目录
前言
LangChain给自身的定位是:用于开发由大语言模型支持的应用程序的框架。它的做法是:通过提供标准化且丰富的模块抽象,构建大语言模型的输入输出规范,利用其核心概念chains,灵活地连接整个应用开发流程。 这里是LangChain系列的第三篇,主要介绍LangChain的检索模块。
一、LangChain
1-1、介绍
LangChain是一个框架,用于开发由大型语言模型(LLM)驱动的应用程序。
LangChain 简化了 LLM 应用程序生命周期的每个阶段:
- 开发:使用LangChain的开源构建块和组件构建应用程序。使用第三方集成和模板开始运行。
- 生产化:使用 LangSmith 检查、监控和评估您的链条,以便您可以自信地持续优化和部署。
- 部署:使用 LangServe 将任何链转换为 API。
总结: LangChain是一个用于开发由LLM支持的应用程序的框架,通过提供标准化且丰富的模块抽象,构建LLM的输入输出规范,主要是利用其核心概念chains,可以灵活地链接整个应用开发流程。(即,其中的每个模块抽象,都是源于对大模型的深入理解和实践经验,由许多开发者提供出来的标准化流程和解决方案的抽象,再通过灵活的模块化组合,才得到了langchain)
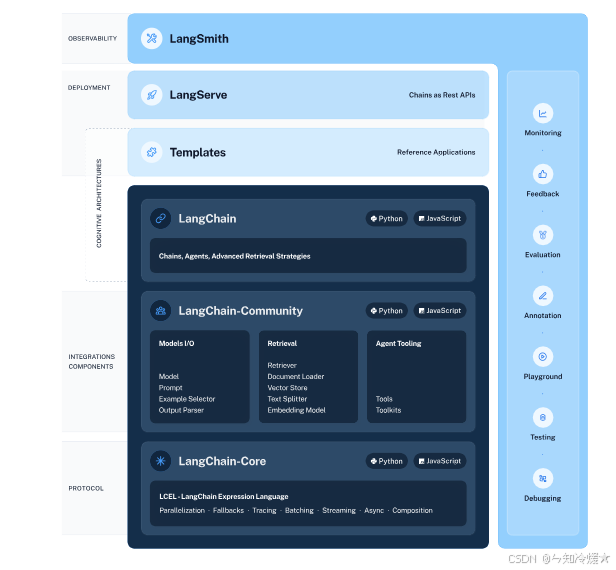
1-2、LangChain抽象出来的核心模块
想象一下,如果要组织一个AI应用,开发者一般需要?
- 提示词模板的构建,不仅仅只包含用户输入!
- 模型调用与返回,参数设置,返回内容的格式化输出。
- 知识库查询,这里会包含文档加载,切割,以及转化为词嵌入(Embedding)向量。
- 其他第三方工具调用,一般包含天气查询、Google搜索、一些自定义的接口能力调用。
- 记忆获取,每一个对话都有上下文,在开启对话之前总得获取到之前的上下文吧?
由上边的内容,引出LangChain抽象的一些核心模块:
LangChain通过模块化的方式去高级抽象LLM在不同场景下的能力,其中LangChain抽象出的最重要的核心模块如下:‘
- Model I/O :标准化各个大模型的输入和输出,包含输入模版,模型本身和格式化输出;
- Retrieval :检索外部数据,然后在执行生成步骤时将其传递到 LLM,包括文档加载、切割、Embedding等;
- Chains :链条,LangChain框架中最重要的模块,链接多个模块协同构建应用,是实际运作很多功能的高级抽象;
- Memory : 记忆模块,以各种方式构建历史信息,维护有关实体及其关系的信息;
- Agents : 目前最热门的Agents开发实践,未来能够真正实现通用人工智能的落地方案;
- Callbacks :回调系统,允许连接到 LLM 应用程序的各个阶段。用于日志记录、监控、流传输和其他任务;
1-3、特点
LangChain的特点如下:
-
大语言模型(llm): LangChain为自然语言处理提供了不同类型的模型,这些模型可用于处理非结构化文本数据,并且可以基于用户的查询检索信息
-
PromptTemplates: 这个特征使开发人员能够使用多个组件为他们的模型构造输入提示。在查询时,开发人员可以使用PromptTemplates为用户查询构造提示模板,之后模板会传递到大模型进行进一步的处理。
-
链:在LangChain中,链是一系列模型,它们被连接在一起以完成一个特定的目标。聊天机器人应用程序的链实例可能涉及使用LLM来理解用户输入,使用内存组件来存储过去的交互,以及使用决策组件来创建相关响应。
-
agent: LangChain中的agent与用户输入进行交互,并使用不同的模型进行处理。Agent决定采取何种行动以及以何种顺序来执行行动。例如,CSV Agent可用于从CSV文件加载数据并执行查询,而Pandas Agent可用于从Pandas数据帧加载数据并处理用户查询。可以将代理链接在一起以构建更复杂的应用程序。
1-4、langchain解决的一些行业痛点
在使用大模型的过程中,一些行业痛点:
- 大模型的使用规范以及基于大模型的开发范式不尽相同,当使用一个新模型时,我们往往需要学习新的模型规范。
- 大模型知识更新的滞后性
- 大模型的外部API调用能力
- 大模型输出的不稳定问题,如何稳定输出?
- 大模型与私有化数据的连接方式?
1-5、安装
pip install langchain
二、检索模块详解
许多LLM应用程序需要用户特定数据,这些数据不是模型的训练集的一部分. 完成这一任务的主要方法是通过检索增强生成(RAG). 在此过程中,检索外部数据,然后在生成步骤中将其传递给LLM.
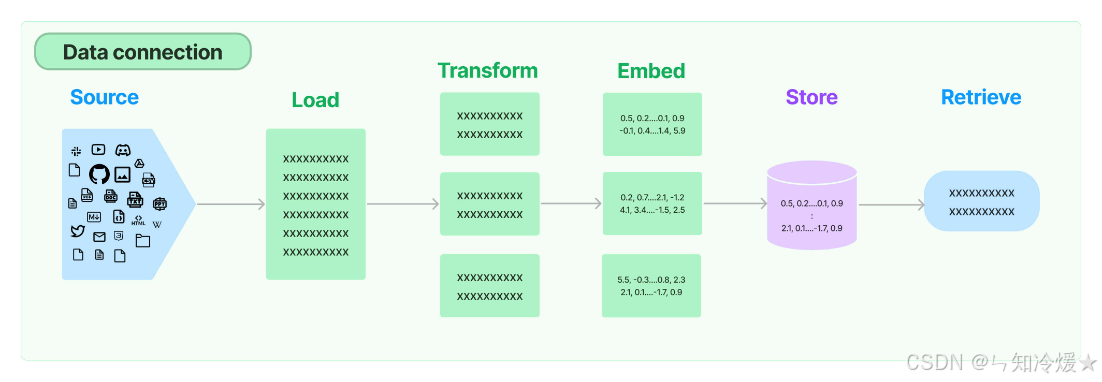
2-1、文档加载器
文档加载器: 从许多不同来源加载文档. LangChain提供了100多种不同的文档加载器,并与空间中的其他主要提供商(如AirByte和Unstructured)集成. 提供了加载各种类型文档(HTML、PDF、代码)的集成,
2-1-1、Demo示例
TextLoader: TextLoader 是 LangChain 中用于加载文本文件(如 .txt 文件)的加载器。它将文本文件的内容读取为 Document 对象,这些对象包含了文本内容以及相关的元数据。
from langchain.document_loaders import TextLoader
loader = TextLoader("./index.txt")
loader.load()
输出:
[Document(metadata={‘source’: ‘./index.txt’}, page_content=‘111’)]
2-1-2、JSON加载
JSONLoader: JSONLoader 是 LangChain 中用于加载 JSON 文件并将其转换为 LangChain 可理解的文档格式的工具。它允许你指定如何从 JSON 结构中提取信息,并将其作为文档内容和元数据。
以下是 JSONLoader 的一些关键特性:
- 使用 jq 语法:JSONLoader 使用 jq 语法来查询和提取 JSON 数据。jq 是一个强大的命令行 JSON 处理器,它的语法可以用来指定从 JSON 文件中提取哪些部分。(在使用 JSONLoader 之前,需要确保安装了 jq 库,可以通过 pip install jq 命令进行安装)
- 加载 JSON 数据:使用 load 方法从 JSON 文件中加载数据。可以指定 jq_schema 来提取特定的 JSON 数据结构。(即指定要提取的数据路径)
- 自定义内容和元数据:你可以指定要从 JSON 数据中提取的内容键(content_key)(即内容对应的键值是什么),以及如何生成每个文档的元数据(通过 metadata_func)。
- 支持 JSON Lines:如果你的 JSON 文件是 JSON Lines 格式(每行一个 JSON 对象),JSONLoader 支持通过设置 json_lines=True 来加载这种格式的文件。
- 异步加载:JSONLoader 还支持异步加载,这对于处理大型文件或提高性能很有帮助。
以下为所要读取的json数据以及对应的代码:
{
"messages": [
{
"content": "Hello, how are you?",
"sender_name": "User1",
"timestamp_ms": 1675091462000
},
{
"content": "I am fine, thanks!",
"sender_name": "User2",
"timestamp_ms": 1675091490000
},
{
"content": "That's great to hear!",
"sender_name": "User1",
"timestamp_ms": 1675091515000
}
]
}
from langchain_community.document_loaders import JSONLoader
# 定义一个函数来自定义文档的元数据
def metadata_func(record: dict, metadata: dict) -> dict:
metadata['sender_name'] = record.get('sender_name')
metadata['timestamp_ms'] = record.get('timestamp_ms')
return metadata
# 初始化 JSONLoader 实例
loader = JSONLoader(
file_path='path_to_your_json_file.json',
jq_schema='.messages[]', # 使用 jq 语法指定要提取的数据路径
content_key='content', # 指定内容键
metadata_func=metadata_func, # 自定义元数据函数
json_lines=False # 如果文件是 JSON Lines 格式,设置为 True
)
# 加载 JSON 文件并获取文档列表
documents = loader.load()
# 遍历文档列表并打印内容和元数据
for doc in documents:
print(doc.page_content)
print(doc.metadata)
输出:
Hello, how are you?
{‘source’: ‘C:\Users\tech\Jupyter_Notebook_Project\index.json’, ‘seq_num’: 1, ‘sender_name’: ‘User1’, ‘timestamp_ms’: 1675091462000}
I am fine, thanks!
{‘source’: ‘C:\Users\tech\Jupyter_Notebook_Project\index.json’, ‘seq_num’: 2, ‘sender_name’: ‘User2’, ‘timestamp_ms’: 1675091490000}
That’s great to hear!
{‘source’: ‘C:\Users\tech\Jupyter_Notebook_Project\index.json’, ‘seq_num’: 3, ‘sender_name’: ‘User1’, ‘timestamp_ms’: 1675091515000}
2-1-3、CSV加载
CSVLoader 是 LangChain 中用于加载 CSV 文件的组件。CSV 文件是一种常见的数据格式,通常用于存储表格数据,如电子表格或数据库导出的数据。CSVLoader 可以帮助你将这些数据导入到 LangChain 中,进而进行进一步的处理或分析。
以下是 CSVLoader 的一些关键特性:
- 自动推断列名:如果 CSV 文件的第一行包含列名,CSVLoader 可以自动识别这些列名。
- 自定义列名:如果 CSV 文件没有标题行,你可以在创建 CSVLoader 实例时提供列名列表。
- 选择特定列:你可以选择加载 CSV 文件中的特定列,而不是加载所有列。
- 惰性加载:CSVLoader 支持惰性加载(lazy loading),这意味着数据会按需加载,而不是一次性加载整个文件到内存中。
- 多线程加载:为了提高加载效率,CSVLoader 支持多线程加载。
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path='./example_data/mlb_teams_2012.csv', csv_args={
# 指定分隔符。
'delimiter': ',',
# 提供列名,在csv文件没有标题时特别有用。
'fieldnames': ['MLB Team', 'Payroll in millions', 'Wins']
})
data = loader.load()
data
2-2、文档转换器
文档转换器: 一旦加载了文档,您通常会希望对其进行转换,以更好地适应您的应用程序。最简单的例子是您可能希望将长文档拆分为更小的块,以适应您模型的上下文窗口。LangChain提供了许多内置的文档转换器,使得拆分、合并、过滤和其他文档操作变得容易。
2-2-1、按字符进行拆分
CharacterTextSplitter : 将文本分割成单个字符或者基于字符的小块。这种类型的文本分割器对于某些特定的NLP任务非常有用,比如字符级的语言模型训练、拼写检查、语音识别等。
- separator: 这个参数指定了用于分割文本的分隔符。在这种情况下,“\n\n” 表示将使用两个换行符作为分隔符,这通常用于将段落或日志条目分开。
- chunk_size: 这个参数设置了每个文本块的目标大小。在这里,1000 表示每个块将包含最多 1000 个字符。分隔符的优先级比该参数更高。
- chunk_overlap:每个块与前一个块的重叠字符数为20。
from langchain.text_splitter import CharacterTextSplitter
# This is a long document we can split up.
with open('./index.txt', encoding='utf-8') as f:
state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(
separator = "\n\n",
chunk_size = 100,
chunk_overlap = 20,
length_function = len,
)
texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
输出:

? 除了separator 参数起到了作用,其他参数好像没用?
2-2-2、按代码分割
RecursiveCharacterTextSplitter: 允许进行多种语言的代码分割, 这个文本分割器是用于通用文本的推荐分割器。它通过一个字符列表进行参数化。它会按顺序尝试使用这些字符进行分割,直到块的大小足够小。默认的分割字符列表为:[“\n\n”, “\n”, " ", “”]
- chunk_size: 这个参数设置了每个文本块的目标大小。在这里,1000 表示每个块将包含最多 1000 个字符。分隔符的优先级比该参数更高。
- chunk_overlap:每个块与前一个块的重叠字符数为20。
from langchain.text_splitter import (
RecursiveCharacterTextSplitter,
Language,
)
PYTHON_CODE = """
def hello_world():
print("Hello, World!")
# Call the function
hello_world()
"""
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, chunk_size=50, chunk_overlap=10
)
python_docs = python_splitter.create_documents([PYTHON_CODE])
python_docs
输出:
[Document(page_content=‘def hello_world():\n print(“Hello, World!”)’),
Document(page_content=‘# Call the function\nhello_world()’)]
? 这里的chunk_size测试有用,chunk_overlap参数依旧没反应。
其他语言支持:
- Language.JS
- Language.MARKDOWN
- Language.SOL
2-2-3、MarkdownHeaderTextSplitter
MarkdownHeaderTextSplitter 是 LangChain 库中的一个类,用于根据指定的 Markdown 标题将 Markdown 文件分割成多个部分。这个工具特别适用于需要保留文档结构的场景,例如在嵌入和向量存储之前对输入文档进行分块。
主要功能
- 识别 Markdown 标题:根据指定的标题级别(如 #、##、###)来分割文本。
- 分割文本:在每个指定的标题处分割文本,创建独立的文本块。
- 保留结构:在分割文本时保留 Markdown 的结构,确保每个文本块都是完整的,包含标题和相应的内容。
- 元数据:为每个分割的块添加元数据,记录标题信息。
需要拆分的内容如下:
# Foo\n\n
## Bar\n\nHi this is Jim\n\nHi this is Joe\n\n
### Boo \n\n Hi this is Lance \n\n
## Baz\n\n Hi this is Molly"
from langchain.text_splitter import MarkdownHeaderTextSplitter
markdown_document = "# Foo\n\n ## Bar\n\nHi this is Jim\n\nHi this is Joe\n\n ### Boo \n\n Hi this is Lance \n\n ## Baz\n\n Hi this is Molly"
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_header_splits = markdown_splitter.split_text(markdown_document)
for split in md_header_splits:
print(split)
输出:
page_content=‘Hi this is Jim
Hi this is Joe’ metadata={‘Header 1’: ‘Foo’, ‘Header 2’: ‘Bar’}
page_content=‘Hi this is Lance’ metadata={‘Header 1’: ‘Foo’, ‘Header 2’: ‘Bar’, ‘Header 3’: ‘Boo’}
page_content=‘Hi this is Molly’ metadata={‘Header 1’: ‘Foo’, ‘Header 2’: ‘Baz’}
其他分词器
- Spacy: from langchain.text_splitter import SpacyTextSplitter
- SentenceTransformers: from langchain.text_splitter import SentenceTransformersTokenTextSplitter
- NLTK: from langchain.text_splitter import NLTKTextSplitter
2-3、文本嵌入模型
文本嵌入模型: 从许多不同来源加载文档. LangChain提供了100多种不同的文档加载器,并与空间中的其他主要提供商(如AirByte和Unstructured)集成. 我们提供了加载各种类型文档(HTML、PDF、代码)的集成,
2-3-1、ModelScopeEmbeddings
ModelScopeEmbeddings: ModelScope提供的词嵌入接口,这里指定使用模型"damo/nlp_corom_sentence-embedding_english-base"。
from langchain.embeddings import ModelScopeEmbeddings
model_id = "damo/nlp_corom_sentence-embedding_english-base"
embeddings = ModelScopeEmbeddings(model_id=model_id)
text = "This is a test document."
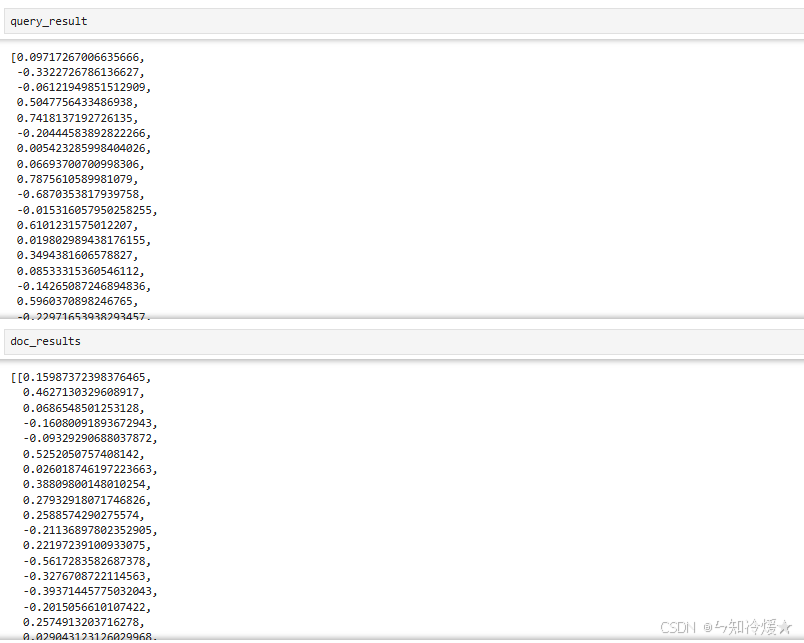
query_result = embeddings.embed_query(text)
doc_results = embeddings.embed_documents(["foo"])
输出:
2-3-2、HuggingFaceEmbeddings
HuggingFaceEmbeddings: HuggingFace提供的词嵌入模型,这里默认使用的是’sentence-transformers/all-mpnet-base-v2’。
依赖包安装:
# 需要开VPN安装
pip install sentence-transformers
# 首次需要开VPN安装模型
from langchain.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings()
text = "This is a test document."
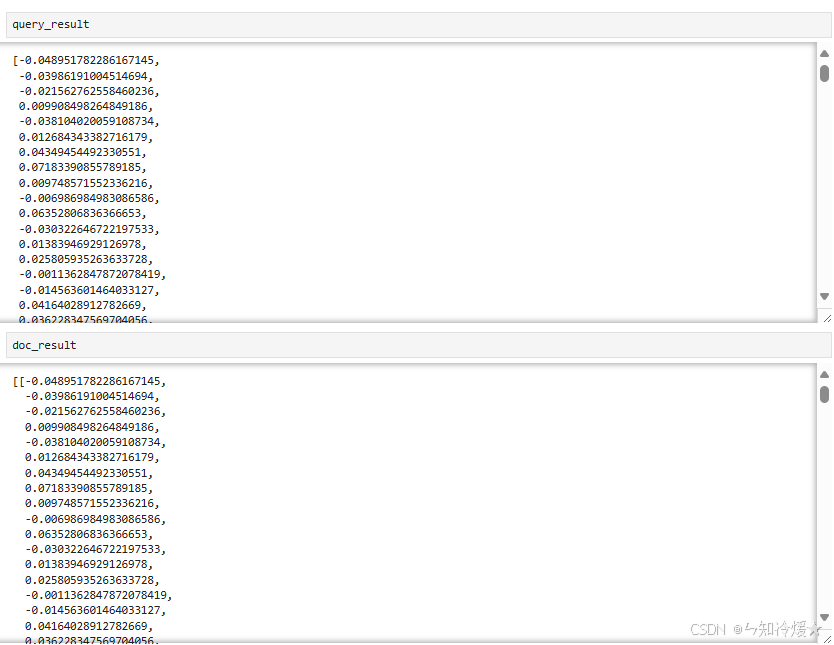
query_result = embeddings.embed_query(text)
doc_result = embeddings.embed_documents([text])
输出:

2-4、向量存储
向量存储: 随着嵌入的兴起,出现了对支持这些嵌入的数据库的需求. LangChain与50多个不同的向量存储进行集成,从开源本地存储到云托管专有存储
2-4-1、FAISS
FAISS(Facebook AI Similarity Search)是由 Meta(前 Facebook)开发的一个高效相似性搜索和密集向量聚类库。它主要用于在大规模数据集中进行向量相似性搜索,特别适用于机器学习和自然语言处理中的向量检索任务。FAISS 提供了多种索引类型和算法,可以在 CPU 和 GPU 上运行,以实现高效的向量搜索。
FAISS 的主要特性
- 高效的相似性搜索:支持大规模数据集的高效相似性搜索,包括精确搜索和近似搜索。
- 多种索引类型:支持多种索引类型,如扁平索引(Flat Index)、倒排文件索引(IVF)、产品量化(PQ)等。
- GPU 加速:支持在 GPU 上运行,以加速搜索过程。
- 批量处理:支持批量处理多个查询向量,提高搜索效率。
- 灵活性:支持多种距离度量,如欧氏距离(L2)、内积(Inner Product)等。
安装:
# cpu或者是GPU版本
pip install faiss-cpu
# 或者
pip install faiss-gpu
Demo分析: 使用 LangChain 库来处理一个长文本文件,将其分割成小块,然后使用 Hugging Face 嵌入和 FAISS 向量存储来执行相似性搜索。
- CharacterTextSplitter:用于将长文本分割成小块。
- FAISS:用于创建向量数据库。
- TextLoader:用于加载文本文件。
- HuggingFaceEmbeddings:另一个用于生成文本嵌入向量的类。
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.document_loaders import TextLoader
from langchain.embeddings import HuggingFaceEmbeddings
# This is a long document we can split up.
with open('./index.txt', encoding='utf-8') as f:
state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(
chunk_size = 100,
chunk_overlap = 0,
)
docs = text_splitter.create_documents([state_of_the_union])
embeddings = HuggingFaceEmbeddings()
db = FAISS.from_documents(docs, embeddings)
query = "学生的表现怎么样?"
docs = db.similarity_search(query)
print(docs[0].page_content)
输出:
Notice: 查询分数,这里的分数为L2距离,因此越低越好


2-4-2、Milvus
Milvus Milvus 是一个开源的向量数据库,专门设计用于处理向量搜索任务,尤其是在机器学习和自然语言处理领域中常见的大规模向量搜索场景。Milvus 支持多种类型的向量,包括但不限于浮点数和二进制向量,它可以与各种深度学习和NLP模型无缝集成,以存储和检索模型生成的向量。
以下是 Milvus 的一些关键特性:
- 高性能向量搜索:Milvus 提供了高效的向量搜索能力,支持精确搜索和近似搜索,包括范围搜索和 k-最近邻(k-NN)搜索。
- 可扩展性:Milvus 支持水平扩展,可以通过增加更多的服务器来处理更大规模的数据集和更高的查询负载。
依赖包安装:
pip install pymilvus
2-5、检索器
检索器: 一旦数据在数据库中,您仍然需要检索它. LangChain支持许多不同的检索算法,并且是我们增加最多价值的地方之一. 我们支持易于入门的基本方法-即简单的语义搜索. 但是,我们还添加了一系列算法以提高性能. 这些算法包括:
- 父文档检索器: 允许您为每个父文档创建多个嵌入,允许您查找较小的块但返回较大的上下文.
- 自查询检索器: 用户的问题通常包含对不仅仅是语义的东西的引用,而是表达一些最好用元数据过滤器表示的逻辑.自查询允许您从查询中解析出语义部分和查询中存在的其他元数据过滤器.
- 集合检索器: 有时您可能希望从多个不同的来源或使用多个不同的算法检索文档.集合检索器使您可以轻松实现此目的.
等待补充
参考文章:
langchain_community.utilities.sql_database.SQLDatabase
LangChain ️ 中文网,跟着LangChain一起学LLM/GPT开发
LangChain官网
Rebuff: 防止提示词注入检测器
未完成:
Build a Question/Answering system over SQL data
langchain101 AI应用开发指南
总结
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【LangChain系列3】【检索模块详解】

发表评论 取消回复