摘要
自注意力机制是Transformer的关键,但计算过于复杂。以前的工作主要是从减少计算冗余的角度,但仍然需要加载完整的网络,并需要相同的内存成本。论文介绍了一种新颖的方法,通过选择性移除非必要的注意力层来简化视觉Transformer,并减少计算负载,其指导思想是基于熵的考虑。我们发现,对于底层的注意力层,其后续的多层感知器(MLP)层(即两个前馈层)可以诱发出相同的熵量。同时,伴随的MLP层由于其特征熵小于顶层块中的MLP层,因此未被充分利用。因此,我们提出通过将无信息的注意力层退化为其后续层相同的映射,将它们整合到后续层中,在某些Transformer块中只留下MLP。在ImageNet-1k上的实验结果表明,提出的方法可以移除40个DeiT-B,提高了吞吐量并消除了内存瓶颈,而没有性能妥协。
代码链接:https://github.com/sihaoevery/lambda_vit
概述
拟解决的问题:论文旨在解决视觉Transformer模型中自注意力机制带来的高计算需求问题。尽管先前的研究通过剪枝或合并冗余的注意力层来减少计算冗余,但这些方法仍需加载完整网络,并占用与原始模型相同的内存成本。因此,该工作的目标是直接移除那些信息量低的注意力层,以推动内存限制的边界。
动机:
- 先前的研究已经发现,在Transformer模型中,不同头(head)或阶段(stage)的注意力层之间存在相似性,表明这些层具有一定的冗余性。
- 熵是信息论中衡量不确定性或信息量的指标。在神经网络中,熵可以用来衡量网络层输出的信息丰富度。
- 通过分析不同注意力层和MLP层的熵分布,研究者们发现底层的注意力层携带的信息量较少,而相应的MLP层具有相似的信息量,这表明MLP层可能能够替代这些注意力层的功能。
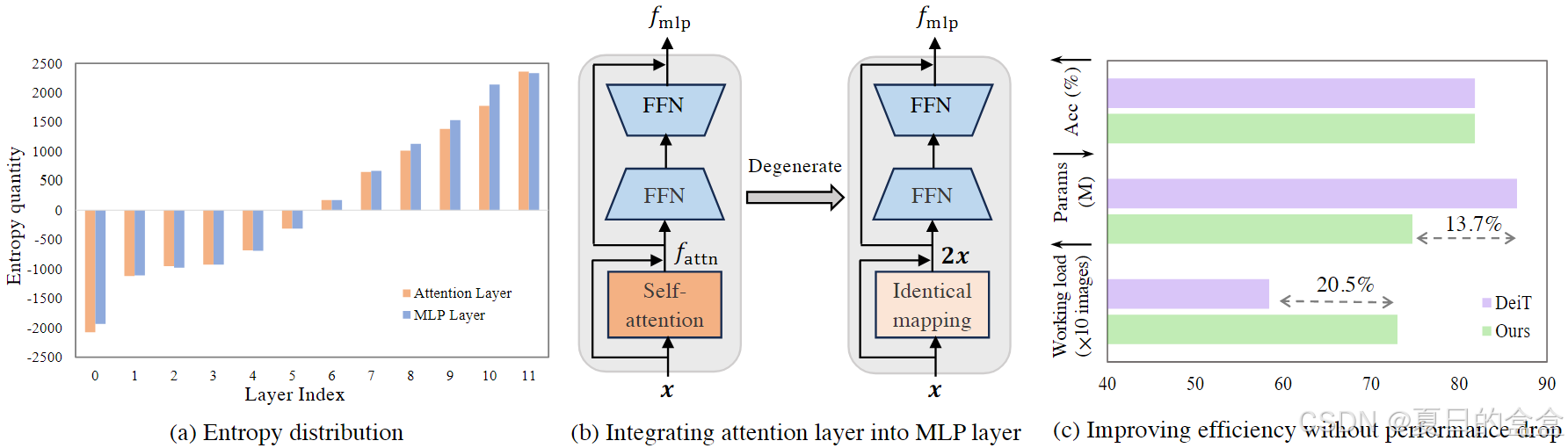
图1(a):熵分布图:使用熵来说明DeiT-B模型中每个Transformer块的注意力层和MLP层(即两个前馈层)携带的信息量。
- 观察结果:(1)底部块的注意力层的熵量比顶部块的低,表明底部块的注意力层携带的信息较少。(2)发现低熵的注意力层伴随着同一层级MLP层的熵量也较低。
- 可得:一方面,由于底部块中的MLP层包含与注意层相同的熵,因此它们可能会引出相同的信息。另一方面,与顶部块的MLP层相比,它们的熵量较低,表明这些mlp未被充分利用,因此可以优化为与顶部块中的mlp一样具有表现力。
图1(b):将注意力层集成到MLP:在熵的背景下,注意力层执行的信息是否可以通过适当的优化移植到相应的MLP层中?
- 如图 1 (b) 所示,注意力层的输出特征是后续 MLP 层的输入。鉴于这一事实,提出了一种优化方法,将信息量低的注意力层整合到其后续的MLP层中,通过退化注意力层为相同映射,最终在某些Transformer块中仅保留MLP层。
图1(c):效果图:该方法能够减少DeiT-B模型13.7%的参数,并在相同的内存预算下提高20.5%的工作负载,而不会降低性能。
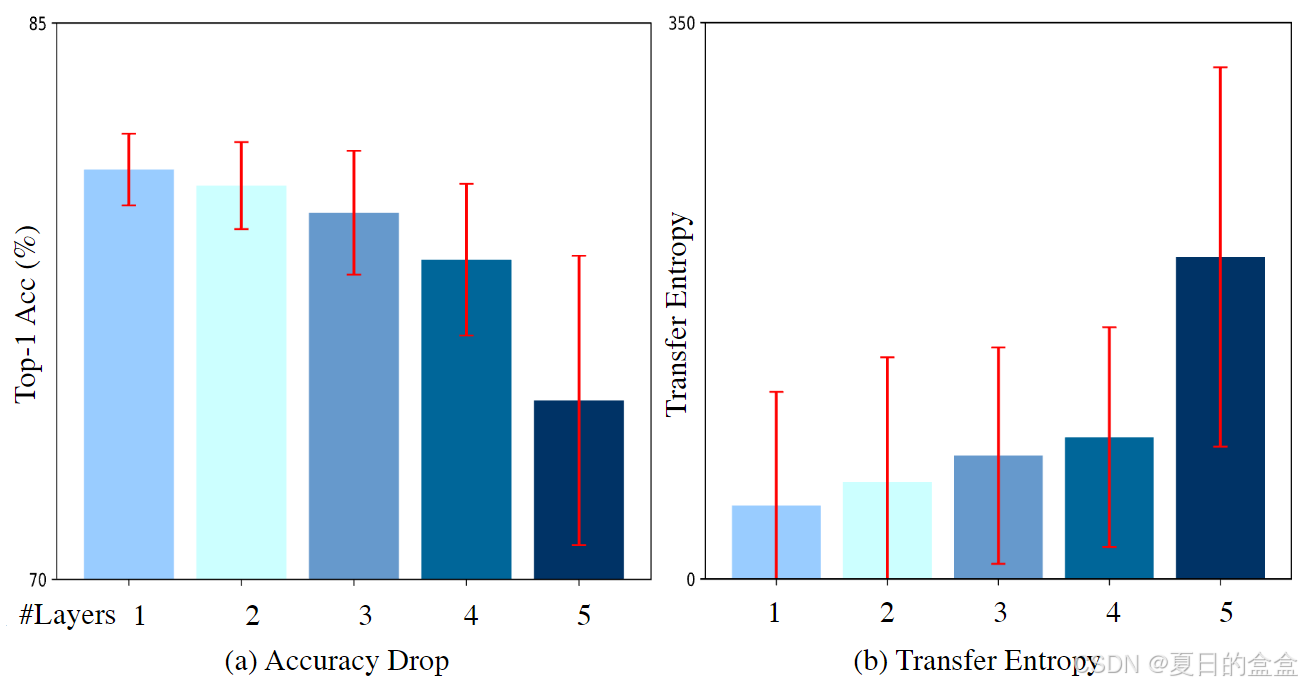
图2说明了为什么需要一种策略(熵转移)来智能地选择哪些注意力层可以被移除,而不会显著影响模型性能。
图2(a):准确度下降
- 目的:评估随机屏蔽(masking)1到5个注意力层对预训练DeiT-B模型性能的影响。
- 方法:通过随机选择并屏蔽一定数量的注意力层,记录模型性能的平均值(条形图)和方差(红线)。
- 观察结果:随着屏蔽的注意力层数量增加,模型的准确度下降。这表明注意力层之间的相互作用对模型性能有重要影响。
图2(b):转移熵
- 目的:使用转移熵(Transfer Entropy)来量化不同注意力层组合对最终输出层的影响。
- 方法:对于每个可能的注意力层组合,计算它们与最终输出层之间的转移熵,以衡量信息从注意力层到输出层的转移量。
- 观察结果:随着屏蔽的注意力层数量增加,转移熵增加,表明模型性能下降与层间信息转移的增加有关。
创新之处:
- 熵基选择策略(NOSE):提出了一种基于熵的选择策略,用于识别和选择可以被移除的注意力层,而不影响模型性能。
- 稀释学习技术:提出了一种将注意力层逐渐退化为相同映射的方法,使得这些层最终可以被整合到后续的MLP层中,从而在某些Transformer块中仅保留MLP。
- 内存和计算效率的提升:通过移除注意力层,该方法减少了模型参数和工作负载,提高了内存效率,解决了之前方法未能触及的内存限制问题。
方法
3.1 Vision Transformer
视觉Transformer(ViT)由一个patch嵌入层P和一系列Transformer块A组成,后面可能跟一个特定任务的头G。Transformer块包括自注意力层Attn和随后的MLP层。
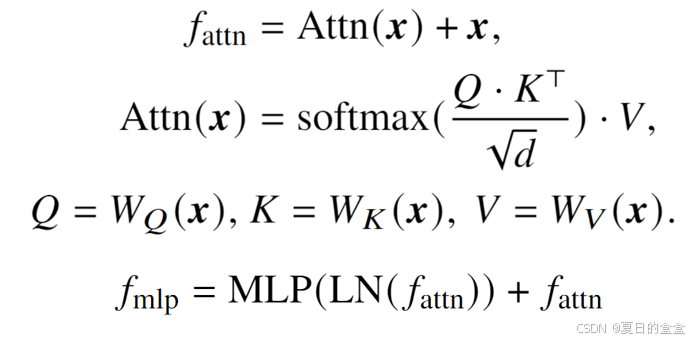
3.2 熵量化
熵是衡量信息量的一个指标。在神经网络中,熵可以用来衡量网络层输出的信息丰富度。通过计算某层特征的概率分布,可以得到该层的熵。由于直接测量特征图的概率分布较为困难,因此使用高斯分布来近似中间特征的概率分布,并据此计算熵。对于一个给定的层,其熵 H(F) 可以通过以下公式近似计算:
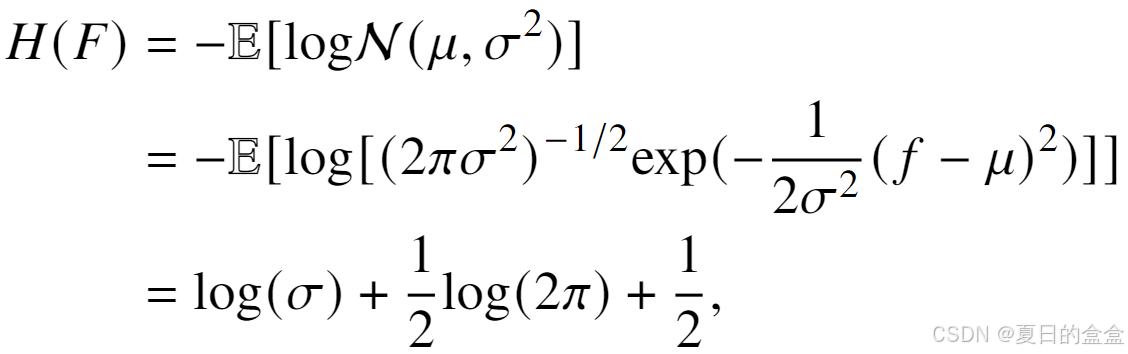
在不考虑常数项的情况下,每一层的熵与每个特征通道标准差的对数之和成正比:
3.3 多层注意力之间的交互
为了确定哪些注意力层可以被移除,提出了基于熵的选择策略(NOSE),通过迭代的方式选择与最终输出层相关性最小的注意力层组合。通过转移熵(TE)来衡量两个层之间的信息转移量。给定一个目标层,转移熵比较了源层存在或不存在的熵量的差异
其中,

基于熵的选择策略,称为 NOSE,以选择转移熵最小的注意力层到最终输出层。所提出的 NOSE 将迭代地测量注意力层和最终输出层之间的传输熵。在每一轮中,NOSE 遍历候选注意力层 C,并使用贪婪搜索找出该层具有最小的转移熵。该层附加到状态集 S 中,该状态集将与候选集分离并不会参与下一个循环。然后,我们通过考虑先前的状态来重复该过程,直到组合达到足够数量的。
3.4 将注意力层整合到MLP
由于MLP层的输入是注意力层的输出,因此提出了一种将注意力层逐渐退化为相同映射的方法,并将相同的映射与残差连接一起整合到后续的MLP层中。
稀释注意力输出:注意力层与原始架构和稀疏掩码解耦。
其中⊙是逐元素乘法。稀疏掩码M通常受到一些约束,例如 L0 范数,并用于正则化注意力输出的稀疏性。M被初始化为 1,并在训练过程中手动衰减到 0。我们在实验中展示了M的实现对不同的选择具有鲁棒性。一旦稀疏掩码衰减到 0,注意力层的输出 attn 就变成了残差连接。
特征补偿:随着稀疏掩模衰减,它不断消失注意层的梯度。因此,退化输出的后向梯度将小于原始输出,从而导致训练不稳定。为此,我们提出了特征补偿,它自适应地补偿稀疏掩码带来的梯度损失:
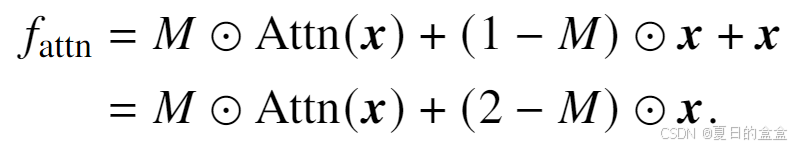
引入一个新术语(1−𝑀)⊙𝒙。它将相应地补偿继𝑀之后注意力输出Attn(𝒙)的损失。最后,注意力层退化为一个相同的映射,得到输出2𝒙。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 《MLP Can Be A Good Transformer Learner》CVPR2024

发表评论 取消回复