基础
概念
1.NumPy 的全称是“ Numeric Python”,它是 Python 的第三方扩展包,主要用来计算、处理一维或多维数组
2.在数组算术计算方面, NumPy 提供了大量的数学函数
3.NumPy 的底层主要用 C语言编写,因此它能够高速地执行数值计算
4.NumPy 还提供了多种数据结构,这些数据结构能够非常契合的应用在数组和矩阵的运算上
优点
NumPy 可以很便捷高效地处理大量数据,使用 NumPy 做数据处理的优点如下:
- NumPy 是 Python 科学计算基础库
- NumPy 可以对数组进行高效的数学运算
- NumPy 的 ndarray 对象可以用来构建多维数组
- NumPy 能够执行傅立叶变换与重塑多维数组形状
- NumPy 提供了线性代数,以及随机数生成的内置函数
与python列表区别
1.NumPy 数组是同质数据类型(homogeneous),即数组中的所有元素必须是相同的数据类型。数据类型在创建数组时指定,并且数组中的所有元素都必须是该类型。
2.Python 列表是异质数据类型(heterogeneous),即列表中的元素可以是不同的数据类型。列表可以包含整数、浮点数、字符串、对象等各种类型的数据。
3.NumPy 数组提供了丰富的数学函数和操作,如矩阵运算、线性代数、傅里叶变换等。
4.Python 列表提供了基本的列表操作,如添加、删除、切片、排序等。
安装
pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple/
ndarray
1.NumPy 定义了一个 n 维数组对象,简称 ndarray 对象,它是一个一系列相同类型元素组成的数组集合。数组中的每个元素都占有大小相同的内存块,您可以使用索引或切片的方式获取数组中的每个元素。
2.ndarray 对象采用了数组的索引机制,将数组中的每个元素映射到内存块上,并且按照一定的布局对内存块进行排列,常用的布局方式有两种,即按行或者按列。
2.主要特点
- 多维数组:ndarray 可以表示任意维度的数组,包括一维、二维、三维等。
- 同质数据类型:ndarray 中的所有元素必须是相同的数据类型。
- 高效内存布局:ndarray 在内存中是连续存储的,这使得数组的访问和操作非常高效。
- 丰富的功能和方法:ndarray 提供了丰富的数学函数和操作,如矩阵运算、线性代数、傅里叶变换等。
3.使用方式
- ndarray 是通过 array 函数或其他 NumPy 函数(如 zeros、ones、arange 等)创建的。
- array 函数接受一个序列作为输入,并返回一个 ndarray 对象。
array创建对象
1.通过 NumPy 的内置函数 array() 可以创建 ndarray 对象,其语法格式如下:
numpy.array(object, dtype = None, copy = True, order = None,ndmin = 0)
2.参数说明
| 序号 | 参数 | 描述说明 |
|---|---|---|
| 1 | object | 表示一个数组序列 |
| 2 | dtype | 可选参数,通过它可以更改数组的数据类型 |
| 3 | copy | 可选参数,表示数组能否被复制,默认是 True |
| 4 | order | 以哪种内存布局创建数组,有 3 个可选值,分别是 C(行序列)/F(列序列)/A(默认) |
| 5 | ndmin | 用于指定数组的维度 |
3.例
#改变数组的形状,比如:将1维数组修改未2未数组,修改后数组元素的个数和原数组相同
def np_reshape():
arr = np.array([1,2,3,4,5,6])
#reshape修改数组的形状,例如:(2,3)表示两行三列,修改后会返回一个新数组,不会修改元素组的维度
#order:指定数据存储顺序,C:按行村,F:按列存
"""
[[1 3 5]
[2 4 6]]
"""
# shaped_arr = arr.reshape((2,3),order='F')
"""
[[1 2 3]
[4 5 6]]
"""
shaped_arr = arr.reshape((2,3),order='C')
# shaped_arr = arr.reshape((2,4),order='C') 报错数组的元素个数不相同
print(shaped_arr)
print(shaped_arr.shape)#(2, 3)
arr2 = arr.reshape((1,2,3))
"""
[[[1 2 3]
[4 5 6]]]
"""
print(arr2)
print(arr2.shape) #(1, 2, 3)
#直接在原数组上修改形状,不是返回一个新数组
"""
[[1 2 3]
[4 5 6]]
"""
arr.shape = (2,3)
print(arr)
#定义main方法,并运行np_array
if __name__ == '__main__':
np_array()reshape数组变维
1.reshape() 函数允许你在不改变数组数据的情况下,改变数组的维度。
2.reshape() 返回的是一个新的数组,原数组不会被修改。reshape() 可以用于多维数组,例如将一个一维数组重塑为二维数组。
3.元素总数必须匹配:新形状中的元素总数必须与原数组中的元素总数相同。
- 例如,一个长度为6的一维数组可以被重塑为 (2, 3) 或 (3, 2),但不能被重塑为 (2, 2)。
4.案例
#改变数组的形状,比如:将1维数组修改未2未数组,修改后数组元素的个数和原数组相同
def np_reshape():
arr = np.array([1,2,3,4,5,6])
#reshape修改数组的形状,例如:(2,3)表示两行三列,修改后会返回一个新数组,不会修改元素组的维度
#order:指定数据存储顺序,C:按行村,F:按列存
"""
[[1 3 5]
[2 4 6]]
"""
# shaped_arr = arr.reshape((2,3),order='F')
"""
[[1 2 3]
[4 5 6]]
"""
shaped_arr = arr.reshape((2,3),order='C')
print(shaped_arr)
print(shaped_arr.shape)#(2, 3)
arr2 = arr.reshape((1,2,3))
"""
[[[1 2 3]
[4 5 6]]]
"""
print(arr2)
print(arr2.shape) #(1, 2, 3)
#直接在原数组上修改形状,不是返回一个新数组
"""
[[1 2 3]
[4 5 6]]
"""
arr.shape = (2,3)
print(arr)
#定义main方法,并运行np_array
if __name__ == '__main__':
np_reshape()5.-1 作为占位符:你可以使用 -1 作为占位符,让 numpy 自动计算某个维度的大小。
def np_reshape():
arr = np.array([1,2,3,4,5,6])
#-1占位符,自动计算列数
arr2 = arr.reshape(2,-1)
"""
[[1 2 3]
[4 5 6]]
"""
print(arr2)
#定义main方法,并运行np_array
if __name__ == '__main__':
np_reshape()数据类型
1.NumPy 提供了比 Python 更加丰富的数据类型,如下所示
| 序号 | 数据类型 | 语言描述 |
|---|---|---|
| 1 | bool_ | 布尔型数据类型(True 或者 False) |
| 2 | int_ | 默认整数类型,类似于 C 语言中的 long,取值为 int32 或 int64 |
| 3 | intc | 和 C 语言的 int 类型一样,一般是 int32 或 int 64 |
| 4 | intp | 用于索引的整数类型(类似于 C 的 ssize_t,通常为 int32 或 int64) |
| 5 | int8 | 代表与1字节相同的8位整数。值的范围是-128到127 |
| 6 | int16 | 代表 2 字节(16位)的整数。范围是-32768至32767 |
| 7 | int32 | 代表 4 字节(32位)整数。范围是-2147483648至2147483647 |
| 8 | int64 | 表示 8 字节(64位)整数。范围是-9223372036854775808至9223372036854775807 |
| 9 | uint8 | 1字节(8位)无符号整数 |
| 10 | uint16 | 2 字节(16位)无符号整数 |
| 11 | uint32 | 4 字节(32位)无符号整数 |
| 12 | uint64 | 8 字节(64位)无符号整数 |
| 13 | float_ | float64 类型的简写 |
| 14 | float16 | 半精度浮点数,包括:1 个符号位,5 个指数位,10个尾数位 |
| 15 | float32 | 单精度浮点数,包括:1 个符号位,8 个指数位,23个尾数位 |
| 16 | float64 | 双精度浮点数,包括:1 个符号位,11 个指数位,52个尾数位 |
| 17 | complex_ | 复数类型,与 complex128 类型相同 |
| 18 | complex64 | 表示实部和虚部共享 32 位的复数 |
| 19 | complex128 | 表示实部和虚部共享 64 位的复数 |
| 20 | str_ | 表示字符串类型 |
| 21 | string_ | 表示字节串类型 |
数据类型对象
1.数据类型对象(Data Type Object)又称 dtype 对象,是用来描述与数组对应的内存区域如何使用。
2.可以在创建数组时指定 dtype 参数来定义数组中元素的数据类型。
import numpy as np
# 创建一个 int32 类型的数组
arr_int = np.array([1, 2, 3], dtype=np.int32)
print(arr_int.dtype) # 输出: int32
# 创建一个 float64 类型的数组
arr_float = np.array([1.0, 2.0, 3.0], dtype=np.float64)
print(arr_float.dtype) # 输出: float642.可以使用数组的 dtype 属性来获取数组中元素的数据类型。
arr = np.array([1, 2, 3])
print(arr.dtype) # 输出: int323.可以使用 astype() 方法来转换数组中元素的数据类型。
arr = np.array([1, 2, 3])
arr_float = arr.astype(np.float64)
print(arr_float.dtype) # 输出: float64数据类型标识码
1.NumPy 中每种数据类型都有一个唯一标识的字符码,int8, int16, int32, int64 四种数据类型可以使用字符串 'i1', 'i2','i4','i8' 代替,如下所示:
| 字符 | 对应类型 |
|---|---|
| b | 代表布尔型 |
| i | 带符号整型 |
| u | 无符号整型 |
| f | 浮点型 |
| c | 复数浮点型 |
| m | 时间间隔(timedelta) |
| M | datatime(日期时间) |
| O | Python对象 |
| S,a | 字节串(S)与字符串(a) |
| U | Unicode |
| V | 原始数据(void) |
2.以下是 NumPy 中常见的数据类型标识码及其对应的详细列表
(1)整数类型
| 数据类型 | 标识码 | 描述 |
|---|---|---|
| int8 | i1 | 8 位有符号整数 |
| int16 | i2 | 16 位有符号整数 |
| int32 | i4 | 32 位有符号整数 |
| int64 | i8 | 64 位有符号整数 |
| uint8 | u1 | 8 位无符号整数 |
| uint16 | u2 | 16 位无符号整数 |
| uint32 | u4 | 32 位无符号整数 |
| uint64 | u8 | 64 位无符号整数 |
(2)浮点数类型
| 数据类型 | 标识码 | 描述 |
|---|---|---|
| float16 | f2 | 16 位浮点数(半精度) |
| float32 | f4 | 32 位浮点数(单精度) |
| float64 | f8 | 64 位浮点数(双精度) |
(3)复数类型
| 数据类型 | 标识码 | 描述 |
|---|---|---|
| complex64 | c8 | 64 位复数(单精度) |
| complex128 | c16 | 128 位复数(双精度) |
(4)布尔类型
| 数据类型 | 标识码 | 描述 |
|---|---|---|
| bool | b1 | 布尔类型 |
(5)字符串类型
| 数据类型 | 标识码 | 描述 |
|---|---|---|
| S | S10 | 长度为 10 的字节串 |
| U | U10 | 长度为 10 的 Unicode 字符串 |
(6)Python 对象类型
| 数据类型 | 标识码 | 描述 |
|---|---|---|
| O | O | Python 对象类型 |
3.自定义一个int32的数据类型
dt=np.dtype('i4')
data = np.array([1,2,3,4],dtype=dt)
print(data) #输出:[1 2 3 4]
print(data.dtype) #输出:int32
#改变数组的形状,比如:将1维数组修改未2未数组,修改后数组元素的个数和原数组相同
def data_type():
arr = np.array([1,2,3,4],dtype=np.int16)
print(arr) # [1 2 3 4]
print(arr.dtype) #int16
#数据类型识别码,和numpy中的数据类型一一对应,例如:i1对应np.int8,f2对于np.float16
arr1 = np.array([5,6,7,8],dtype='i2')
print(arr.dtype) #int164.可以自定义复杂的数据结构
dt=np.dtype([('name','S10'),('age','i4')])
data = np.array([('zhangsan',20),('lisi',21)],dtype=dt)
print(data) #输出:[(b'zhangsan', 20) (b'lisi', 21)]
print(data.dtype) #输出:[('name', 'S10'), ('age', '<i4')]5.说明
在编程中,字节序标记用于指定数据的字节顺序。常见的字节序标记包括:
<: 小端序,数据的最低有效字节存储在内存的最低地址,而最高有效字节存储在内存的最高地址。>: 大端序,数据的最高有效字节存储在内存的最低地址,而最低有效字节存储在内存的最高地址。
数组属性
shape
1.返回一个元组,元组中的每个元素表示数组在对应维度上的大小。元组的长度等于数组的维度数。
2.shape 属性功能
- 未传入参数,返回一个由数组维度构成的元组
- 传入参数,可以用来调整数组维度的大小
如果使用shape属性修改数组的形状,则修改的是原数组的形状,reshape修改数组的形状会返回一个新数组,不修改原数组的形状。
ndim
- ndim 属性功能:返回的是数组的维数
itemsize
1.itemsize 属性功能:返回数组中每个元素的大小(以字节为单位)
'''
itemsize 属性功能:
1、返回数组中每个元素的大小(以字节为单位)
'''
#itemsize():返回数组中每个元素的字节大小
def item_size():
arr = np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12]],dtype=np.int32)
print(arr.itemsize) #int64:8 int32:4
print(arr.dtype) #int64flags
1.flags 属性功能:返回 ndarray 数组的内存信息
'''
flags 属性功能:
1、返回 ndarray 数组的内存信息
'''
#flags:显示数据在内存中的存储信息
def arr_flags():
arr = np.array([1,2,3,4,5,6])
"""
C_CONTIGUOUS : True
F_CONTIGUOUS : True
OWNDATA : True
WRITEABLE : True
ALIGNED : True
WRITEBACKIFCOPY : False
"""
print(arr.flags)
arr1 = np.array([[1,2,3,4],[5,6,7,8]],order='F')
"""
C_CONTIGUOUS : False
F_CONTIGUOUS : True
OWNDATA : True
WRITEABLE : True
ALIGNED : True
WRITEBACKIFCOPY : False
"""
print(arr1.flags)2.说明
- C_CONTIGUOUS:表示数组在内存中是 C 风格连续的(行优先)。如果为 True,则数组是 C 风格连续的。
- F_CONTIGUOUS:表示数组在内存中是 Fortran 风格连续的(列优先)。如果为 True,则数组是 Fortran 风格连续的。
- OWNDATA:表示数组是否拥有自己的数据。如果为 True,则数组拥有自己的数据;如果为 False,则数组可能是从另一个数组或对象借用数据的。
- WRITEABLE:表示数组是否可写。如果为 True,则数组是可写的;如果为 False,则数组是只读的。
- ALIGNED:表示数组是否对齐。如果为 True,则数组的数据在内存中是对齐的。
- WRITEBACKIFCOPY:表示数组是否是通过 np.copy 创建的副本,并且需要将更改写回原始数组。如果为 True,则数组是通过 np.copy 创建的副本,并且需要将更改写回原始数组。
- UPDATEIFCOPY:表示数组是否是通过 np.copy 创建的副本,并且需要将更改写回原始数组。如果为 True,则数组是通过 np.copy 创建的副本,并且需要将更改写回原始数组。
创建数组的其他方法
empty()
1.empty() 方法用来创建一个指定形状(shape)、数据类型(dtype)且未初始化的数组(数组元素为随机值)
2.格式
numpy.empty(shape, dtype = float, order = 'C')
| 参数 | 描述 |
|---|---|
| shape | 数组的形状,可以是整数或整数元组 |
| dtype | 数组的数据类型,默认为 float |
| order | 数组的内存布局,有"C"和"F"两个选项,分别代表,行优先和列优先,在计算机内存中的存储元素的顺序 |
3.案例
import numpy as np
'''
empty 函数:
1、用来创建一个指定形状(shape)、数据类型(dtype)且未初始化的数组(数组元素为随机值)
'''
#empty:创建一个空数值,第一个参数是形状,ru:(2,3),创建的数组中的元素是随机的
def empty_test():
array_one = np.empty(shape=(2,3),dtype='i1',order='C')
"""
empty 函数创建数组: [[ 0 0 41]
[ 2 114 -108]]
"""
print("empty 函数创建数组:",array_one)
if __name__ == '__main__':
empty_test()zeros()
1.创建指定大小的数组,数组元素以 0 来填充
2.格式
numpy.zeros(shape, dtype = float, order = 'C')
| 参数 | 描述 |
|---|---|
| shape | 数组形状 |
| dtype | 数据类型,可选 |
| order | 'C' 用于 C 的行数组,或者 'F' 用于 FORTRAN 的列数组 |
ones()
1.创建指定形状的数组,数组元素以 1 来填充
2.格式
numpy.ones(shape, dtype = None, order = 'C')
| 参数 | 描述 |
|---|---|
| shape | 数组形状 |
| dtype | 数据类型,可选 |
| order | 'C' 用于 C 的行数组,或者 'F' 用于 FORTRAN 的列数组 |
2.案例
import numpy as np
'''
ones 函数:
1、创建指定形状的数组,数组元素以 1 来填充
'''
def ones_test():
array_one = np.ones(shape=(2,3),dtype='i1',order='C')
"""
zeros 函数创建数组: [[1 1 1]
[1 1 1]]
"""
print("zeros 函数创建数组:",array_one)
if __name__ == '__main__':
ones_test()arange()
1.arange() 函数用于创建一个等差数列的数组。它类似于 Python 内置的 range() 函数,但返回的是一个 NumPy 数组而不是一个列表。
1.格式
numpy.arange(start, stop, step, dtype)
2.根据 start 与 stop 指定的范围以及 step 设定的步长,生成一个 ndarray。
| 参数 | 描述 |
|---|---|
| start | 起始值,默认为 0 |
| stop | 终止值(不包含) |
| step | 步长,默认为 1 |
| dtype | 返回 ndarray 的数据类型,如果没有提供,则会使用输入数据的类型 |
3.案例
#linspace:将指定start和stop的数值范围平均分num份,然后生成一个一维的等差数列数组
#计算公式:如果endpoint为True:(stop-start)/(num-1),如果endpoint为False:(stop-start)/num
#start:起始值,默认为0
#stop:终止值
#num:平均分的份数,默认为50
#endpoint:如果为True表示包含终止值,否则不包含终止值,默认为True
def arr_linspace():
arr = np.linspace(1,9,5)
print(arr)# [1. 3. 5. 7. 9.]
arr1 = np.linspace(1,9,5,endpoint=False)
print(arr1) #1. 2.6 4.2 5.8 7.4]
#randn是生成指定数量的标准正态分布的数据,均值为0,方差为1
arr2 = np.random.randn(10)
"""
[ 1.10091769 -0.45285111 0.51299818 -1.71709497 1.11938142 0.81769967
-0.7379198 0.29435144 -0.92741176 -0.93446599]
"""
print(arr2)
#生成一个两行三列的二维标准正态分布的样本数据
arr3 = np.random.randn(2,3)
"""
[[-1.63587702 0.85352693 0.00905748]
[ 0.46826982 1.89012727 0.38757468]]
"""
print(arr3)import numpy as np
# 创建一个从 0 到 9 的数组
arr = np.arange(10)
print(arr)
# 输出:
# [0 1 2 3 4 5 6 7 8 9]
# 创建一个从 1 到 10 的数组
arr = np.arange(1, 11)
print(arr)
# 输出:
# [ 1 2 3 4 5 6 7 8 9 10]
# 创建一个从 0 到 10,步长为 2 的数组
arr = np.arange(0, 10, 2)
print(arr)
# 输出:
# [0 2 4 6 8]
# 创建一个从 10 到 0,步长为 -1 的数组
arr = np.arange(10, 0, -1)
print(arr)
# 输出:
# [10 9 8 7 6 5 4 3 2 1]
# 创建一个从 0 到 1,步长为 0.1 的浮点数数组
arr = np.arange(0, 1, 0.1)
print(arr)
# 输出:
# [0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9]4.注意
- arange() 函数生成的数组不包含 stop 值。
- 如果 step 为负数,则 start 必须大于 stop,否则生成的数组为空。
- arange() 函数在处理浮点数时可能会出现精度问题,因为浮点数的表示和计算存在精度误差。
linspace
1.在指定的数值区间内,返回均匀间隔的一维等差数组,默认均分 50 份
2.格式
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
| 参数 | 描述 |
|---|---|
| start | 起始值,默认为 0 |
| stop | 终止值 |
| num | 表示数值区间内要生成多少个均匀的样本,默认值为 50 |
| endpoint | 默认为 True,表示数列包含 stop 终止值,反之不包含 |
| retstep | 表示是否返回步长。如果为 True,则返回一个包含数组和步长的元组;如果为 False,则只返回数组。默认为 False。 |
| dtype | 返回 ndarray 的数据类型,默认为 None,表示根据输入参数自动推断数据类型。 |
3.案例
'''
linspace 函数:
1、在指定的数值区间内,返回均匀间隔的一维等差数组,默认均分 50 份
'''
# linspace:将指定start和stop的数值范围平均分为num分,然后生成一个一维的等差数列数组
# 计算公式:如果endpoint为True:(stop - start)/(num - 1),如果endpoint为False:(stop - start)/num
# start:起始值,默认为0
# stop:终止值
# num:平均分的份数,默认为50
# endpoint:如果为True表示包含终止值,否则不包含终止值,默认为True
def arr_linspace():
arr = np.linspace(1, 10, 5)
#[ 1. 3.25 5.5 7.75 10. ]
print(arr)
arr1 = np.linspace(1, 9, 5, endpoint=False)
#[1. 2.6 4.2 5.8 7.4]
print(arr1)
# randn生成指定数量的标准正态分布的数据:均值为0,方差为1
arr2 = np.random.randn(10)
"""
[ 1.14643383 1.51842025 -1.69942956 0.71048501 1.50162918 1.15224079
0.13879779 -1.89119695 0.25485893 -0.68173526]
"""
print(arr2)
# randn生成一个2行3列的二维标准正态分布的样本数据
arr3 = np.random.randn(2, 3)
"""
[[-0.15180904 0.62854141 -0.73839177]
[-1.42902692 0.20057867 1.48851128]]
"""
print(arr3)
def linspace_test():
array_one = np.linspace(0,9,3)
print(array_one)#[0. 4.5 9. ]
array_one = np.linspace(0,9,3,retstep=True,dtype='i1')
#(array([0, 4, 9], dtype=int8), np.float64(4.5))
print("linspace 函数创建数组:",array_one)说明:以上几个函数通常用于创建数字类型的数组,也可以用于创建布尔、字符串等类型的数组。但更适合用于创建数字数组。
切片
1、ndarray 对象的内容可以通过索引或切片来访问和修改,与 Python 中 list 的切片操作一样;
slice()(slice获取的是索引)
1.在 Python 中,slice 可以作为一个对象来使用。你可以创建一个 slice 对象,然后使用它来获取序列的片段。
2.参数
- start 是切片开始的位置(包含该位置)。
- stop 是切片结束的位置(不包含该位置)。
- step 是切片的步长,即选取元素的间隔。
3.案例
import numpy as np
'''
slice 函数:
1、从原数组的上切割出一个新数组
'''
def slice_test():
array_one = np.array([1,2,3,4])
#[1 2 3 4]
print("array_one 数组内容:",array_one)
result = slice(0,len(array_one),2)
#slice(0, 4, 2) slice获取的是索引
print(result)#[1 3]
print("slice 截取 array_one 数组内容:",array_one[result])
if __name__ == '__main__':
slice_test()3.slice 操作也可通过 [start:stop:step] 的形式来实现
#切片:slice
#冒泡:
#一维数组是通过[start,stop,step]切片
#二维数组按行或按列切片
#省略号:截取所有行或所有列数据
import numpy as np
def two():
array_one = np.array([[1, 2, 3], [4, 5, 6]])
"""
[[1 2 3]
[4 5 6]]
"""
print(array_one)
print(array_one[..., 1]) # [2 5] 第2列元素
print(array_one[1,...]) # [4 5 6] 第2行元素
print(array_one[1:2, 1:2]) # [[5]] 第2行第2列元素
"""
[[2 3]
[5 6]]
"""
print(array_one[..., 1:]) # 第2列及剩下的所有元素
if __name__== '__main__':
two()4.冒号 : 的作用
- 表示范围: 冒号用于表示一个范围。例如,array[1:3] 表示从索引 1 到索引 3(不包括 3)的元素。
- 表示所有元素: 单独使用冒号表示所有元素。例如,array[:, 1] 表示所有行的第 1 列。
- 步长: 双冒号后面可以跟一个步长值,表示每隔多少个元素取一个。例如,array[::2] 表示每隔一个元素取一个。
注:冒号对于一维数组按索引号截取,二维数组按行和列截取。
省略号 ... 的作用
-
表示所有维度: 省略号用于表示数组的所有维度。例如,array[..., 1] 表示取所有行的第 1 列。
-
简化多维切片: 在多维数组中,省略号可以简化切片操作,避免显式地写出所有维度的索引。
高级索引
1.NumPy 中的高级索引指的是使用整数数组、布尔数组或者其他序列来访问数组的元素。相比于基本索引,高级索引可以访问到数组中的任意元素,并且可以用来对数组进行复杂的操作和修改。
整数数组索引
1.整数数组索引是指使用一个数组来访问另一个数组的元素。这个数组中的每个元素都是目标数组中某个维度上的索引值。
2.案例
def one():
array_one = np.array([[1,2,3],[4,5,6]])
"""
[[1 2 3]
[4 5 6]]
"""
print(array_one)
# [0,1,0]代表行索引、[0,1,2]代表列索引;即取出索引坐标 (0,0)、(1,1)、(0,2) 的元素
array_one = array_one[[0,1,0],[0,1,2]]
"""
[1 5 3]
"""
print(array_one)
if __name__ == '__main__':
one()3.取出 4 * 3 数组四个角的数据:
import numpy as np
def two():
array_one = np.array([[0, 1, 2], [3, 4, 5], [6, 7, 8], [9, 10, 11]])
"""
原数组:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
"""
print('原数组:\n',array_one)
array_one = array_one[[0,0,-1,-1], [0,-1,0,-1]]
"""
这个数组的四个角元素是:
[ 0 2 9 11]
"""
print('这个数组的四个角元素是:')
print(array_one)
if __name__ =='__main__':
two()
布尔索引
1.布尔索引通过布尔运算(如:比较运算符)来获取符合指定条件的元素的数组。
2.案例1:一维数组的布尔索引
import numpy as np
# 创建一个一维数组
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
# 使用布尔索引筛选大于 5 的元素
bool_idx = arr > 5
print(bool_idx) # 输出: [False False False False False True True True True True]
# 使用布尔索引获取满足条件的元素
result = arr[bool_idx]
print(result) # 输出: [ 6 7 8 9 10]3.案例2:多维数组的布尔索引
import numpy as np
# 创建一个二维数组
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 使用布尔索引筛选大于 5 的元素
bool_idx = arr > 5
print(bool_idx)
# 输出:
# [[False False False]
# [False False True]
# [ True True True]]
# 使用布尔索引获取满足条件的元素
result = arr[bool_idx]
print(result) # 输出: [6 7 8 9]4.案例3:使用逻辑运算符(如 &、|、~)组合多个条件。(注意括号区分运算优先级)
import numpy as np
# 创建一个一维数组
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
# 使用布尔索引筛选大于 5 且小于 9 的元素
bool_idx = (arr > 5) & (arr < 9)
print(bool_idx) # 输出: [False False False False False True True True False False]
# 使用布尔索引获取满足条件的元素
result = arr[bool_idx]
print(result) # 输出: [6 7 8]5.逻辑运算符
- &:与运算,组合多个条件。
- |:或运算,组合多个条件。
- ~:非运算,取反条件。
广播(复制自身形式相同的维度)
1.广播(Broadcast)是 numpy 对不同形状(shape)的数组进行数值计算的方式, 对数组的算术运算通常在相应的元素上进行。这要求维数相同,且各维度的长度相同,如果不相同,可以通过广播机制,这种机制的核心是对形状较小的数组,在横向或纵向上进行一定次数的重复,使其与形状较大的数组拥有相同的维度。
2.广播规则
- 维度匹配:如果两个数组的维度数不同,维度数较少的数组会在前面补上长度为 1 的维度。
- 长度匹配:如果两个数组在某个维度上的长度不同,但其中一个数组在该维度上的长度为 1,则该数组会沿着该维度进行广播。
- 不匹配:如果两个数组在某个维度上的长度既不相同也不为 1,则广播失败,抛出 ValueError。
3.案例1:一维数组与标量相加(标量 1 被广播到与 arr 相同的形状,然后进行逐元素相加。)
import numpy as np
#一维数组和标量相加,可以理解为将标量扩充(重复标量)为何以为数组相同的列数的数组在与一维数组相加
# 创建一个一维数组
arr = np.array([1, 2, 3])
# 标量相加
result = arr + 1
print(result) # 输出: [2 3 4]4.案例2:二维数组与一维数组相加
import numpy as np
#二维数组和一维数组相加,理解为将一维数扩充为形状和二维数组的形状相同,扩充的行或列复制一维数组的行或列
# 创建一个二维数组
arr2d = np.array([[1, 2, 3], [4, 5, 6]])
# 创建一个一维数组
arr1d = np.array([10, 20, 30])
# 相加
result = arr2d + arr1d
print(result)
# 输出:
# [[11 22 33]
# [14 25 36]]5.案例3:二维数组与二维数组相加(arr2d_broadcast 被广播到与 arr2d 相同的形状,然后进行逐元素相加。)
import numpy as np
# 创建一个二维数组
arr2d = np.array([[1, 2, 3], [4, 5, 6]])
# 创建一个形状为 (1, 3) 的二维数组
arr2d_broadcast = np.array([[10, 20, 30]])
# 相加
result = arr2d + arr2d_broadcast
print(result)
# 输出:
# [[11 22 33]
# [14 25 36]]6.案例4:广播失败(抛出异常)
import numpy as np
# 创建一个二维数组
arr2d = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 创建一个形状为 (2, 3) 的二维数组
arr2d_broadcast = np.array([[10, 20, 30], [40, 50, 60]])
# 尝试相加
try:
result = arr2d + arr2d_broadcast
except ValueError as e:
print(e) # 输出: operands could not be broadcast together with shapes (3,3) (2,3)迭代数组
1.nditer 是 NumPy 中的一个强大的迭代器对象,用于高效地遍历多维数组。nditer 提供了多种选项和控制参数,使得数组的迭代更加灵活和高效。
2.控制参数(nditer 提供了多种控制参数,用于控制迭代的行为。)
(1)order 参数:用于指定数组的遍历顺序。默认情况下,nditer 按照 C 风格(行优先)遍历数组。
- C 风格(行优先): order='C'
- Fortran 风格(列优先): order='F'
# 创建一个二维数组
arr = np.array([[1, 2, 3], [4, 5, 6]])
# 使用 C 风格遍历数组
for x in np.nditer(arr, order='C'):
print(x)
# 输出:
# 1
# 2
# 3
# 4
# 5
# 6
# 使用 Fortran 风格遍历数组
for x in np.nditer(arr, order='F'):
print(x)
# 输出:
# 1
# 4
# 2
# 5
# 3
# 6(2)flags 参数:用于指定迭代器的额外行为。
- multi_index: 返回每个元素的多维索引。
- external_loop: 返回一维数组而不是单个元素,减少函数调用的次数,从而提高性能。
import numpy as np
# 创建一个三维数组
arr = np.array([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
"""
[[[1 2]
[3 4]]
[[5 6]
[7 8]]]
"""
print(arr)
# 使用 nditer 遍历数组并获取多维索引
it = np.nditer(arr, flags=['multi_index'])
for x in it:
print(f"Element: {x}, Index: {it.multi_index}")
# 输出:
# Element: 1, Index: (0, 0, 0)
# Element: 2, Index: (0, 0, 1)
# Element: 3, Index: (0, 1, 0)
# Element: 4, Index: (0, 1, 1)
# Element: 5, Index: (1, 0, 0)
# Element: 6, Index: (1, 0, 1)
# Element: 7, Index: (1, 1, 0)
# Element: 8, Index: (1, 1, 1)
#返回的是每一个一维数组相互对应的一维数组的单个数据组成的数组**
# 创建一个二维数组
arr = np.array([[1, 2, 3], [4, 5, 6]])
# 使用外部循环遍历数组
for x in np.nditer(arr, flags=['external_loop'], order='F'):
print(x)
# 输出:
# [1 4]
# [2 5]
# [3 6](3)op_flags 参数:于指定操作数的行为。
- readonly: 只读操作数。
- readwrite: 读写操作数。
- writeonly: 只写操作数。
import numpy as np
# 创建一个二维数组
arr = np.array([[1, 2, 3], [4, 5, 6]])
# 使用读写操作数遍历数组
for x in np.nditer(arr, op_flags=['readwrite']):
x[...] = 2 * x
print(arr)
# 输出:
# [[ 2 4 6]
# [ 8 10 12]]数组操作
数组变维
| 函数名称 | 函数介绍 |
|---|---|
| reshape | 在不改变数组元素的条件下,修改数组的形状 |
| flat | 返回是一个迭代器,可以用 for 循环遍历其中的每一个元素 |
| flatten | 以一维数组的形式返回一份数组的副本,对副本的操作不会影响到原数组 |
| ravel | 返回一个连续的扁平数组(即展开的一维数组),与 flatten不同,它返回的是数组视图(修改视图会影响原数组) |
reshape
1.在不改变数组元素的条件下,修改数组的形状
flat
1.返回一个一维迭代器,用于遍历数组中的所有元素。无论数组的维度如何,ndarray.flat属性都会将数组视为一个扁平化的一维数组,按行优先的顺序遍历所有元素。
2.语法
ndarray.flat
3.案例
import numpy as np
def flat_test():
array_one = np.arange(4).reshape(2,2)
"""
遍历的原数组元素:
[0 1] [2 3]
"""
print("原数组元素:")
for i in array_one:
print(i,end=" ")
print()
print("使用flat属性,遍历数组:")
"""
使用flat属性,遍历数组:
0 1 2 3
"""
for i in array_one.flat:
print(i,end=" ")
if __name__ == '__main__':
flat_test()
flatten()
1.用于将多维数组转换为一维数组。flatten() 返回的是原数组的一个拷贝,因此对返回的数组进行修改不会影响原数组。
2.语法
ndarray.flatten(order='C')
3.参数
(1)order: 指定数组的展开顺序。
'C':按行优先顺序展开(默认)。'F':按列优先顺序展开。'A':如果原数组是 Fortran 连续的,则按列优先顺序展开;否则按行优先顺序展开。'K':按元素在内存中的顺序展开。
4.案例
import numpy as np
# 创建一个二维数组
arr = np.array([[1, 2, 3], [4, 5, 6]])
# 使用 flatten 方法按行优先顺序展开
flat_arr = arr.flatten(order='C')
print(flat_arr)
# 输出:
# [1 2 3 4 5 6]ravel()
1。用于将多维数组转换为一维数组。与 flatten() 不同,ravel() 返回的是原数组的一个视图(view),而不是拷贝。因此,对返回的数组进行修改会影响原数组。
2.语法
ndarray.ravel()
3.参数
(1)order: 指定数组的展开顺序。
'C':按行优先顺序展开(默认)。'F':按列优先顺序展开。'A':如果原数组是 Fortran 连续的,则按列优先顺序展开;否则按行优先顺序展开。'K':按元素在内存中的顺序展开。
4.案例
import numpy as np
# 创建一个二维数组
arr = np.array([[1, 2, 3], [4, 5, 6]])
# 使用 ravel 方法按行优先顺序展开
ravel_arr = arr.ravel()
print(ravel_arr)
# 输出:
# [1 2 3 4 5 6]
#修改值,原数据也被修改
#原数组中的值会进行改变,但是维度却不会进行改变
ravel_arr[-1] = 7
print(arr)
# 输出:
# [[1 2 3]
# [4 5 7]]数组转置
| 函数名称 | 说明 |
|---|---|
| transpose | 将数组的维度值进行对换,比如二维数组维度(2,4)使用该方法后为(4,2) |
| ndarray.T | 与 transpose 方法相同 |
案例
import numpy as np
def transpose_test():
array_one = np.arange(12).reshape(3, 4)
"""
原数组:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
"""
print("原数组:")
print(array_one)
"""
[[ 0 4 8]
[ 1 5 9]
[ 2 6 10]
[ 3 7 11]]
"""
print("使用transpose()函数后的数组:")
print(np.transpose(array_one))
def T_test():
array_one = np.arange(12).reshape(3, 4)
"""
原数组:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
"""
print("原数组:")
print(array_one)
"""
数组转置:
[[ 0 4 8]
[ 1 5 9]
[ 2 6 10]
[ 3 7 11]]
"""
print("数组转置:")
print(array_one.T)
if __name__ == '__main__':
transpose_test()
T_test()修改数组维度
1.多维数组(也称为 ndarray)的维度(或轴)是从外向内编号的。这意味着最外层的维度是轴0,然后是轴1,依此类推。
| 函数名称 | 参数 | 说明 |
|---|---|---|
| expand_dims(arr, axis) | arr:输入数组 axis:新轴插入的位置 | 在指定位置插入新的轴(相对于结果数组而言),从而扩展数组的维度 |
| squeeze(arr, axis) | arr:输入数的组 axis:取值为整数或整数元组,用于指定需要删除的维度所在轴,指定的维度值必须为 1 ,否则将会报错,若为 None,则删除数组维度中所有为 1 的项 | 删除数组中维度为 1 的项 |
2.案例
import numpy as np
def expand_dims_test():
array_one = np.arange(4).reshape(2,2)
"""
原数组:
[[0 1]
[2 3]]
"""
print('原数组:\n', array_one)
"""
原数组维度情况:
(2, 2)
"""
print('原数组维度情况:\n', array_one.shape)
# 在 1 轴处插入新的轴
array_two = np.expand_dims(array_one, axis=1)
"""
在 1 轴处插入新的轴后的数组:
[[[0 1]]
[[2 3]]]
"""
print('在 1 轴处插入新的轴后的数组:\n', array_two)
"""
在 1 轴处插入新的轴后的数组维度情况:
(2, 1, 2)
"""
print('在 1 轴处插入新的轴后的数组维度情况:\n', array_two.shape)
def squeeze_test():
array_one = np.arange(6).reshape(2,1,3)
"""
原数组:
[[[0 1 2]]
[[3 4 5]]]
"""
print('原数组:\n', array_one)
"""
原数组维度情况:
(2, 1, 3)
"""
print('原数组维度情况:\n', array_one.shape)
# 删除
array_two = np.squeeze(array_one,1)
"""
从数组的形状中删除一维项后的数组:
[[0 1 2]
[3 4 5]]
"""
print('从数组的形状中删除一维项后的数组:\n', array_two)
"""
从数组的形状中删除一维项后的数组维度情况:
(2, 3)
"""
print('从数组的形状中删除一维项后的数组维度情况:\n', array_two.shape)
if __name__ == '__main__':
expand_dims_test()
squeeze_test()连接数组
| 函数名称 | 参数 | 说明 |
|---|---|---|
| hstack(tup) | tup:可以是元组,列表,或者numpy数组,返回结果为numpy的数组 | 按水平顺序堆叠序列中数组(列方向) |
| vstack(tup) | tup:可以是元组,列表,或者numpy数组,返回结果为numpy的数组 | 按垂直方向堆叠序列中数组(行方向) |
1.hstack函数要求堆叠的数组在垂直方向(行)上具有相同的形状。如果行数不一致,hstack() 将无法执行,并会抛出 ValueError 异常。
2.vstack() 要求堆叠的数组在垂直方向(行)上具有相同的形状。如果列数不一致,将无法执行堆叠操作。
3.vstack() 和 hstack() 要求堆叠的数组在某些维度上具有相同的形状。如果维度不一致,将无法执行堆叠操作。
4.案例
# hstack:
import numpy as np
# 创建两个形状不同的数组
arr1 = np.array([[1, 2], [3, 4]])
arr2 = np.array([[5], [6]])
print(arr1.shape) # (2, 2)
print(arr2.shape) # (2, 1)
# 使用 hstack 水平堆叠数组
result = np.hstack((arr1, arr2))
print(result)
# 输出:
# [[1 2 5]
# [3 4 6]]
# 创建两个形状不同的数组
arr1 = np.array([[1, 2], [3, 4]])
arr2 = np.array([[5], [6], [7]])
print(arr1.shape) # (2, 2)
print(arr2.shape) # (3, 1)
# 使用 hstack 水平堆叠数组
# result = np.hstack((arr1, arr2))
# print(result) 出错
# ValueError: all the input array dimensions except for the concatenation axis must match exactly
# 第一个数组在第0维有2个元素,而第二个数组在第0维有3个元素,因此无法直接连接。
import numpy as np
# vstack:
# 创建两个一维数组
arr1 = np.array([1, 2, 3])
arr2 = np.array([4, 5, 6])
# 使用 vstack 垂直堆叠数组
result = np.vstack((arr1, arr2))
print(result)
# 输出:
# [[1 2 3]
# [4 5 6]]
# 创建两个形状不同的数组
arr1 = np.array([[1, 2], [3, 4]])
arr2 = np.array([[5, 6, 7], [8, 9, 10]])
# 使用 vstack 垂直堆叠数组
result = np.vstack((arr1, arr2))
# print(result) 报错
# ValueError: all the input array dimensions except for the concatenation axis must match exactly
# 第一个数组在第1维有2个元素,而第二个数组在第1维有3个元素,因此无法直接连接。
分割数组(数组是几维的分割后维度不变)
| 函数名称 | 参数 | 说明 |
|---|---|---|
| hsplit(ary, indices_or_sections) | ary:原数组 indices_or_sections:按列分割的索引位置 | 将一个数组水平分割为多个子数组(按列) |
| vsplit(ary, indices_or_sections) | ary:原数组 indices_or_sections:按列分割的索引位置 | 将一个数组垂直分割为多个子数组(按行) |
案例
import numpy as np
'''
hsplit 函数:
1、将一个数组水平分割为多个子数组(按列)
2、ary:原数组
3、indices_or_sections:按列分割的索引位置
'''
# 创建一个二维数组
arr = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
# 使用 np.hsplit 将数组分割成三个子数组
# 分割点在索引1和3处,这意味着:
# 第一个子数组将包含从第0列到索引1(不包括索引1)的列,即第0列。
# 第二个子数组将包含从索引1(包括索引1)到索引3(不包括索引3)的列,即第1列到第2列。
# 第三个子数组将包含从索引3(包括索引3)到末尾的列,即第3列。
result = np.hsplit(arr, [1, 3])
# 查看结果
"""
第一个子数组:
[[1]
[5]
[9]]
"""
print("第一个子数组:\n", result[0]) # 输出包含第0列的子数组
"""
第二个子数组:
[[ 2 3]
[ 6 7]
[10 11]]
"""
print("第二个子数组:\n", result[1]) # 输出包含第1列和第2列的子数组
"""
第三个子数组:
[[ 4]
[ 8]
[12]]
"""
print("第三个子数组:\n", result[2]) # 输出包含第3列的子数组
import numpy as np
'''
vsplit 函数:
1、将一个数组垂直分割为多个子数组(按行)
2、ary:原数组
3、indices_or_sections:按列分割的索引位置
'''
array_one = np.arange(12).reshape(2,6)
"""
array_one 原数组:
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]]
"""
print('array_one 原数组:\n', array_one)
array_two = np.vsplit(array_one,[1])
"""
vsplit 之后的数组:
[array([[0, 1, 2, 3, 4, 5]]), array([[ 6, 7, 8, 9, 10, 11]])]
"""
print('vsplit 之后的数组:\n', array_two)数组元素的增删改查
resize
| 函数名称 | 参数 | 说明 |
|---|---|---|
| resize(a, new_shape) | a:操作的数组 new_shape:返回的数组的形状,如果元素数量不够,重复数组元素来填充新的形状 | 返回指定形状的新数组 |
import numpy as np
array_one = np.arange(6).reshape(2, 3)
"""
[[0 1 2]
[3 4 5]]
"""
print(array_one)
"""
resize 后数组:
[[0 1 2 3]
[4 5 0 1]
[2 3 4 5]]
"""
print('resize 后数组:\n', np.resize(array_one, (3, 4)))
最后一行代码将数组形状修改为(3, 4),原数组的元素数量不够,则重复原数组的元素填充。
append
| 函数名称 | 参数 | 说明 |
|---|---|---|
| append(arr, values, axis=None) | arr:输入的数组 values:向 arr 数组中添加的值,需要和 arr 数组的形状保持一致 axis:默认为 None,返回的是一维数组;当 axis =0 时,追加的值会被添加到行,而列数保持不变,若 axis=1 则与其恰好相反 | 在数组的末尾添加值,返回一个一维数组 |
import numpy as np
'''
append(arr, values, axis=None) 函数:
1、将元素值添加到数组的末尾,返回一个一维数组
2、arr:输入的数组
3、values:向 arr 数组中添加的值,需要和 arr 数组的形状保持一致
4、axis:默认为 None,返回的是一维数组;当 axis =0 时,追加的值会被添加到行,而列数保持不变,若 axis=1 则与其恰好相反
'''
#append(arr, values, axis=None):将values追加到arr数组后边
#如果不指定axis,则将values追加到arr数组后边,返回一维数组
#如果axis=0,则按行追加到arr数组后边
#如果axis=1,则将列追加到arr数组后边
def append_test():
array_one = np.arange(6).reshape(2,3)
"""
原数组:
[[0 1 2]
[3 4 5]]
"""
print('原数组:\n', array_one)
array_two = np.append(array_one,[[1,1,1],[1,1,1]],axis=None)
"""
append 后数组 axis=None:
[0 1 2 3 4 5 1 1 1 1 1 1]
"""
print('append 后数组 axis=None:\n', array_two)
array_three = np.append(array_one, [[1, 1, 1], [1, 1, 1]], axis=0)
"""
append 后数组 axis=0:
[[0 1 2]
[3 4 5]
[1 1 1]
[1 1 1]]
"""
print('append 后数组 axis=0:\n', array_three)
array_three = np.append(array_one, [[1, 1, 1], [1, 1, 1]], axis=1)
"""
append 后数组 axis=1:
[[0 1 2 1 1 1]
[3 4 5 1 1 1]]
"""
print('append 后数组 axis=1:\n', array_three)
if __name__ == '__main__':
append_test()insert
| 函数名称 | 参数 | 说明 |
|---|---|---|
| insert(arr, obj, values, axis) | arr:输入的数组 obj:表示索引值,在该索引值之前插入 values 值 values:要插入的值 axis:默认为 None,返回的是一维数组;当 axis =0 时,追加的值会被添加到行,而列数保持不变,若 axis=1 则与其恰好相反 | 沿规定的轴将元素值插入到指定的元素前 |
import numpy as np
# 插入的数组,要么长度相等,要么只含有一个元素(这一行或列将都是同一个添加的元素)
def insert_test():
array_one = np.arange(6).reshape(2,3)
"""
原数组:
[[0 1 2]
[3 4 5]]
"""
print('原数组:\n', array_one)
array_two = np.insert(array_one, 1, [6],axis=None)
"""
insert 后数组 axis=None:
[0 6 1 2 3 4 5]
"""
print('insert 后数组 axis=None:\n', array_two)
array_three = np.insert(array_one,1, [6], axis=0)
"""
insert 后数组 axis=0:
[[0 1 2]
[6 6 6]
[3 4 5]]
"""
print('insert 后数组 axis=0:\n', array_three)
array_three = np.insert(array_one, 1, [6,7], axis=1)
"""
insert 后数组 axis=1:
[[0 6 1 2]
[3 7 4 5]]
"""
print('insert 后数组 axis=1:\n', array_three)
if __name__ == '__main__':
insert_test()如果obj为-1,表示插入在倒数第一个元素之前。
delete
| 函数名称 | 参数 | 说明 |
|---|---|---|
| delete(arr, obj, axis) | arr:输入的数组 obj:表示要删除的数据索引值 axis:默认为 None,返回的是一维数组;当 axis =0 时,删除指定的行,若 axis=1 则与其恰好相反 | 删掉某个轴上的子数组,并返回删除后的新数组 |
- 一维数组:
# 创建一个 NumPy 数组
arr = np.array([1, 2, 3, 4, 5, 6])
# 删除索引为 2 和 4 的元素
new_arr = np.delete(arr, [2, 4])
print(new_arr) #[1 2 4 6]- 二维数组:
import numpy as np
def delete_test():
array_one = np.arange(6).reshape(2,3)
"""
原数组:
[[0 1 2]
[3 4 5]]
"""
print('原数组:\n', array_one)
array_two = np.delete(array_one,1,axis=None)
"""
delete 后数组 axis=None:
[0 2 3 4 5]
"""
print('delete 后数组 axis=None:\n', array_two)
array_three = np.delete(array_one,1, axis=0)
"""
delete 后数组 axis=0:
[[0 1 2]]
"""
print('delete 后数组 axis=0:\n', array_three)
array_three = np.delete(array_one, 1, axis=1)
"""
delete 后数组 axis=1:
[[0 2]
[3 5]]
"""
print('delete 后数组 axis=1:\n', array_three)
if __name__ == '__main__':
delete_test()argwhere
返回数组中非 0 元素的索引,若是多维数组则返回行、列索引组成的索引坐标
import numpy as np
'''
argwhere(a) 函数:
1、返回数组中非 0 元素的索引,若是多维数组则返回行、列索引组成的索引坐标
'''
def argwhere_test():
array_one = np.arange(6).reshape(2,3)
"""
原数组:
[[0 1 2]
[3 4 5]]
"""
print('原数组:\n', array_one)
"""
argwhere 返回非0元素索引:
[[0 1]
[0 2]
[1 0]
[1 1]
[1 2]]
"""
print('argwhere 返回非0元素索引:\n', np.argwhere(array_one))
"""
argwhere 返回所有大于 1 的元素索引:
[[0 2]
[1 0]
[1 1]
[1 2]]
"""
print('argwhere 返回所有大于 1 的元素索引:\n', np.argwhere(array_one > 1))
array_two = np.argwhere(array_one) > 5#如果要继续条件限制,注意比较符应该在括号中,在括号外就成了布尔索引
"""
[[False False]
[False False]
[False False]
[False False]
[False False]]
"""
print(array_two)
if __name__ == '__main__':
argwhere_test()unique
| 函数名称 | 参数 | 说明 |
|---|---|---|
| unique(ar, return_index=False, return_inverse=False, return_counts=False, axis=None) | ar:输入的数组 return_index:如果为 True,则返回新数组元素在原数组中的位置(索引) return_inverse:如果为 True,则返回原数组元素在新数组中的位置(逆索引) return_counts:如果为 True,则返回去重后的数组元素在原数组中出现的次数 | 删掉某个轴上的子数组,并返回删除后的新数组 |
1.案例1:返回唯一元素的索引
import numpy as np
# 创建一个 NumPy 数组
arr = np.array([1, 2, 2, 3, 4, 4, 5])
unique_elements, indices = np.unique(arr, return_index=True)
print(unique_elements) # [1 2 3 4 5]
print(indices) #[0 1 3 4 6]2.案例2:返回唯一元素及其逆索引
import numpy as np
# 创建一个一维数组
arr = np.array([1, 2, 2, 3, 3, 3, 4, 4, 4, 4])
# 使用 np.unique 查找唯一元素及其逆索引
unique_elements, inverse_indices = np.unique(arr, return_inverse=True)
print(unique_elements)
# 输出:
# [1 2 3 4]
print(inverse_indices)
# 输出:
# [0 1 1 2 2 2 3 3 3 3]
# 逆索引数组,表示原始数组中的每个元素在唯一元素数组中的位置。案例3:返回唯一元素的计数
import numpy as np
# 创建一个一维数组
arr = np.array([1, 2, 2, 3, 3, 3, 4, 4, 4, 4])
# 使用 np.unique 查找唯一元素及其计数
unique_elements, counts = np.unique(arr, return_counts=True)
print(unique_elements)
# 输出:
# [1 2 3 4]
print(counts)
# 输出:
# [1 2 3 4]对于多维数组,unique 函数同样适用。默认情况下,unique 函数会将多维数组展平为一维数组,然后查找唯一元素。
import numpy as np
arr = np.array([[1, 2], [2, 3], [1, 2]])
# 查找数组中的唯一元素
unique_elements = np.unique(arr)
print(unique_elements) #[1 2 3]统计函数
amin() 和 amax()
1.计算数组沿指定轴的最小值与最大值,并以数组形式返回
2.对于二维数组来说,axis = None(默认)表示返回一维数组进行操作,axis=1 表示沿着水平方向,axis=0 表示沿着垂直方向
3.案例
'''
numpy.amin() 和 numpy.amax() 函数:
1、计算数组沿指定轴的最小值与最大值,并以数组形式返回
2、对于二维数组来说,axis=1 表示沿着水平方向,axis=0 表示沿着垂直方向
'''
import numpy as np
def amin_amax_test():
array_one = np.array([[1, 23, 4, 5, 6], [1, 2, 333, 4, 5]])
"""
原数组元素:
[[ 1 23 4 5 6]
[ 1 2 333 4 5]]
"""
print('原数组元素:\n', array_one)
"""
原数组水平方向最小值:
1
"""
print('原数组水平方向最小值:\n', np.amin(array_one, axis=None))
"""
原数组水平方向最大值:
333
"""
print('原数组水平方向最大值:\n', np.amax(array_one, axis=None))
""""
原数组水平方向最小值:
[1 1]
"""
print('原数组水平方向最小值:\n', np.amin(array_one, axis=1))
"""
原数组水平方向最大值:
[ 23 333]
"""
print('原数组水平方向最大值:\n', np.amax(array_one, axis=1))
"""
原数组垂直方向最小值:
[1 2 4 4 5]
"""
print('原数组垂直方向最小值:\n', np.amin(array_one, axis=0))
"""
原数组垂直方向最大值:
[ 1 23 333 5 6]
"""
print('原数组垂直方向最大值:\n', np.amax(array_one, axis=0))
if __name__ == '__main__':
amin_amax_test()按1轴求最小值,表示在最内层轴中(每列中)分别找最小值;按0轴求最小值表示在最外层轴中(所有行中按列)找最小值。求最大值类似。
ptp()
1.计算数组元素中最值之差值,即最大值 - 最小值
2.对于二维数组来说,axis = None(默认)表示返回一维数组进行操作,axis=1 表示沿着水平方向,axis=0 表示沿着垂直方向
import numpy as np
# 创建一个二维数组
arr = np.array([[1, 2, 3], [4, 5, 6]])
# 使用 np.ptp 计算峰峰值
ptp_value = np.ptp(arr)
print(ptp_value) # 5
# 使用 np.ptp 按行计算峰峰值
ptp_values_none = np.ptp(arr, axis=None)
print(ptp_values_none) # 5
# 使用 np.ptp 按行计算峰峰值
ptp_values_row = np.ptp(arr, axis=1)
print(ptp_values_row) # [2 2]
# 使用 np.ptp 按列计算峰峰值
ptp_values_col = np.ptp(arr, axis=0)
print(ptp_values_col) # [3 3 3]
median()
1.用于计算中位数,中位数是指将数组中的数据按从小到大的顺序排列后,位于中间位置的值。如果数组的长度是偶数,则中位数是中间两个数的平均值。
2.2.对于二维数组来说,axis = None(默认)表示返回一维数组进行操作,axis=1 表示沿着水平方向,axis=0 表示沿着垂直方向
# 创建一个二维数组
arr = np.array([[1, 2, 3], [4, 5, 6]])
# 使用 np.median 计算中位数
median_value = np.median(arr,axis=None)
print(median_value)
# 输出:
# 3.5
# 使用 np.median 按行计算中位数
median_values_row = np.median(arr, axis=1)
# 使用 np.median 按列计算中位数
median_values_col = np.median(arr, axis=0)
print(median_values_row)
# 输出:
# [2. 5.]
print(median_values_col)
# 输出:
# [2.5 3.5 4.5]mean()
1.沿指定的轴,计算数组中元素的算术平均值(即元素之总和除以元素数量)
2.对于二维数组来说,axis = None(默认)表示返回一维数组进行操作 axis=1 表示沿着水平方向,axis=0 表示沿着垂直方向
# 创建一个一维数组
arr = np.array([1, 2, 3, 4, 5])
# 使用 np.mean 计算平均值
mean_value = np.mean(arr)
print(mean_value)
# 输出:
# 3.0
# 创建一个二维数组
arr = np.array([[1, 2, 3], [4, 5, 6]])
# 使用 np.mean 计算平均值
mean_value = np.mean(arr)
print(mean_value)
# 输出:
# 3.5
# 使用 np.mean 按行计算平均值
mean_values_row = np.mean(arr, axis=1)
# 使用 np.mean 按列计算平均值
mean_values_col = np.mean(arr, axis=0)
print(mean_values_row)
# 输出:
# [2. 5.]
print(mean_values_col)
# 输出:
# [2.5 3.5 4.5]average()
加权平均值是将数组中各数值乘以相应的权数,然后再对权重值求总和,最后以权重的总和除以总的单位数(即因子个数);根据在数组中给出的权重,计算数组元素的加权平均值。该函数可以接受一个轴参数 axis,如果未指定,则数组被展开为一维数组。
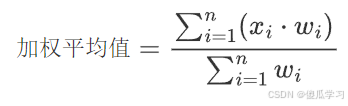
其中 xi是数组中的元素,wi是对应的权重。
如果所有元素的权重之和等于1,则表示为数学中的期望值。
# 创建一个一维数组
arr = np.array([1, 2, 3, 4, 5])
# 创建权重数组
weights = np.array([0.1, 0.2, 0.3, 0.2, 0.2])
# 使用 np.average 计算加权平均值
average_value = np.average(arr, weights=weights)
print(average_value)
# 输出:
# 3.2var()
在 NumPy 中,计算方差时使用的是统计学中的方差公式,而不是概率论中的方差公式,主要是因为 NumPy 的设计目标是处理实际数据集,而不是概率分布。
np.var 函数默认计算的是总体方差(Population Variance),而不是样本方差(Sample Variance)。
总体方差:
对于一个总体数据集 X={x1,x2,…,xN},总体方差的计算公式为:
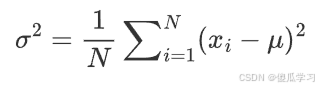
其中:
-
N是总体数据点的总数。
-
μ是总体的均值。
# 创建一个数组
arr = np.array([1, 2, 3, 4, 5])
# 计算方差
variance = np.var(arr)
print(variance)
#输出:2样本方差:
对于一个样本数据集 X={x1,x2,…,xn},样本方差 的计算公式为:
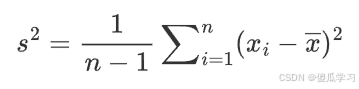
其中:
-
n是样本数据点的总数。
-
xˉ是样本的均值。
在样本数据中,样本均值的估计会引入一定的偏差。通过使用 n−1n−1 作为分母,可以校正这种偏差,得到更准确的总体方差估计。
# 创建一个数组
arr = np.array([1, 2, 3, 4, 5])
# 计算方差
variance = np.var(arr, ddof=1)
print(variance)
#输出:2.5std()
标准差是方差的算术平方根,用来描述一组数据平均值的分散程度。若一组数据的标准差较大,说明大部分的数值和其平均值之间差异较大;若标准差较小,则代表这组数值比较接近平均值
# 创建一个数组
arr = np.array([1, 2, 3, 4, 5])
# 计算标准差
std_dev = np.std(arr)
print(std_dev)
# 输出:1.4142135623730951本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » NumPy的基础知识

发表评论 取消回复