根据尚硅谷哔哩哔哩视频搭建:bilibili.com/video/BV1Qp4y1n7EN/
安装虚拟机教程可参考:VMware虚拟机 安装 Centos7(linux)(新手超详细教程)_vmware安装centos7教程-CSDN博客
集群配置如下:

一、先配置一台虚拟机hadoop101
1‘安装完修改ip
以下内容都在root用户下进行
vim /etc/sysconfig/network-scripts/ifcfg-ens33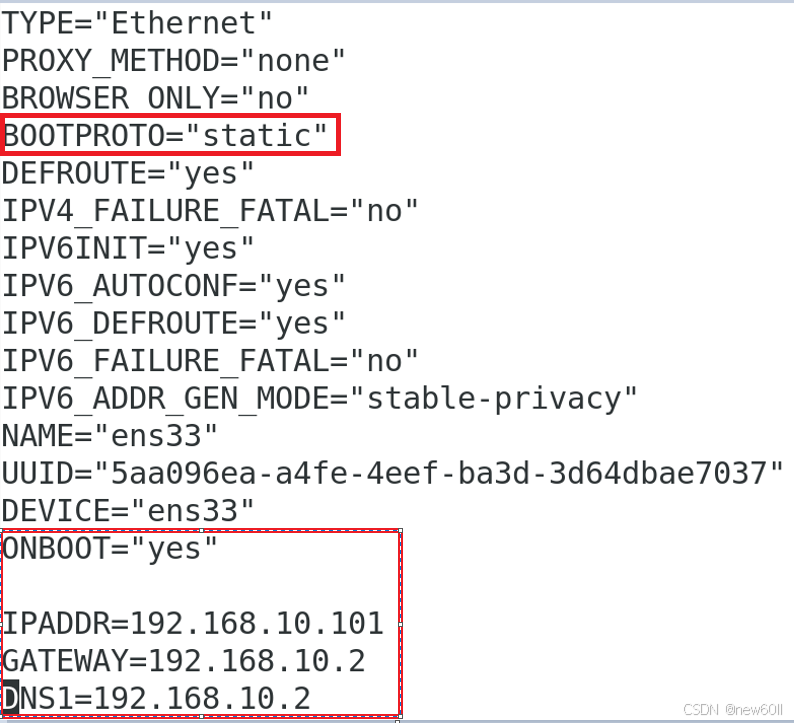
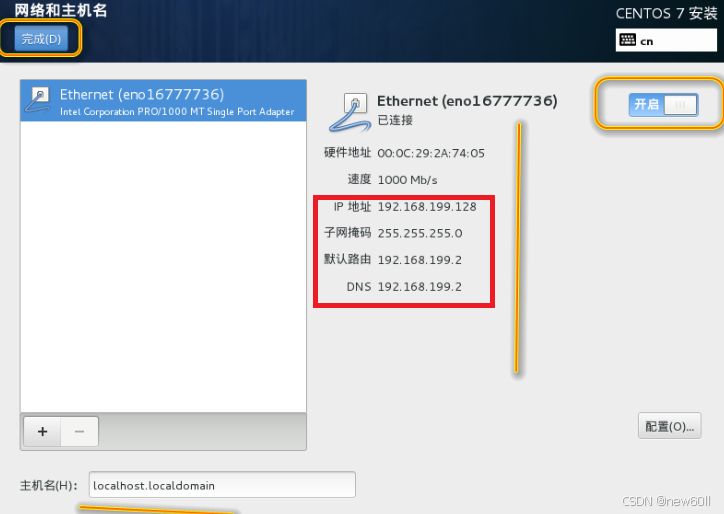
注意: 网络配置不使用虚拟机设置修改就要与安装时一致,ip可以修改
vim /etc/sysconfig/network-scripts/ifcfg-ens33
内容如下:
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="922b4573-63d9-44ae-ac4a-411515a8f4e4"
DEVICE="ens33"
ONBOOT="yes"
IPADDR=192.168.100.10
GATEWAY=与配置的时网卡中的一致
DNS1=与配置的时网卡中的一致注意:本教程安装,将hadoop的相关配置全部配置完毕后再克隆虚拟机,没有使用视频中的分发脚本。
2.修改主机名
vim /etc/hostname内容如下:
hadoop101
3.测试网络是否通畅
ping www.baidu.com4.创建目录
cd /opt
mkdir software
mkdir module
5.卸载系统自带的jdk
查找是否有jdk:
rpm -qa | grep -i java删除jdk:
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps检查是否删除干净:
rpm -qa | grep -i java6.安装jdk
将jdk的包拖入虚拟机

出现的信息即为压缩包所在地址,如果没有出现可能在桌面/home目录下,或者上传不成功。上传不成功再次上传即可。
解压到module目录下和视频中一样:
tar -zxvf /tmp/VMwareDnD/w7eciW/jdk-8u281-linux-x64.tar.gz -C /opt/module删除压缩包:
rm -rf /tmp/VMwareDnD/w7eciW/jdk-8u281-linux-x64.tar.gz进入/opt/module/jdk1.8.0_281
cd /opt/module/jdk1.8.0_281/
ll 进入/etc/profile.d/,配置环境变量
cd /etc/profile.d/
vim my_env.sh内容如下:
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_281
export PATH=$PATH:$JAVA_HOME/bin加载环境变量
source /etc/profile查看java信息
java
7.安装Hadoop
将hadoop的包拖入虚拟机
解压到module目录下:
tar -zxvf /tmp/VMwareDnD/w7eciW/hadoop-3.2.4.tar.gz /opt/module/进入/opt/module/hadoop-3.2.4/目录,配置环境变量
cd /opt/module/hadoop-3.2.4/
sudo vim /etc/profile.d/my_env.sh加入以下内容:
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.2.4
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin加载环境变量
source /etc/profile查看hadoop信息
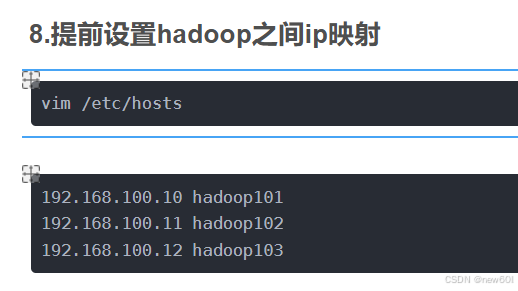
hadoop8.提前设置hadoop之间ip映射
vim /etc/hosts192.168.100.10 hadoop101
192.168.100.11 hadoop102
192.168.100.12 hadoop1039.Hadoop配置文件修改
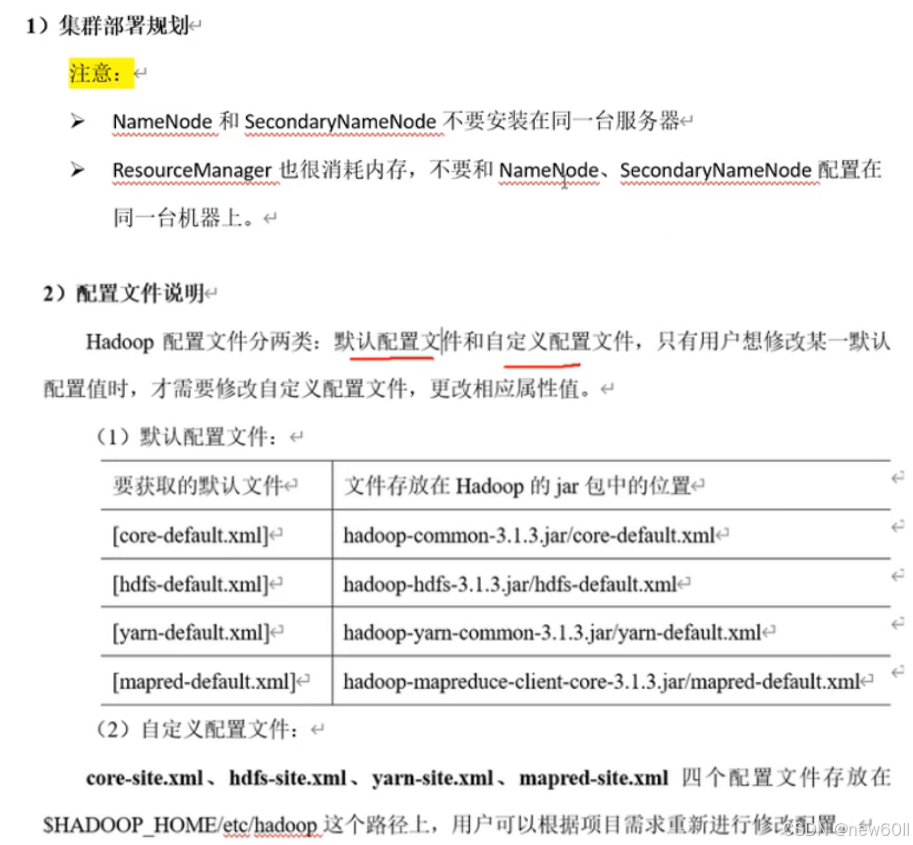
首先进入$HADOOP_HOME/etc/hadoop
cd $HADOOP_HOME/etc/hadoop根据集群规划,配置文件:
core-site.xml:
vim core-site.xml加入以下内容:
<configuration>
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:8020</value>
</property>
<!-- 指定 Hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.2.4/data</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 root-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>注意:不同的hadoop版本目录不同需要修改
hdfs-site.xml:
vim hdfs-site.xml加入内容如下:
<configuration>
<!-- nn(NameNode) web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop101:9870</value>
</property>
<!-- 2nn(SecondaryNameNode) web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:9868</value>
</property>
</configuration>yarn-site.xml:
vim yarn-site.xml加入内容如下:
<configuration>
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
mapred-site.xml:
vim mapred-site.xml加入以下内容:
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>10.群起集群
配置workers
vim /opt/module/hadoop-3.2.4/etc/hadoop/workers内容如下:
hadoop101
hadoop102
Hadoop103注:该文件中添加内容结尾不允许有空格,文件中不允许有空行,删除local等信息
二、克隆两台虚拟机
1.分别修改三台虚拟机的ip和主机名
修改ip:只用改IPADDR与下面一致
vim /etc/sysconfig/network-scripts/ifcfg-ens33修改主机名:
vim /etc/hostname
重启虚拟机它才会更新
reboot重启后,输入如下内容查看ens33下的inet是否与修改的ip一致
ifconfig查看网络是否连接
ping www.baidu.com查看hostname
hostname2.设置免密登录
在hadoop101中:
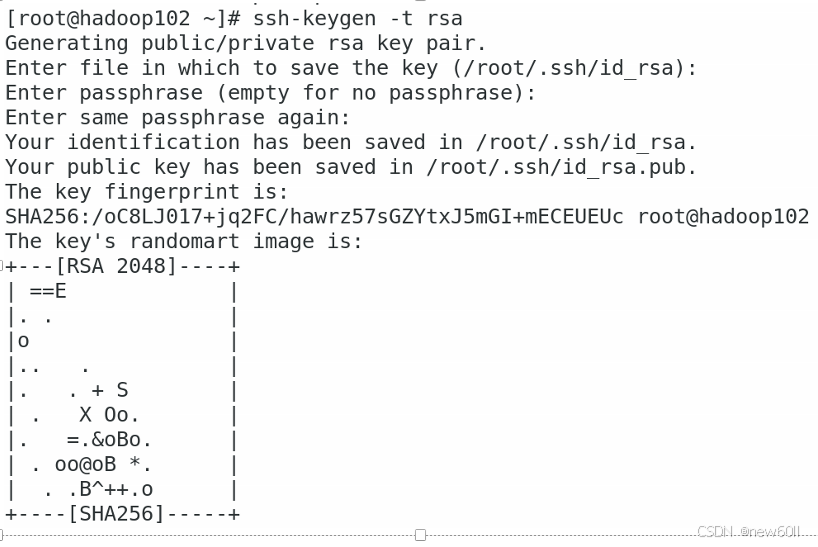
获取公钥
ssh-keygen -t rsa按三次空格
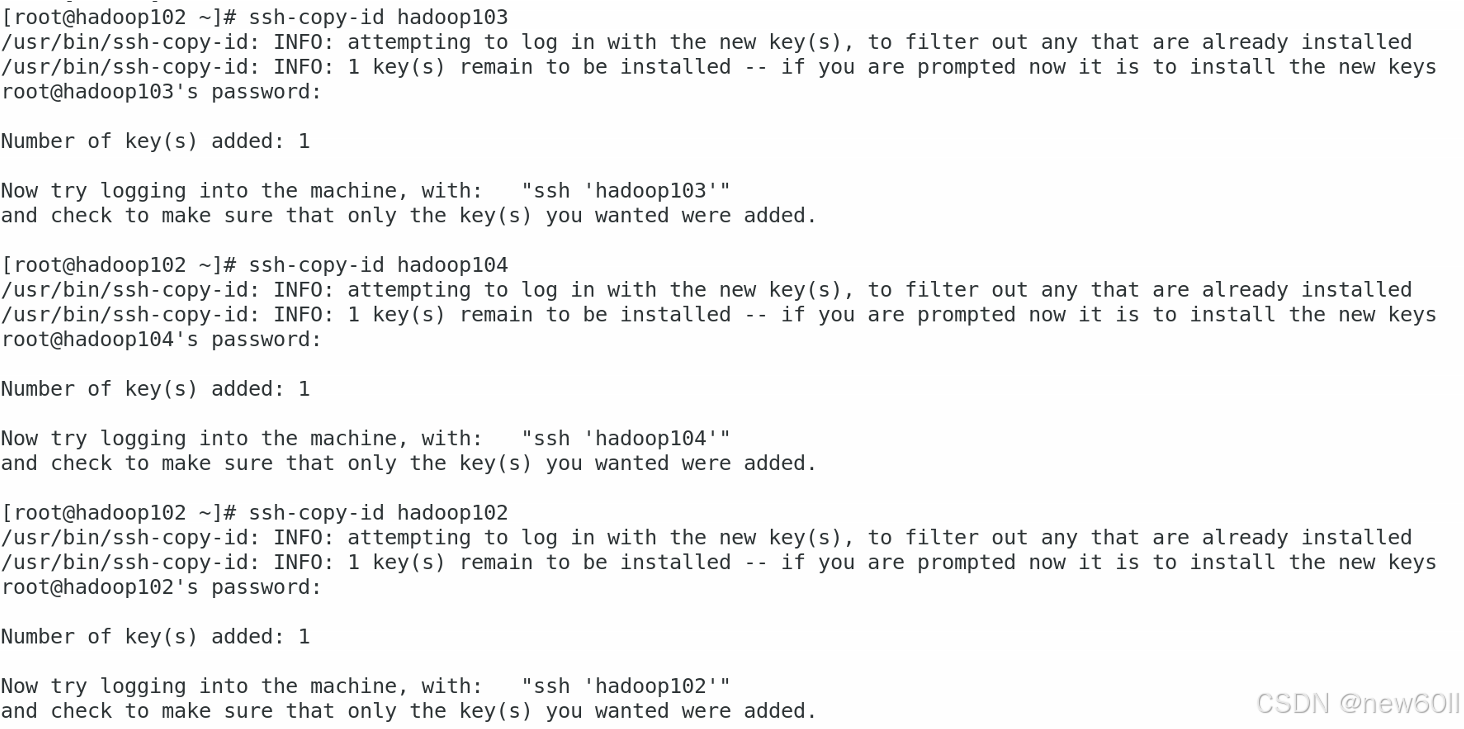
分发公钥
ssh-copy-id hadoop103
ssh-copy-id hadoop104
ssh-copy-id hadoop102第一次访问要输入yes,输入每个虚拟机的root密码
在hadoop102和hadoop103中重复以上步骤
 三、启动集群
三、启动集群
在hadoop101(主节点)上格式化
cd /opt/module/hadoop-3.2.4
hdfs namenode -format查看目录下是否有data和logs文件夹
ll配置hadoop环境变量,定义hadoop组件以root用户运行
cd $HADOOP_HOME/etc/hadoop
vim hadoop-env.sh在第一行加入一下内容:
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root在hadoop103中
配置hadoop环境变量,定义hadoop组件以root用户运行
cd $HADOOP_HOME/etc/hadoop
vim hadoop-env.sh在第一行加入一下内容:
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root启动集群
在hadoop101上执行:
cd $HADOOP_HOME/
sbin/start-dfs.sh在hadoop102上执行:
cd $HADOOP_HOME/
sbin/start-yarn.sh关闭防火墙
在hadoop101,102,103上执行:
systemctl stop firewalld.service在windowns系统的浏览器中输入hadoop101的IP:9870,可以看到文件管理
在windowns系统的浏览器中输入hadoop102的IP:8088,可以看到资源管理
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » hadoop全分布式搭建(三台虚拟机,一个主节点,两个从节点)

发表评论 取消回复