SQL 命令的解析过程主要包括四个步骤:词法分析(Lexical Analysis)、语法分析(Syntax Analysis)、语义分析(Semantic Analysis)以及执行计划生成。这些步骤从接收到 SQL 查询开始,最终转换成数据库能够理解和执行的操作。
为了模拟这个过程,使用 Java 可以设计一个简化版的 SQL 解析器。以下是对每个步骤的解释,以及如何在 Java 中进行相应的实现。
SQL 解析过程分解:
-
词法分析(Lexical Analysis):
词法分析负责将 SQL 命令的字符串拆分为有意义的符号(Tokens),这些符号包括关键字、表名、列名、操作符等。可以理解为将整个 SQL 语句分割成最小的语言单元。 -
语法分析(Syntax Analysis):
语法分析则会对这些符号按照 SQL 语法规则进行解析,构建出一个抽象语法树(AST, Abstract Syntax Tree),并检查 SQL 是否符合语法规则。 -
语义分析(Semantic Analysis):
语义分析检查 SQL 语句的逻辑正确性,例如表、列是否存在,类型是否匹配等。 -
生成执行计划(Query Plan Generation):
最后生成执行计划,决定如何读取数据、如何使用索引、如何排序等。
Java 代码模拟 SQL 解析器
下面的代码展示了一个简化的 SQL 查询解析器,包含了词法分析、语法分析和简单的执行计划生成部分。
import java.util.ArrayList;
import java.util.List;
import java.util.StringTokenizer;
// SQL Token
class Token {
enum TokenType {
SELECT, FROM, WHERE, IDENTIFIER, OPERATOR, VALUE, COMMA, END
}
private String value;
private TokenType type;
public Token(String value, TokenType type) {
this.value = value;
this.type = type;
}
public String getValue() {
return value;
}
public TokenType getType() {
return type;
}
@Override
public String toString() {
return "Token{" + "value='" + value + '\'' + ", type=" + type + '}';
}
}
// 词法分析器
class Lexer {
private String sql;
private List<Token> tokens;
public Lexer(String sql) {
this.sql = sql;
this.tokens = new ArrayList<>();
tokenize();
}
private void tokenize() {
StringTokenizer tokenizer = new StringTokenizer(sql, " ,()", true);
while (tokenizer.hasMoreTokens()) {
String token = tokenizer.nextToken().trim();
if (token.isEmpty()) continue;
switch (token.toUpperCase()) {
case "SELECT":
tokens.add(new Token(token, Token.TokenType.SELECT));
break;
case "FROM":
tokens.add(new Token(token, Token.TokenType.FROM));
break;
case "WHERE":
tokens.add(new Token(token, Token.TokenType.WHERE));
break;
case ",":
tokens.add(new Token(token, Token.TokenType.COMMA));
break;
case "=":
tokens.add(new Token(token, Token.TokenType.OPERATOR));
break;
default:
if (token.matches("[a-zA-Z_]+")) {
tokens.add(new Token(token, Token.TokenType.IDENTIFIER));
} else if (token.matches("[0-9]+")) {
tokens.add(new Token(token, Token.TokenType.VALUE));
}
break;
}
}
tokens.add(new Token("", Token.TokenType.END));
}
public List<Token> getTokens() {
return tokens;
}
}
// 简单的抽象语法树节点
class ASTNode {
private Token token;
private ASTNode left;
private ASTNode right;
public ASTNode(Token token) {
this.token = token;
}
public void setLeft(ASTNode left) {
this.left = left;
}
public void setRight(ASTNode right) {
this.right = right;
}
public Token getToken() {
return token;
}
public ASTNode getLeft() {
return left;
}
public ASTNode getRight() {
return right;
}
@Override
public String toString() {
return "ASTNode{" + "token=" + token + ", left=" + left + ", right=" + right + '}';
}
}
// 语法解析器
class Parser {
private List<Token> tokens;
private int position;
public Parser(List<Token> tokens) {
this.tokens = tokens;
this.position = 0;
}
public ASTNode parse() {
if (tokens.get(position).getType() == Token.TokenType.SELECT) {
return parseSelect();
} else {
throw new IllegalArgumentException("Unknown SQL command");
}
}
private ASTNode parseSelect() {
ASTNode selectNode = new ASTNode(tokens.get(position++)); // SELECT
ASTNode columnsNode = parseColumns();
ASTNode fromNode = parseFrom();
ASTNode whereNode = null;
if (tokens.get(position).getType() == Token.TokenType.WHERE) {
whereNode = parseWhere();
}
ASTNode root = new ASTNode(new Token("Query", Token.TokenType.IDENTIFIER));
root.setLeft(selectNode);
selectNode.setLeft(columnsNode);
selectNode.setRight(fromNode);
if (whereNode != null) {
fromNode.setRight(whereNode);
}
return root;
}
private ASTNode parseColumns() {
ASTNode columnsNode = new ASTNode(new Token("Columns", Token.TokenType.IDENTIFIER));
while (tokens.get(position).getType() == Token.TokenType.IDENTIFIER) {
ASTNode column = new ASTNode(tokens.get(position++));
if (columnsNode.getLeft() == null) {
columnsNode.setLeft(column);
} else {
ASTNode comma = new ASTNode(new Token(",", Token.TokenType.COMMA));
comma.setLeft(columnsNode.getLeft());
comma.setRight(column);
columnsNode.setLeft(comma);
}
if (tokens.get(position).getType() == Token.TokenType.COMMA) {
position++;
}
}
return columnsNode;
}
private ASTNode parseFrom() {
position++; // Skip FROM
return new ASTNode(tokens.get(position++));
}
private ASTNode parseWhere() {
position++; // Skip WHERE
ASTNode conditionNode = new ASTNode(new Token("Condition", Token.TokenType.IDENTIFIER));
ASTNode left = new ASTNode(tokens.get(position++)); // Column
ASTNode operator = new ASTNode(tokens.get(position++)); // Operator (=)
ASTNode right = new ASTNode(tokens.get(position++)); // Value
operator.setLeft(left);
operator.setRight(right);
conditionNode.setLeft(operator);
return conditionNode;
}
}
// SQL 执行器,模拟执行计划
class SQLExecutor {
private ASTNode ast;
public SQLExecutor(ASTNode ast) {
this.ast = ast;
}
public void execute() {
System.out.println("Executing SQL query: ");
traverse(ast);
}
private void traverse(ASTNode node) {
if (node == null) return;
System.out.println(node.getToken().toString());
traverse(node.getLeft());
traverse(node.getRight());
}
}
// 主程序
public class SQLParserDemo {
public static void main(String[] args) {
String sql = "SELECT name, age FROM users WHERE id = 123";
Lexer lexer = new Lexer(sql);
List<Token> tokens = lexer.getTokens();
System.out.println("Tokens:");
for (Token token : tokens) {
System.out.println(token);
}
Parser parser = new Parser(tokens);
ASTNode ast = parser.parse();
System.out.println("Abstract Syntax Tree:");
System.out.println(ast);
SQLExecutor executor = new SQLExecutor(ast);
executor.execute();
}
}
解析过程解释
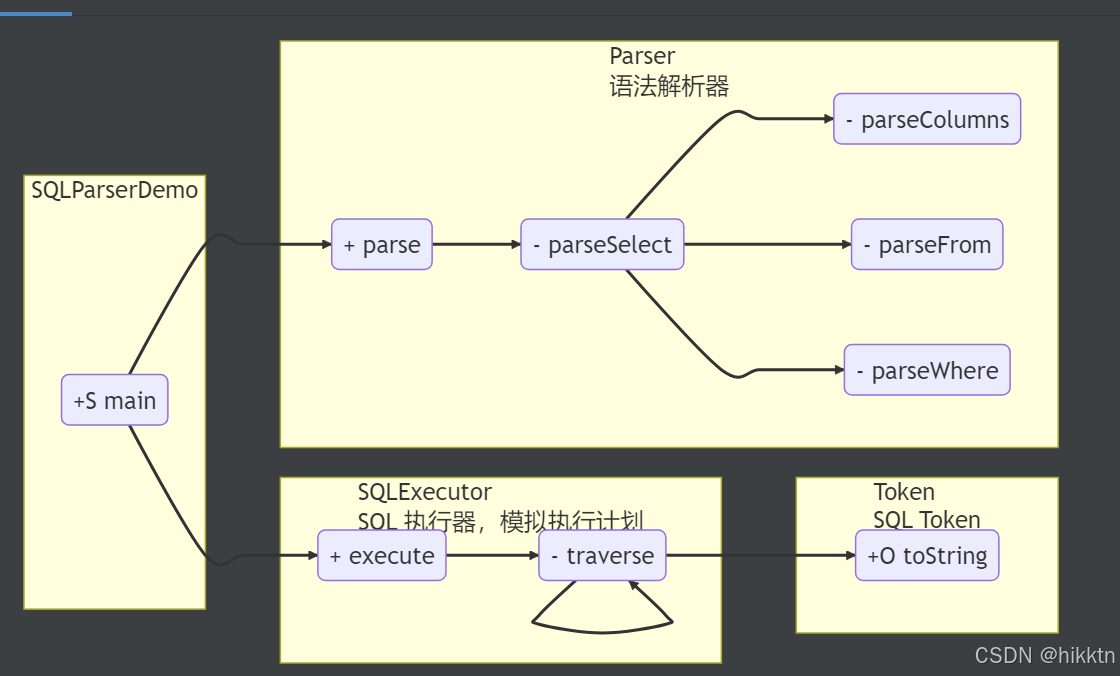
-
词法分析(Lexer):
- 词法分析器将输入的 SQL 查询字符串分解成一系列的
Token(标记)。例如:SELECT->Token(SELECT)name->Token(IDENTIFIER)FROM->Token(FROM)users->Token(IDENTIFIER)WHERE->Token(WHERE)id->Token(IDENTIFIER)=->Token(OPERATOR)123->Token(VALUE)
- 词法分析器将输入的 SQL 查询字符串分解成一系列的
-
语法分析(Parser):
- 语法解析器会根据 SQL 的语法规则解析生成抽象语法树(AST)。这棵树表示 SQL 查询的逻辑结构:
SELECT是根节点,它连接着列、表名、条件等信息。
- 语法解析器会根据 SQL 的语法规则解析生成抽象语法树(AST)。这棵树表示 SQL 查询的逻辑结构:
-
执行计划生成(SQLExecutor):
- 在执行器中,对解析好的 AST 进行遍历,模拟执行 SQL 查询操作。在实际的数据库中,这一步会生成 SQL 的执行计划,并决定具体的索引和操作顺序。
优缺点和局限性
这个示例代码模拟了 SQL 查询解析的基本流程,但相比于实际的 SQL 解析器,还存在较多简化。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 如何使用Java模拟SQL解析器

发表评论 取消回复