完整代码如下
基于朴素贝叶斯的中文垃圾短信分类、垃圾邮件分类。
可用于机器学习课程设计等。
import warnings
warnings.filterwarnings('ignore')
import os
os.environ["HDF5_USE_FILE_LOCKING"] = "FALSE"
import pandas as pd
import numpy as np
from sklearn import metrics
import joblib
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
def read_stopwords(stopwords_path):
"""
读取停用词库
:param stopwords_path: 停用词库的路径
:return: 停用词列表
"""
with open(stopwords_path, 'r', encoding='utf-8') as f:
stopwords = f.read()
stopwords = stopwords.splitlines()
return stopwords
def train():
# 1.1 数据集的路径
data_path = "./dataset/data140152/5f9ae242cae5285cd734b91e-momodel/sms_pub.csv"
# 1.2 读取数据
sms = pd.read_csv(data_path, encoding='utf-8')
# 1.3 划分训练集和测试集 9:1
X = np.array(sms.msg_new)
y = np.array(sms.label)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42, test_size=0.2)
# 2.1 加载停用词库
stopwords_path = r'./dataset/data140152/5f9ae242cae5285cd734b91e-momodel/scu_stopwords.txt'
stopwords = read_stopwords(stopwords_path)
# 3. 文本向量化
# 3.1 设置匹配的正则表达式和停用词
vect = CountVectorizer(token_pattern=r"(?u)\b\w+\b", stop_words=stopwords)
X_train_dtm = vect.fit_transform(X_train)
X_test_dtm = vect.transform(X_test)
# 4.模型搭建
# 4.1 创建朴素贝叶斯
nb = MultinomialNB(alpha=10)
# 4.2 开始训练
nb.fit(X_train_dtm, y_train)
# 4.3 对测试集的数据集进行预测
y_pred = nb.predict(X_test_dtm)
# 4.4 在测试集上评估训练的模型
print("在测试集上的混淆矩阵:")
print(metrics.confusion_matrix(y_test, y_pred))
print("在测试集上的分类结果报告:")
print(metrics.classification_report(y_test, y_pred))
print("在测试集上的f1-score :")
print(metrics.f1_score(y_test, y_pred))
accuracy = metrics.accuracy_score(y_test, y_pred)
print("在测试集上的Accuracy:", accuracy)
# 计算准确率
accuracy = metrics.accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
# 计算精确率
precision = metrics.precision_score(y_test, y_pred)
print("Precision:", precision)
# 计算召回率
recall = metrics.recall_score(y_test, y_pred)
print("Recall:", recall)
# 计算 F1 值
f1 = metrics.f1_score(y_test, y_pred)
print("F1 score:", f1)
# 5. 搭建PIpeLine
# 5.1. 构建PipleLine可以将数据处理和数据分类结合在一起,这样输入原始的数据就可以得到分类的结果,方便直接对原始数据进行预测。
pipeline = Pipeline([
('cv', vect),
('classifier', nb),
])
# 5.2 保存Pipeline
joblib.dump(pipeline, 'sms_spam_pipeline.pkl')
# 5.3 加载Pipeline
new_pipeline = joblib.load('sms_spam_pipeline.pkl')
# 5.4 使用加载的Pipeline进行预测
print(new_pipeline.predict(["乌兰察布丰镇市法院成立爱心救助基金", "感谢致电杭州萧山全金釜韩国烧烤店,本店位于金城路xxx号。韩式烧烤等,价格实惠、欢迎惠顾【全金釜韩国烧烤店】"]))
if __name__ == "__main__":
train()
另提供

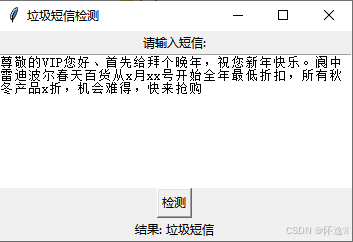
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 基于朴素贝叶斯的中文垃圾短信分类(含ui界面)

发表评论 取消回复