1. 什么是RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象。
代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
RDD类比工厂生产。
2. RDD五大特性
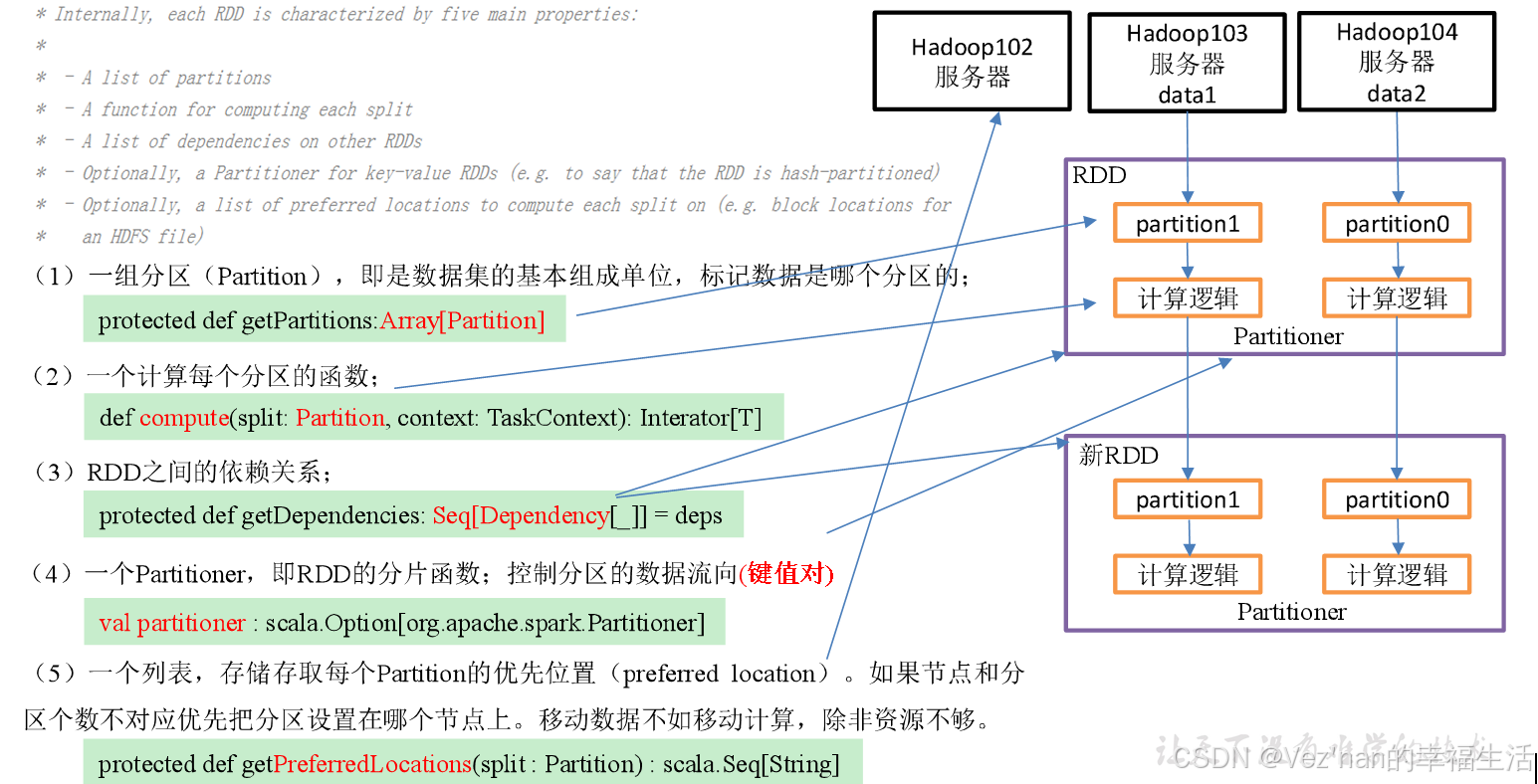
3. RDD的创建
3.1 内存中(集合)创建RDD
object Spark01_RDD_Memory {
def main(args: Array[String]): Unit = {
// TODO 准备环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
// 从内存中创建RDD,将内存中集合的数据作为处理的数据源
// val rdd = sc.makeRDD(List(1, 2, 3, 4))
// makeRDD方法第二个参数不写默认的是,分区个数=cpu的核数
// 如果给了第二个参数,即rdd有两个分区
val rdd = sc.makeRDD(List(1, 2, 3, 4), 2)
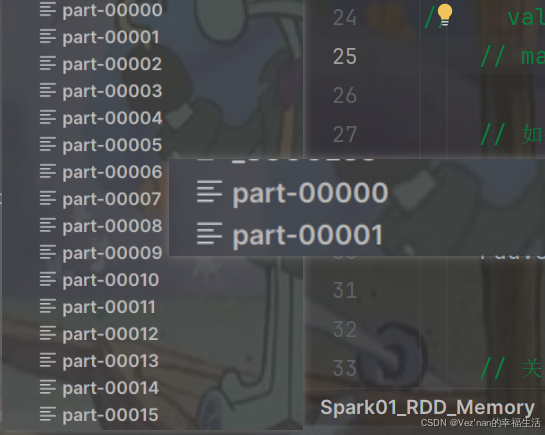
// 将分区信息保存在datas文件夹下
rdd.saveAsTextFile("datas")
// 关闭环境
sc.stop()
}
}
// datas下的文件分区信息
3.2 从外部存储系统的数据集创建
由外部存储系统的数据集创建RDD包括:本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、HBase等。
object Spark01_RDD_File {
def main(args: Array[String]): Unit = {
// TODO 准备环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
// TODO 创建RDD
// 从文件中创建RDD,将文件中的数据作为处理的数据源
// path路径默认当前的环境路径为基准,可以写绝对路径,也可相对路径
// path可以是文件的具体路径,也可以是目录名称
val rdd = sc.textFile("datas/1.txt")
// 以行为单位读取数据
rdd.collect().foreach(println)
// 输出:
//hello scala
//hello spark
//hello java
// TODO 关闭环境
sc.stop()
}
}4. RDD并行度与分区
4.1 内存创建的RDD的分区
默认情况下,Spark可以将一个作业切分为多个任务后,发送给Executer节点开始计算,而能够并行计算的任务数量我们称之为并行度。这个数量可以在创建RDD的时候指定。注意,这里的并行执行的任务数量,并不是指切分任务的数量。
RDD方法可以传递第二个参数,这个参数表示分区的数量。
但第二个参数也可以不传递,那么RDD将使用默认值:查看源码发现:
numSlices: Int = defaultParallelism4.2 文件中创建的RDD分区
可以查看textfire方法中可以传入第二个参数minPartitions,最小分区个数。

minPartitions: Int = defaultMinPartitions
def defaultMinPartitions: Int = math.min(defaultParallelism, 2)如果不传入第二个参数,默认填写的最小分区数 2和环境的核数取小的值 一般为2
5. 集合中分区数据的分配
object Spark01_RDD_Memory_Par1 {
def main(args: Array[String]): Unit = {
// TODO 准备环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
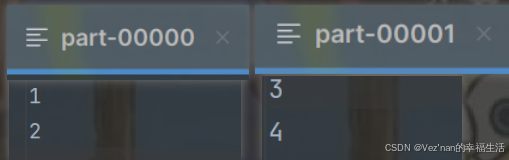
val rdd = sc.makeRDD(List(1, 2, 3, 4), 2)
// 如果makeRDD方法的第二个参数numSlices为2,很容易想到将会创建两个分区
// 一个是1, 2.
// 一个是3, 4
rdd.saveAsTextFile("datas")
// 关闭环境
sc.stop()
}
}
object Spark01_RDD_Memory_Par1 {
def main(args: Array[String]): Unit = {
// TODO 准备环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
// val rdd = sc.makeRDD(List(1, 2, 3, 4), 2)
// 如果makeRDD方法的第二个参数numSlices为2,很容易想到将会创建两个分区
// 一个是1, 2.
// 一个是3, 4
// 如果numSlices为3的话,将会产生三个分区文件,那么4个数据是如何分配到3的分区文件的呢?
val rdd = sc.makeRDD(List(1, 2, 3, 4), 3)
rdd.saveAsTextFile("datas")
// 关闭环境
sc.stop()
}
}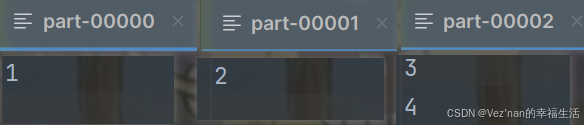
为什么1,2, 3, 4分配到三个分区中分配为什么会是[1], [2], [3, 4]呢
查看源码:
def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = {
(0 until numSlices).iterator.map { i =>
val start = ((i * length) / numSlices).toInt
val end = (((i + 1) * length) / numSlices).toInt
(start, end)
}
}返回一个元组:
以numSlices为3为例:0到3(但取不到3)的迭代器:i从0开始,start计算为:0;end计算得到为:1 * 4 / 3 = 1 => (0, 1)但1取不到,即第一个分区文件为List(1, 2, 3, 4)索引为0的元素。
.......
6. 文件中分区数据的分配
发现textFire方法内有hadoopFire方法。说明spark读取文件的方式是跟hadoop是一样的。
// 具体的分区个数需要经过公式计算
// 首先获取文件的总长度 totalSize
// 计算平均长度 goalSize = totalSize / numSplits
// 获取块大小 128M
// 计算切分大小 splitSize = Math.max(minSize, Math.min(goalSize, blockSize));
// 最后使用splitSize 按照1.1倍原则切分整个文件 得到几个分区就是几个分区
// 实际开发中 只需要看文件总大小 / 填写的分区数 和块大小比较 谁小拿谁进行切分
lineRDD.saveAsTextFile("output");
// 数据会分配到哪个分区
// 如果切分的位置位于一行的中间 会在当前分区读完一整行数据
①分区数量的计算方式:
totalSize = 10
goalSize = 10 / 3 = 3(byte) 表示每个分区存储3字节的数据
分区数= totalSize/ goalSize = 10 /3 => 3,3,4
4子节大于3子节的1.1倍,符合hadoop切片1.1倍的策略,因此会多创建一个分区,即一共有4个分区 3,3,3,1
②Spark读取文件,采用的是hadoop的方式读取,所以一行一行读取,跟字节数没有关系
③数据读取位置计算是以偏移量为单位来进行计算的。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【Spark | Spark-Core篇】RDD(弹性分布式数据集)概述

发表评论 取消回复