什么是大模型?
大模型:是“规模足够大,训练足够充分,出现了涌现”的深度学习系统;
大模型技术的革命性:延申了人的器官的功能,带来了生产效率量级提升,展现了AGI的可行路径;
大模型的三个关键能力(涌现的行为):ICL(情景学习能力),CoT(深度推理能力),LNI(自然指令学习)
大模型智能涌现现象:
数据型规模达到一定水平时,在新任务上的性能显著提高,超出平均水平。
大模型的尺度(scaling laws):
大模型的泛化表现与学习质量、训练数据规模、参数规模呈指数率关系。
智能涌现:自然现象与多学科启示
智能涌现:由个体的相互作用(简单规则)导致非常智能(复杂而有序)的整体行为。
物理观点:对称性破缺是基础(Anderson,more is different,Science,1972):尺度是根本要素:1)划分尺度 2)出现新的因果 3)选择最强因果性——因果涌现。
数学观点:极限所展示的行为(极限是开拓认知边界的利器)



大模型智能涌现与尺度率:数学建模
假设

由此推得

大模型是否存在相变? 存在性就意味着相变!
大模型能不能工作更好? 
大模型涌现的判定准则
大模型与极限架构:有限vs无限
模型架构:以“功能块+基块周期性重复”为结构的大规模深度神经网络(映射功能)
一个大模型架构由若干个功能块组成。固定一个功能块,假设该功能含k个基块,且第i个基块定义映射

假设宽度有限,P是K个基块的参数总规模,![w_{p}= [w_{1}...w_{n}]](/uploads/article_img/eq?w_%7Bp%7D%3D%20%5Bw_%7B1%7D...w_%7Bn%7D%5D)
而无限维系统为


本模型极限架构的存在性等价于算子无穷乘积的收敛性。
通过引入非线性Lipschitz算子及特征数(涉及泛函分析,此处不细讲)可以用于描述大模型涌现或尺度率的判定条件。

结论:涌现存在的条件
1)通常假设1和假设3作为A的前提假设,因而上述定理说明:如果大模型的权值能最优设置,而且其基块满足Lip

2) 极限架构行为即表现为涌现具体可刻画可通过选择特定的


结论:模型规模尺度率
模型规模尺度率为指数律或幂率,取决于模型基块的组装方式:A.模式(残差式)要求的条件m(A)>0,一般总是弱于T模式(堆叠式)条件
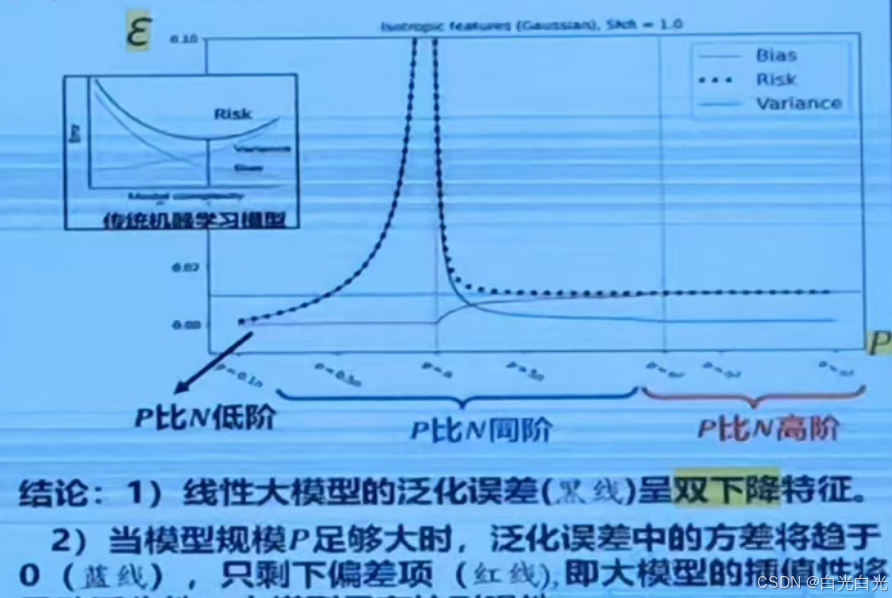
只剩下偏差(红线),即大模型的插值性将导致泛化性,大模型具有抗耐噪性
一些可以进一步深化的问题?


来自徐宗本院士的分享!
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 大模型涌现判定

发表评论 取消回复