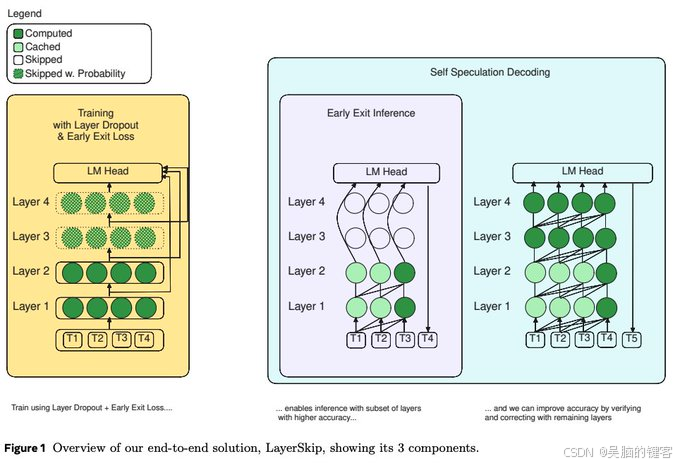
我们提出的 LayerSkip 是一种端到端的解决方案,可加快大型语言模型(LLM)的推理速度。 首先,在训练过程中,我们采用了层间丢弃技术(layer dropout),早期层间丢弃率较低,后期层间丢弃率较高。 其次,在推理过程中,我们证明这种训练方法提高了早期退出的准确性,而无需在模型中添加任何辅助层或模块。 第三,我们提出了一种新颖的自推测解码方案,即在早期层退出,并通过模型的其余层进行验证和校正。 与其他推测式解码方法相比,我们提出的自推测式解码方法占用的内存更少,并能从草稿和验证阶段的共享计算和激活中获益。 我们在不同大小的 Llama 模型上进行了不同类型的训练实验:从头开始预训练、持续预训练、在特定数据域上进行微调,以及在特定任务上进行微调。 我们实施了推理解决方案,结果表明,CNN/DM 文档的摘要速度提高了 2.16 倍,编码速度提高了 1.82 倍,TOPv2 语义解析任务的速度提高了 2.0 倍。 我们在 https://github.com/facebookresearch/LayerSkip 开源了我们的代码。
快速上手
$ git clone git@github.com:facebookresearch/LayerSkip.git
$ cd LayerSkip
创建环境
$ conda create --name layer_skip python=3.10
$ conda activate layer_skip
$ pip install -r requirements.txt
访问模型: 为了观察加速情况,您需要访问使用 LayerSkip 配方训练过的 LLM。 我们在 HuggingFace 上提供了 6 个检查点,它们是使用 LayerSkip 配方持续预训练的不同 Llama 模型:
facebook/layerskip-llama2-7Bfacebook/layerskip-llama2-13Bfacebook/layerskip-codellama-7Bfacebook/layerskip-codellama-34Bfacebook/layerskip-llama3-8Bfacebook/layerskip-llama3.2-1B
代码
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from copy import deepcopy
checkpoint = "facebook/layerskip-llama3.2-1B"
early_exit = 4
device = "cuda" if torch.cuda.is_available() else "cpu"
prompt = "typing import List\ndef bucket_sort(A: List):"
model = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto", use_safetensors=True, torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
generation_config = model.generation_config
weights_memo = {id(w): w for w in model.parameters()}
assistant_model = deepcopy(model, memo=weights_memo) # Clone main model with shared weights
assistant_model.model.layers = assistant_model.model.layers[:early_exit] # Apply early exit
del assistant_model.model.layers[early_exit:]
inputs = tokenizer(prompt, return_tensors="pt").to(device)
outputs = model.generate(**inputs, generation_config=generation_config, assistant_model=assistant_model, max_new_tokens=512)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True)[0])
或者Torchrun
$ torchrun generate.py --model facebook/layerskip-llama2-7B \
--sample True \
--max_steps 512
LayerSkip的项目地址
- GitHub仓库:https://github.com/facebookresearch/LayerSkip
- HuggingFace模型库:https://huggingface.co/collections/facebook/layerskip-666b25c50c8ae90e1965727a
- arXiv技术论文:https://arxiv.org/pdf/2404.16710
感谢大家花时间阅读我的文章,你们的支持是我不断前进的动力。期望未来能为大家带来更多有价值的内容,请多多关注我的动态!
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » LayerSkip – Meta推出加速大型语言模型推理过程的技术

发表评论 取消回复