
1.大赛背景
在全球人工智能发展和治理广受关注的大趋势下,由中国图象图形学学会、蚂蚁集团、云安全联盟CSA大中华区主办,广泛联合学界、机构共同组织发起全球AI攻防挑战赛。本次比赛包含攻防两大赛道,分别聚焦大模型自身安全和大模型生成内容的防伪检测,涉及信用成长、凭证审核、商家入驻、智能助理等多个业务场景,覆盖机器学习、图像处理与计算机视觉、数据处理等多个算法领域,旨在聚合行业及学界力量共同守护AI及大模型的安全,共同推动AI安全可信技术的发展。
2.赛题二:AI核身-金融场景凭证篡改检测
金融领域交互式自证业务中涵盖信用成长、用户开户、商家入驻、职业认证、商户解限等多种应用场景,通常都需要用户提交一定的材料(即凭证)用于证明资产收入信息、身份信息、所有权信息、交易信息、资质信息等,而凭证的真实性一直是困扰金融场景自动化审核的一大难题。随着数字媒体编辑技术的发展,越来越多的AI手段和工具能够轻易对凭证材料进行篡改,大量的黑产团伙也逐渐掌握PS、AIGC等工具制作逼真的凭证样本,并对金融审核带来巨大挑战。
为此,开设AI核身-金融凭证篡改检测赛道。将会发布大规模的凭证篡改数据集,参赛队伍在给定的大规模篡改数据集上进行模型研发,同时给出对应的测试集用于评估算法模型的有效性。
3.赛题与数据
数据集格式如下:
- 训练集数据总量为100w,提供篡改后的凭证图像及其对应的篡改位置标注,标注文件以csv格式给出,csv文件中包括两列
- 测试集分为A榜和B榜,分别包含10w测试数据。测试集中数据格式与训练集中一致,但不包含标注文件。
采用Micro-F1作为评价指标,该分数越高表示排名越靠前。
4.baseline
本任务可以基于检测模型微调,也允许使用基于大模型的方案等。方案不限于:
小模型微调(例如Faster R-CNN、ConvNeXt(Base)+UPerHead、SegNeXt、VAN(B5)+UPerHead等);
使用大模型(例如SAM、Grounded-SAM等);
多模型协同等。
赛事官方给出的baseline是基于SwinTransformer (Large) + Cascade R-CNN的实验结果。
Datawhale提供的是基于yolov8模型的实验结果。
本任务基于Datawhale提供的是基于yolov8模型的baseline展开。
首先需要下载数据集,数据集很大,训练集包括16个文件夹,接近50G.
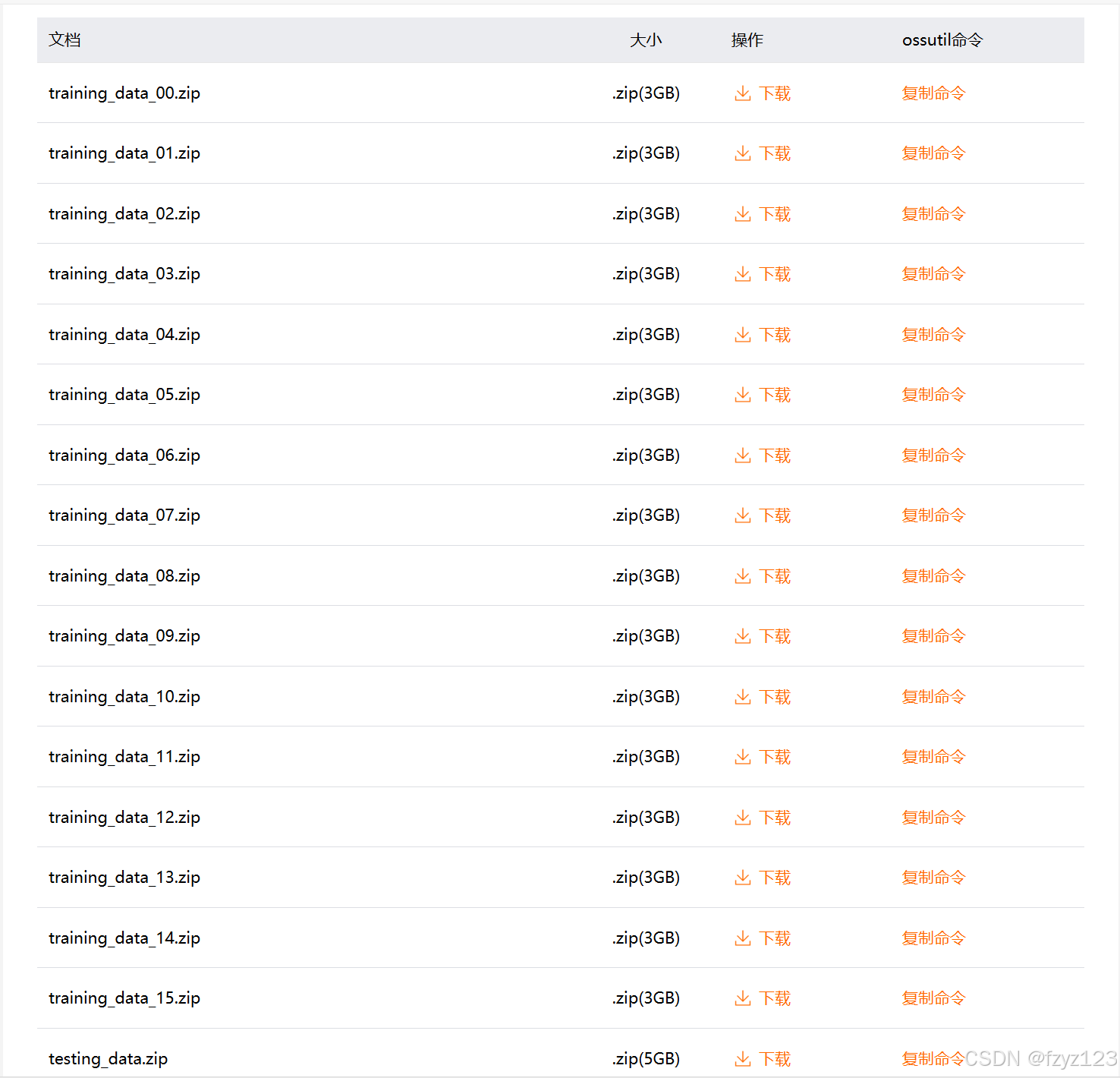
考虑到机器的限制和训练的效率,使用全量数据来跑是不现实的,也是很贵的。全量数据共有100W+。
那么可行的策略
策略一:就是使用1个train_data来跑,比如training_data-00,跑到收敛,然后再用训好的模型去微调其他数据集。可能需要固定一些层的参数,然后比赛截止前再用全量数据微调一下。提交最后的结果;
策略二:自己采样制作数据集,从16个文件夹中,按一定比例采样数据,最终得到约6W的训练数据集,进行训练,直到收敛。然后再全量数据微调。
在数据处理环节,我们可以查看训练集的样本,可以看到样本的类型,这个样本还是很丰富的。
我用的机器是阿里云V100,单卡,训练6W数据的话,50个epoch需要9h。
感觉这种比赛越来越卷,数据越来越大,对机器的要求越来越高,那么这里面应该是有很多算法工程化的小技巧的,应该是有很多优化的tricks的,这些需要通过不断的实践来提高、积累。
接下里记录一些跑baseline中遇到的问题和解决方法。
1.training_anno = pd.read_csv('./seg_risky_training_anno.csv')
这行代码,baseline里面给的是原始URL,运行有一定概率出现Connection的问题,那么我们可以修改为
!axel -n 12 -a http://mirror.coggle.club/seg_risky_training_anno.csv
training_anno = pd.read_csv('./seg_risky_training_anno.csv')2.训练集和验证集的划分
baseline里面默认使用了前10000行作为训练集,10000-10150作为验证集,datatrain_00的6W数据没有数据。我们需要采用随机采样来划分训练集和验证集,验证集的比例为0.1。
代码修改后如下:
#随机采样划分训练集和验证集,验证集占比0.1
import os
import shutil
import cv2
import glob
import json
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
# 定义一个函数,用于归一化多边形的坐标
def normalize_polygon(polygon, img_width, img_height):
return [(x / img_width, y / img_height) for x, y in polygon]
# 随机划分训练集和验证集,验证集比例为0.1
train_df, valid_df = train_test_split(training_anno, test_size=0.1, random_state=42)
# 处理训练集
for row in train_df.iterrows():
shutil.copy(row[1].Path, 'yolo_seg_dataset/train')
img = cv2.imread(row[1].Path)
img_height, img_width = img.shape[:2]
txt_filename = os.path.join('yolo_seg_dataset/train/', row[1].Path.split('/')[-1][:-4] + '.txt')
with open(txt_filename, 'w') as up:
for polygon in row[1].Polygons:
normalized_polygon = normalize_polygon(polygon, img_width, img_height)
normalized_coords = ' '.join([f'{coord[0]:.3f} {coord[1]:.3f}' for coord in normalized_polygon])
up.write(f'0 {normalized_coords}\n')
# 处理验证集
for row in valid_df.iterrows():
shutil.copy(row[1].Path, 'yolo_seg_dataset/valid')
img = cv2.imread(row[1].Path)
img_height, img_width = img.shape[:2]
txt_filename = os.path.join('yolo_seg_dataset/valid/', row[1].Path.split('/')[-1][:-4] + '.txt')
with open(txt_filename, 'w') as up:
for polygon in row[1].Polygons:
normalized_polygon = normalize_polygon(polygon, img_width, img_height)
normalized_coords = ' '.join([f'{coord[0]:.3f} {coord[1]:.3f}' for coord in normalized_polygon])
up.write(f'0 {normalized_coords}\n')3.推理
我们每练一次就会产生一个train文件,推理的时候需要使用最新训练好的模型参数,防止弄错模型导致结果错误。
from ultralytics import YOLO
import glob
from tqdm import tqdm
model = YOLO("./runs/segment/train5/weights/best.pt") #注意更新模型,查看segment/train文件夹,防止弄错模型
test_imgs = glob.glob('./test_set_A_rename/*/*')4.结果提交
原始baseline还存在一个问题,提交的格式不正确,赛事要求的提交格式是

baseline初版给出的是,yolo_seg输出是一堆坐标点,需要转换为满足[左上,右上,右下,左下]格式的矩形框。
代码修改后如下:
# 初始化一个空列表,用于存储每个图像的多边形掩码
Polygon = []
# 使用 tqdm 包装循环,显示进度条
for path in tqdm(test_imgs[:]): # 只处理前10000个图像
# 使用模型对当前图像进行推理
results = model(path, verbose=False) # verbose=False 表示不打印推理过程中的详细信息
# 获取第一个结果(假设模型返回的是一个结果列表)
result = results[0]
# 检查是否有检测到的掩码
if result.masks is None:
# 如果没有检测到掩码,添加一个空列表
Polygon.append([])
else:
# 如果检测到了掩码,将每个掩码转换为所需的格式
processed_masks = []
for mask in result.masks.xy:
# 将每个坐标点转换为浮点数
float_mask = [point.astype(float).tolist() for point in mask]
# 计算边界框的最小和最大坐标
x_coords = [point[0] for point in float_mask]
y_coords = [point[1] for point in float_mask]
min_x, max_x = min(x_coords), max(x_coords)
min_y, max_y = min(y_coords), max(y_coords)
# 构建左上、右上、右下、左下的坐标点
polygon = [
[round(min_x, 1), round(min_y, 1)], # 左上
[round(max_x, 1), round(min_y, 1)], # 右上
[round(max_x, 1), round(max_y, 1)], # 右下
[round(min_x, 1), round(max_y, 1)] # 左下
]
processed_masks.append(polygon)
# 将处理后的多边形添加到 Polygon 列表中
Polygon.append(processed_masks)
# 此时,Polygon 列表中存储了每个图像的多边形掩码,每个多边形由4个顶点组成这里面其实还是存在一些问题的,我查看训练集标签发现的。训练集标签中还存在一些:
1)不规则四边形(非矩形,那么按照代码计算最大最小坐标在生成框应该是不准确的,比如可能存在右下坐标(不是max_x,max_y)比这个最大值小一些,那么按照最大值得到就把这个区域扩大了,其他几个顶点类似),我们无法看到测试集的标签分布,所以无法得知测试集是否存在同样情况;
2)我发现训练集标签还存在一些不是4个点的情况,比如6个点,两个大小矩形连在一起,这种情况在模型中是没有考虑的。
这些可能会影响到最终的得分,不过这是TOP选手需要考虑的哈。
上分情况记录:
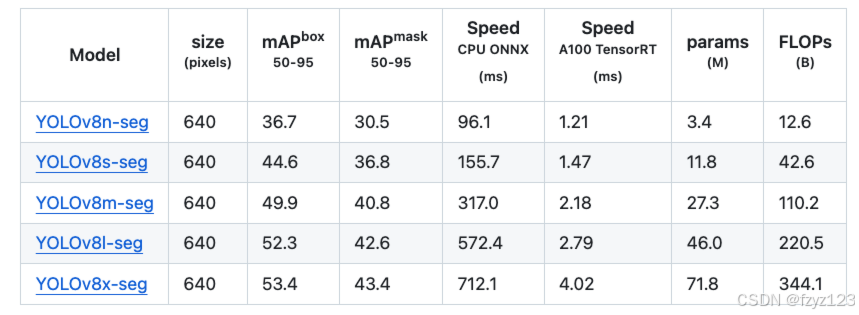
YOLOV8
模型参数
YOLO11
模型参数
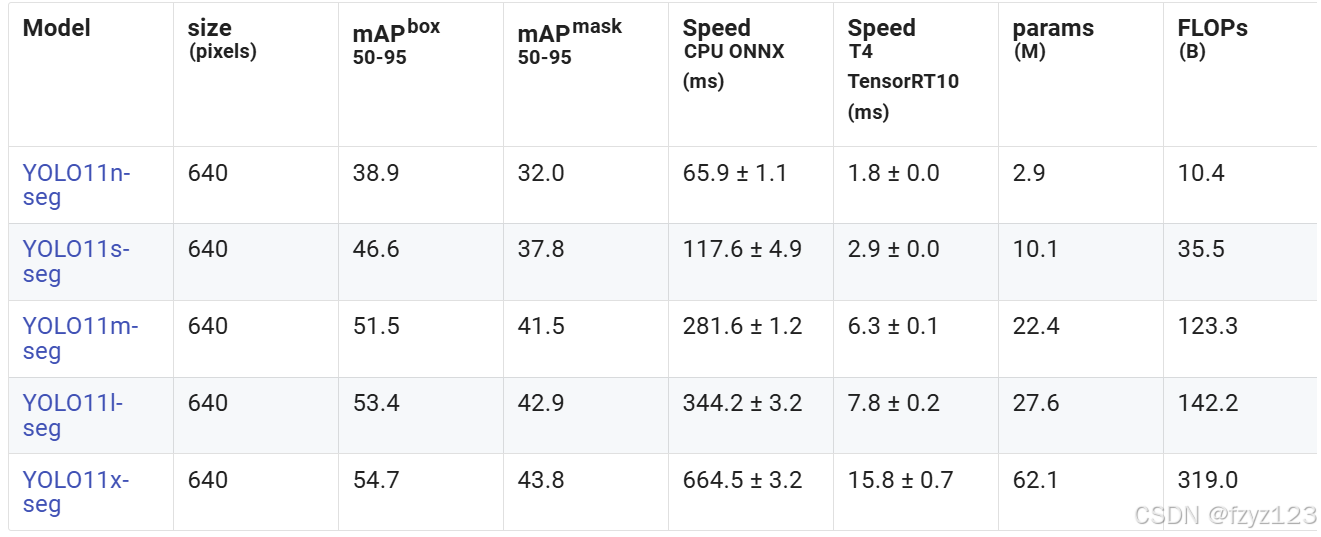
由于我们需要在有限的资源下,去尽可能取得高分,对比YOLOv8和YOLO11的模型预训练参数,综合考虑下来选择YOLO11s或者YOLO11l可能效果会更好。
目前自己跑下来的情况,YOLOv8n,跑data0文件6W数据,因为没有连续跑,一共跑了10+50+50+90轮,得分情况如下:从60轮到200轮,提分2分。
训练仍未收敛,预计还需要继续跑,不过感觉后面提分情况有限了。
后面准备跑一下YOLO11s看看效果。

本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 从零入门AI篡改图片检测(金融场景)#Datawhale十月组队学习

发表评论 取消回复