目录
一、概述
该论文提出利用真实世界数据集,设计一个从文本生成真实世界3D场景和自适应相机轨迹的强大的开放世界文本到3D生成框架Director3D。
(1)引入Trajectory Diffusion Transformer(Traj-DiT)模型,用于根据文本描述建模相机轨迹分布。
(2)提出GS-driven Multi-view Latent Diffusion Model(GM-LDM,高斯驱动的多视角潜在扩散模型),用于生成像素对齐的3D高斯分布作为中间3D场景表示,在扩散过程中直接加强3D一致性产生3D表示。
(3)设计了一种用于细化生成的3D高斯分布的SDS++损失函数。
二、相关工作
1、文本到3D生成
结合了NeRF和视觉语言模型CLIP的DreamField诞生之后,文本到3D生成领域逐渐发展。
DreamFusion和SJC结合2D扩散模型 ,通过SDS分数蒸馏采样来作3D表示。
大多数的方法都仅仅关注对象级3D生成,近期考虑场景级3D生成问题,但由于多视图的不一致性和单目深度估计会导致不好的几何和纹理伪影。另外也考虑使用全景图像扩散模型来生成3D场景,但这仅限于特定场景。所以开放世界泛化能力的文本到三维场景生成方法仍然是一个挑战。
2、3DGS
3DGS,提出基于稠密视图的快速光栅化来用于新视图合成,大大减少渲染时间。当前方法集中于重建几何形状,适应动态场景建模。另外也有一些考虑将图像特征转换为像素对齐的3DGS,并通过反向传播渲染图像的损失来优化,训练可泛化的稀疏视图重建模型。
DreamGaussian、GaussianDreamer,GSGen等考虑用3DGS来作文本到3D生成,通过点云扩散模型初始化3DGS提高生成质量和3D一致性。
GRM、LGM、GS-LRM等基于3DGS的可泛化稀疏视图重建模型,也可以作上游任务参与文本到3D生成。
GM-LDM直接在扩散过程中采用像素对齐的3DGS作为中间3D表示,来强化3D一致性。
三、Director3D
Director3D框架分为三个部分:Cinematographer(生成密集视角相机轨迹的Traj-DiT,模拟密集视图摄影机的轨迹分布),Decorator(通过密集视图的稀疏子集来建模图像分布,生成像素对齐的3DGS基元),Detailer(通过密集相机插值渲染精炼3DGS基元)。
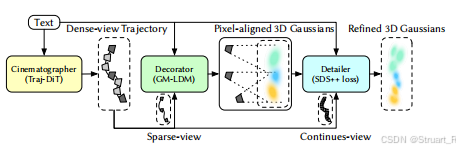
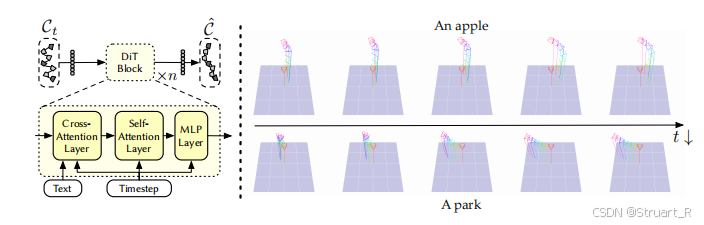
1、Cinematographer
首先相机轨迹





之后采用DiT结构(交叉注意力-自注意力-MLP)来生成摄像机的运动轨迹
相比于以往的DiT结构(Diffusion Transformer)来说,将以往预测图像中的噪声,改为预测摄像机轨迹中的噪声。
右图是不同去噪步骤下预测的摄像机轨迹(右图)。
2、Decorator
GM-LDM的流程:
(1)基于2D的去噪
首先输入潜在的多视图噪声表示




(2)基于渲染的去噪
将多视图的潜在表示









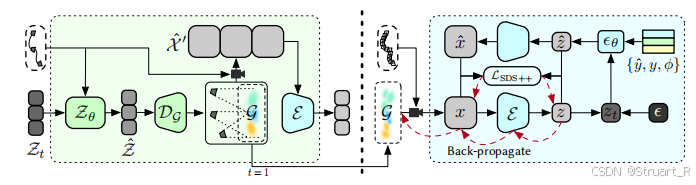
3、Detailer
Detailer负责提高生成3D场景的视觉质量模块,采用了一种SDS++的损失函数,利用2D扩散模型先验来优化3D高斯分布。
首先利用3DGS参数来渲染2D图像



4、Loss
因为该模型不是端到端的,所以在三个步骤分别计算损失进行监督,之后进行冻结网络。
第一部分:
第二部分(监督
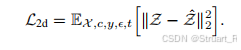
第三部分:
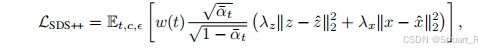
参考论文:Director3D: Real-world Camera Trajectory and 3D Scene Generation from Text
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Director3D: Real-world Camera Trajectory and 3DScene Generation from Text 论文解读

发表评论 取消回复