
这篇博客主要讲一下如何将word2vec的思想运用于电子电离(EI)质谱(MS)编码(embedding)。
模型:
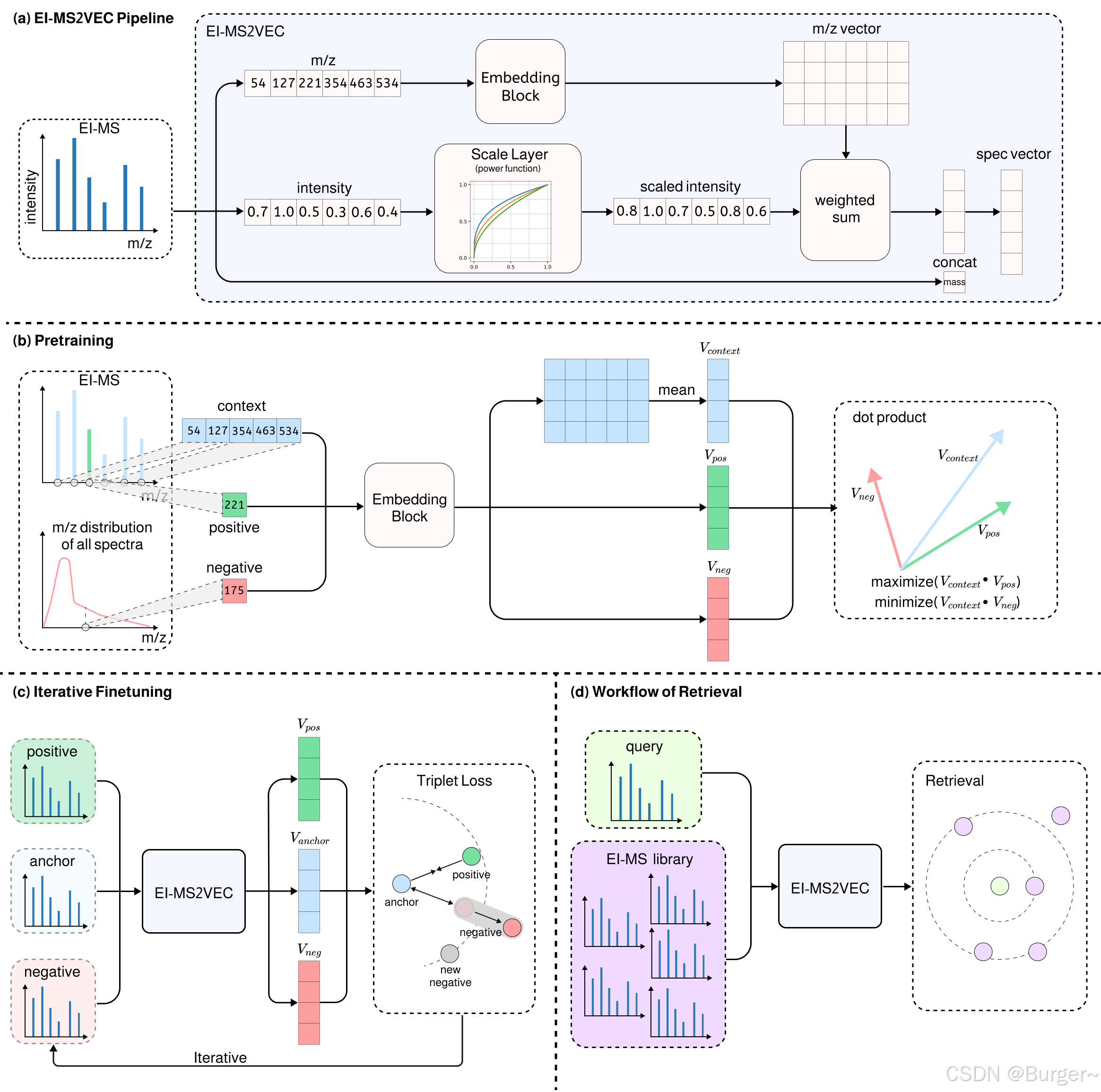
(a)EI-MS2VEC Pipeline
对于一个电子电离质谱,可以得到三部分信息:一是峰的质核比,二是峰的强度,三是分子的质量。
质荷比送入embedding block进行编码,强度通过幂次函数进行放缩;将编码后的m/z vector与放缩后的强度相乘(broadcast),然后在峰的数量那一个维度上求和;得到的向量与mass进行拼接,得到最终的Spec vector。
(b)预训练
这里引入word2vec的概念,包括:上下文、正中心词、负中心词、词汇表、负采样。
质谱中的任何一个峰都可以被选做正中心词,剩下的峰就作为上下文;所有质谱的质核比出现的频次,形成词汇表,按照频率从词汇表中选取质荷比作为负中心词。上下文、正中心词、负中心词都送入embedding block进行编码,其中上下文的向量要在峰数量那一维度上求平均。
训练任务是最大化上下文与正中心词向量的点积,最小化上下文与负中心词向量的点积。
(c)迭代微调
对于每一个查询谱(anchor),我们可以找到它的匹配(positive)和最近的错配(negative)。我们的目标是让模型区分匹配和错配,也就是让anchor与positive尽可能地靠近,让anchor与negative尽可能地远离,所以使用三元组损失函数。
计算完loss之后重复这一过程,对每一个查询谱继续寻找它的匹配和错配。
(d)检索流程
对于查询谱(实验谱)和库中的谱(预测谱),我们都将它们通过EI-MS2VEC得到相应的embeddings,然后利用embeddings进行检索,就可以检索到与查询谱对应的库中的谱。
代码:
完整的项目代码放在了Github:LiuBurger/EI-MS2VEC上面,这里只展示最重要的代码。
model:
class Spec2Emb(nn.Module):
def __init__(self, num_emb:int=1000, emb_dim:int=500):
super(Spec2Emb, self).__init__()
self.max_exp = 6
self.emb_con = nn.Embedding(
num_embeddings=num_emb,
embedding_dim=emb_dim,
)
self.emb_cen = nn.Embedding(
num_embeddings=num_emb,
embedding_dim=emb_dim,
)
self.trip_loss = nn.TripletMarginLoss(margin=1.0, p=2)
def _compute_embedding(self, mzs, intens, masks, power):
embs = self.emb_cen(mzs)
embs = embs * masks.unsqueeze(-1)
intens = pt.pow(intens, power).unsqueeze(-1)
embs = (embs * intens).sum(dim=1)
return embs
def forward(self, data, mode:str='train', power:float=0.5):
if mode == 'train':
mzs_con, masks_con, poss_cen, batch_idx, negs_cen, masks_neg = data
embs_con = self.emb_con(mzs_con) # [batch, seq, emb_dim]
embs_pos = self.emb_cen(poss_cen) # [B, emb_dim]
embs_neg = self.emb_cen(negs_cen) # [B, neg_num, emb_dim]
embs_neg *= masks_neg.unsqueeze(-1)
# for every cen word its context words
embs_con = embs_con[batch_idx] * masks_con.unsqueeze(-1)
embs_con = embs_con.sum(dim=1) / masks_con.sum(dim=1).unsqueeze(-1) # [B, emb_dim]
pos_score = (embs_con * embs_pos).sum(dim=-1) # 点积
pos_score = pt.clamp(pos_score, max=self.max_exp, min=-self.max_exp)
pos_score = -F.logsigmoid(pos_score)
neg_score = pt.bmm(embs_neg, embs_con.unsqueeze(-1)).squeeze(-1) #
neg_score = pt.clamp(neg_score, max=self.max_exp, min=-self.max_exp)
neg_score = -F.logsigmoid(-neg_score).sum(dim=-1)
return (pos_score + neg_score).sum()
elif mode == 'emb': # emb模式下的masks只mask掉了padding
mzs_all, intens_all, masks_all = data # [batch, seq]
return self._compute_embedding(mzs_all, intens_all, masks_all, power)
elif mode == 'finetune':
data_mea, data_pre_hit, data_pre_nhit = data
embs_mea = self._compute_embedding(*data_mea, power)
embs_pre_hit = self._compute_embedding(*data_pre_hit, power)
embs_pre_nhit = self._compute_embedding(*data_pre_nhit, power)
# batchsize, emb_dim
embs_mea = F.normalize(embs_mea, p=2, dim=-1)
embs_pre_hit = F.normalize(embs_pre_hit, p=2, dim=-1)
embs_pre_nhit = F.normalize(embs_pre_nhit, p=2, dim=-1)
# batchsize
loss = self.trip_loss(embs_mea, embs_pre_hit, embs_pre_nhit)
return loss
else:
raise ValueError('mode not exist')dataset:
class SpecDataset(Dataset):
def __init__(self, dataset, mapping=None):
super(SpecDataset, self).__init__()
if isinstance(dataset, list):
self.spectra = dataset
self.map = np.arange(len(dataset), dtype=np.int64)
else:
self.spectra = dataset.spectra
self.map = mapping
def __getitem__(self, idx):
idx_ = self.map[idx]
mzs = self.spectra[idx_].mz.astype(int).tolist()
intens = self.spectra[idx_].intensities
return deepcopy(mzs), deepcopy(intens)
def __len__(self):
return len(self.map)
class SpecDataset_finetune(Dataset):
def __init__(self, dataset, mapping=None):
super(SpecDataset_finetune, self).__init__()
if isinstance(dataset, tuple):
self.spec_mea = dataset[0]
self.spec_pre = dataset[1]
self.map = tuple([np.arange(len(dataset[0]), dtype=np.int64),
np.arange(len(dataset[1]), dtype=np.int64),
np.arange(len(dataset[1]), dtype=np.int64)])
else:
assert isinstance(mapping, tuple), 'mapping should be tuple'
self.spec_mea = dataset.spec_mea
self.spec_pre = dataset.spec_pre
self.map = mapping
def __getitem__(self, idx):
idx_mea = self.map[0][idx]
idx_pre_hit = self.map[1][idx]
idx_pre_nhit = self.map[2][idx]
mzs_mea = self.spec_mea[idx_mea].mz.astype(int).tolist()
intens_mea = self.spec_mea[idx_mea].intensities
mzs_pre_hit = self.spec_pre[idx_pre_hit].mz.astype(int).tolist()
intens_pre_hit = self.spec_pre[idx_pre_hit].intensities
mzs_pre_nhit = self.spec_pre[idx_pre_nhit].mz.astype(int).tolist()
intens_pre_nhit = self.spec_pre[idx_pre_nhit].intensities
return (deepcopy(mzs_mea), deepcopy(intens_mea)), \
(deepcopy(mzs_pre_hit), deepcopy(intens_pre_hit)), \
(deepcopy(mzs_pre_nhit), deepcopy(intens_pre_nhit))
def __len__(self):
return len(self.map[0])collate function:
def collate_fun(keep_prob:np.array, neg_prob:np.array, neg_num:int=5, min_len_mz:int=10, min_inten:float=0.01):
neg_choice = np.arange(neg_prob.shape[0])
def collate_fn(batch):
# con: context, cen: center
mzs_con, masks_con, poss_cen, batch_idx, negs_cen, masks_neg = [], [], [], [], [], []
max_len = max([len(mz) for mz, _ in batch])
idx = 0
for mz, inten in batch:
len_mz = len(mz)
if len_mz >= min_len_mz: # 移除峰的数量小于阈值的质谱
pad_num = max_len - len_mz
pos_cen = []
mask_down = np.random.random(len_mz) < keep_prob[mz]
for i in range(len_mz):
if mask_down[i] and inten[i] > min_inten: # 如果没有被mask掉
mask_pos_down = np.array(mask_down)
mask_pos_down[i] = False
if np.any(mask_pos_down): # 上下文没有被全部mask掉
pos_cen.append(mz[i])
masks_con.append(np.pad(mask_pos_down, (0, pad_num)))
if len(pos_cen) == 0: # 整个质谱中的中心词都被mask掉了
continue
mzs_con.append(np.pad(mz, (0, pad_num)))
poss_cen.extend(pos_cen)
batch_idx.extend([idx] * len(pos_cen))
idx += 1
neg_cen = np.random.choice(neg_choice, (len(pos_cen), neg_num), p=neg_prob)
mask_neg = (neg_cen != np.array(pos_cen)[:, np.newaxis])
negs_cen.append(neg_cen)
masks_neg.append(mask_neg)
if len(mzs_con) == 0:
return None
mzs_con = pt.tensor(np.array(mzs_con), dtype=pt.long)
masks_con = pt.tensor(np.array(masks_con), dtype=pt.bool)
poss_cen = pt.tensor(np.array(poss_cen), dtype=pt.long)
batch_idx = pt.tensor(np.array(batch_idx), dtype=pt.int)
negs_cen = pt.tensor(np.concatenate(negs_cen), dtype=pt.long)
masks_neg = pt.tensor(np.concatenate(masks_neg), dtype=pt.bool)
return mzs_con, masks_con, poss_cen, batch_idx, negs_cen, masks_neg
return collate_fn
def collate_fun_emb(batch):
mzs_con, intens_con, masks = [], [], []
max_len = max([len(mz) for mz, _ in batch])
for mz, inten in batch:
len_mz = len(mz)
pad_num = max_len - len_mz
mz_con = np.pad(mz, (0, pad_num))
inten_con = np.pad(inten, (0, pad_num))
mask = np.pad(np.ones_like(mz, dtype=np.bool_), (0, pad_num))
mzs_con.append(mz_con)
intens_con.append(inten_con)
masks.append(mask)
mzs_con = pt.tensor(np.array(mzs_con), dtype=pt.long)
intens_con = pt.tensor(np.array(intens_con), dtype=pt.float)
masks = pt.tensor(np.array(masks), dtype=pt.bool)
return mzs_con, intens_con, masks
def collate_fun_finetune(batch):
data_mea = [data[0] for data in batch]
data_pre_hit = [data[1] for data in batch]
data_pre_nhit = [data[2] for data in batch]
return collate_fun_emb(data_mea), collate_fun_emb(data_pre_hit), collate_fun_emb(data_pre_nhit)有问题欢迎在评论区讨论!
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » EI-MS2VEC

发表评论 取消回复