词元化是针对自然语言处理任务的数据预处理中一个重要步骤,目的是将原始文本切分成模型可以识别和处理的词元序列。在大模型训练任务中,就是作为大模型的输入。传统的自然语言处理方法,如基于条件随机场的序列标注,主要采用基于词汇的分词方式,这与我们人类的语言认知更为契合。但是,这种分词方法在中文等语言中,可能会导致对同一输入产生不同的分词结果,从而生成包含大量低频词的庞大词表,并可能出现未登录词(OOV)的问题。因此,一些语言模型开始使用字符作为最小单位进行分词,例如,ELMo 使用了 CNN 词编码器。近年来,子词分词器在基于 Transformer 的语言模型中得到了广泛应用,常见的方法包括 BPE 分词、WordPiece 分词和 Unigram 分词,接下来我们将参考huggingface的材料【1】来分析这几类分词器,并展示每种模型使用的标记器类型的示例。本文首先对BPE进行分享。
1. 原理讲解
字节对编码(BPE, Byte-Pair Encoding tokenization)【2】最初是作为一种文本压缩算法开发的,随后被OpenAI用于预训练GPT模型时的分词。许多Transformer模型都使用了该算法,包括GPT、GPT-2、RoBERTa、BART和DeBERTa。BPE 算法从一组基本符号(如字母和边界字符)开始,迭代地寻找语料库中的两个相邻词元,并将它们替换为新的词元,这一过程被称为合并。合并的选择标准是计算两个连续词元的共现频率,也就是每次迭代中,最频繁出现的一对词元会被选择与合并。合并过程将一直持续达到预定义的词表大小【3】。
BPE训练开始于计算语料库中使用的唯一词汇集(在完成标准化和预分词步骤后),然后通过获取写这些词所用的所有符号来构建词汇表。举个非常简单的例子,假设我们的语料库使用了以下五个词:
"hug", "pug", "pun", "bun", "hugs"
基础词汇表将是["b", "g", "h", "n", "p", "s", "u"]。在实际情况下,该基础词汇表至少会包含所有ASCII字符,并可能包括一些Unicode字符。如果一个例子使用了在训练语料库中不存在的字符,该字符将被转换为未知标记。许多NLP模型在分析包含表情符号的内容时表现不佳的原因可能这个就是其中一种。
GPT-2和RoBERTa的分词器(相似性较高)有一种方法来处理这个问题:它们将词视为由字节组成,而不是Unicode字符。这样基础词汇表的大小就很小(256),但字符仍会被包含在内,而不会被转换为未知标记。这个技巧称为字节级BPE。 字节级别的 BPE(Byte-level BPE, B-BPE)是 BPE 算法的一种扩展,它将字节视为合并操作的基本符号,从而实现更精细的分割,并解决了未登录词的问题。代表性语言模型如 GPT-2、BART 和 LLaMA 都采用了这种分词方法。具体而言,如果将所有 Unicode 字符视为基本字符,基本词表的规模会非常庞大(例如,每个汉字都作为一个基本字符)。而使用字节作为基本字符,可以将词汇表的大小限制在 256,同时确保所有基本字符都包含在内。以 GPT-2 为例,其词表大小为 50,257,包含 256 个字节的基本词元、一个特殊的文末词元,以及通过 50,000 次合并学习到的词元。通过一些处理标点符号的附加规则,GPT-2 的分词器能够有效进行分词,而无需使用 “<UNK>” 符号。
在获得这个基础词汇表后,通过学习合并规则(将现有词汇表中的两个元素合并为一个新元素的规则)添加新标记,直到达到所需的词汇大小。因此,最开始这些合并将创建两个字符的标记,随着训练的进行,合并会生成更长的子词。在分词器训练的任何步骤中,BPE算法都会寻找最常见的现有标记对。最常见的那一对将被合并,然后重复下一步。
回到之前的例子,假设这些词的频率如下:
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
这意味着“hug”在语料库中出现了10次,“pug”5次,“pun”12次,“bun”4次,“hugs”5次。我们通过将每个词拆分为字符(构成我们初始词汇表的字符)开始训练,这样我们就可以将每个词视为标记的列表:
("h" "u" "g", 10), ("p" "u" "g", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "u" "g" "s", 5)
然后查看标记对。标记对("h", "u")出现在“hug”和“hugs”中,因此在语料库中总共出现15次。但这不是最常见的标记对:最常见的对是("u", "g"),出现在“hug”、“pug”和“hugs”中,在词汇表中总共出现20次。因此,分词器学到的第一个合并规则是("u", "g") -> "ug",这意味着“ug”将被添加到词汇表中,并且在语料库中的所有词中都应合并该对。在这个阶段结束时,词汇表和语料库如下所示:
词汇表: ["b", "g", "h", "n", "p", "s", "u", "ug"]
语料库: ("h" "ug", 10), ("p" "ug", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "ug" "s", 5)
现在有一些结果是超过两个字符的标记对:例如,标记对("h", "ug")(在语料库中出现15次)。然而,此时最常见的对是("u", "n"),在语料库中出现16次,因此第二个学习的合并规则是("u", "n") -> "un"。将其添加到词汇表并合并所有现有的出现结果如下:
词汇表: ["b", "g", "h", "n", "p", "s", "u", "ug", "un"]
语料库: ("h" "ug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("h" "ug" "s", 5)
现在最常见的对是("h", "ug"),所以我们学习合并规则("h", "ug") -> "hug",这给我们带来了第一个三字符的标记。合并后,语料库如下:
词汇表: ["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"]
语料库: ("hug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("hug" "s", 5)
然后继续这样处理直到达到所需的词汇大小。
分词紧密跟随训练过程,新输入的分词通过以下步骤完成:
- 标准化
- 预分词
- 将词拆分为单个字符
- 在这些拆分上按顺序应用学习到的合并规则
以刚才使用的例子为例,三条学习到的合并规则为:
("u", "g") -> "ug"
("u", "n") -> "un"
("h", "ug") -> "hug"
单词“bug”将被分词为["b", "ug"]。然而,“mug”将被分词为["[UNK]", "ug"],因为字母“m”不在基础词汇表中。同样,“thug”将被分词为["[UNK]", "hug"]:字母“t”不在基础词汇表中,应用合并规则后首先会合并“u”和“g”,然后合并“h”和“ug”。
2. BPE代码实现
2.1 创建jupyter实验环境
为了快速方便验证代码,因此我们在服务器上安装了jupyter,来进行编程演示。这里记录下安装和部署的方式。
首先服务器上下载安装jupyter:
pip install jupyter
设置登录密码
jupyter notebook password
启动jupyter
jupyter notebook --no-browser --ip=0.0.0.0 --allow-root
访问jupyter-lab
一般域名就是:https://你的服务器ip地址:8888/lab
2.2 代码实现
示例语料库如下
corpus = [
"This is the Hugging Face Course.",
"This chapter is about tokenization.",
"This section shows several tokenizer algorithms.",
"Hopefully, you will be able to understand how they are trained and generate tokens.",
]我们需要将该语料库预分词为单词。这里将使用gpt2分词器进行预分词,国内的话,为了方便,我们依然采用model scope的模型库来操作, 下载gpt2模型到本地并加载,下载大概要花个几分钟的样子:
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
from transformers import AutoTokenizer
model_dir = snapshot_download('AI-ModelScope/gpt2', cache_dir='/root/autodl-tmp', revision='master')
mode_name_or_path = '/root/autodl-tmp/AI-ModelScope/gpt2'
tokenizer = AutoTokenizer.from_pretrained(mode_name_or_path, trust_remote_code=True)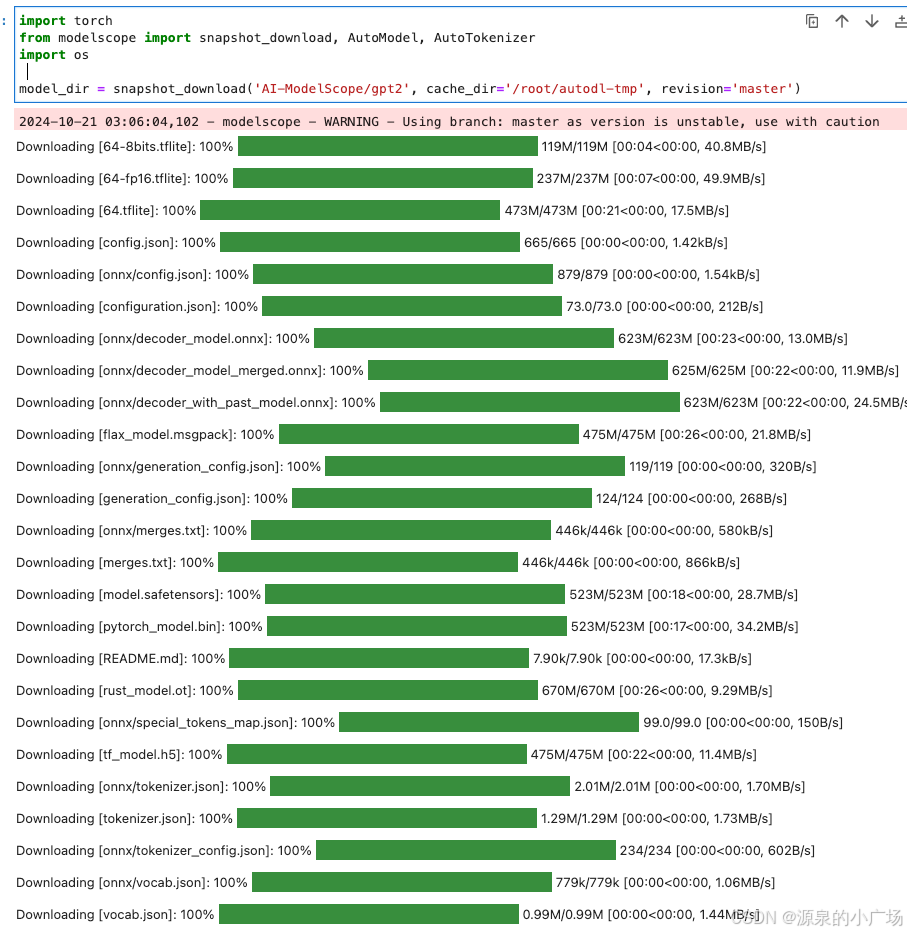
然后,在预分词的同时,我们计算每个单词在语料库中的频率,并且计算基础词汇表,由语料库中使用的所有字符组成,将模型使用的特殊标记添加到词汇表的开头。对于GPT-2,唯一的特殊标记是"<|endoftext|>"。另外说明下:前面带有“Ġ”符号的词(例如“Ġis”、“Ġthe”)通常是在使用字节级别的BPE(Byte-level BPE)分词时生成的。这个符号的作用是标记一个单词是以空格开头的,即这个单词前面有一个空格。这种标记方式在处理文本时有助于保持词与词之间的分隔,使模型能够更好地理解上下文。
from collections import defaultdict
word_freqs = defaultdict(int)
for text in corpus:
words_with_offsets = tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str(text)
new_words = [word for word, offset in words_with_offsets]
for word in new_words:
word_freqs[word] += 1
print(word_freqs)alphabet = []
for word in word_freqs.keys():
for letter in word:
if letter not in alphabet:
alphabet.append(letter)
alphabet.sort()
print(alphabet)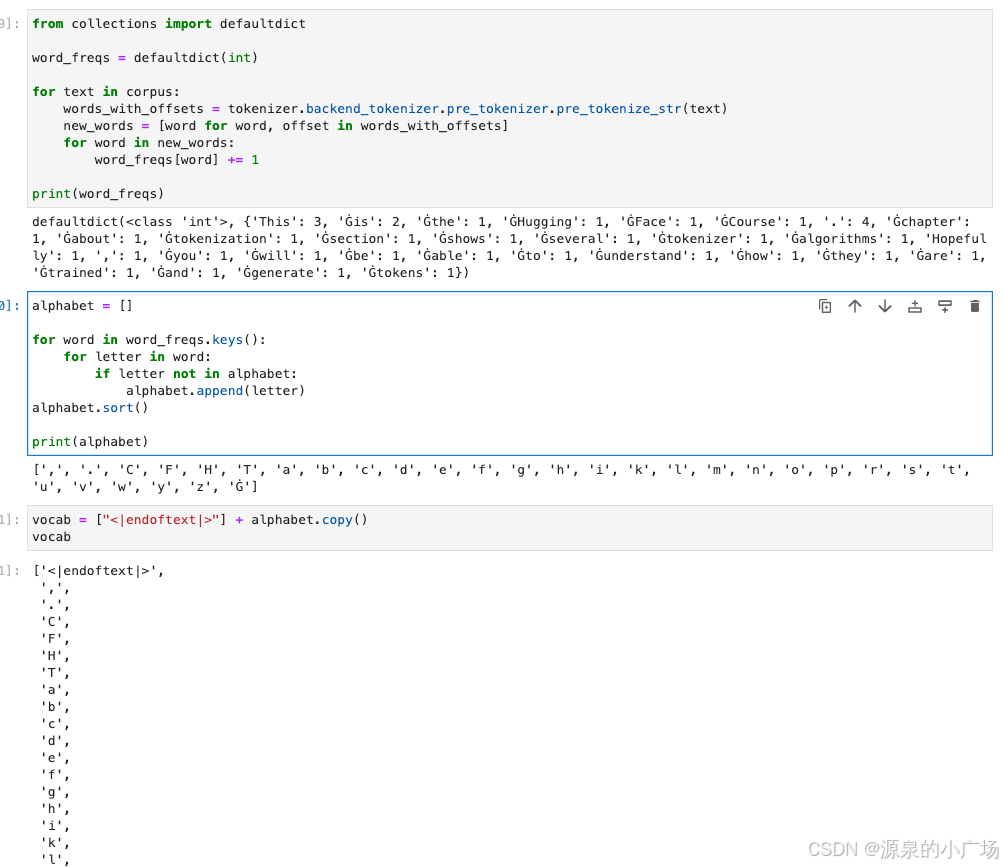
将每个单词拆分为单个字符,以便开始训练。计算每个标记对的频率。找到出现次数最多的词对。
splits = {word: [c for c in word] for word in word_freqs.keys()}def compute_pair_freqs(splits):
pair_freqs = defaultdict(int)
for word, freq in word_freqs.items():
split = splits[word]
if len(split) == 1:
continue
for i in range(len(split) - 1):
pair = (split[i], split[i + 1])
pair_freqs[pair] += freq
return pair_freqs
pair_freqs = compute_pair_freqs(splits)
for i, key in enumerate(pair_freqs.keys()):
print(f"{key}: {pair_freqs[key]}")
if i >= 5:
breakbest_pair = ""
max_freq = None
for pair, freq in pair_freqs.items():
if max_freq is None or max_freq < freq:
best_pair = pair
max_freq = freq
print(best_pair, max_freq)
第一个合并学习的是 ('Ġ', 't') -> 'Ġt',我们将 'Ġt' 添加到词汇表中。接下来,在分割字典中应用这个合并。
merges = {("Ġ", "t"): "Ġt"}
vocab.append("Ġt")def merge_pair(a, b, splits):
for word in word_freqs:
split = splits[word]
if len(split) == 1:
continue
i = 0
while i < len(split) - 1:
if split[i] == a and split[i + 1] == b:
split = split[:i] + [a + b] + split[i + 2 :]
else:
i += 1
splits[word] = split
return splitssplits = merge_pair("Ġ", "t", splits)
print(splits["Ġtrained"])循环,直到学习到我们想要的所有合并。设置目标词汇表大小为 50。
vocab_size = 50
while len(vocab) < vocab_size:
pair_freqs = compute_pair_freqs(splits)
best_pair = ""
max_freq = None
for pair, freq in pair_freqs.items():
if max_freq is None or max_freq < freq:
best_pair = pair
max_freq = freq
splits = merge_pair(*best_pair, splits)
merges[best_pair] = best_pair[0] + best_pair[1]
vocab.append(best_pair[0] + best_pair[1])
print(merges)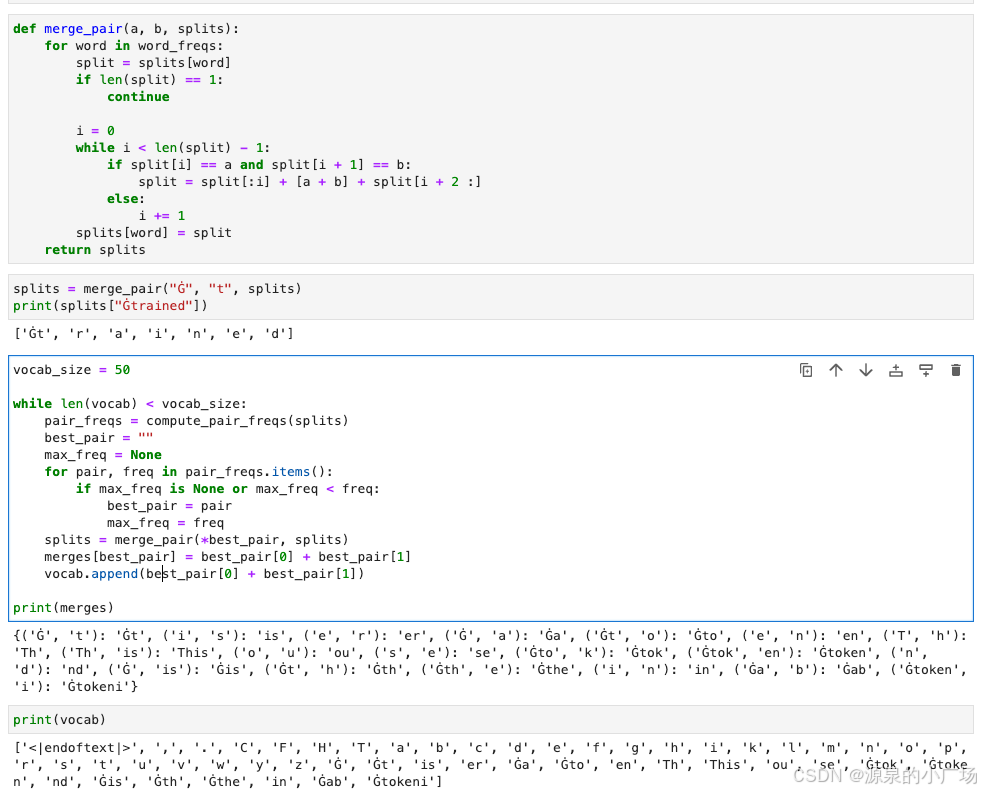
接下来为了对新文本进行分词,先进行预分词,再拆分,然后应用所有学习到的合并规则:
def tokenize(text):
pre_tokenize_result = tokenizer._tokenizer.pre_tokenizer.pre_tokenize_str(text)
pre_tokenized_text = [word for word, offset in pre_tokenize_result]
splits = [[l for l in word] for word in pre_tokenized_text]
for pair, merge in merges.items():
for idx, split in enumerate(splits):
i = 0
while i < len(split) - 1:
if split[i] == pair[0] and split[i + 1] == pair[1]:
split = split[:i] + [merge] + split[i + 2 :]
else:
i += 1
splits[idx] = split
return sum(splits, [])
3. 参考材料
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【大模型实战篇】大模型分词算法BPE(Byte-Pair Encoding tokenization)及代码示例

发表评论 取消回复