现有的背景:
我们需要把几千万企业挂靠到一个或多个国家二级行业(企业在国民经济行业分类里隶属的行业类别,分类有农、林、牧、渔业等),使用当前的大模型或传统的BERT模型存在准确率低或性能差的问题,不能满足业务及系统要求。
现有技术方案:
方案1、使用100M以上的NLP传统bert模型进行类目预测:
1.1)其能够预测的数量为10个左右,业务需要预测100个左右,数量上不能满足要求;
1.2)该模型超过10个会导致预测准确率大幅下降,比如类目10个以内准确率会在80%左右,国家标准行业类别有97个准确率会下降到30%以内,业务要求准确率80%以上,不能满足业务需要。
1.3)该方案在线实时进行类目预测耗时在100ms左右,API响应时间勉强满足要求。
方案2、使用大模型进行类目预测:qwen1.5 72b
2.1)支持把企业分类到97个行业
2.2)准确率在40%左右,业务要求准确率80%以上,不能满足业务需要。
2.3)API响应时间在1000ms以上,不能满足要求。
问题:产品业务需要预测100个左右的类目,准确率在80%以上,API响应时间需要在100ms以内,现有开源的模型不能同时满足这些要求。
现有技术问题的推导:
1、使用大模型得到初步的结构化数据D,解决训练集获取难的问题
2、使用步骤1中的数据D,进一步清洗得到高准确度的训练数据S
3、使用步骤2中的数据S训练一个小模型,得到一个高准确率及性能满足要求的模型M,解决准确率低、预测数目少、API响应时间长的问题
新方案:
优化后的技术方案:
最终实现的方案:分5步实现
1、通过各种渠道获取企业介绍、当前售卖的产品、业务介绍等非结构化的文本数据
2、通过大模型使用步骤1的数据对企业进行分类,并提取主营产品词,提取的样例数据如下:
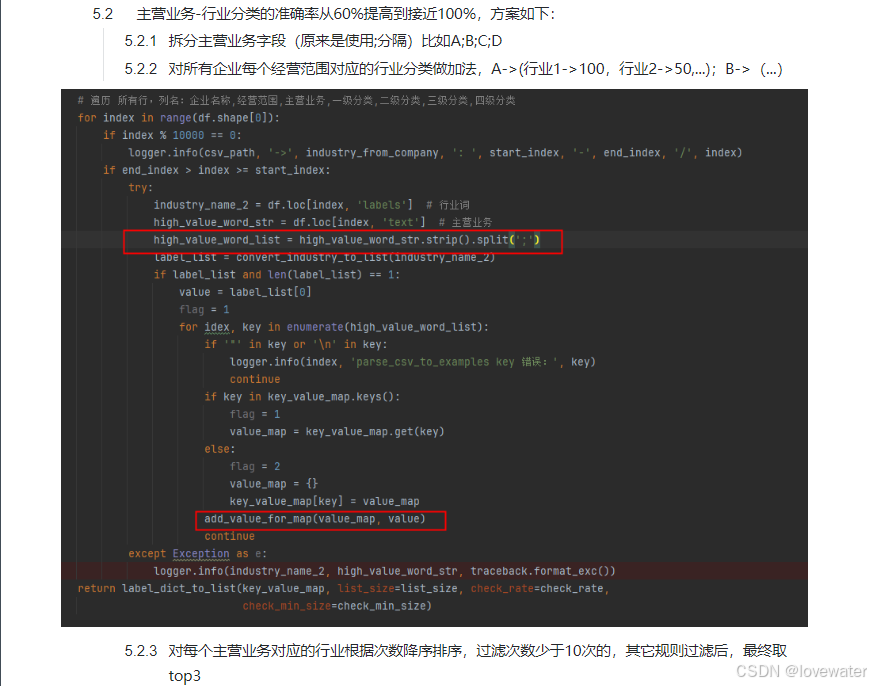
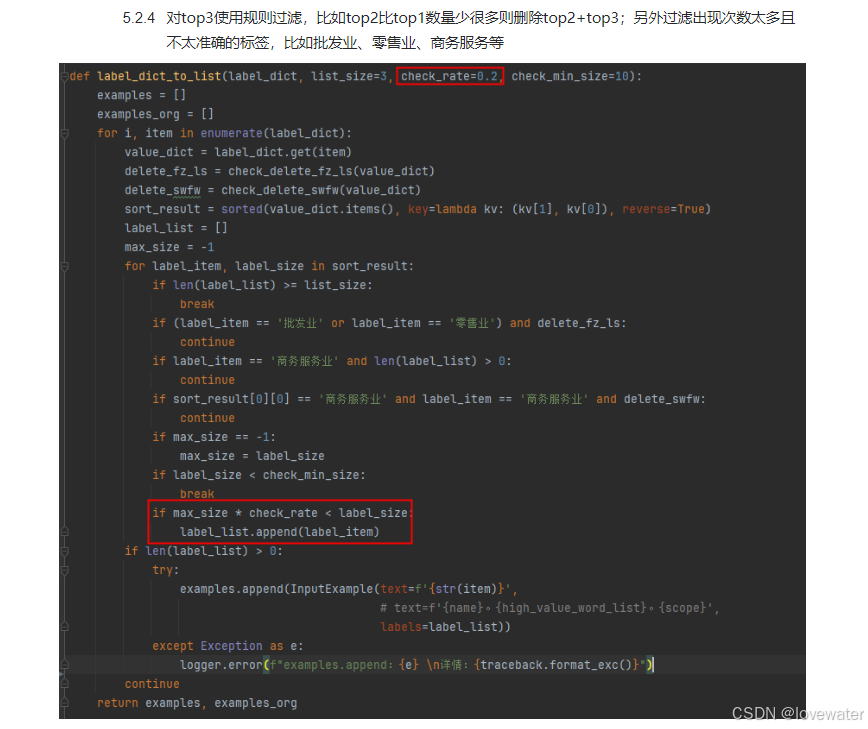
3、清洗加工步骤2生成的5000多万数据,得到高准确率的30万数据,作为下一步bert模型训练数据S,数据加工步骤如下:
首先:统计5000多万个企业:产品词与行业分类词的关系及出现的次数,同一个产品词需要合并所有结果并统计各个行业分类的数量,比如第2步中的数据统计结果并排序如下:
然后:针对每个产品词-行业分类词(出现次数),把出现次数小于10的去掉,得到可信度非常高的产品词与行业分类的映射数据,比如示例数据中把次数小于2的去掉后结果如下:
最终从5000万准确率为40%的数据中清洗得到准确率接近100%的数据,把这些数据作为下一步模型的训练集
4、使用步骤3的数据集S训练已预训练过的bert模型bert-base-chinese,生成训练后的类目预测模型M
5、使用步骤4生成的模型M部署到生产环境,准确率98%,api响应时间100ms以内,效果及性能均满足业务需要。
最张的技术效果:
1、能够预测的类目数量从原来的10个左右提升到100个左右
2、类型预测准确率:从原来的30%~40%提升到98%左右
3、API响应时间从原来的1000ms以上,降低到50ms左右
总结:


本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 企业行业分类【BERT bert-base-chinese】

发表评论 取消回复