禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者!
文章目录
介绍
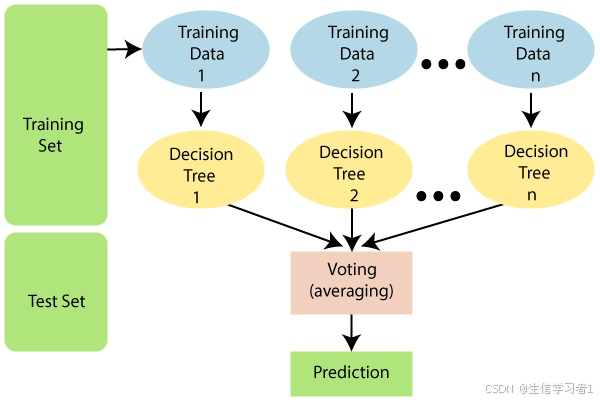
随机森林是常用的非线性用于构建分类器的算法,它是由数目众多的弱决策树构建成森林进而对结果进行投票判断标签的方法。
随机森林用于分类器的算法过程,
- 随机切分样本,然后选择2/3用于建模,剩余1/3用于验证袋外误差;
- 随机选择特征构建决策树,每个叶子节点分成二类;
- 根据GINI系数判断分类内部纯度程度,进行裁剪树枝;
- 1/3数据预测,根据每个决策树的结果投票确定标签;
- 输出标签结果,并给出OOB rate
随机的含义在于样本和特征是随机选择去构建决策树,这可以有效避免偏差,另外弱分类器组成强分类器也即是多棵决策树组成森林能提升模型效果。
教程
本文旨在通过R语言实现Random forest,总共包含:
- 下载数据
- 加载R包
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » R语言机器学习算法实战系列(四)随机森林算法+SHAP值 (Random Forest)

发表评论 取消回复