前言:需自行准备hadoop集群
1. Spark 是一款分布式内存计算引擎, 可以支撑海量数据的分布式计算。 Spark 在大数据体系是明星产品, 作为最新一代的综合计算引擎, 支持离线计算和实 时计算。 在大数据领域广泛应用, 是目前世界上使用最多的大数据分布式计算引擎。 我们将基于前面构建的 Hadoop 集群, 部署 Spark Standalone 集群。
2.安装
spark镜像安装https://mirrors.aliyun.com/apache/spark/spark-3.5.3/?spm=a2c6h.25603864.0.0.12d22104b1PXSX
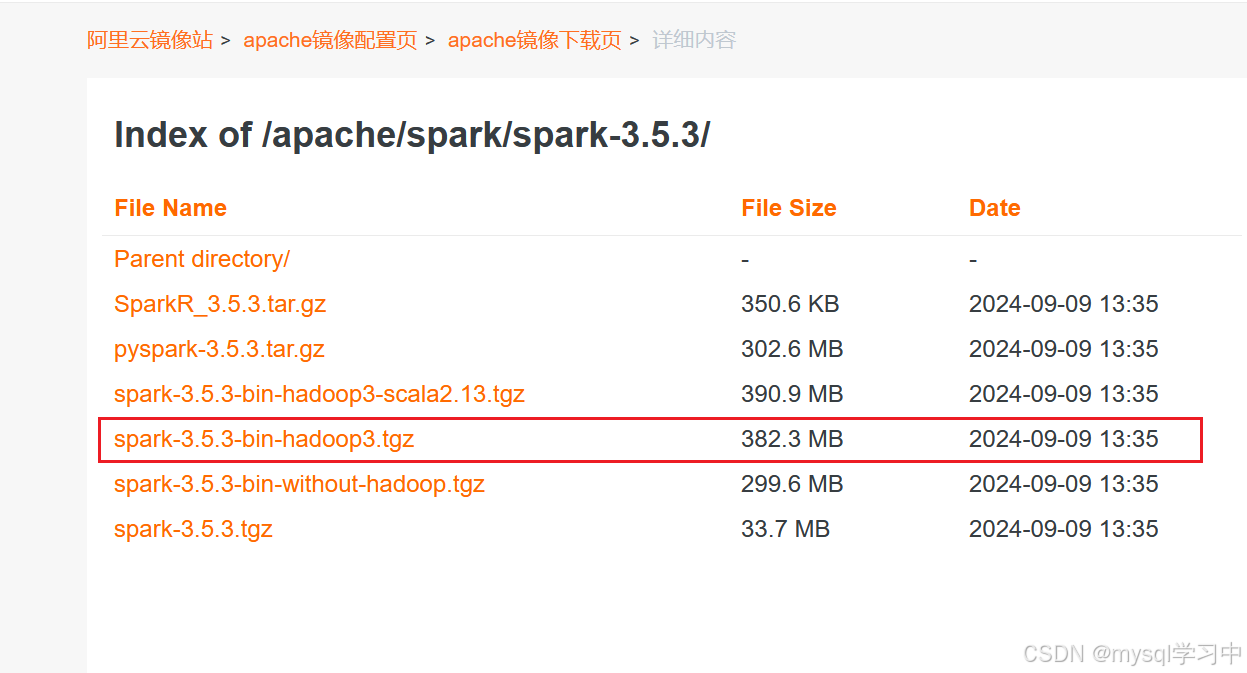
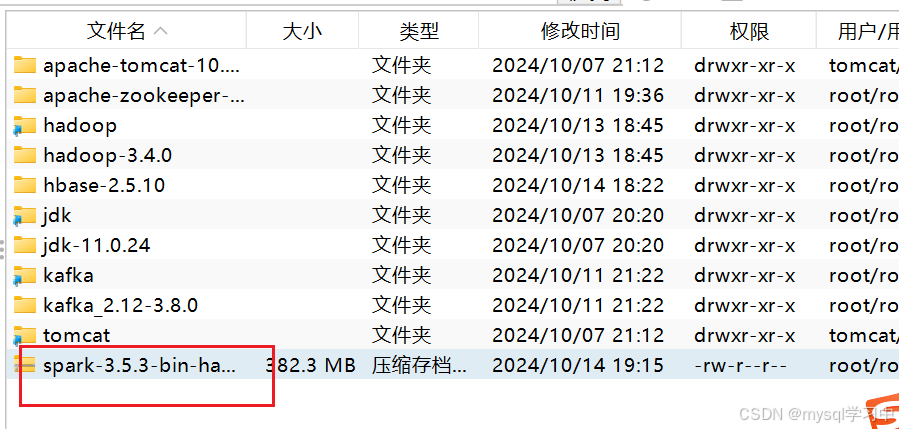
3.解压: 命令: tar -zxvf spark-3.5.3-bin-hadoop3.tgz -C /export/server/
4.创建软连接 命令: ln -s /export/server/spark-3.5.3-bin-hadoop3 /export/server/spark
5.改名
命令: cd /export/server/spark/conf
mv spark-env.sh.template spark-env.sh
mv workers.template workers
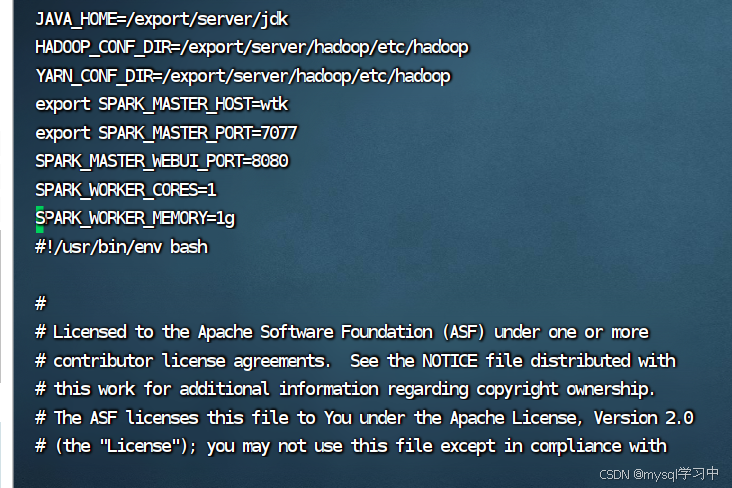
6.修改配置文件, spark-env.sh
加入:
JAVA_HOME=/export/server/jdk
HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
YARN_CONF_DIR=/export/server/hadoop/etc/hadoop
export SPARK_MASTER_HOST=wtk
export SPARK_MASTER_PORT=7077
SPARK_MASTER_WEBUI_PORT=8080
SPARK_WORKER_CORES=1
SPARK_WORKER_MEMORY=1g
7.修改配置文件,workers
清空加入:
各个主机名
8.分发到各个主机
命令 scp -r /export/server/spark-3.5.3-bin-hadoop3 wtk1:/export/server/
部分文件:
9.给分配主机创建软连接
命令: ln -s /export/server/spark-3.5.3-bin-hadoop3 /export/server/spark
10.启动spark
命令: /export/server/spark/sbin/start-all.sh
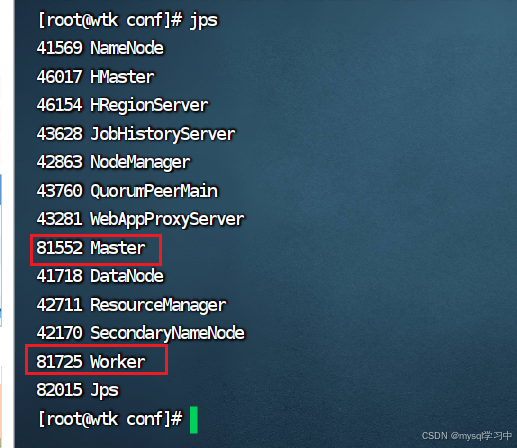
11.验证:
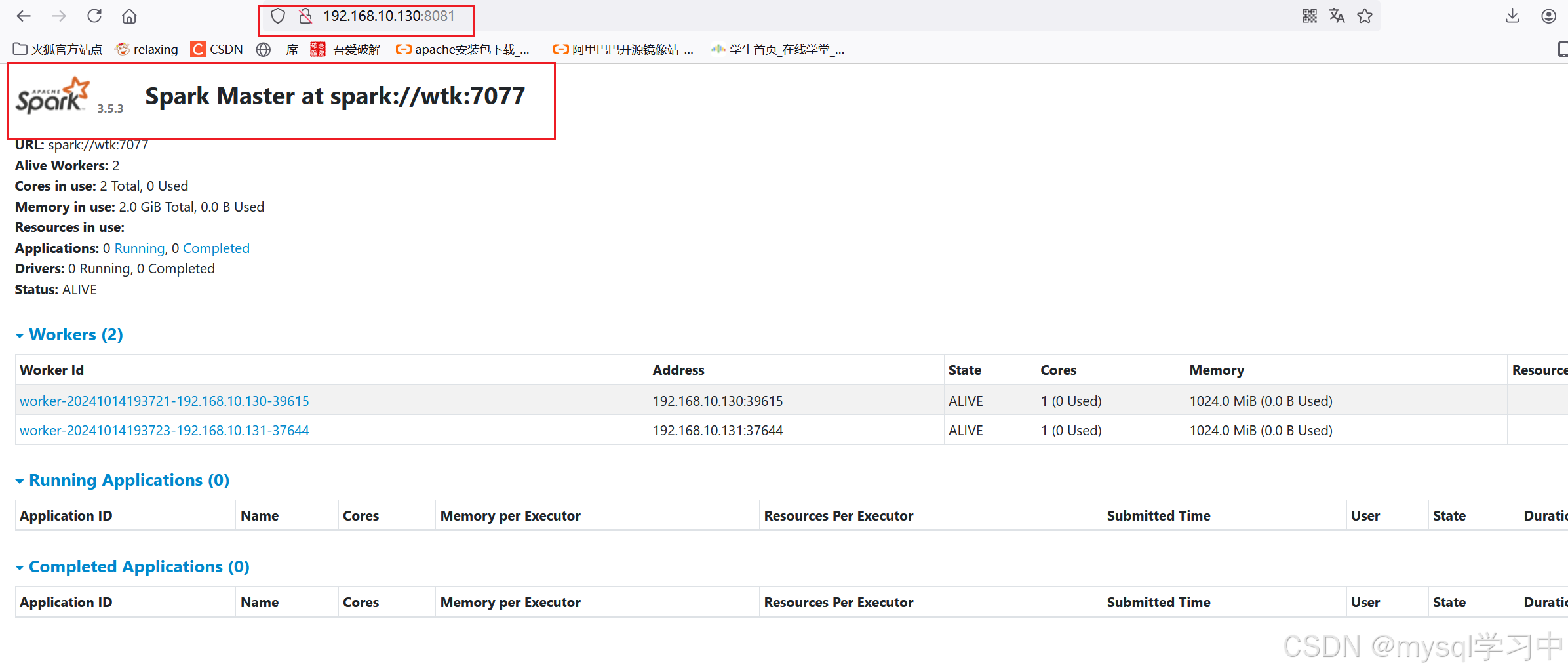
打开spark监控页面
主机ip:8081
我的是192.168.10.130:8081
提交测试任务:(执行以下脚本,主机名自行修改):
/export/server/spark/bin/spark-submit --master spark://wtk:7077 --class org.apache.spark.examples.SparkPi /export/server/spark-3.5.3-bin-hadoop3/examples/jars/spark-examples_2.12-3.5.3.jar examples_2.11-2.4.5.jark
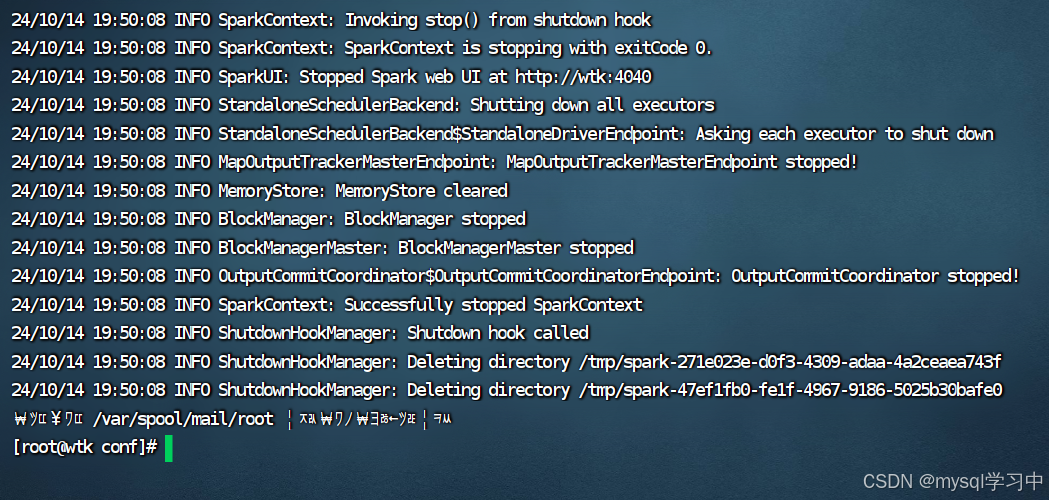
网页刷新,发现脚本已经执行完毕
此时显示应用程序完成
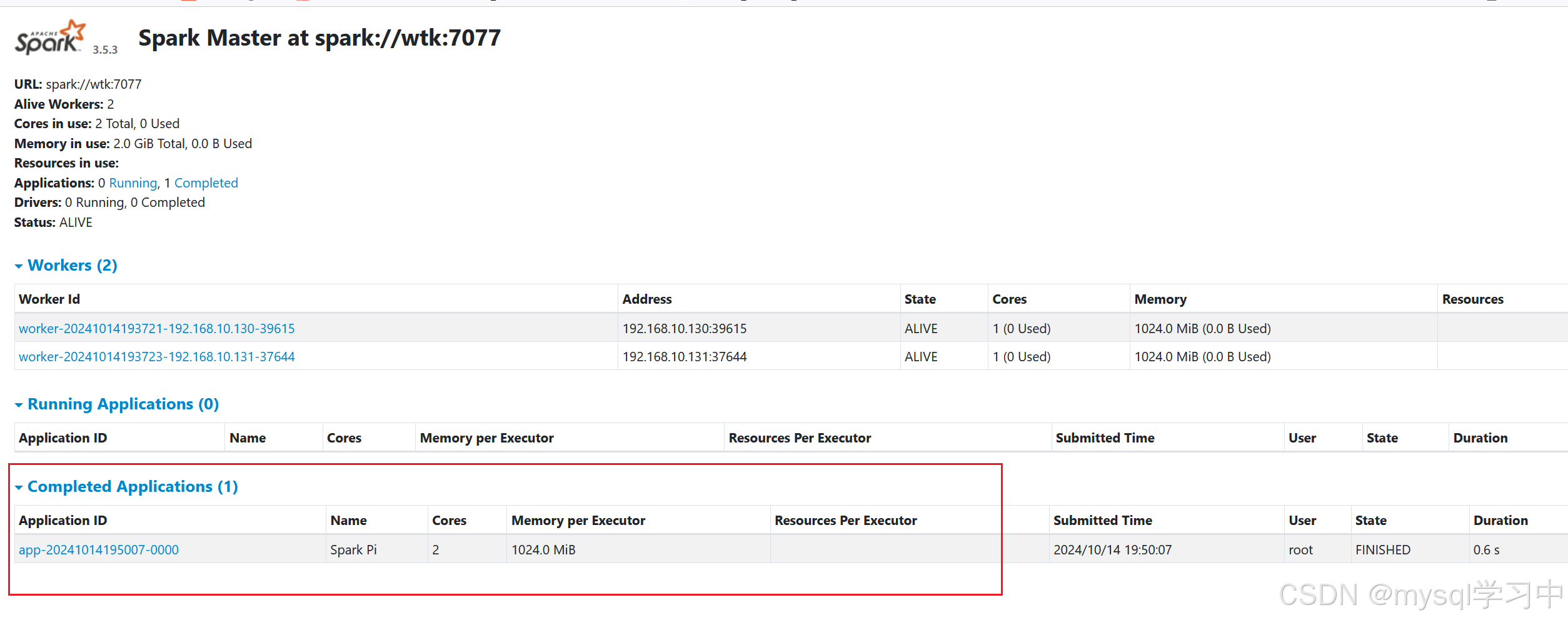
这就是spark的安装部署了
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Linux的Spark 环境部署

发表评论 取消回复