Large Language Models Are Reasoning Teachers
http://arxiv.org/abs/2212.10071
摘要
最近的研究表明,思维链(CoT)提示可以诱导语言模型逐步解决复杂的推理任务。然而,基于提示的 CoT 方法依赖于非常大的模型,如 GPT-3 175B,这对于大规模部署来说是难以承受的。在本文中,我们利用这些大型模型作为推理教师,在较小的模型中实现复杂推理,并将对模型大小的要求降低几个数量级。我们提出了 Fine-tune-CoT,这是一种从超大型教师模型中生成推理样本来微调较小模型的方法。我们在广泛的公共模型和复杂任务中对我们的方法进行了评估。我们发现,Fine-tuneCoT 能够在小型模型中实现强大的推理能力,在许多任务中远远优于基于提示的基线,甚至优于教师模型。此外,我们还利用教师模型为每个原始样本生成多个不同推理的能力,扩展了我们的方法。利用这种多样化的推理来丰富微调数据,即使对于非常小的模型,也能在不同数据集上大幅提升性能。我们进行了消融和样本研究,以了解学生模型推理能力的出现。
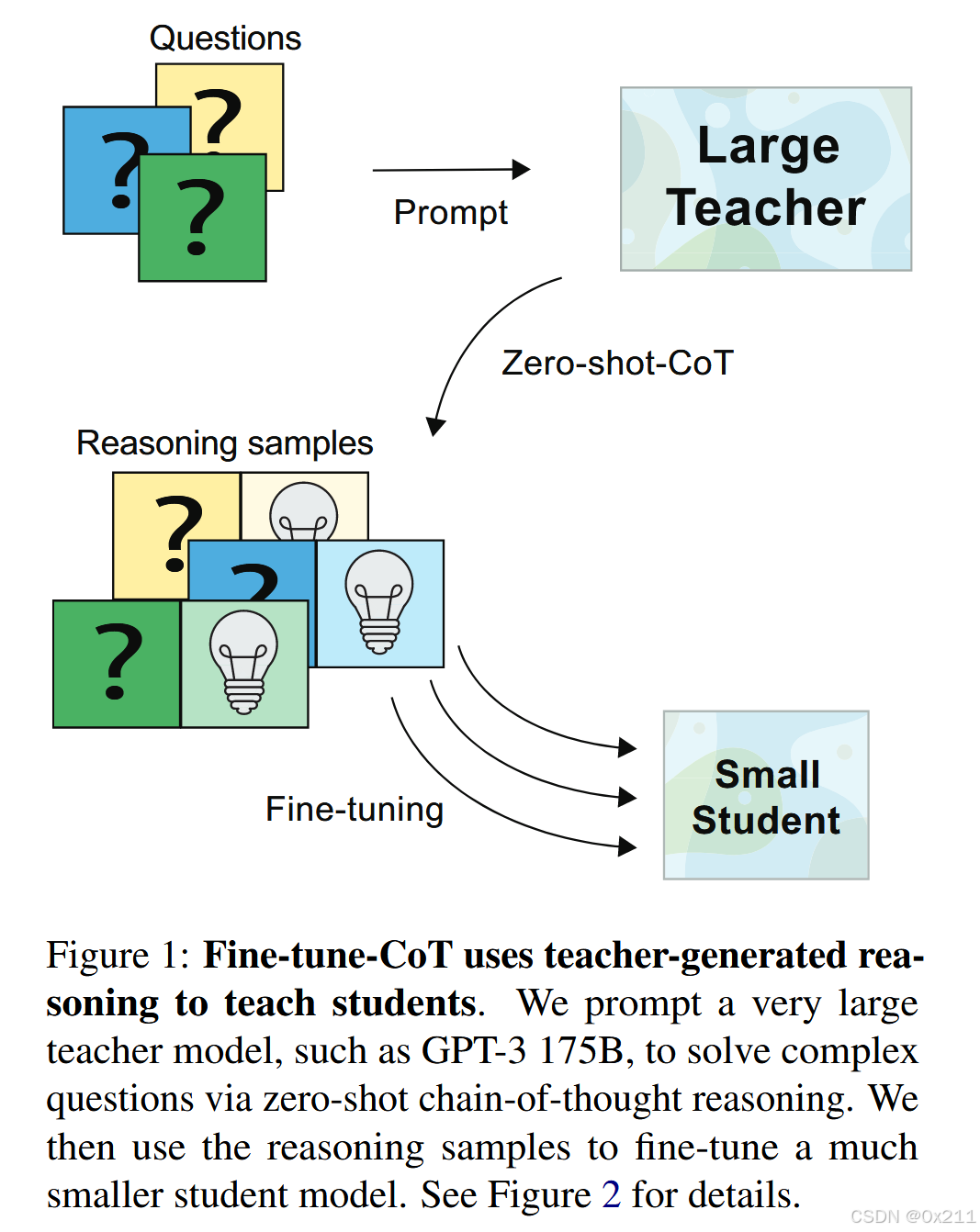
文章的核心:
提出了一种名为Fine-tune-CoT微调思维链的方式,该方式利用了LLM的推理能力来指导小模型如何解决复杂的任务。
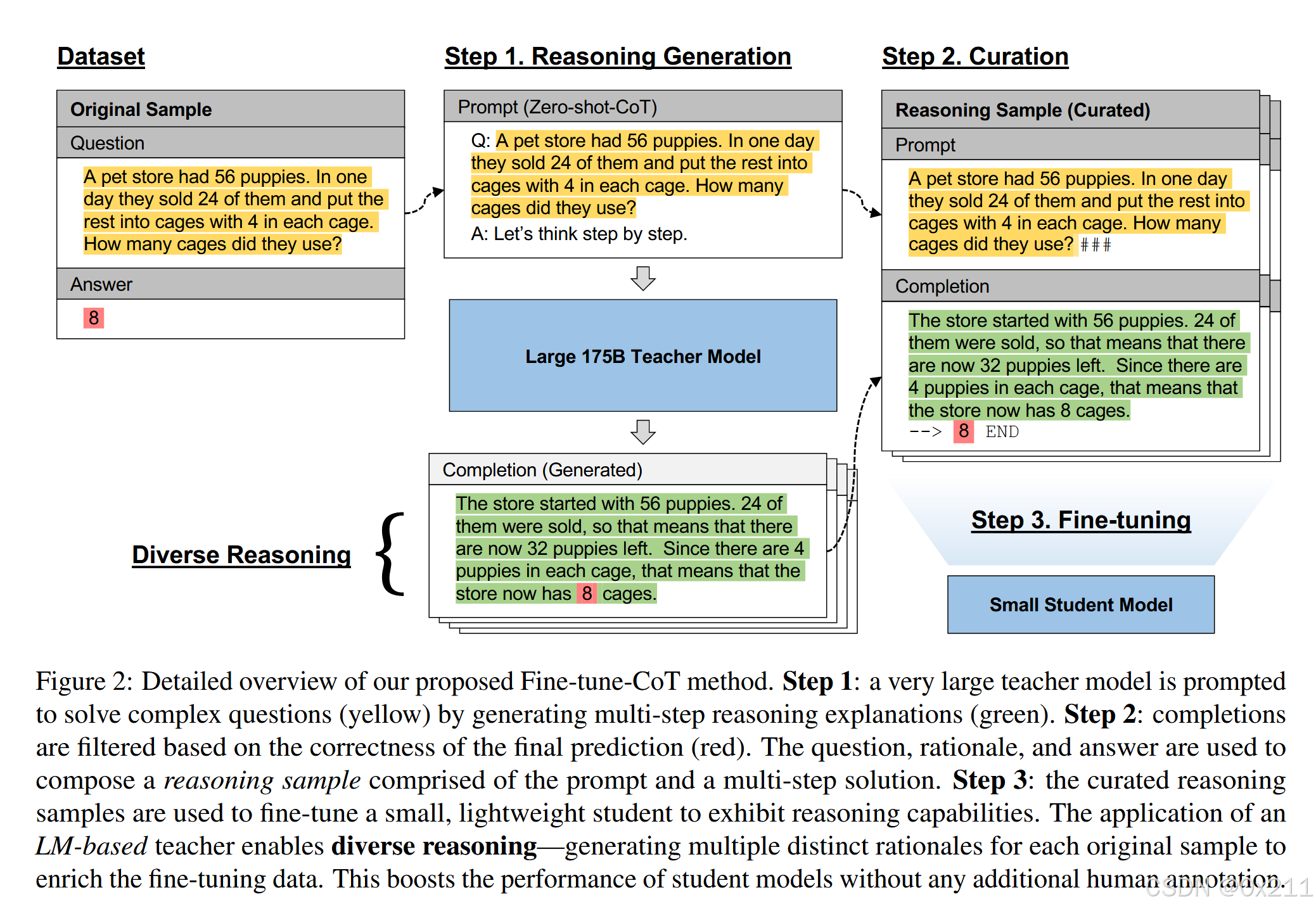
在我们的方法中,教师模型的作用是教授中间推理的概念。推理的主要监督信号不是具体的输出,而是生成的结构。因此,我们并没有使用标准的 KD 损失函数来试图匹配教师的输出结果。此外,我们还注意到,在 KD 的背景下,我们的多样化推理也是不同寻常的,例如,在实践中,只生成一个教师序列就足以进行序列级提炼。
方法
其核心理念是利用 CoT 提示从大型教师模型中生成推理样本,然后利用生成的样本对小型学生模型进行微调。这种方法既保留了基于提示的 CoT 方法的通用性,又克服了它们对过大模型的依赖。为了最大限度地提高通用性并降低教师推理成本,我们在教师模型上使用了与任务无关的 Zero-shot-CoT 提示方法(Kojima 等人,2022 年),因为它不需要任何推理示例或较长的推理上下文。
步骤1:推理生成
设计了一个提示词,让LLM按照同种方法输出推理过程
步骤2:综合处理
把上一步生成的推理和答案对进行一个过滤,过滤的依据是最终生成的答案和真实答案是否一致。作者自己也在文中说了这种基于答案的过滤器会导致一些训练样本的损失,并且该方法并不能保证推理的正确性。这个问题作者说目前还未被解决。

这里倒是让我想起来之前读的一篇使用对抗样本、反事实推理来进行蒸馏的文章:[论文阅读]SCOTT: Self-Consistent Chain-of-Thought Distillation-CSDN博客这样的方式可以使得学生模型不直接依赖答案和问题之间的关系,而是真正依赖于推理过程得出最终的答案,使得学生模型更加的忠实。也不知道这个方法算不算解决了本文在step2上的局限性。
步骤3:微调
把上一步得到的合并结果给学生模型进行微调训练。
多推理
为了最大限度地提高微调-CoT 的教学效果,我们可以为每个训练样本生成多个推理解释。这种方法的灵感来源于一种直觉,即多重推理路径可用于解决复杂任务,即第二类任务(Evans,2010 年)。我们认为,复杂任务的这一独特特征与教师模型的随机生成能力相结合,可以使多样化推理仅仅通过额外的教师推理就能显著提高推理监督。具体来说,对于给定的样本 Si,我们不是采用贪婪解码的 Zero-shot-CoT 来获得单一的解释-答案对(eˆi, ˆai),而是使用随机抽样策略,即大 T 的温度抽样,来获得 D 个不同的生成 {(rˆij, ˆaij)}D j。随后的推理样本整理和微调工作照常进行。我们将 D 称为推理多样性程度。Wang 等人(2022 年)和 Huang 等人(2022 年)也采用了类似的方法,即生成多个 CoT 输出并进行边际化,以找到最优答案。然而,这种多样化推理对学生模型教学的影响尚未得到认可,也未在同时进行的工作中得到深入研究(Huang 等人,2022;Li 等人,2022a;Magister 等人,2022;Fu 等人,2023)。我们注意到,多样化推理需要在学生模型的开发成本和推理成本/质量之间做出重要权衡,我们将在第 5.3 节讨论这一点。
实验
任务和数据集:4种类型的12个数据集
模型选择:在教师模型方面,我们使用了 OpenAI API 提供的 GPT-3 175B(Brown 等人,2020 年)的四个变体。除非另有说明,我们使用基于 InstructGPT 175B (欧阳等人,2022 年)的 text-davinci-002 作为 Finetune-CoT 的教师。对于学生模型,我们考虑了四种流行的模型系列。在主要实验中,我们使用 GPT-3 {ada, babbage, curie},因为它们可以通过 OpenAI API 进行微调。由于 API 的黑箱性质,我们还考虑了受控设置下的各种开源模型。我们使用 GPT-2{Small, Medium, Large}(Radford 等人,2019 年)和 T5{Small, Base, Large}(Raffel 等人,2020 年)分别作为纯解码器架构和编码器-解码器架构的代表性模型族。我们还使用 T5 的指令调整版本 FlanT5-{Small, Base, Large}(Chung 等人,2022 年),在应用 Fine-tune-CoT 之前研究指令调整对学生模型的影响。这些学生模型比教师模型小 25-2500 倍,因此在现实世界中部署更为可行。我们在附录 C 中提供了有关模型和应用程序接口使用的详细信息。
baseline: 我们将微调-CoT(我们的方法)与四种基线方法进行了比较:标准零样本提示、虚无微调、零样本-CoT(Kojima 等人,2022 年)和少样本-CoT(Wei 等人,2022 年b)。在给定训练样本 {(qi, ai)}i 的情况下,我们使用简单的格式 "Q: <qi>"进行零点提示。对于零样本微调,我们将提示和完成分别格式化为"<qi> ###" 和"<ai> END"。我们在表 2 中阐明了各种方法的分类。在文本生成方面,除多样化推理外,我们在整个实验中都采用了 Wei 等人(2022b)和 Kojima 等人(2022)的贪婪解码法。对于教师的多样化推理,我们沿用了 Wang 等人(2022)的方法,使用温度采样,T = 0.7。我们在附录 A 中提供了实验细节。

结果
文中的方法可以使得小模型在推理方面的性能得到挺大程度的提升。
文中的方法可以比教师模型在推理上的表现更突出。
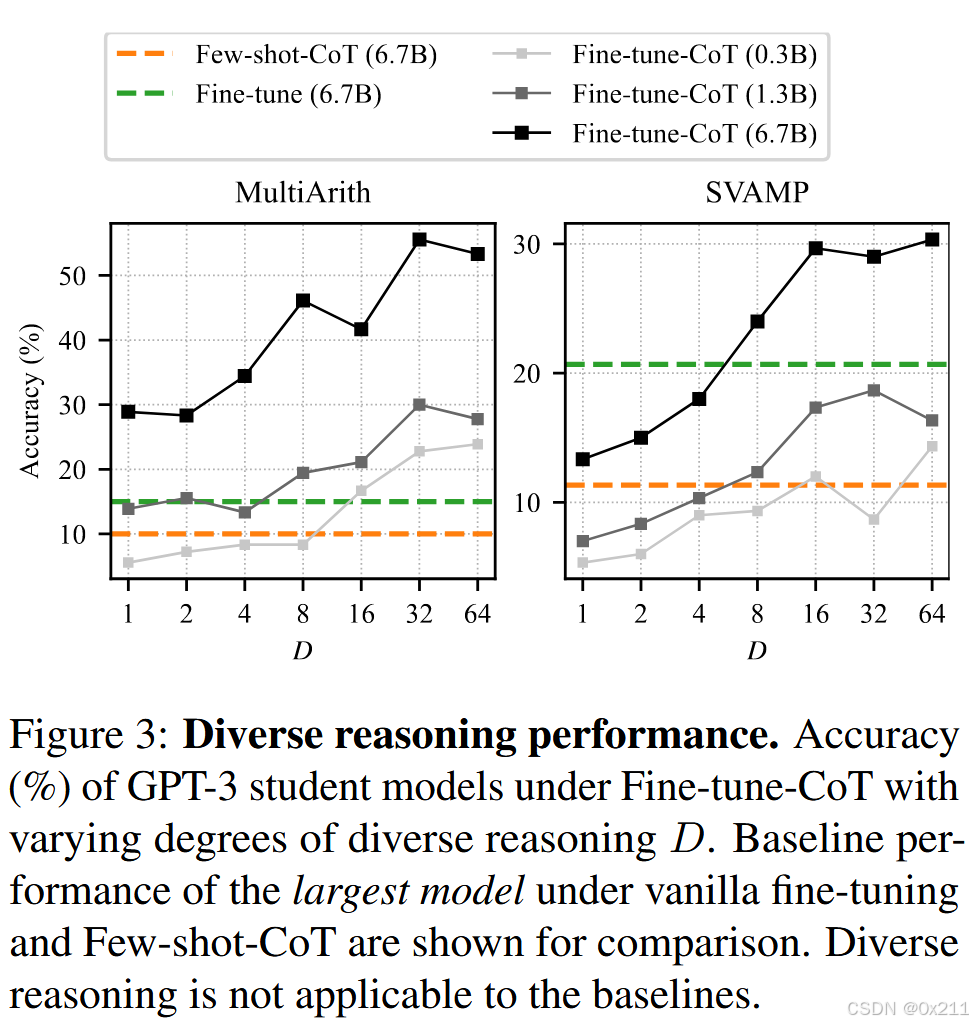
多推理方案本质上提高了微调COT的表现。
如果数据更多,则文中的方法会更好
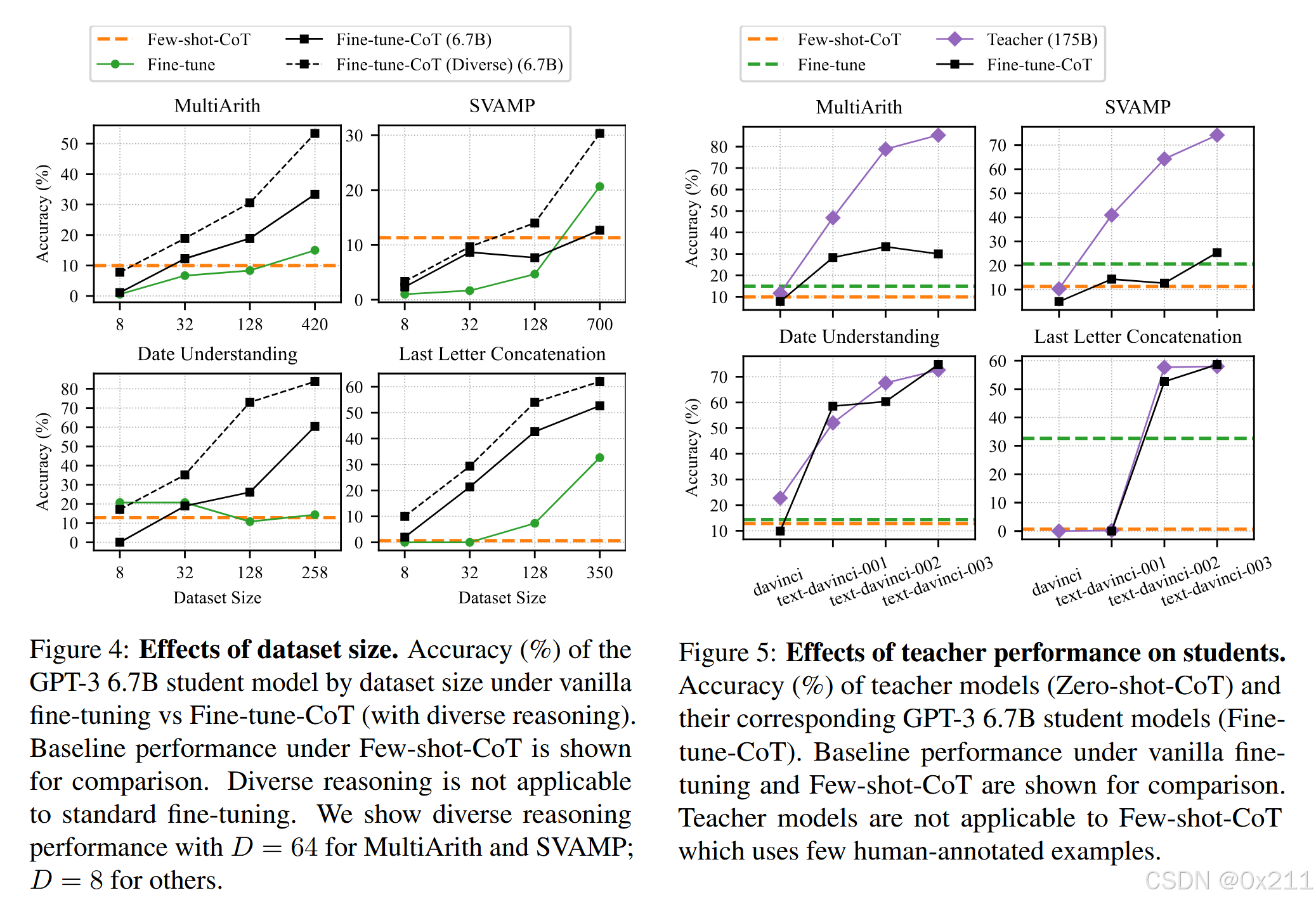
教师模型的推理过程会影响效果
总结
提出了Fine-tune-CoT方法,核心内容是让教师模型针对一个问题生成多个推理过程(调整超参数T),使用这些问题-推理-答案多对组合来对学生模型进行为微调训练(训练方法和pre-train方法一致)。文章结果表明,这种多推理训练方法可以使得学生模型的表现更为出众。但是在简短的答案回答上,学生模型的输出就很很多重复性内容;结果达不到SOTA。文章并不认为自己的做法是知识蒸馏KD方法,因为对学生模型的训练是用的学生模型预训练的方式,并没有拿教师模型的输出来使得学生模型的输出向其对齐(实际上也不好对齐,因为教师模型需要输出的是多种不同的推理内容)。 对我有用的就是本文是拿模型预训练方式一致的方式来对模型进行微调,而不是拿教师模型的显性输出来让学生模型的输出对齐。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » [论文阅读]Large Language Models Are Reasoning Teachers

发表评论 取消回复