缓存
介绍缓存 & 用redis作为mysql的缓存
Redis最主要的用途有三个方面:
1.作为数据库(内存数据库)
2.作为缓存。
3.消息队列。
其中作为数据库和缓存是比较常见的,其中作为缓存的情况则是最多的。
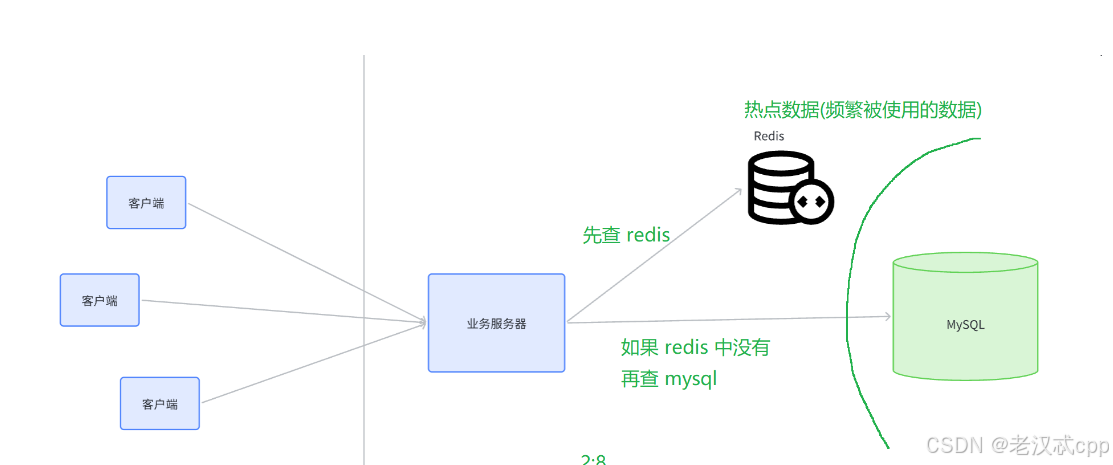
缓存之所以能够有意义,是因为数据的访问大多遵循 “二八” 原则,即20%的数据能够满足80%的访问量。 这样我们就能把这20%的数据(高频访问的数据)放在缓存中, 就可以应付大多数场景,从而在整体上有明显的性能提升。
因此, 如果访问数据库的并发量⽐较⾼, 对于数据库的压⼒是很⼤的, 很容易就会使数据库服务器宕机。
实际开发中,这两种方案一般都是搭配使用的。
Redis 就是⼀个⽤来作为数据库缓存的常⻅⽅案
就像⼀个 "护盾" ⼀样, 把 MySQL 给罩住了。
缓存更新策略
1.定期生成

定期生成策略的优点:
实现比较简单,过程比较可控,方便排查问题。
缺点:
实时性不够。比如对于某一些突发事件,有一些本来不是热词的内容成为了热词,此时就会给后面的数据库(比如mysql)带来不小的压力。
2.实时生成
当redis的内存达到上限时,如果继续插入数据,就会触发问题,在这里redis就引入了“内存淘汰策略”(经典面试题)。
关于redis的内存上限不一定指机器的内存上限,在redis的配置文件中也可以配置redis最多使用多少内存。
内存淘汰策略
重点
其中这个随机淘汰的策略显然是不太合理的,所以一般不会用到。
这些策略不仅仅局限于redis,其它缓存也可以按照这些策略展开。
另外这些策略我们可以自己实现出来,也可以直接使用redis内置的淘汰策略。
redis内置的淘汰策略:
缓存预热, 缓存穿透, 缓存雪崩 和 缓存击穿
这是重点内容,面试常考,工作常用。
缓存预热 (Cache preheating)
定期生成这种缓存更新策略是不涉及到预热的,预热主要是针对实时生成的。
缓存穿透 (Cache penetration)
缓存穿透产生的原因:
其中业务设计不合理是比较典型的一种情况。
一些解决缓存穿透的方案:
通过改进业务/加强监控报警。这个是属于一种亡羊补牢的方案。
更靠谱一点的方法有(降低问题的严重性):
1.先对查询的参数进行严格的合法性校验。比如要查询的key是一个qq邮箱,那么就需要先校验这个key是否符合qq邮箱的格式。
2.针对数据库上不存在的key,可以将这个信息存储到redis上,比如将这个key的value值设置成一个"",也就是空字符(或者其它表示非法值的值),这样就能避免后续频繁因为这个key访问到数据库。
3.可以引入一个布隆过滤器,通过hash + 位图(bitmap)的一个数据结构可以以较小的空间和时间开销,来判定一个key是否存在。
缓存雪崩 (Cache avalanche)
短时间内⼤量的 key 在缓存上失效, 因此很多请求就都打到数据库上了,导致数据库压⼒骤增, 甚⾄直接宕机。
可能产生的原因:
1.redis直接挂了。 redis宕机 或者 redis集群下大量节点宕机。
2.redis没问题,但是有大量的key同时过期了。有可能在短时间内缓存内设置了大量过期时间相同的key导致的。
解决方法:
1.加强监控警报,提高redis集群的可用性。
2.不给key设置过期时间 或者 在设置过期时间时加入一些随机因子。
缓存击穿 (Cache breakdown)

缓存击穿相当于缓存雪崩的特殊情况. 针对热点 key , 突然过期了, 导致⼤量的请求直接访问到数据库上, 甚⾄引起数据库宕机。
这里热点的key访问频率高,造成的影响更大。
解决方法:
1.基于统计的方式发现热点的key,并且设置永不过期。
2.进⾏必要的服务降级. 例如访问数据库的时候使⽤分布式锁, 限制同时请求数据库的并发数。
服务降级可以理解为手机的省电模式,就是关闭一些不那么必要的功能,保留核心功能。
分布式锁在这里就是限制访问数据库的频率,对数据库起到保护作用。
分布式锁
什么是分布式锁?
在学Linux的时候,我们接触到过线程安全问题
关于线程安全问题:因为多个线程并发执行的顺序是不确定的,也就是具备随机性,我们需要保证线程程序在任意执行顺序下执行逻辑都是OK的。最常见的方案就是加入互斥锁,但是互斥锁的本质只是在一个进程内生效的,而在分布式系统中,这都不是同一个进程的问题了,这都不同主机了,那么这种锁肯定就是无效的了。
在分布式系统的场景下(卖车票场景):
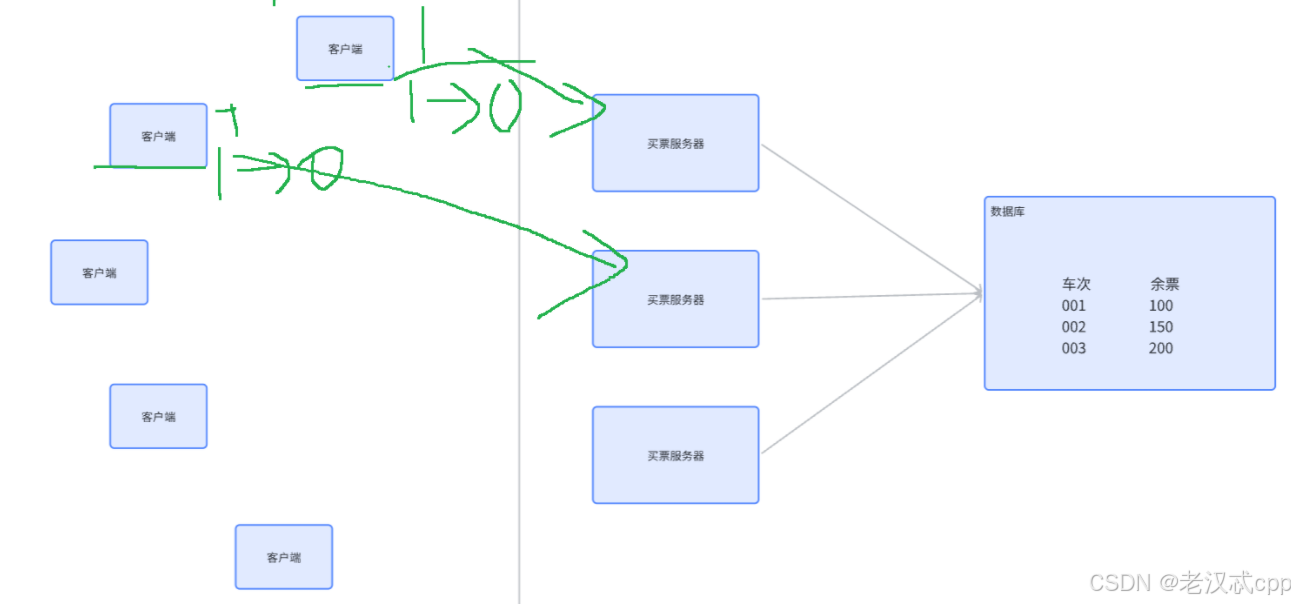
所谓分布式锁,其实也是一个/一组 单独的服务器程序,专门给其它的服务器提供“加锁”的服务。
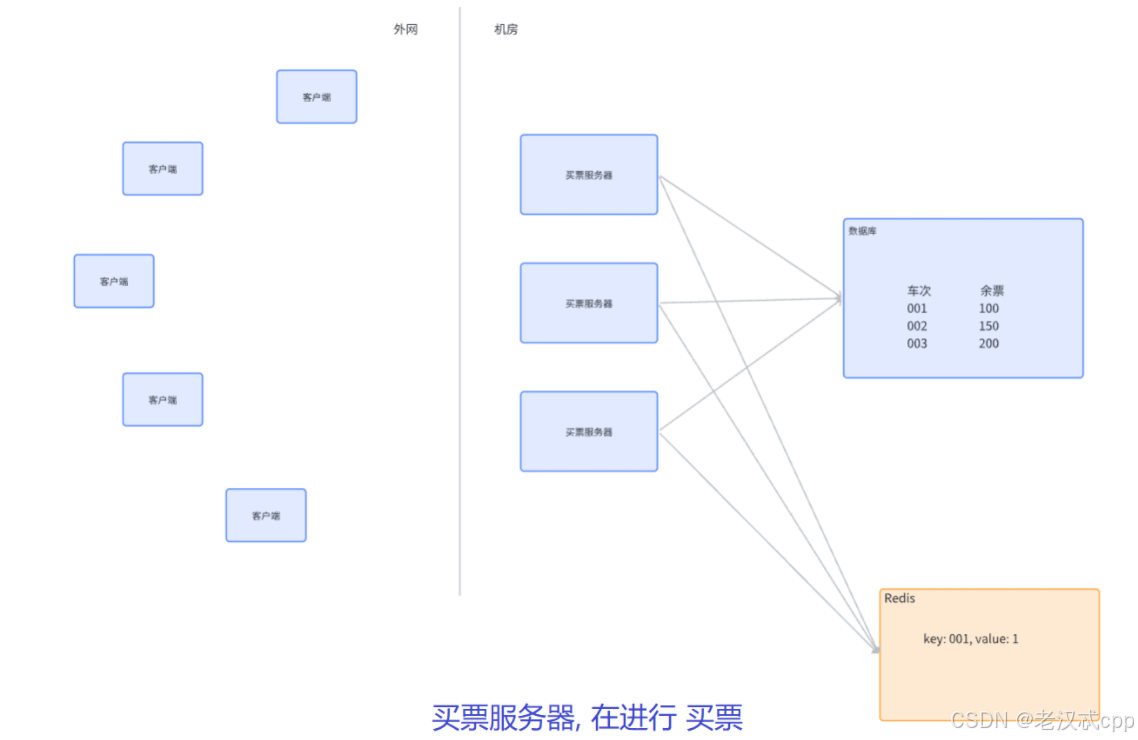
如上图,这样买票服务器在买票前,会先申请一个分布式锁,申请成功了,才能买票成功。
Redis是一种典型的可以用来实现分布式锁的方案(就是上图的Redis服务器), 但不是唯一的一种,业界也可能采用 mysql / zookeeper 这样的组件来实现分布式锁的效果。

这里看似很简单,但是有很多的细节,接下来就开始介绍。
引入setnx
这个申请锁的过程其实就是服务器向redis申请设置一个key - value,如果key不存在,那么就设置成功, 也就是申请锁成功,反之就是失败了。
释放锁就是将之前set的key给删掉即可。
而我们之前学过一个setnx,刚好就能应付这个场景:
setnx,如果key存在那么就会出错返回;如果不存在那么就设置成功。
这里就会出现一个问题:
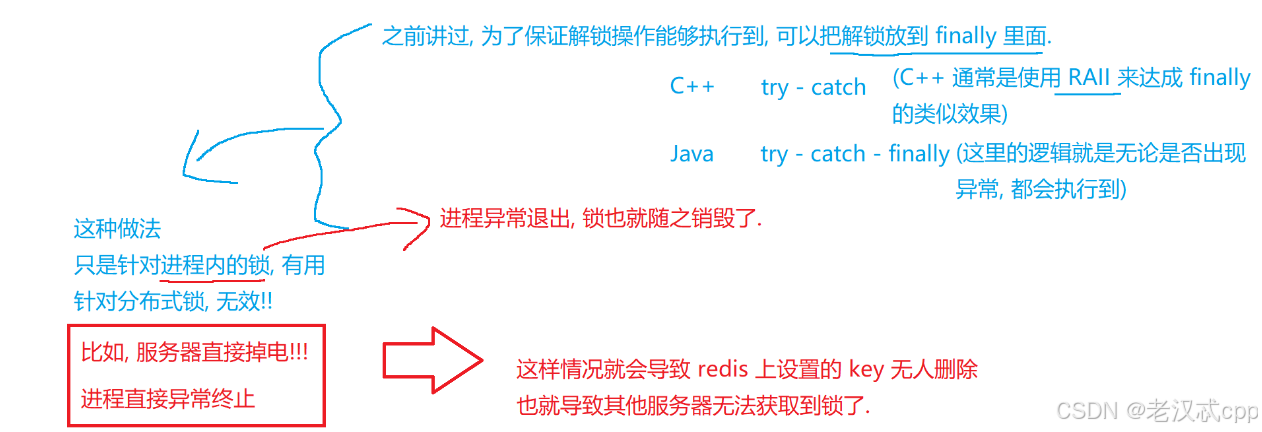
setnx确实可以实现 “加锁”的效果,解锁就是用del即可。但是如果某个服务器加锁成功了,执行后续的逻辑时程序崩溃了(或者服务器都没了),也就是还没有执行到解锁操作,这样就导致了后续其它的服务器申请锁时会一直失败(失败后是放弃还是阻塞就看具体实现了)。
引入过期时间
为了解决上述因为服务器在执行逻辑时,程序崩溃没有执行解锁操作,导致后续其它服务器申请锁一直失败的问题,我们可以给设置的key加入过期时间。
此时需要用的命令就是 set ex nx了,setnx不能设置过期时间。

注意:不要使用
setnx
expire这样的方式来设置带有过期时间的key,因为redis对于多个命令是无法保证原子性的(这里的原子性指不能像mysql那样可以回滚的原子性),所以务必要使用 set ex nx的方式。
引入校验id
所谓加锁,就是给redis设置一个 key-value。
所谓解锁,就是将redis上的这个key-value删除掉。
然而有可能会出现一种情况:
服务器1加的锁,被服务器2解掉了。
虽然正常来说,服务器2不会故意执行这样的操作,但是保不齐代码中有bug,这样可能就给整个系统带来更严重的问题(比如超卖)。
所以为了解决这个问题,就需要引入一些校验机制:
1.给每个服务器加上一个编号id,用于标识自己的身份。
2.进行加锁的时候,设置key - value的时候,key表示要对哪个资源加锁(比如列车车次),value则是这个加锁的服务器的id。
这样后续解锁的时候,就可以进行一个身份校验了。

引入lua脚本
到这里,我们知道解锁的时候大致分为两步:
1.先进行身份校验(向服务器查询id)。
2. 再进行del解锁。
这里顺便提醒一下,进行身份校验的工作一般也是在服务器上完成的。
可见这里的解锁操作并不是原则的,在一个服务器内部往往会有多个线程,也就是说同一个服务器,可能会有多个线程同时在解锁。
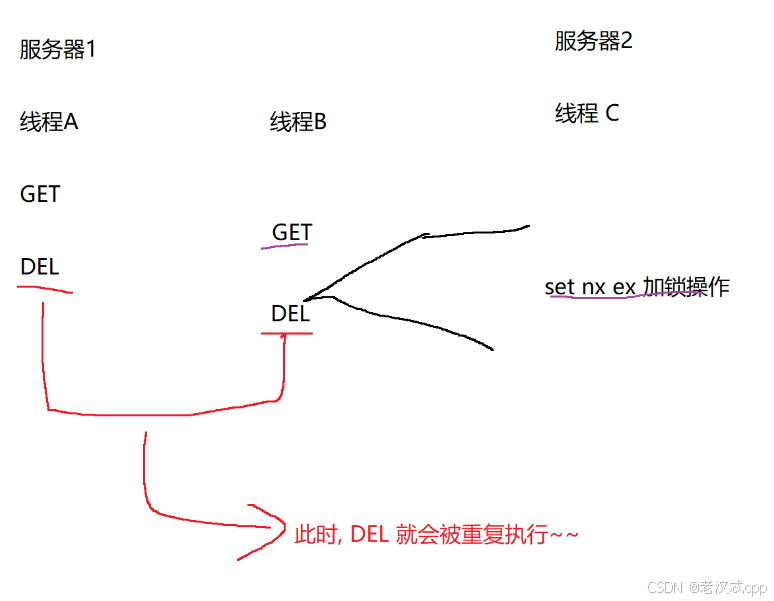
如上图,这样就可能会出现del被重复执行,也就是重复解锁,如果在两次解锁期间,有一个线程执行了一次加锁操作,那么这个锁可能立马就被解掉了。
这个问题归根结底还是因为get和del 不是原子操作导致的。
我们可以使用redis的事务解决上述问题,虽然redis的事务是弱原子性的,但是能避免插队。但是还有一个更好的解决方案:就是使用lua脚本。

在redis的官方文档都说使用lua是事务的替代方案。

使用lua脚本完成解锁的过程:
if redis.call('get',KEYS[1]) == ARGV[1] then
return redis.call('del',KEYS[1])
else
return 0
end;引⼊ watch dog (看⻔狗)
之前说过可以给key引入一个过期时间,这样就能防止因为服务器挂掉却没有及时释放锁的问题。
然而这里仍然存在一个重要的问题,那就是当这个key过期以后,这个任务可能还没有执行完,这样就导致锁提前失效了。
这里更好的方式就是“动态续约”。我们可以为这个服务器专门搞一个线程,负责续约这个问题。
这个线程就称为 看门狗 。

假设我们给这个key初始设置1s后过期,当过期时间只有300ms(数值可以灵活调整)的时候,如果当前任务还没有完成,那么就把过期时间加上1s,如果还没完成就继续续约。
如果此时就算服务器崩溃了,那么也会在短时间内把锁释放掉。
引⼊ Redlock 算法
即便已在这么多的方案的加持下,还是免不了一些极端的情况。
主节点和从节点之间的数据同步是有延迟的,假如redis收到了 set加锁的请求,但是主节点还没来得及同步给从节点,自己就挂了,即使从节点升级称为了主节点,但是刚刚加锁的数据还是不存在了。为了解决这个问题, Redis 的作者提出了 Redlock 算法。
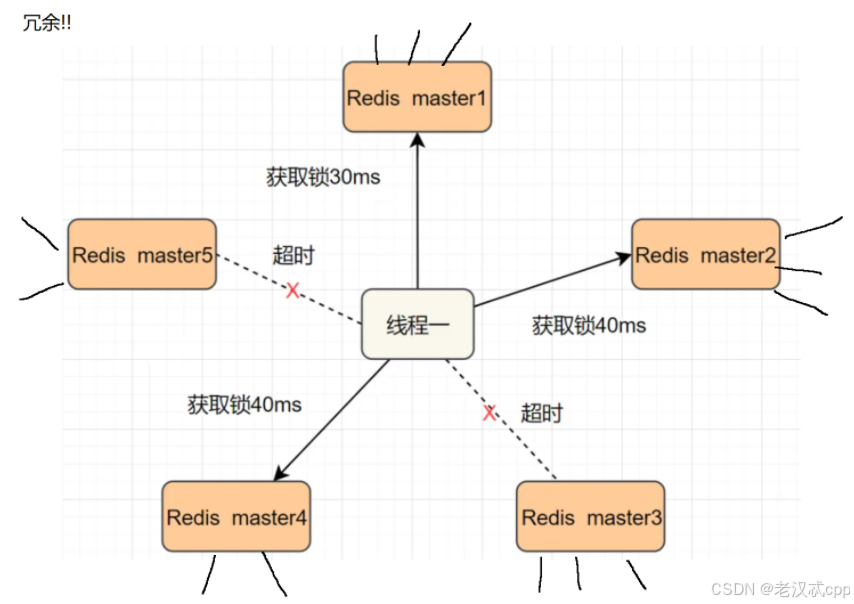
此时的redis就不是一组redis了,而是引入了多组redis,每组redis都包含了一个主节点和多个从节点,并且组和组之间的数据都是一致的,互相为一个“备份”的关系,目的就是为了备份数据(注意这里不是集群)。
如上图有5组redis,其中有3组加锁成功了,那么就视为加锁成功。
这样即便有些节点挂了,也不影响锁的正确性。
小总结:
这里介绍的只是一个简单的“互斥锁”。

这里对redis的学习就告一段落了,如果还想继续深入学习redis可以阅读redis的源码

本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Redis 缓存 && 分布式锁

发表评论 取消回复