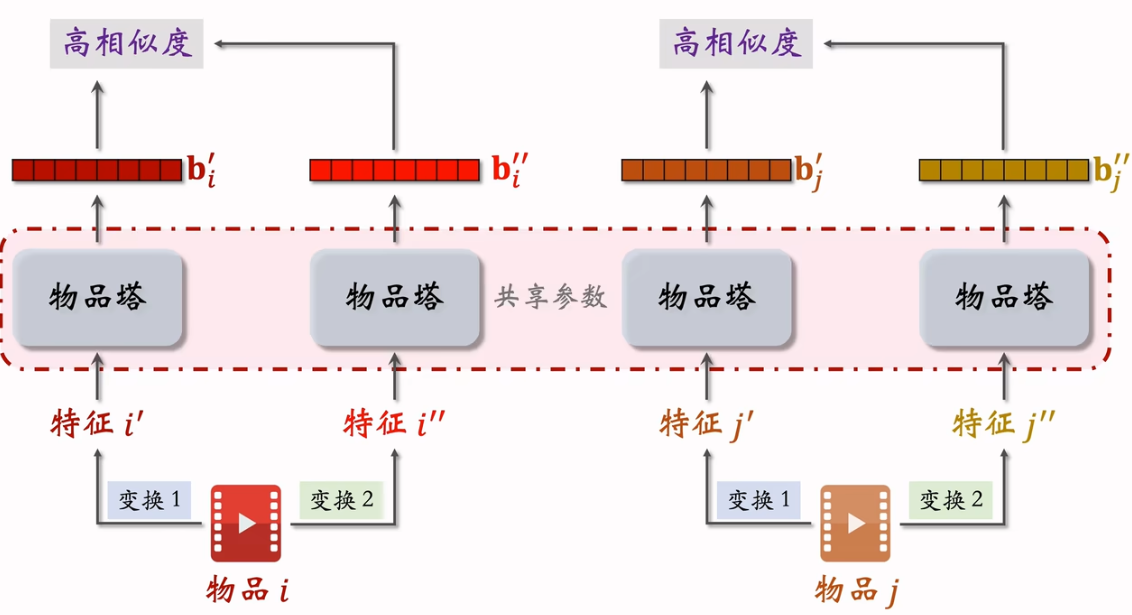
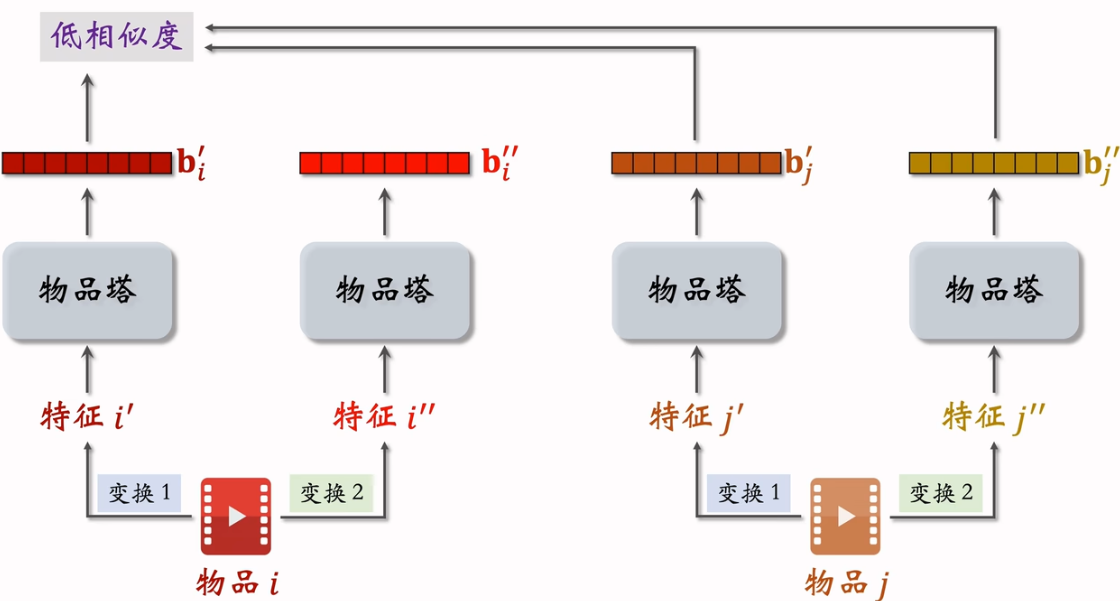





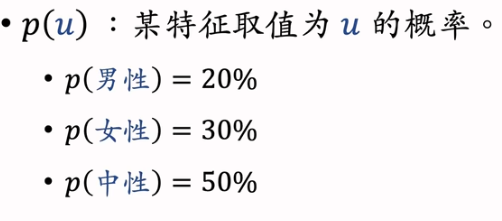



自监督物品塔训练:
/
a
l
p
h
a
/alpha
/alpha: 超参数


2.7 Deep Retrieval 召回


2.7.1 索引
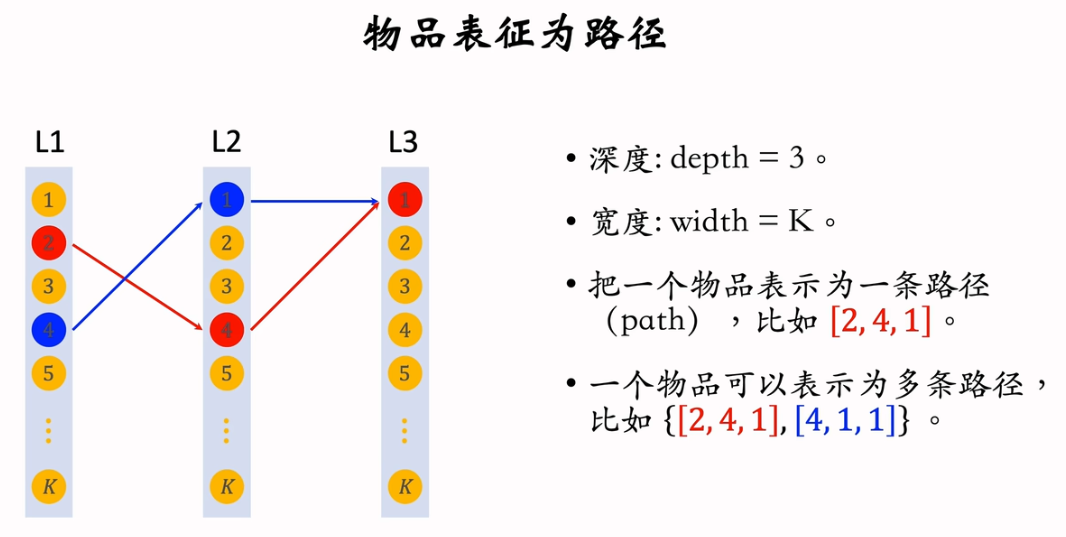

2.7.2 预估模型

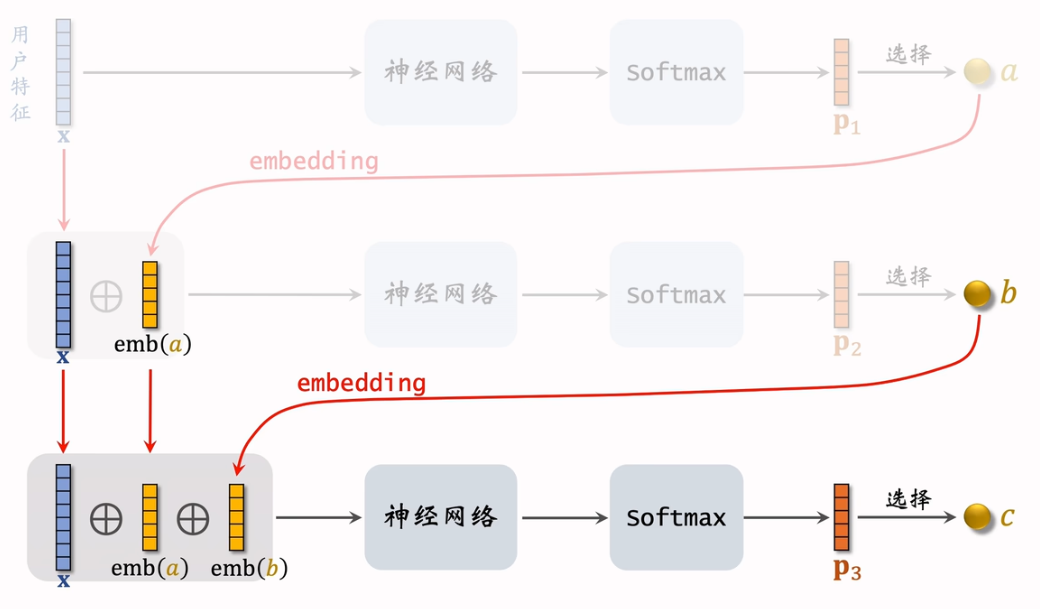
2.7.3 线上召回



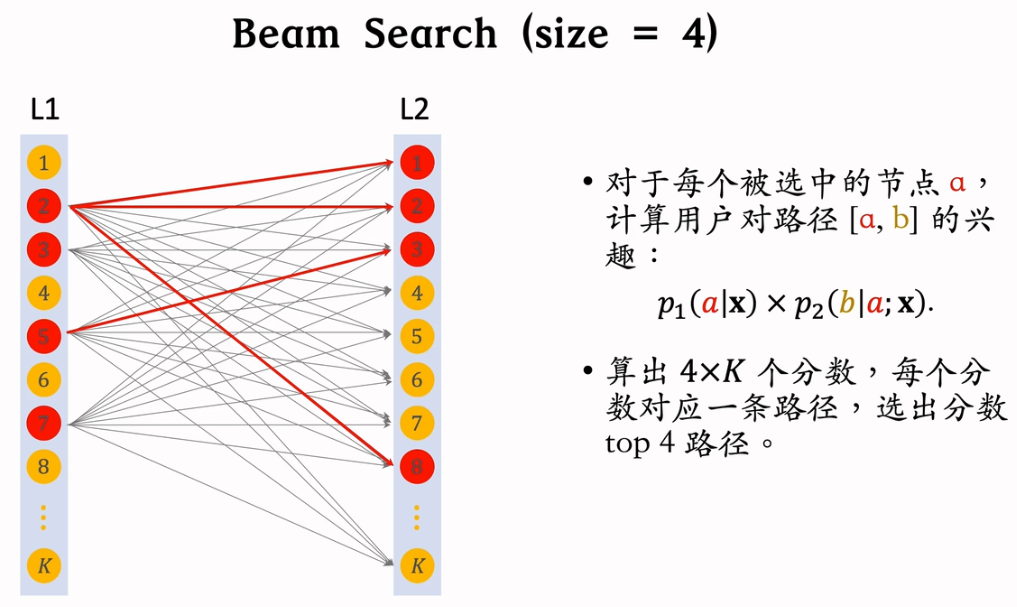
2.7.4 训练






补充几点:
- 双塔使用单向量召回,导致召回结果集中在单个topic上。字节做deep retrieval的目的是多兴趣召回(multi-interest)。deep retrieval召回多条路径,每条路径是一个兴趣点,所以属于multi-interest。
- 据说抖音已经下掉了deep retrieval,因为有了更好的模型。
- 这是抖音实际在用的multi-interest retrieval,建议读一下:Trinity: Syncretizing Multi-/Long-tail/Long-term Interests All in
One
PS:双塔模型也有改进版处理 multi-interest 的情况,多点建模比多边好计算
2.8 其他召回通道:地理位置召回、作者召回、缓存召回
GeoHash 召回

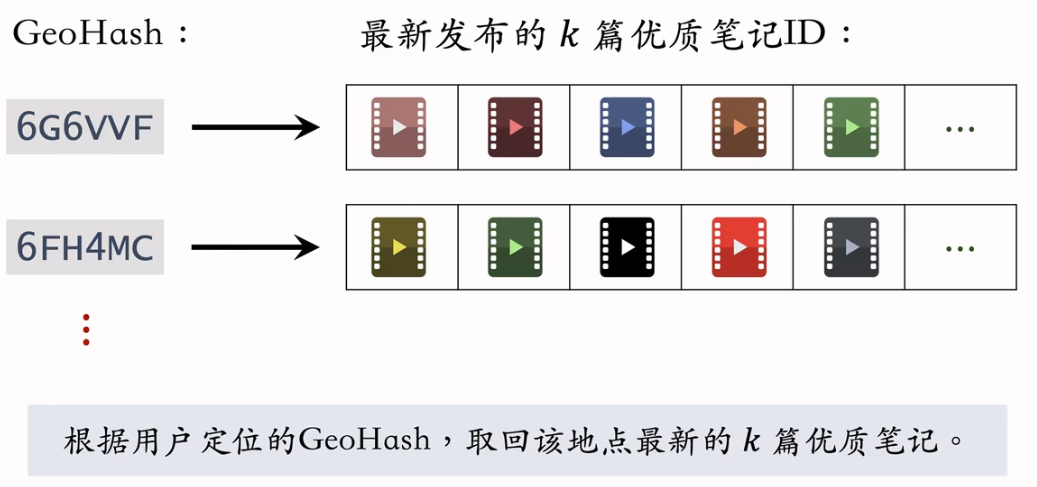
同城召回

作者召回
关注作者召回

交互作者召回

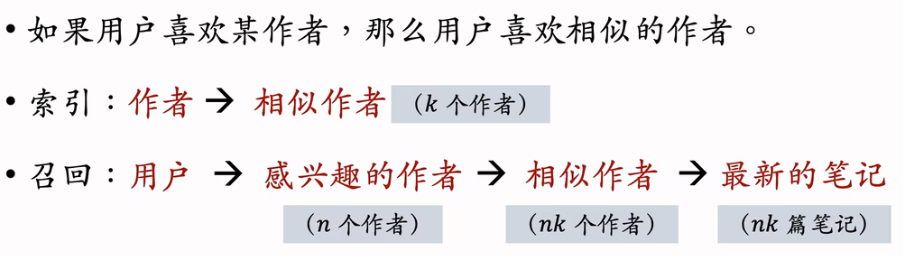
相似作者召回
缓存召回


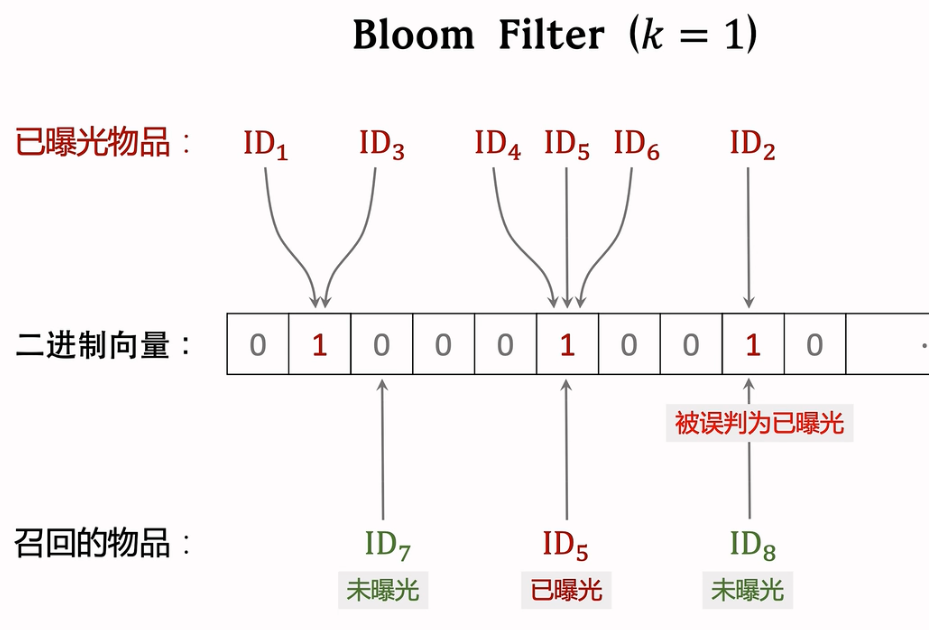
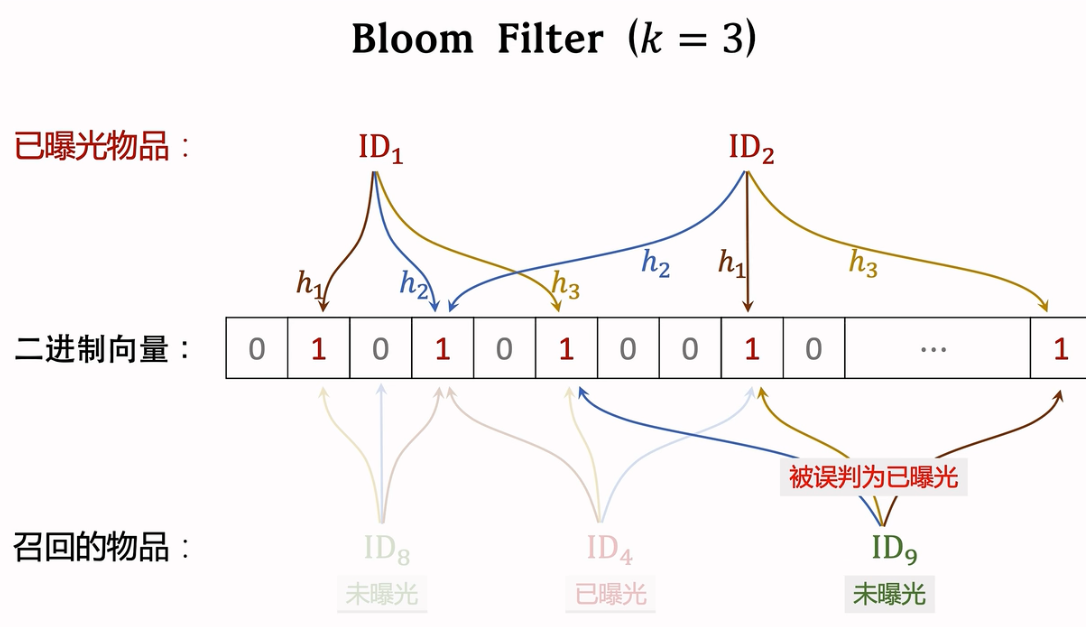
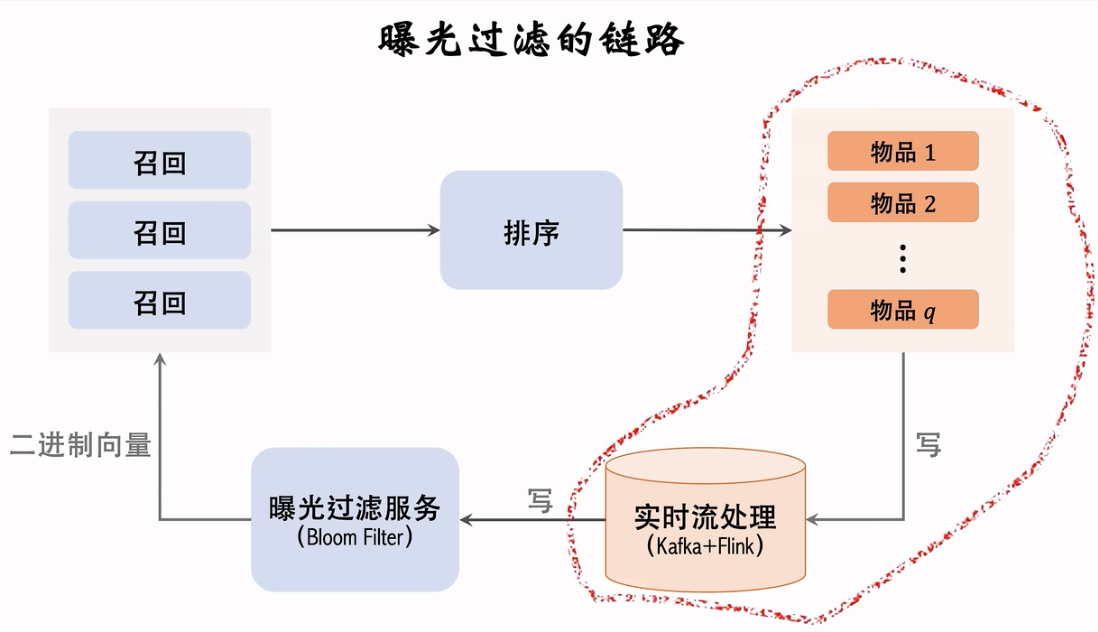
2.9 曝光过滤 & Bloom Filter






本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 推荐系统 # 二、推荐系统召回:协同过滤 ItemCF/UserCF、离散特征处理、双塔模型、自监督学习、多路召回、曝光过滤

发表评论 取消回复