最近工作中,反思自己计算生物学基础非常薄弱,然而作为一门非常新兴的交叉学科,涉及计算机、物理、生物、数学等多多学科,国内并没有这样完善的教程,因此想要自己做一个教程,使用费曼学习法学习,并希望能帮助到各位同学同事老师!
且我本着实践才是检验真理的唯一标准,也会在学习知识点的同时进行R语言、python及linux的学习演示。本教程参考哈佛生物信息与计算生物学课程及多本国外的教程与论文,如有疏漏敬请原谅
本教程初步先讲各种测序及测序数据分析,后续安排再续
目录
(3)第一代测序First-Generation Sequencing
(4)下一代测序技术Next-Generation Sequencing
【1】罗氏 454 (Roche 454 Technology)
(5)第三代测序Third-Generation Sequencing
【2】牛津纳米孔技术 Oxford Nanopore Technology
1.前言
(1)计算生物学
计算生物学是一门跨学科领域,它结合了生物学、数学、统计学和计算机科学的知识和技术,旨在通过数学建模和计算机模拟来理解和预测生物系统的行为。这个领域特别关注于使用计算方法来分析和解释生物大数据,如基因组序列、蛋白质结构和细胞网络。
计算生物学的发展始于20世纪60年代,当时科学家们开始使用计算机来分析蛋白质序列。随着DNA测序技术的发展,计算生物学开始涉及更多的基因组学研究。到了21世纪,随着高通量测序技术的出现,计算生物学迎来了爆炸性的增长,能够处理和分析海量的生物数据。
计算生物学的未来将继续受到技术进步的推动,特别是在人工智能和机器学习领域(今年诺奖)。未来计算生物学在个性化医疗和精准农业等领域也有巨大的应用潜力。
(2)生物信息学
生物信息学是研究生物信息的采集、处理、存储、传播、分析和解释的学科。它主要关注于使用计算机技术来处理和分析生物数据,特别是与基因和蛋白质有关的数据。生物信息学的目标是从这些数据中提取有用的信息,以支持生物学研究和医学应用。
生物信息学的历史可以追溯到1950年代,当时科学家们开始使用计算机来分析蛋白质和DNA序列。随着计算机技术的发展,生物信息学开始涉及更多的基因组学和蛋白质组学研究。进入21世纪,随着测序技术的进步,生物信息学开始处理越来越多的生物数据,成为了一个独立的学科领域。随着生物数据的不断增加,生物信息学将需要更强大的算法和工具来处理这些数据。此外,生物信息学在疾病诊断、个性化医疗、生物多样性保护等领域也将发挥重要作用。随着人工智能技术的发展,生物信息学将能够提供更精确的预测和更深入的洞察。
(3)不同
计算生物学和生物信息学虽然都是交叉学科,结合了生物学与计算机科学,但它们的侧重点和研究方法有所不同。
- 计算生物学更侧重于使用计算方法来模拟和理解生物系统的复杂行为。它强调的是通过数学建模、计算机模拟和理论分析来揭示生物过程的机制。
- 计算生物学的研究对象包括但不限于基因组学、蛋白质结构预测、分子动力学模拟、系统生物学等。
其实简单来说计算生物学是做轮子也就是做工具,而生物信息偏向于使用工具,两种并无高低之分,只是侧重点不同。
2.测序之路
新一代测序数据分析对于理解高通量测序技术产生的海量基因组数据至关重要。这些数据以GB和TB为单位在数据库中积累。科学家需要掌握相关的计算资源和算法以实现研究目标。学习NGS数据分析技术已成为生物信息学家和生物学家必须具备的重要技能,以跟上现代生物学的发展,并有效利用基因组技术和资源。 过去二十年中,新一代测序技术的进步对人类生活产生了积极影响,推动了人类文明的进步,并催生了基因组学这一新生物学领域。基因组学关注基因组的多个方面,如组成、结构、功能单元、进化,产生了大量需要分析的数据。生物信息学作为跨学科领域,满足了数据采集、存储、处理和分析的特定需求。
(1)核酸(NUCLEIC ACIDS)
核酸是所有生物都必须拥有的化学分子。它们就像生物体内的“指令手册”,指导细胞中的生物活动,并决定了生物体的遗传特征。核酸主要有两种:脱氧核糖核酸(DNA)和核糖核酸(RNA)。
可以把DNA想象成生命的大蓝图或生命之书,它构成了原核细胞、真核细胞和病毒粒子的遗传物质。而RNA则是RNA病毒的主要遗传物质,同时在其他生物体内,它也扮演着重要的角色,比如从DNA转录而来,参与蛋白质合成和基因调控等。
无论是原核细胞还是真核细胞,它们所含有的DNA集合被称为基因组。而RNA仅作为某些病毒(RNA病毒)的基因组。
核酸(无论是DNA还是RNA)都是由四种基本核苷酸组成。一个核苷酸分子包括:
(i)一个糖分子(DNA中是脱氧核糖,RNA中是核糖)连接一个磷酸基团
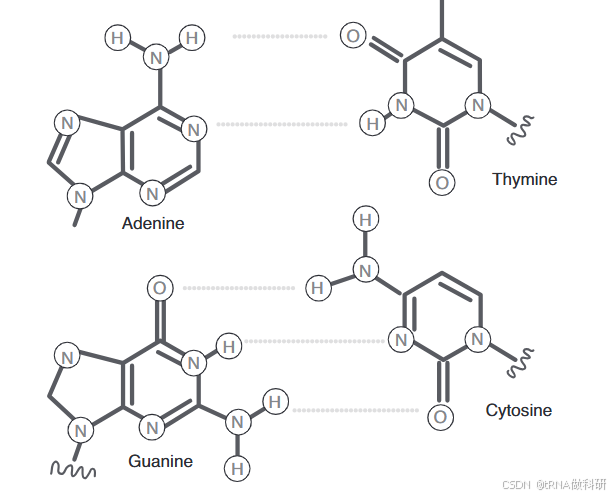
(ii)一个含氮的碱基。一般而言,核苷酸序列由四种不同的核苷酸组成,它们唯一的区别在于含氮碱基的不同(DNA分子中的腺嘌呤(A)、胞嘧啶(C)、鸟嘌呤(G)和胸腺嘧啶(T),以及RNA分子中的腺嘌呤(A)、胞嘧啶(C)、鸟嘌呤(G)和尿嘧啶(U))。这四种核碱基可以分为嘧啶碱基和嘌呤碱基两大类。
嘧啶碱基包括胞嘧啶、胸腺嘧啶和尿嘧啶;它们是具有单环结构的芳香杂环有机化合物。
嘌呤碱基包括腺嘌呤和鸟嘌呤,它们具有两个杂环结构。DNA分子以两条互补的链的形式存在,这两条链相互缠绕形成双螺旋结构。两条链通过碱基之间的氢键相连(腺嘌呤与胸腺嘧啶配对(A/T),胞嘧啶与鸟嘌呤配对(C/G))。腺嘌呤和胸腺嘧啶之间形成两个氢键(弱键),而胞嘧啶和鸟嘌呤之间形成三个氢键(强键)。这些碱基配对是特定的,因此可以根据一条链的序列预测另一条链的序列。
DNA序列的长度可以用碱基对(bp)、千碱基对(kbp)或兆碱基对(Mbp)来表示。而RNA通常以单链形式存在,但有时也会自身形成双链的二级结构以执行特定功能。
一个生物体的基因组就是它的生命之书,决定了细胞的生活方式和生物活动。
基因组包含编码区,即基因,它们携带了蛋白质合成的信息。基因会被转录成信使RNA(mRNA),然后翻译成蛋白质,而蛋白质则控制着生物体内的大多数生物过程。
一个基因由编码区、非编码区和调控区组成。在真核基因中,编码区不是连续的,而非编码序列(称为内含子)会出现在编码序列(称为外显子)之间。这些内含子在转录后的转录本中会被移除,只留下外显子,形成编码区,也称为开放阅读框(ORF)。每个真核基因都有自己的调控区,控制其表达。
(2)测序之初SEQUENCING
DNA/RNA测序是指确定核酸分子中四种核苷酸的排列顺序。生物体基因组中核苷酸的排列顺序被称为序列。DNA测序帮助科学家研究基因的功能、突变在性状和疾病中的作用、物种间的进化关系、遗传因素导致的疾病诊断、基因疗法的开发等。
尝试对核酸进行测序始于1953年詹姆斯·沃森和弗朗西斯·克里克发现DNA双螺旋结构这一里程碑式发现之后。

1965年,诺贝尔奖得主罗伯特·霍利首次对丙氨酸tRNA进行了测序。霍利用两种核糖核酸酶将tRNA在特定核苷酸位置切割,并手动确定了核苷酸的顺序。1972年,沃尔特·菲尔斯首次对DNA分子进行了测序。该DNA分子是编码噬菌体MS2外壳蛋白的基因,测序是通过使用酶将噬菌体RNA分解成片段,并通过电泳和色谱法分离这些片段来完成的。罗伯特·霍利对丙氨酸tRNA的测序以及对噬菌体MSE外壳蛋白基因的测序是基因组学和DNA测序历史上的重要里程碑。

它们为第一代测序技术铺平了道路。
(3)第一代测序First-Generation Sequencing
20世纪70年代初见证了第一代测序技术的诞生,当时美国生物学家艾伦·M·马克斯姆和沃尔特·吉尔伯特开发了一种化学测序方法,随后英国生物化学家弗雷德里克·桑格开发了链终止法。桑格方法成为至今最常用的第一代测序方法。这两种方法都被用于鸟枪法测序,这种方法涉及将基因组分解成DNA片段并分别对这些片段进行测序。然后根据片段序列的重叠部分组装出完整的基因组序列。 马克斯-吉尔伯特测序方法基于DNA分子的化学修饰及其在特定碱基处的切割(不详细叙述) 另一方面,桑格测序方法的步骤与聚合酶链反应(PCR)类似,包括变性、引物退火和聚合酶介导的互补链合成。然而,在桑格测序中,样本DNA被分成四个标记为ddATP、ddGTP、ddCTP和ddTTP的反应管。在四个反应管中,加入四种脱氧核苷三磷酸(dATP、dGTP、dCTP和dTTP),就像在PCR中一样,但还会根据标签加入一种放射性标记的二脱氧核苷三磷酸(ddATP、ddGTP、ddCTP或ddTTP)以在已知核苷酸的某些位置终止DNA合成。这种合成终止会产生长度不一且末端为标记的ddNTP的DNA片段。然后使用变性聚丙烯酰胺-尿素凝胶电泳按大小分离这些片段,每个反应在单独的泳道中标记为A、T、G和C。DNA片段将按长度分离;较短的片段在凝胶中移动得更快。然后通过自显影将DNA条带绘制成图,可以直接从X射线胶片或凝胶图像读取DNA序列上核苷酸碱基的顺序。

(4)下一代测序技术Next-Generation Sequencing
下一代测序(NGS)就像是给生命科学插上了翅膀,它让科学家们能够以前所未有的速度和精度探索生命的奥秘。想象一下,如果第一代测序技术是用老式相机一张一张地拍照,那么NGS就是用现代高速相机一次性拍摄成千上万张照片。这样,我们不仅能在更短的时间内获得更多的信息,还能大大降低成本。 NGS的魔法在于它的并行处理能力,就像一个超级厨师同时烹饪数百道菜一样。它可以同时处理数百万到数十亿的DNA片段,快速地读取它们的序列。这个过程不依赖于传统的链终止法,而是通过创建一个“文库”——将DNA切割成小片段,然后加上一些特殊的“标签”,以便在测序过程中识别和处理这些片段。 在开始测序之前,我们需要准备这些DNA或RNA样本,这个过程叫做文库准备。如果我们要研究的是RNA,首先得把它转化成一种叫做cDNA的形式。接着,我们会用超声波或者酶把DNA切成小块,然后修复这些片段的末端,确保它们整齐划一。之后,我们会给这些片段加上特殊的接头,这些接头就像是给每个片段装上了“翅膀”,让它们能够在测序过程中飞到正确的位置。 这些接头还包含了通用引物和条形码序列,就像是每个片段的身份证明,让我们能够在一次实验中同时处理多个样本,并在后期分析时准确地分辨出它们各自来自哪个样本。对于某些特定的研究,比如研究基因表达或表观遗传学,我们还会加入一个富集步骤,就像是在一堆沙子里找到金子,帮助我们专注于那些最感兴趣的序列。 最后,当我们准备好这一切,就可以开始测序了。NGS技术会产生长度在75到400个碱基对之间的短读长序列。这些序列可以是单端的,也可以是成对端的,后者能帮助我们更准确地拼接和解读这些序列。而这些序列最终会以A、C、G、T这四个字母的形式呈现出来,有时也会出现N,表示那个位置的碱基无法确定。
【1】罗氏 454 (Roche 454 Technology)
罗氏454开发了下一代测序(NGS)的技术,这种技术在2006年被用来完成解脲支原体的全基因组测序。这项技术的核心是焦磷酸测序,它的工作原理是根据核苷酸在DNA模板上的添加和结合顺序来工作。 简单来说,焦磷酸测序的过程是这样的:
1. 首先,把DNA切成小片段,并变成单链状态。
2. 给这些片段的两端分别加上两个特殊的接头(A和B)。
3. 用一种特殊的珠子,上面有能跟接头A配对的引物,这样就可以开始复制DNA的另一条链了。
4. 这个复制过程可以重复很多次,以增加DNA的数量(这一步叫PCR)。
5. 把这些带有DNA的珠子放进小孔,再加一个能跟接头B配对的引物,开始往这条链上加新核苷酸。
6. 每当有一个核苷酸被加到链上时,就会释放出一个叫做无机焦磷酸盐(PPi)的物质。
7. PPi含有大量的能量,它可以被用来生成ATP,而ATP可以进一步让荧光素发光。
8. 这个光信号会被相机捕捉到,通过测量光的强度,就可以知道DNA链上核苷酸的顺序。
【2】Ion Torrent
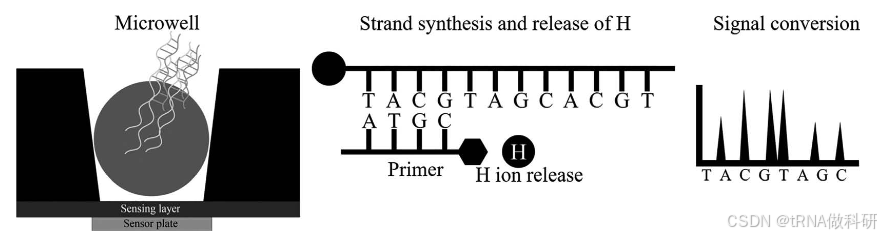
Ion Torrent测序仪是由赛默飞世尔科技公司制造的,它的测序方法在最初的几个步骤与罗氏454测序类似,包括DNA的片段化、变性、接头连接,以及使用珠子和引物在微孔中进行扩增。但是,Ion Torrent测序的关键区别在于它不依赖于光信号来检测核苷酸的结合,而是依赖于氢离子(质子)的释放所引起的pH变化。 Ion Torrent测序仪的优势在于它的便携性和快速性,因为它不需要复杂的光学系统来检测信号,而是直接通过pH变化来实时监测核苷酸的结合。原理如图所示:
【3】Illumina技术
想象一下,我们有一个非常长的梯子,这个梯子的每一级台阶都代表DNA的一个小片段。现在,我们的目标是找出这个梯子每一级台阶的具体样子。
为了做到这一点,Illumina的方法就像是给每一级台阶涂上不同的颜色,这样我们就能通过观察颜色来知道台阶是什么样的。具体来说,他们使用了四种不同颜色的特殊“涂料”(这四种颜色分别代表四种不同的核苷酸:dATP、dCTP、dGTP和dTTP)。
在每一轮操作中,只会有一种颜色的“涂料”被涂抹上去。这种“涂料”有一个特殊的性质,就是它会阻止下一种“涂料”继续涂抹,直到我们用特殊的工具把这种“涂料”的阻止作用去掉。这样,我们就可以一次只涂抹一种颜色,然后用相机拍下照片,记录下这种颜色的位置。之后,我们再去除这种“涂料”的阻止作用,以便下一种颜色的“涂料”可以涂抹上去。
通过重复这个过程,我们可以逐步构建出整个DNA梯子的完整图像。而这个图像就是我们所说的测序结果。
至于DNA文库的准备,可以想象成我们在开始涂色之前,先要把这个长梯子拆成很多小段,然后把这些小段整理好,方便我们后续的操作。这个过程包括把DNA切成小片段、修复片段的末端,以及给这些片段加上特殊的标签(接头),这样它们就能更好地和我们的“画布”(流动池)结合。
在流动池中,有两种特殊的“引物”(寡核苷酸),它们能和我们加在DNA片段上的标签完美匹配。当DNA片段加入到流动池中时,这些标签就会和“引物”结合,形成一个个小桥。这些“引物”同时也充当了起点的作用,帮助我们开始涂抹“涂料”,生成DNA片段的簇。
最后,我们通过变性(分离DNA的双链)、添加荧光标记的核苷酸、激发光源并捕捉信号等步骤,逐步确定每个碱基的身份。
(5)第三代测序Third-Generation Sequencing
第三代测序(TGS)是一种相对较新的测序技术,它的发展源于对长读长的需求,以提高诸如从头基因组组装、变异发现和表观遗传学等测序应用的准确性和分辨率。通常,基因组中存在数百到数千个碱基的长重复序列,这些序列很难用NGS产生的短读长覆盖。TGS的基础是在2003年奠定的,当时使用荧光显微镜通过DNA聚合酶从单个DNA分子获得了5个碱基的序列。
单分子测序(SMS)随后发展,包括
(i)使用先进的显微镜技术直接成像单个DNA分子,以及
(ii)纳米孔测序技术,其中单个DNA分子穿过纳米孔,分子碱基在其通过纳米孔时被检测。尽管TGS提供了长读长(从几百到几千个碱基对),但这可能以牺牲准确性为代价。然而,最近,TGS的准确性有了很大的提高。TGS提供的长读长可以增强从头组装,并允许直接检测单体型和更高的共识准确性,以便更好地发现变异。
【1】PacBio 技术
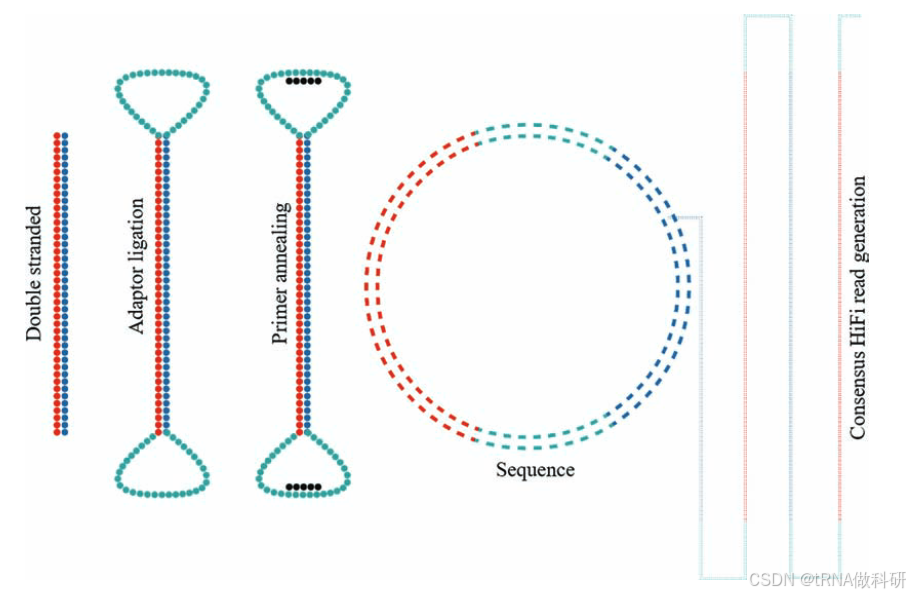
PacBio测序技术能够提供长度在500至50,000碱基对之间的长读长。这项技术自2011年推出以来不断进步,其核心技术是单分子实时(SMRT)测序,即在测序过程中实时读取单个DNA分子的碱基序列。测序流程包括将接头连接到DNA片段以构建文库,形成特殊的环形结构(SMRTbell),并在纳米孔(ZMWs)中进行测序。每个ZMW都是一个微型反应器,其中DNA聚合酶会添加荧光标记的核苷酸来构建DNA链,而荧光信号则用于实时检测碱基的添加。通过重复这一过程并利用环状共识序列(CCS),可以生成高精度的长读长(HiFi读长),其准确率可达99.9%。PacBio测序能够在数千个ZMW中并行执行,从而高效地生成高质量的长读长数据。
【2】牛津纳米孔技术 Oxford Nanopore Technology
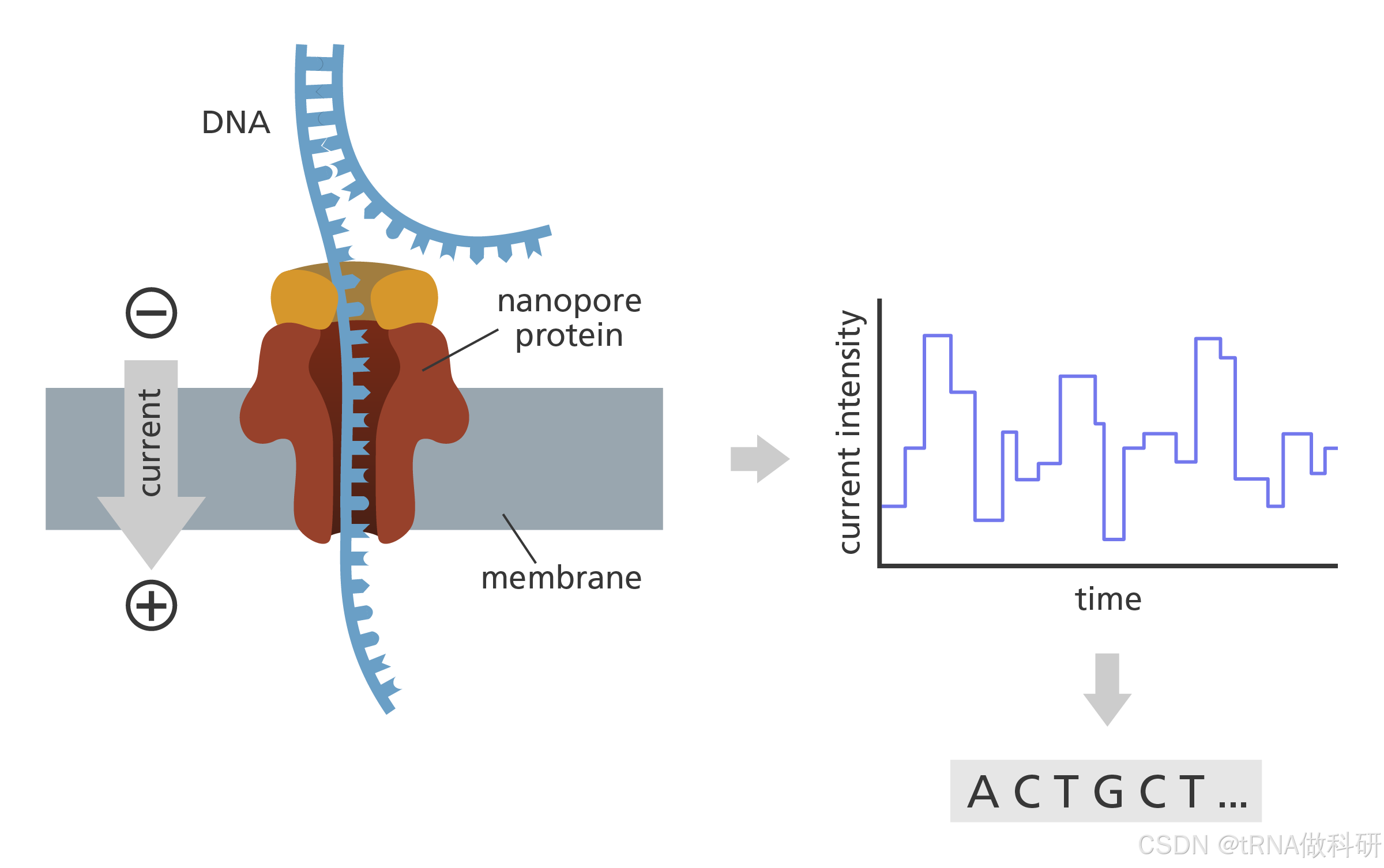
牛津纳米孔技术(ONT)于2012年宣布,但直到2015年才作为MinION技术商业化。ONT使用流动池实现大规模并行测序。他们的流动池由一个电阻力膜制成,其中包含数千个直径为一纳米的微小孔洞。测序原理是基于对纳米孔施加恒定电流。电流的大小取决于纳米孔的大小和形状。在测序过程中,允许单链DNA(ssDNA)像针线一样通过纳米孔,使得每次只有一个核苷酸通过。当一个核苷酸通过孔的开口时,电压大小会发生变化。我们可以使用已知的DNA序列来捕捉每个核苷酸的独特电变化,然后让需要测序的DNA分子通过纳米孔的开口。通过匹配模式来确定DNA序列上核苷酸的顺序。ONT的错误率较高,因为DNA片段倾向于快速通过纳米孔,这可能会产生错误。
3.总结
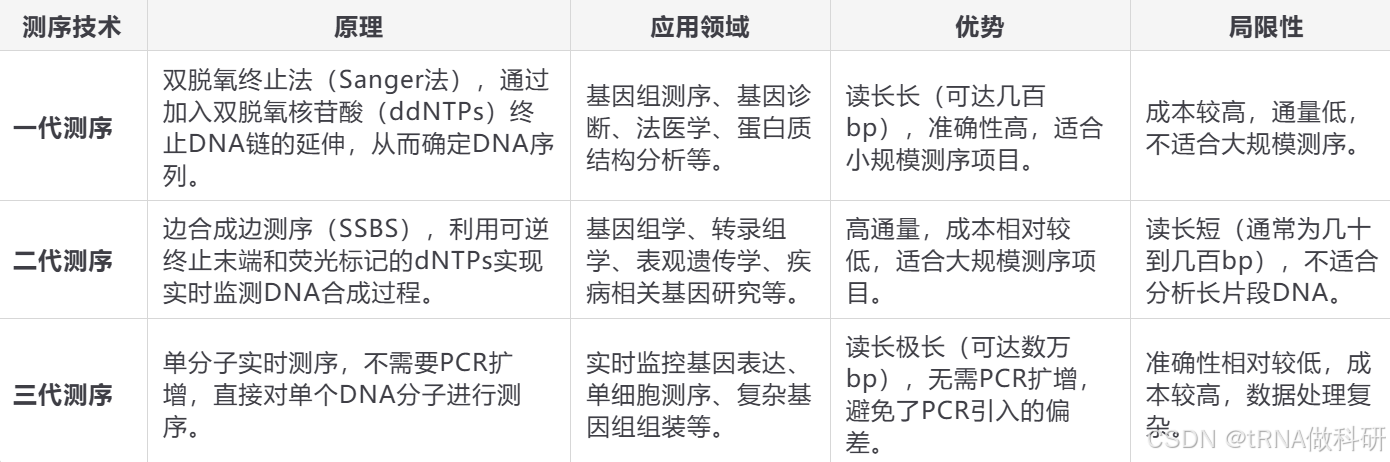
我们通过一个表格来简单回顾一下三代测序
下一篇将讲述测序深度及读段质量等内容,如果有问题欢迎大家交流讨论
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 计算生物学与生物信息学漫谈-1-测序一路走来

发表评论 取消回复