Apache Spark 是一个用于大规模数据处理的分布式计算框架,它支持多种处理模型(如批处理、流处理、SQL、机器学习等)。为了高效地在分布式环境中处理这些多样化的工作负载,Spark 在 2.x 版本后引入了统一内存管理模型,以便在不同类型的计算和存储任务之间合理分配和管理内存。
本文将详细全面地从底层原理和部分源代码的角度解释 Spark 的统一内存模型,涵盖其内存管理的基本思想、不同的内存区域划分、动态内存管理机制以及具体的内存分配和回收机制。
1. Spark 的内存管理问题
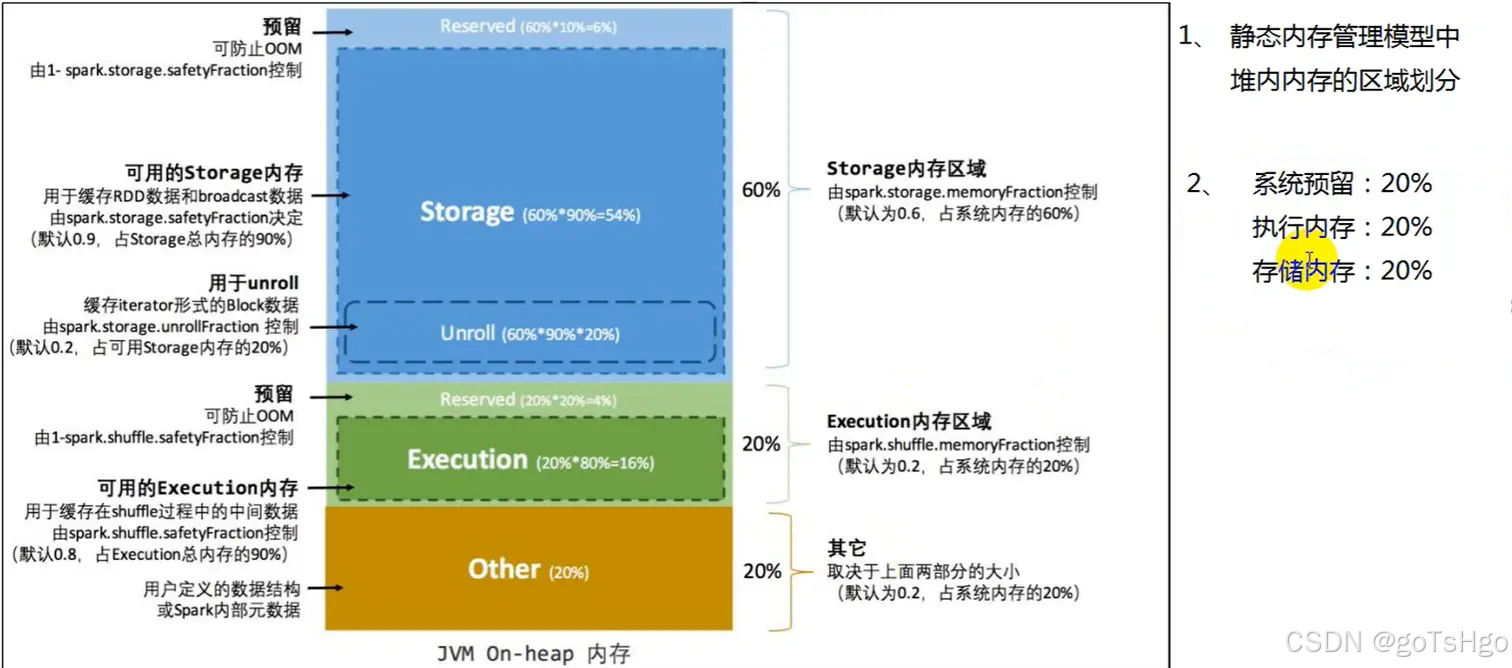
Spark 处理大量数据时,内存是一个关键的资源。传统的内存管理模型(Spark 1.x)中,内存资源主要被划分为两部分:
- 存储内存(Storage Memory):用于缓存中间计算结果(如 RDD Cache 或 Broadcast 变量)。
- 执行内存(Execution Memory):用于执行任务时的数据操作(如 shuffle、join、sort 时的数据缓冲区)。
在 1.x 版本中,这两部分内存是彼此隔离的,存储内存和执行内存之间的使用是静态分配的。如果一部分内存不足,而另一部分有多余内存,无法进行灵活共享。这个问题在 2.x 版本中得到了改进,引入了统一内存管理模型。
2. 统一内存管理模型的基本思想
在 Spark 2.x 版本中(其实是1.6以后就出现了),内存模型的核心思想是通过动态调整存储内存和执行内存之间的划分,使得内存资源在运行时能够根据实际需要进行分配。这个动态分配机制使得在某些场景下(如缓存使用较少或执行任务不密集时),存储内存和执行内存可以灵活地共享内存资源。
统一内存模型主要有两个核心区域:
- 堆内内存(On-heap Memory):通过 JVM 堆来管理的内存,用于存储和操作数据。
- 堆外内存(Off-heap Memory):不在 JVM 堆中管理的内存,通常通过
sun.misc.Unsafe或者直接的操作系统调用进行分配和管理,用于减少 JVM 垃圾回收(GC)的影响。
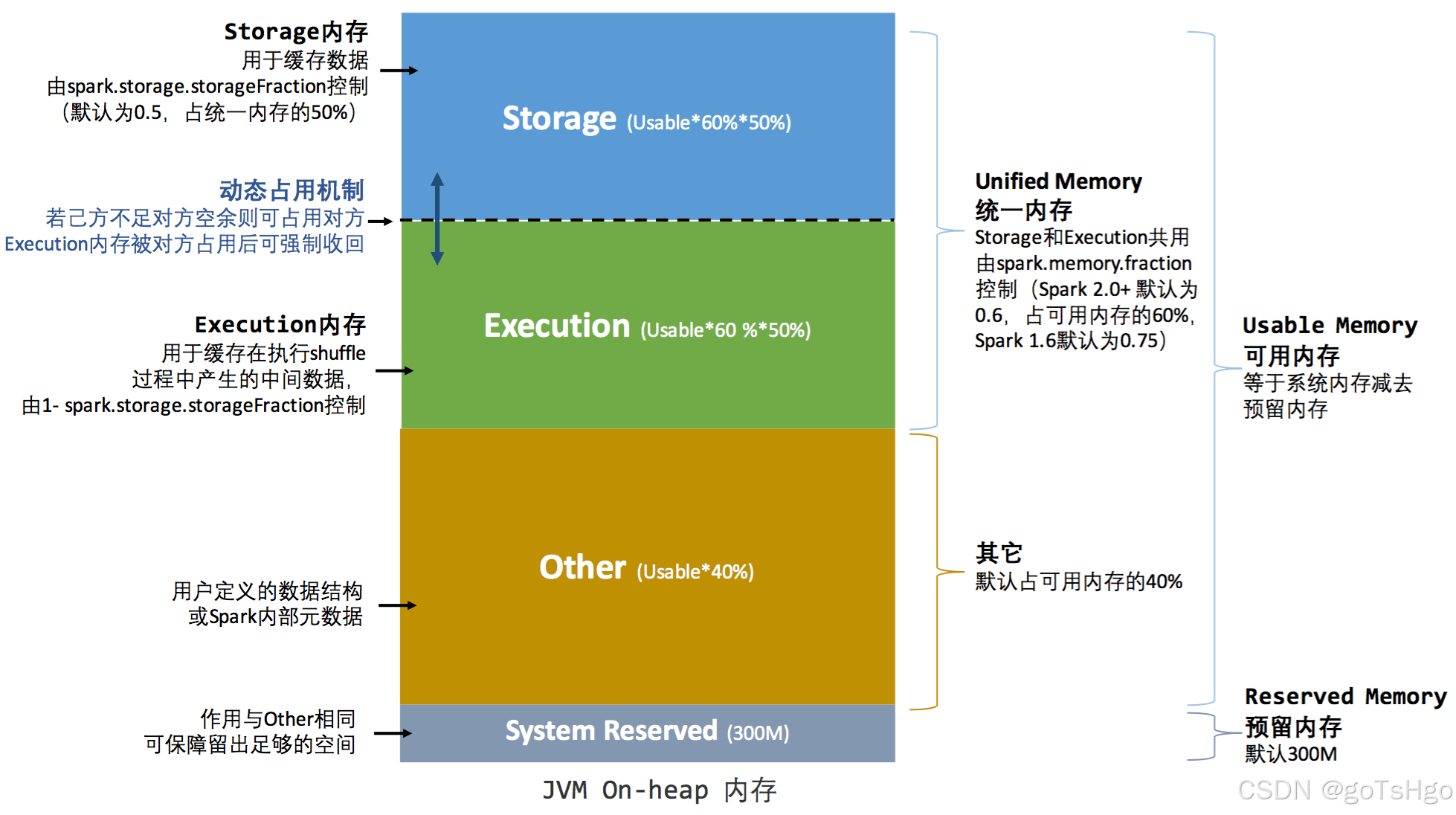
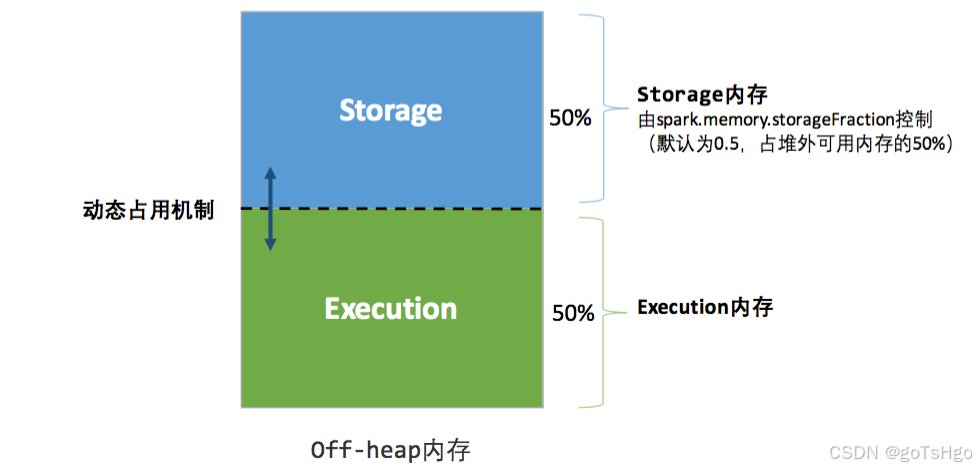
统一内存管理的核心在内存区域的动态占用机制,其占用规则如下:
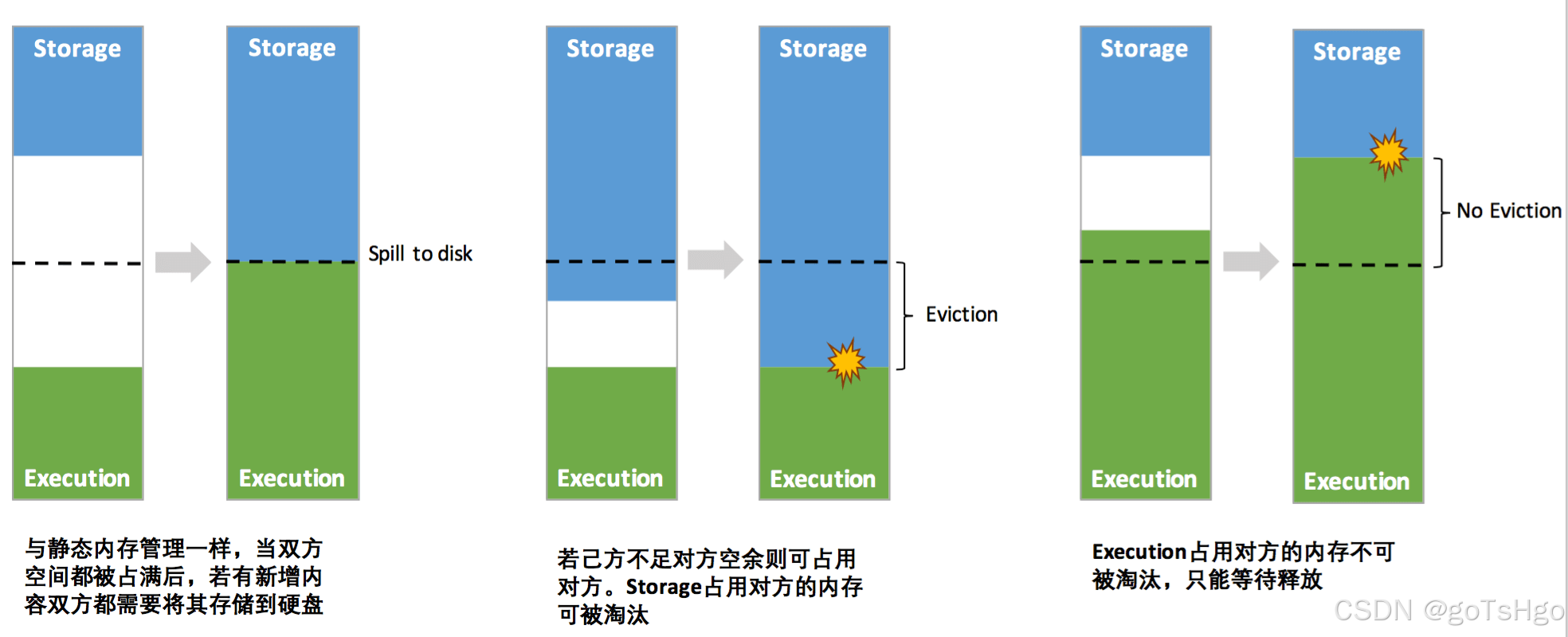
- 双方空间都不足时,则存储到硬盘;如己方空间不足而对方空余时,可借用对方的空间;(存储空间不足是指不足以放下一个完整的 Block)。
- 执行内存的空间被对方占用后,可让对方将占用的部分存储转存到硬盘,然后“归还”借用的空间。
- 存储内存的空间被对方占用后,无法让对方“归还”,因为需要考虑到 Shuffle 过程中很多因素,实现起来较为复杂。
Spark 的内存管理通过两个子模块进行控制:
- 静态内存管理(Static Memory Management):用户根据应用程序需求预定义内存分配策略,Spark 不会动态调整分配。
- 动态内存管理(Dynamic Memory Management):Spark 动态调整内存的使用以提高资源利用率。
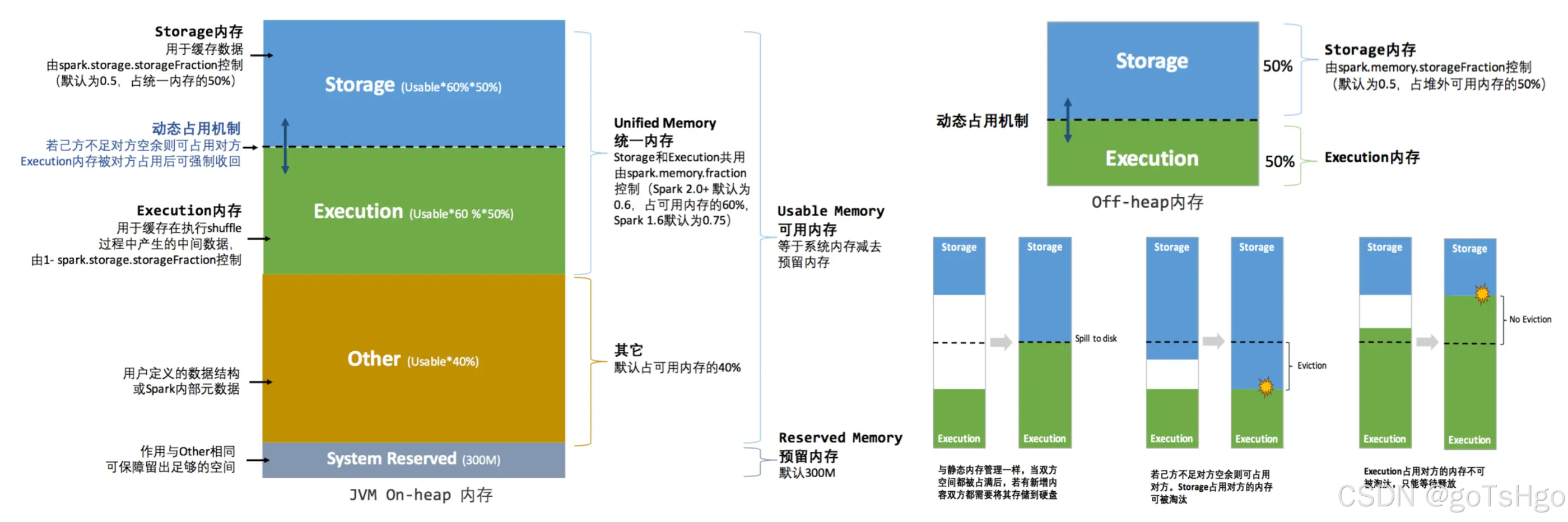
3. Spark 内存的核心划分
在 Spark 中,内存被分为如下几个区域:
-
Reserved Memory(保留内存):这部分内存用于 Spark 内部一些核心的操作,如内存管理、任务调度等。通常是一个固定的小比例,默认情况下保留 300MB。
-
User Memory(用户内存):这部分内存用于存放用户数据结构、内存中的对象等。主要用来执行非 Spark 任务本身的数据操作(如用户自定义的代码)。
-
Execution Memory(执行内存):用于执行任务时所需的内存,如进行 shuffle、join、sort 等操作时的数据缓冲区。
-
Storage Memory(存储内存):用于缓存 RDD 的中间计算结果、广播变量等。它可以通过
persist或cache方法将数据保存在内存中,以便重用。
4. 动态内存管理机制
Spark 的统一内存管理模型采用动态内存管理机制,允许 Execution Memory 和 Storage Memory 在一定条件下共享内存资源。当 Execution Memory 或 Storage Memory 的使用量较低时,未被使用的部分可以被另一方临时使用。
4.1 动态分配策略
动态分配策略的核心机制体现在如下几点:
- 共享机制:
Execution Memory和Storage Memory在需要时可以动态调整各自的内存占用,但两者总内存使用不会超过可用内存的最大限制(spark.memory.fraction,默认为 0.75,即 JVM 堆内存的 75%)。 - 逐步收回:当
Execution Memory需要更多内存时,Spark 会首先尝试从Storage Memory中回收未使用的缓存空间。如果缓存的数据占满了存储内存且不能被回收,任务执行可能会出现内存不足。 - 溢出磁盘:当
Execution Memory或Storage Memory超过了指定的内存限制时,Spark 会将部分数据溢出到磁盘以保证内存的有效使用。
5. Spark 统一内存模型的源代码解析
接下来,我们深入解析 Spark 的内存管理相关的核心源代码,了解其底层实现。
5.1 UnifiedMemoryManager(统一内存管理器)
UnifiedMemoryManager 是 Spark 内部管理内存的核心类。它负责跟踪和分配 Execution Memory 和 Storage Memory,并根据内存使用情况动态调整内存划分。
class UnifiedMemoryManager(
override val maxHeapMemory: Long,
memoryFraction: Double,
storageRegionSize: Long,
onHeapStorageMemory: Long,
offHeapStorageMemory: Long) extends MemoryManager {
// 计算执行内存的最大限制,基于 memoryFraction 参数
private val maxExecutionMemory = (maxHeapMemory * memoryFraction).toLong
// 当前已分配的执行内存
private var executionMemoryUsed = 0L
// 当前已分配的存储内存
private var storageMemoryUsed = 0L
// 获取执行内存的接口
override def acquireExecutionMemory(
numBytes: Long,
taskAttemptId: Long,
memoryMode: MemoryMode): Long = {
val availableExecutionMemory = maxExecutionMemory - executionMemoryUsed
val memoryToAcquire = math.min(numBytes, availableExecutionMemory)
executionMemoryUsed += memoryToAcquire
memoryToAcquire
}
// 获取存储内存的接口
override def acquireStorageMemory(
blockId: BlockId,
numBytes: Long,
memoryMode: MemoryMode): Boolean = {
val availableStorageMemory = maxStorageMemory - storageMemoryUsed
if (availableStorageMemory >= numBytes) {
storageMemoryUsed += numBytes
true
} else {
false
}
}
}
在这个类中:
maxExecutionMemory:表示执行内存的最大限制,基于memoryFraction参数计算得出。acquireExecutionMemory:负责从执行内存中分配指定数量的内存。如果当前执行内存不足,Spark 会根据内存使用情况尝试回收存储内存。acquireStorageMemory:负责为存储缓存(如 RDD Cache)分配内存。如果当前的存储内存不足,Spark 会首先尝试从执行内存中获取未使用的部分。
5.2 动态调整机制
Spark 的内存管理器能够动态地调整执行内存和存储内存之间的分配。通过以下两个方法来实现动态调整:
executionMemoryUsed:记录当前执行任务已经使用的执行内存。当执行任务完成后,内存会被释放并归还给内存池。storageMemoryUsed:记录当前用于缓存数据的存储内存。当存储的 RDD 被移除或者被淘汰时,内存会被释放。
当 Execution Memory 需要更多内存时,acquireExecutionMemory 会检查 Storage Memory 是否有未使用的部分,然后回收这些内存。
5.3 内存的申请与释放
内存的申请和释放是通过以下两个核心方法实现的:
- 申请内存:在
acquireExecutionMemory或acquireStorageMemory中,系统根据当前的内存使用情况分配内存,并调整executionMemoryUsed和storageMemoryUsed。 - 释放内存:当任务执行完成或缓存不再需要时,通过
releaseExecutionMemory或releaseStorageMemory将内存归还给系统。
def releaseExecutionMemory(numBytes: Long, taskAttemptId: Long, memoryMode: MemoryMode): Unit = {
executionMemoryUsed -= numBytes
}
def releaseStorageMemory(numBytes: Long, blockId: BlockId, memoryMode: MemoryMode): Unit = {
storageMemoryUsed -= numBytes
}
5.4 内存的动态扩展
当 Execution Memory 或 Storage Memory 无法满足需求时,Spark 会尝试动态扩展内存的使用。MemoryManager 会检查其他内存池是否有未使用的内存,如果有,则可以临时借用部分内存。
例如,在 acquireExecutionMemory 中,Spark 会首先检查是否有足够的执行内存,如果不足,则会从存储内存中回收未使用的部分:
val memoryToBorrow = math.min(availableStorageMemory, numBytes - availableExecutionMemory)
executionMemoryUsed += memoryToBorrow
这种机制保证了 Spark 在内存不足时,能够尽量通过动态扩展来提高内存的利用率,避免因内存不足而导致任务失败。
6. 堆外内存管理
Spark 还支持堆外内存(Off-heap Memory)的管理,主要用于减少 JVM 垃圾回收的开销。在堆外内存模式下,Spark 会绕过 JVM 堆,通过操作系统直接分配和管理内存。
堆外内存的管理通过 sun.misc.Unsafe 或者 Netty 框架来实现,具体机制与堆内内存管理类似,不过它的内存分配不受 JVM 堆限制,因此能够在某些场景下提供更高的性能。
用户可以通过配置 spark.memory.offHeap.enabled 参数启用堆外内存管理,同时设置 spark.memory.offHeap.size 来指定堆外内存的大小。
7. 内存回收与垃圾回收
Spark 的内存回收机制与 JVM 的垃圾回收机制密切相关。当内存管理器检测到内存不足时,Spark 会尝试触发垃圾回收(GC),以回收未使用的对象和内存。
Spark 内存管理器与 GC 结合紧密,特别是当执行任务时,临时对象会频繁创建并在任务结束后被回收。因此,适当的 GC 策略(如 G1、CMS)对于 Spark 应用的性能至关重要。
Spark 还提供了多种 GC 调优选项,用户可以通过调整 JVM 参数(如 -Xmx、-XX:MaxGCPauseMillis)和 Spark 参数(如 spark.memory.fraction、spark.memory.storageFraction)来优化内存使用和垃圾回收。
总结
Spark 的统一内存模型通过动态调整执行内存和存储内存的划分,极大地提高了内存资源的利用率。通过引入堆外内存支持、灵活的内存共享机制以及动态扩展策略,Spark 能够在不同类型的任务(如批处理、流处理、机器学习)之间高效地分配和管理内存资源。
我们从底层原理和源代码的角度详细解析了 Spark 内存管理的工作机制,了解了 UnifiedMemoryManager 如何动态管理和调度内存,以及内存的申请、释放与回收机制。掌握这些底层实现细节有助于在实际应用中优化 Spark 性能,提升资源利用率。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » spark统一内存模型 详解

发表评论 取消回复