6 协同LLMs与知识图谱(KGs)
近年来,LLMs与知识图谱(KGs)的协同工作引起了越来越多的关注,这种协同结合了LLMs与知识图谱的优势,在各种下游应用中相互提升表现。例如,LLMs可用于理解自然语言,而知识图谱则作为知识库,提供事实知识。LLMs与知识图谱的统一可以产生一个强大的模型,用于知识表示和推理。
在本节中,我们将从两个角度讨论最先进的协同LLMs与知识图谱的研究:1)协同知识表示,2)协同推理。代表性的工作总结在表4中。
表4
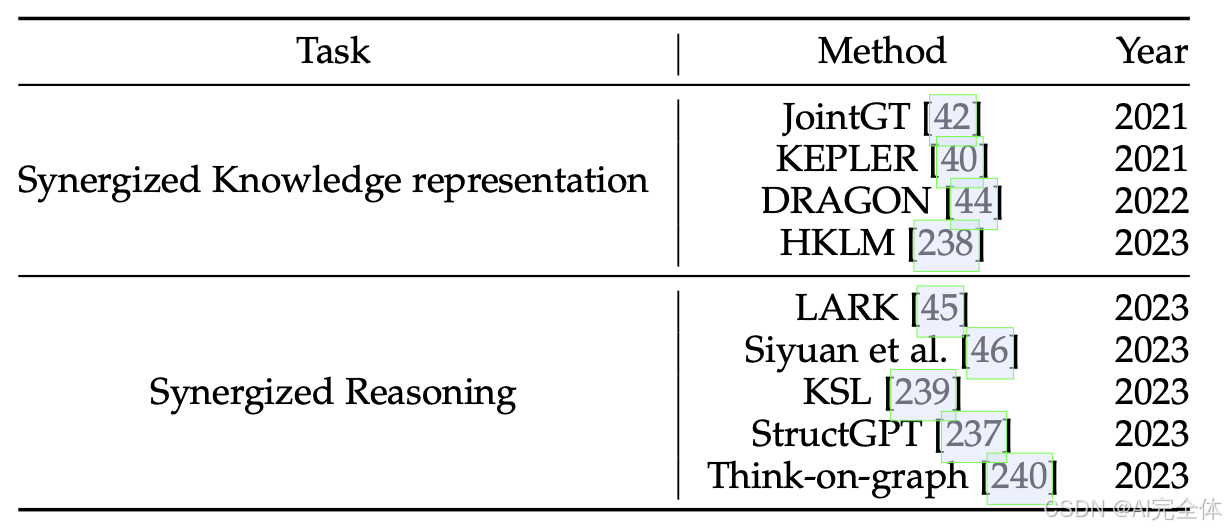
协同LLMs与知识图谱的研究总结
6.1 协同知识表示
文本语料库和知识图谱(KGs)都包含大量知识。然而,文本语料库中的知识通常是隐式和非结构化的,而知识图谱中的知识是显式和结构化的。协同知识表示(Synergized Knowledge Representation)旨在设计一个协同模型,能够有效地表示来自LLMs和知识图谱的知识。该协同模型能够更好地理解来自这两种资源的知识,使其在许多下游任务中具有重要价值。
为了联合表示这些知识,研究人员提出了通过引入额外的知识图谱融合模块来进行协同模型设计,并与LLMs进行联合训练。
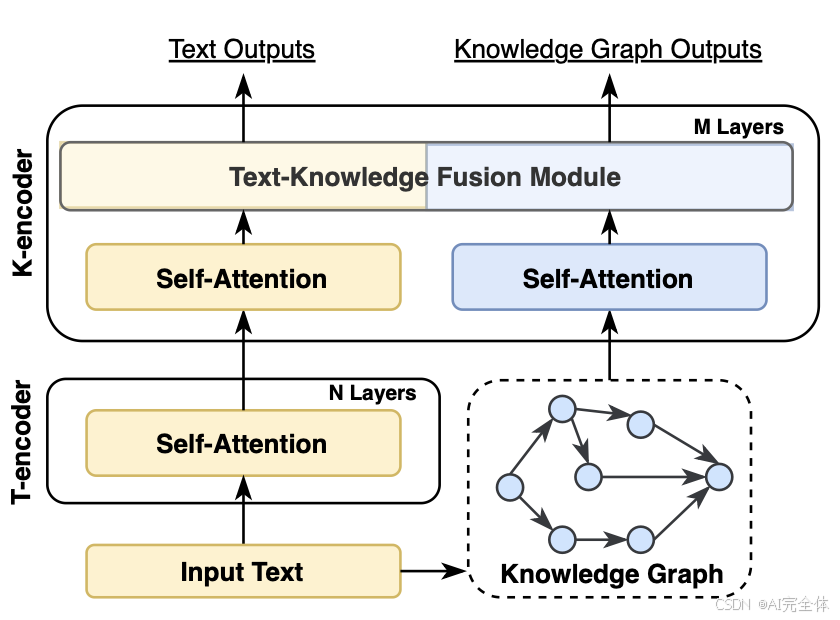
- 如图23所示,ERNIE [35] 提出了一种文本-知识双编码器架构,其中T编码器首先编码输入句子,随后K编码器处理知识图谱,并将其与T编码器生成的文本表示融合。
- BERT-MK [241] 采用了类似的双编码器架构,但在LLMs的预训练过程中引入了邻近实体的额外信息。然而,知识图谱中的一些邻近实体可能与输入文本无关,从而产生额外的冗余和噪音。
- CokeBERT [242] 针对这个问题,提出了基于图神经网络(GNN)的模块,利用输入文本过滤掉无关的知识图谱实体。
- JAKET [243] 提出了在大型语言模型的中间阶段融合实体信息的方法。
- KEPLER [40] 提出了一个用于知识嵌入和预训练语言表示的统一模型。在KEPLER中,他们使用LLM对文本实体描述进行编码,并将其作为嵌入,然后联合优化知识嵌入和语言建模目标。
- JointGT [42] 提出了一个图-文本联合表示学习模型,设计了三个预训练任务,以对齐图和文本的表示。
- DRAGON [44] 提出了一个自监督方法,用于从文本和知识图谱中预训练联合语言-知识基础模型。该方法以文本段落和相关的知识图谱子图为输入,双向融合这两种模态的信息。随后,DRAGON利用了两个自监督推理任务,即掩码语言模型和知识图谱链接预测,以优化模型参数。
- HKLM [238] 引入了一个统一的LLM,结合知识图谱来学习特定领域知识的表示。
图23
通过额外的知识图谱(KG)融合模块实现的协同知识表示。
6.2 协同推理
为了更好地利用文本语料库和知识图谱的推理能力,协同推理旨在设计一个能够有效结合LLMs和KGs进行推理的模型。
LLM-KG融合推理。
LLM-KG融合推理通过两个分别独立的LLM和KG编码器处理文本和相关的KG输入 [244] 。这两个编码器同等重要,联合融合来自两个来源的知识进行推理。
- 为了增强文本和知识之间的交互,KagNet [38] 首先对输入的KG进行编码,然后增强输入的文本表示。
- 与此相对,MHGRN [234] 使用输入文本的最终LLM输出来引导KG上的推理过程。然而,这两者都仅设计了文本和KG之间的单向交互。
- 为了解决这一问题,QA-GNN [131] 提出使用基于GNN的模型,通过信息传递机制,在输入上下文和KG信息上进行联合推理。具体来说,QA-GNN通过池化操作将输入的文本信息表示为一个特殊节点,并将该节点与KG中的其他实体连接。然而,文本输入仅被池化为一个单一的稠密向量,限制了信息融合的效果。
- JointLK [245] 提出了一个框架,通过LM到KG和KG到LM的双向注意力机制,精细地交互文本输入中的任意标记与KG实体之间的关系。如图24所示,所有文本标记和KG实体的成对点积分数被单独计算,双向注意力得分分别被计算。此外,在每一层JointLK层中,KG也基于注意力得分动态修剪,以便后续层聚焦于更重要的子KG结构。尽管JointLK有效,但它在文本和KG之间的融合过程中仍然使用LLM的最终输出作为文本输入表示。
- GreaseLM [178] 设计了LLMs每一层中的输入文本标记和KG实体之间的深度和丰富的交互。这种架构和融合方法与 6.1 节讨论的ERNIE [35] 相似,但GreaseLM没有使用仅处理文本的T编码器来处理输入文本。
LLMs作为代理进行推理。
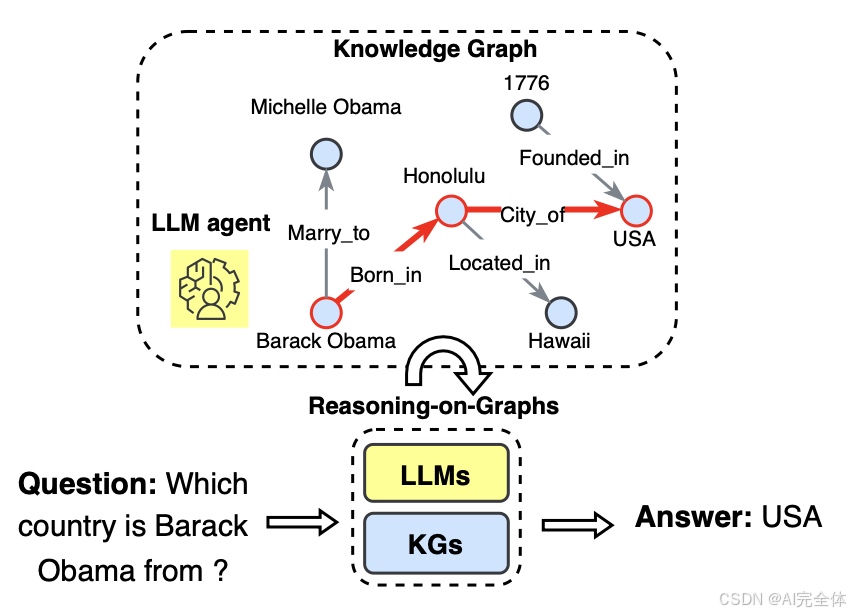
与其使用两个编码器融合知识,LLMs也可以作为代理,与KGs进行交互推理 [246] ,如图25所示。
- KD-CoT [247] 迭代检索KG中的事实,并生成可靠的推理轨迹,指导LLMs生成答案。
- KSL [239] 教LLMs在KG上搜索相关事实并生成答案。
- StructGPT [237] 设计了多个API接口,允许LLMs访问结构化数据,并通过在KG上遍历进行推理。
- Think-on-graph [240] 提供了一个灵活的即插即用框架,LLM代理通过在KG上执行束搜索迭代地发现推理路径并生成答案。
- 为了增强代理的能力,AgentTuning [248] 提出了几个指令微调数据集,以指导LLM代理在KG上进行推理。
比较与讨论。
LLM-KG融合推理将LLM编码器和KG编码器结合起来,以统一的方式表示知识。然后,它使用协同推理模块联合推理结果。该框架允许不同的编码器和推理模块,端到端训练,从而有效利用LLMs和KGs的知识和推理能力。然而,这些额外的模块可能会引入额外的参数和计算成本,同时缺乏可解释性。LLMs作为KG推理的代理提供了一个灵活的推理框架,无需额外的训练成本,可以推广到不同的LLMs和KGs。同时,推理过程具有可解释性,可以用于解释结果。然而,为LLM代理定义动作和策略也是一个挑战。LLMs和KGs的协同仍然是一个正在研究的课题,未来可能会有更强大的框架出现。
图24的解读
LLM-KG融合推理的框架
为了更好地理解图24的工作机制,我们用一个例子来说明。
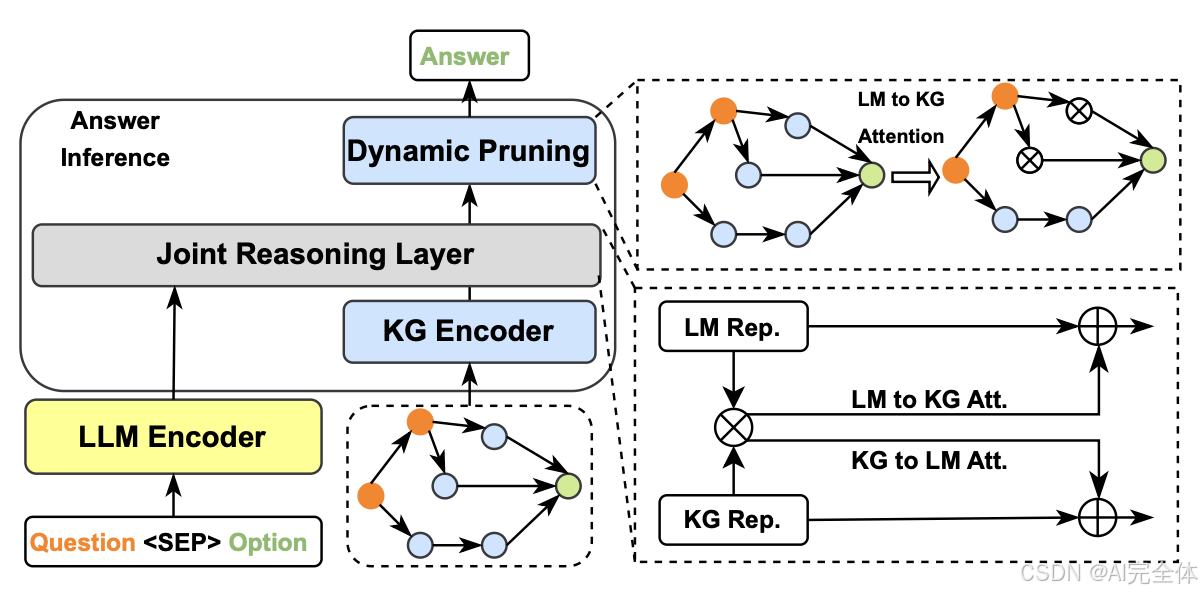
问题: “张三是哪个公司的CEO?”
选项: “公司A”、“公司B”、“公司C”
系统通过以下几个步骤进行推理:
- 输入问题和选项
系统接收问题“张三是哪个公司的CEO?”以及三个候选答案:“公司A”、“公司B”和“公司C”。这些问题和选项被格式化为:
张三是哪个公司的 C E O < S E P > 公司 A 张三是哪个公司的CEO <SEP> 公司A 张三是哪个公司的CEO<SEP>公司A
张三是哪个公司的 C E O < S E P > 公司 B 张三是哪个公司的CEO <SEP> 公司B 张三是哪个公司的CEO<SEP>公司B
张三是哪个公司的 C E O < S E P > 公司 C 张三是哪个公司的CEO <SEP> 公司C 张三是哪个公司的CEO<SEP>公司C
并输入到语言模型编码器(LLM Encoder)。 - 知识图谱编码器(KG Encoder)
同时,系统会从知识图谱中获取与“张三”相关的实体和关系。例如,知识图谱可能包含“张三”与“公司A”之间的“CEO”关系,也可能包含张三与其他公司的关系。知识图谱编码器会将这些信息编码成知识图谱表示。 - 联合推理层(Joint Reasoning Layer)
在这个阶段,系统将问题的语言模型表示和知识图谱表示联合起来,通过联合推理层进行推理。系统会使用双向注意力机制,进行“LM到KG”和“KG到LM”的信息交互。比如,语言模型在处理问题“张三是哪个公司的CEO?”时,会关注与“张三”相关的实体和关系,并从知识图谱中提取到“张三”是“公司A”的CEO的信息。 - 动态修剪(Dynamic Pruning)
在推理过程中,系统会动态地修剪掉与推理任务无关的知识图谱信息。比如,如果知识图谱中有很多无关的关系,如“张三喜欢篮球”或“张三的朋友是李四”等信息,系统会自动去除这些不相关的节点,只保留“张三是公司A的CEO”这样的关键信息。 - 答案推理(Answer Inference)
通过联合推理层的深度交互,系统会生成最终的答案。在这个例子中,系统通过推理发现“张三”与“公司A”之间的关系最为符合“CEO”这一职位,因此系统选择“公司A”作为正确答案。 - LM到KG和KG到LM注意力机制
在推理过程中,语言模型会使用注意力机制专注于问题中的关键实体“张三”和与其相关的知识图谱信息。知识图谱表示中的“CEO”关系和“公司A”的实体会通过双向注意力机制与语言模型表示进行交互,确保模型能够充分理解文本和知识图谱中的关联信息。
在这个例子中,系统通过双向注意力机制和联合推理层结合了语言模型和知识图谱中的信息,通过动态修剪过滤掉不相关的信息,最终得出“张三是公司A的CEO”的答案。
图25
使用LLMs作为代理在知识图谱(KGs)上进行推理
7 未来方向和里程碑
在本节中,我们讨论了统一知识图谱(KGs)和大型语言模型(LLMs)这一研究领域的未来方向和几个关键里程碑。
7.1 用于LLM幻觉检测的知识图谱
LLMs 的幻觉问题,即生成事实不正确的内容,严重影响了 LLMs 的可靠性。正如第4节中讨论的那样,现有研究尝试通过预训练或知识图谱增强的推理来获得更可靠的 LLMs。尽管做出了努力,但在可预见的未来,幻觉问题可能仍将存在于 LLMs 的领域中。因此,为了获得公众的信任并扩展应用领域,检测和评估 LLMs 及其他人工智能生成内容(AIGC)中的幻觉实例至关重要。现有方法试图通过在一小部分文档上训练神经分类器来检测幻觉 [249] ,这些方法既不够稳健,也不足以处理不断增长的 LLMs。最近,研究人员尝试利用知识图谱作为外部来源来验证 LLMs [250] 。进一步的研究将 LLMs 和 KGs 结合,开发通用的事实检查模型,以跨领域检测幻觉 [251] 。因此,利用 KGs 进行幻觉检测开启了新的研究方向。
7.2 用于编辑 LLM 知识的知识图谱
虽然 LLMs 能够存储大量的现实世界知识,但它们无法快速更新其内部知识以应对不断变化的现实情况。已经有一些研究提议可以在不重新训练整个 LLM 的情况下编辑 LLM 中的知识 [252] 。然而,这些解决方案仍存在性能不佳或计算开销过大的问题 [253] 。现有研究 [254] 还表明,编辑单个事实会对其他相关知识产生连锁效应。因此,有必要开发一种更高效且更有效的方法来编辑 LLM 中的知识。最近,研究人员开始尝试利用知识图谱来更有效地编辑 LLM 中的知识。
7.3 用于黑盒 LLM 知识注入的知识图谱
虽然预训练和知识编辑可以更新 LLMs 以跟上最新知识的步伐,但它们仍然需要访问 LLMs 的内部结构和参数。然而,许多最先进的大型 LLMs(如 ChatGPT)仅提供 API 供用户和开发者访问,这使它们对公众而言是一个“黑盒”。因此,无法采用现有的知识注入方法 [38] [244] ,通过添加额外的知识融合模块来改变 LLM 的结构。将各种类型的知识转换为不同的文本提示似乎是一个可行的解决方案。然而,目前尚不清楚这些提示是否能够很好地适用于新的 LLMs。此外,基于提示的方法受限于 LLMs 输入标记的长度。因此,如何实现对黑盒 LLMs 的有效知识注入仍是我们需要探索的一个开放问题 [255] [256] 。
7.4 多模态 LLMs 与知识图谱
当前的知识图谱通常依赖文本和图结构来处理与知识图谱相关的应用。然而,现实世界中的知识图谱通常是由多种模态的数据构建而成的 [99] [257] [258] 。因此,有效利用来自多个模态的表示将成为未来知识图谱研究的一个重要挑战 [259] 。一个潜在的解决方案是开发能够跨不同模态准确编码和对齐实体的方法。最近,随着多模态 LLMs 的发展 [98] [260] ,利用 LLMs 进行模态对齐在这一领域展现出希望。但是,弥合多模态 LLMs 与知识图谱结构之间的差距仍然是该领域的关键挑战,需要进一步的研究和进展。
7.5 LLMs 理解知识图谱结构
传统的 LLMs 是在纯文本数据上训练的,并不设计用于理解像知识图谱这样的结构化数据。因此,LLMs 可能无法完全掌握或理解知识图谱结构所传达的信息。一个直接的方法是将结构化数据线性化为 LLMs 可以理解的句子。然而,知识图谱的规模使得不可能将整个知识图谱线性化为输入。此外,线性化过程可能会丢失知识图谱中的一些底层信息。因此,开发能够直接理解知识图谱结构并在其上进行推理的 LLMs 是必要的 [237] 。
7.6 协同 LLMs 和知识图谱的双向推理
知识图谱和 LLMs 是两种互补的技术,它们可以相互协同。然而,现有研究人员对 LLMs 和知识图谱的协同研究较少。理想的 LLMs 和知识图谱的协同将利用两种技术的优势来克服各自的局限性。LLMs,如 ChatGPT,擅长生成类人文本和理解自然语言,而知识图谱是捕捉和表示知识的结构化数据库。通过结合它们的能力,我们可以创建一个强大的系统,既能利用 LLMs 的上下文理解,又能利用知识图谱的结构化知识表示。为了更好地统一 LLMs 和知识图谱,许多先进技术需要被整合,例如多模态学习 [261] 、图神经网络 [262] 和持续学习 [263] 。最后,LLMs 和知识图谱的协同可以应用于许多现实世界的应用场景,例如搜索引擎 [100] 、推荐系统 [10] [89] 和药物发现。
面对具体的应用问题,我们可以应用知识图谱进行基于知识的搜索,寻找潜在的目标和未见数据,同时从 LLMs 入手,进行基于数据/文本的推理,看看可以推导出哪些新的数据/目标项。当基于知识的搜索与基于数据/文本的推理相结合时,它们可以相互验证,产生高效和有效的解决方案。因此,我们可以预期在不久的将来,越来越多的研究将关注解锁整合知识图谱和 LLMs 的潜力,以同时具备生成和推理能力的多样化下游应用。
8 结论
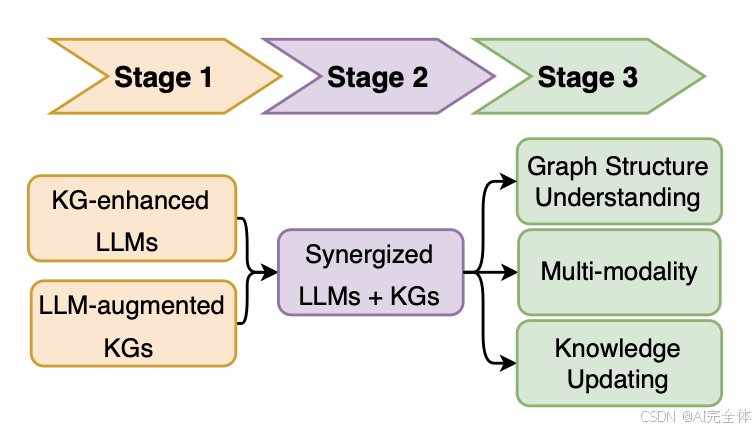
统一大型语言模型(LLMs)和知识图谱(KGs)是一个活跃的研究方向,吸引了学术界和工业界的广泛关注。在本文中,我们对这一领域的最新研究进行了全面概述。我们首先介绍了用于增强 LLMs 的不同知识图谱集成方法。接着,我们介绍了现有的应用 LLMs 进行知识图谱处理的方法,并基于各种知识图谱任务建立了分类法。最后,我们讨论了这一领域的挑战和未来方向。我们预见,在统一 LLMs 和知识图谱的路线图中将会有多个阶段(里程碑),如图26所示。特别是,我们预计在以下三个阶段会有越来越多的研究:阶段1:知识图谱增强的LLMs,LLMs增强的知识图谱,阶段2:协同 LLMs + 知识图谱,阶段3:图结构理解、多模态、知识更新。我们希望本文能够为未来的研究提供指导。
图26
统一 LLMs 和知识图谱的多个阶段(里程碑)
完结撒花
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【AI论文精读5】知识图谱与LLM结合的路线图-P4(完)

发表评论 取消回复